(超详细) Spark环境搭建(Local模式、 StandAlone模式、Spark On Yarn模式)-程序员宅基地
技术标签: 大数据学习之路 Spark学习之路 spark hadoop 大数据
Spark环境搭建
JunLeon——go big or go home

目录
目录
(4)配置log4j.properties 文件 [可选配置]
前言:
Spark部署模式主要有4种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、Spark On Yarn模式(使用YARN作为集群管理器)和Spark On Mesos模式(使用Mesos作为集群管理器)。
本教程做前三种环境搭建的详细讲解。
一、环境准备
1、软件准备
Linux:CentOS-7-x86_64-DVD-1708.iso
Hadoop:hadoop-2.7.3.tar.gz
Java:jdk-8u181-linux-x64.tar.gz
Anaconda:Anaconda3-2021.11-Linux-x86_64.sh
Spark:spark-2.4.0-bin-without-hadoop.tgz
2、Hadoop集群搭建
请查看 大数据学习——Hadoop集群完全分布式的搭建(超详细)_IT路上的军哥的博客-程序员宅基地_hadoop完全分布式搭建
注:本教程中使用Hadoop完全分布式集群,主机名分别为spark-master、spark-slave01、spark-slave02
3、Anaconda环境搭建
(1)下载Anaconda3
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
注:如果打不开网页,可以尝试换浏览器打开
(2)上传Anaconda的文件到Linux
上传到指定目录:/opt/software #没有的话就创建
(3)Anaconda On Linux 安装
在该目录下,执行Anaconda文件
cd /opt/software
sh ./Anaconda3-2021.11-Linux-x86_64.sh进入以下界面:直接回车即可
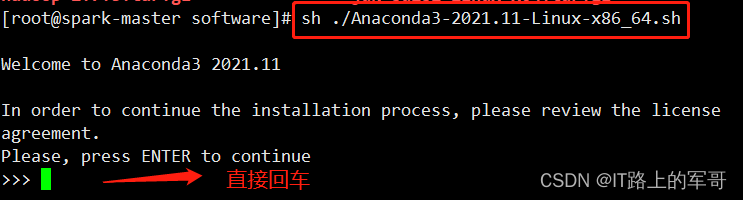
接下来 阅读许可条款 ,一直空格

在此处是询问是否同意许可条款,输入 yes

指定 anaconda3 安装路径:
将路径修改为
/opt/anaconda3目录下
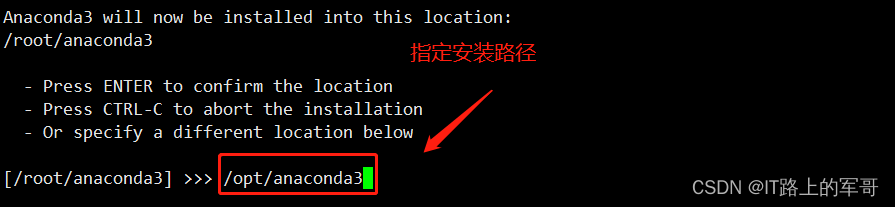
此处需要初始化,输入 yes

最后,使用exit退出远程连接工具,重新连接,如果出现以下base字样,说明安装成功!

注:base是默认的虚拟环境。
以上单台 Anaconda On Linux 环境搭建成功,即可开始安装spark。
(4)配置国内源:
vi ~/.condarc这个文件,追加以下内容:
注:该文件是一个空文件,直接添加即可
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud(5)创建pyspark环境
conda create -n pyspark python=3.6 # 基于python3.6创建pyspark虚拟环境
conda activate pyspark # 激活(切换)到pyspark虚拟环境注:如果执行 conda create -n pyspark python=3.6 命令下载失败,可能是你的虚拟机不能ping通网络,可以看看ping www.baidu.com是否能够ping通
(6)pip下载pyhive、pyspark、jieba包
在pyspark环境中使用pip下载pyhive、pyspark、jieba包
pip install pyspark==2.4.0 jieba pyhive -i https://pypi.tuna.tsinghua.edu.cn/simple二、Spark Local模式搭建
Spark Local模式也称单机或者本地模式,仅供测试用。并在spark-master主机进行操作。
1、Spark下载、上传和解压
(1)Spark版本下载
该环境搭建spark使用spark-2.4.0版本
(2)上传Spark压缩包
上传到指定目录:/opt/software
(3)解压上传好的压缩包
cd /opt/software
tar -zxvf spark-2.4.0-bin-without-hadoop.tgz -C /opt
mv spark-2.4.0-bin-without-hadoop/ spark-2.4.0解压之后进行重命名,重命名为
spark-2.4.0
2、配置环境变量
配置Spark由如下5个环境变量需要设置
-
SPARK_HOME: 表示Spark安装路径在哪里
-
PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器
-
JAVA_HOME: 告知Spark Java在哪里
-
HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里
-
HADOOP_HOME: 告知Spark Hadoop安装在哪里
这5个环境变量 都需要配置在: /etc/profile中
# JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_181
# HADOOP_HOME
export HADOOP_HOME=/opt/hadoop-2.7.3
# SPARK_HOME
export SPARK_HOME=/opt/spark-2.4.0
# HADOOP_CONF_DIR
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# PYSPARK_PYTHON
export PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$PATHPYSPARK_PYTHON和JAVA_HOME 需要同样配置在: ~/.bashrc中
vi ~/.bashrc
# 默认启动pyspark虚拟环境
conda activate pyspark
# JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_181
# PYSPARK_PYTHON
export PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python
export PATH=$JAVA_HOME/bin:$PATH配置好环境变量记得使文件生效:
source /etc/profile
source ~/.bashrc3、配置Spark配置文件
(1)spark-env.sh
cd /opt/spark-2.4.0/conf
cp spark-env.sh.template spark-env.sh在该文件最后追加以下内容:
export JAVA_HOME=/opt/jdk1.8.0_181
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.7.3/bin/hadoop classpath)4、测试
(1)验证Spark是否安装成功
pyspark进入pyspark虚拟环境后,输入pyspark后出现spark的logo则说明已成功:
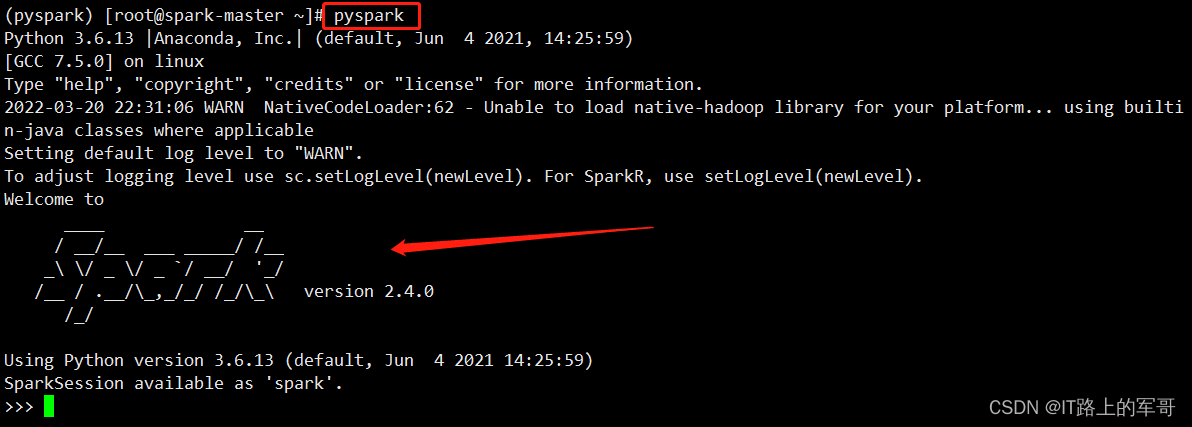
(2)运行Spark自带的Pi实例
run-example SparkPi
run-example SparkPi 2>&1 | grep "Pi is roughly" # 过滤日志信息(3)运行WordCount.py文件
在家目录下,创建一个.py文件,添加以下代码:
附:WordCount.py代码
# ~/WordCount.py
if __name__ == '__main__':
# 导入相关依赖包
from pyspark import SparkConf, SparkContext
# 创建SparkConf,创建一个SparkContext对象
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
# 设置文件路径
logFile = "file:///opt/spark-2.4.0/README.md"
# 负责读取README.md文件生成RDD
logData = sc.textFile(logFile, 2).cache()
# 统计RDD元素中包含字母a和字母b的行数
numAs = logData.filter(lambda line: 'a' in line).count()
numBs = logData.filter(lambda line: 'b' in line).count()
# 打印输出统计结果
print('Lines with a: %s, Lines with b: %s' % (numAs, numBs))执行任务提交:
spark-submit ~/WordCount.py5、补充:spark-shell、spark-submit
(1)spark-shell
同样是一个解释器环境, 和pyspark不同的是, 这个解释器环境运行的不是python代码, 而是scala程序代码。
scala> sc.parallelize(Array(1,2,3,4,5)).map(x=> x + 1).collect()
res0: Array[Int] = Array(2, 3, 4, 5, 6)(2)spark-submit
作用: 提交指定的Spark代码到Spark环境中运行
使用方法:
# 语法
bin/spark-submit [可选的一些选项] jar包或者python代码的路径 [代码的参数]
# 示例
bin/spark-submit /opt/spark-2.4.0/examples/src/main/python/pi.py 10
# 此案例运行Spark官方所提供的示例代码,来计算圆周率值。后面的10是主函数接受的参数, 数字越高, 计算圆周率越准确。(3)pyspark、spark-shell、spark-submit对比
| 功能 | bin/spark-submit | bin/pyspark | bin/spark-shell |
|---|---|---|---|
| 功能 | 提交java\scala\python代码到spark中运行 | 提供一个python |
|
| 解释器环境用来以python代码执行spark程序 | 提供一个scala |
||
| 解释器环境用来以scala代码执行spark程序 | |||
| 特点 | 提交代码用 | 解释器环境 写一行执行一行 | 解释器环境 写一行执行一行 |
| 使用场景 | 正式场合, 正式提交spark程序运行 | 测试\学习\写一行执行一行\用来验证代码等 | 测试\学习\写一行执行一行\用来验证代码等 |
三、Spark StandAlone模式搭建
1、Hadoop集群与Spark集群节点规划
(1)集群主机名、IP规划
| 主机名 | IP地址 | 节点类型 |
|---|---|---|
| spark-master | 192.168.83.100 | Master |
| spark-slave01 | 192.168.83.101 | Slave |
| spark-slave02 | 192.168.83.102 | Slave |
(2)节点规划
| 节点进程 | spark-master | spark-slave01 | spark-slave02 |
|---|---|---|---|
| NameNode | |||
| Secondary NameNode | |||
| DataNode | |||
| ResourceManager | |||
| NodeManager | |||
| JobHistoryServer(YARN) | |||
| Master | |||
| Worker | |||
| HistoryServer(Spark) |
注:
JobHistoryServer:YARN资源管理器的历史服务器,将YARN运行的程序的历史日志记录下来,通过历史服务器方便用户查看程序运行的历史信息。
HistoryServer:Spark的历史服务器,将Spark运行的程序的历史日志记录下来, 通过历史服务器方便用户查看程序运行的历史信息。
2、三台虚拟机分别安装Anaconda3环境
此Anaconda环境搭建参考以上 环境准备中的第3点。也可以从第一台分发到另外两台:
scp -r /opt/anaconda3 root@spark-slava01:/opt
scp -r /opt/anaconda3 root@spark-slava02:/opt3、配置Spark配置文件
可以在spark-master主机操作,最后再进行分发。
注:Spark安装路径为:/opt/spark-2.4.0
spark配置文件路径为:/opt/spark-2.4.0/conf
cd /opt/spark-2.4.0/conf(1)配置spark-env.sh文件
# 1. 改名
mv spark-env.sh.template spark-env.sh
# 2. 编辑spark-env.sh, 在底部追加如下内容
vi spark-env.sh在spark-env.sh文件底部追加以下内容
## 设置JAVA安装目录
export JAVA_HOME=/opt/jdk1.8.0_181
## 设置hadoop命令路径
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.7.3/bin/hadoop classpath)
## 以上两行在local模式中已经添加,如果有请勿重复配置
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/opt/hadoop-2.7.3/etc/hadoop
YARN_CONF_DIR=/opt/hadoop-2.7.3/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=spark-master
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的webui端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu可用核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://spark-master:9000/sparklog/ -Dspark.history.fs.cleaner.enabled=true"(2)配置spark-defaults.conf文件
# 1. 改名
mv spark-defaults.conf.template spark-defaults.confvi spark-defaults.conf # 2. 修改内容, 追加如下内容
# 开启spark的日期记录功能
spark.eventLog.enabled true
# 设置spark日志记录的路径
spark.eventLog.dir hdfs://spark-master:9000/sparklog/
# 设置spark日志是否启动压缩
spark.eventLog.compress true(3)配置slaves文件(新版本为workers文件)
# 改名, 去掉后面的.template后缀
mv slaves.template slaves# 编辑worker文件 vi slaves # 将文件里面最后一行的localhost删除
追加从节点worker运行的服务器,配置三台主机名
spark-master
spark-slave01
spark-slave02(4)配置log4j.properties 文件 [可选配置]
# 1. 改名
mv log4j.properties.template log4j.properties# 2. 修改内容 参考下图
vi log4j.properties定位到19行:将INFO修改为WARN
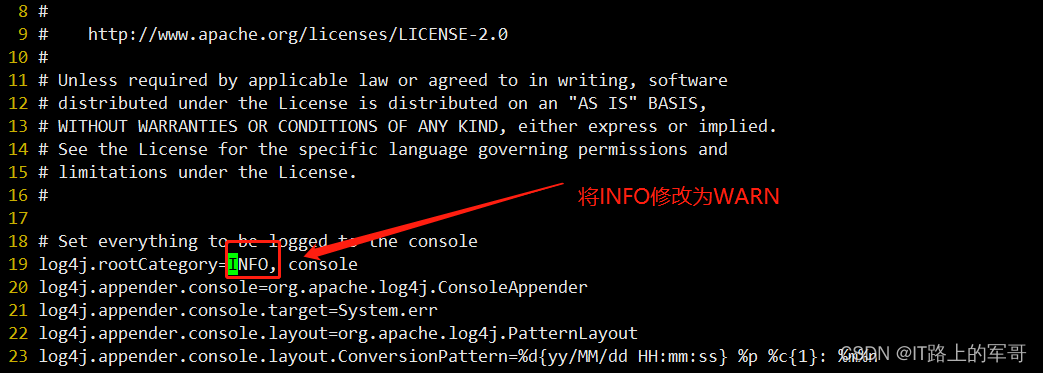
4、将配置好的spark分发到其他两台服务器上
将在spark-master主机上配置好的spark分发到另外两台服务器上:
scp -r /opt/spark-2.4.0/ root@spark-slave01:/opt/
scp -r /opt/spark-2.4.0/ root@spark-slave02:/opt/将主机的/etc/profile文件和~/.bashrc文件也同时分发到另外两台:
scp /etc/profile root@spark-slave01:/etc/
scp /etc/profile root@spark-slave02:/etc/
scp ~/.bashrc root@spark-slave01:~/
scp ~/.bashrc root@spark-slave02:~/分发过去之后需要分别在两台使配置文件生效:
source /etc/profile
source ~/.bashrc5、启动节点
1)启动Hadoop集群
start-all.sh # 只在spark-master主机上执行2)启动spark集群
cd /opt/spark-2.4.0/sbin
./start-all.sh开启全部节点后,如图所示:
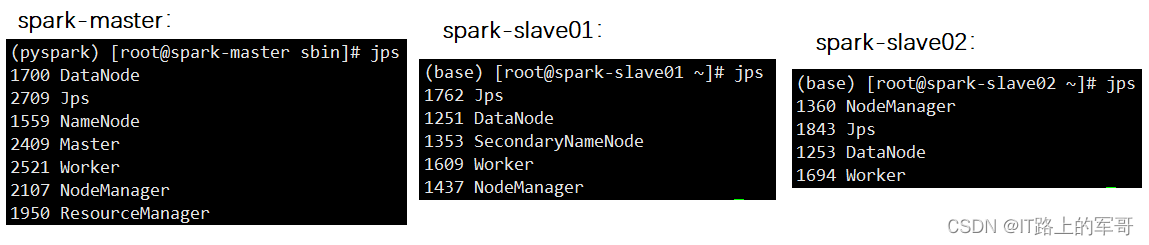
6、web端访问:
web端访问需要关闭防火墙:
systemctl stop firewalld1)访问HDFS
192.168.83.100:50070 # IP:端口号2)访问YARN
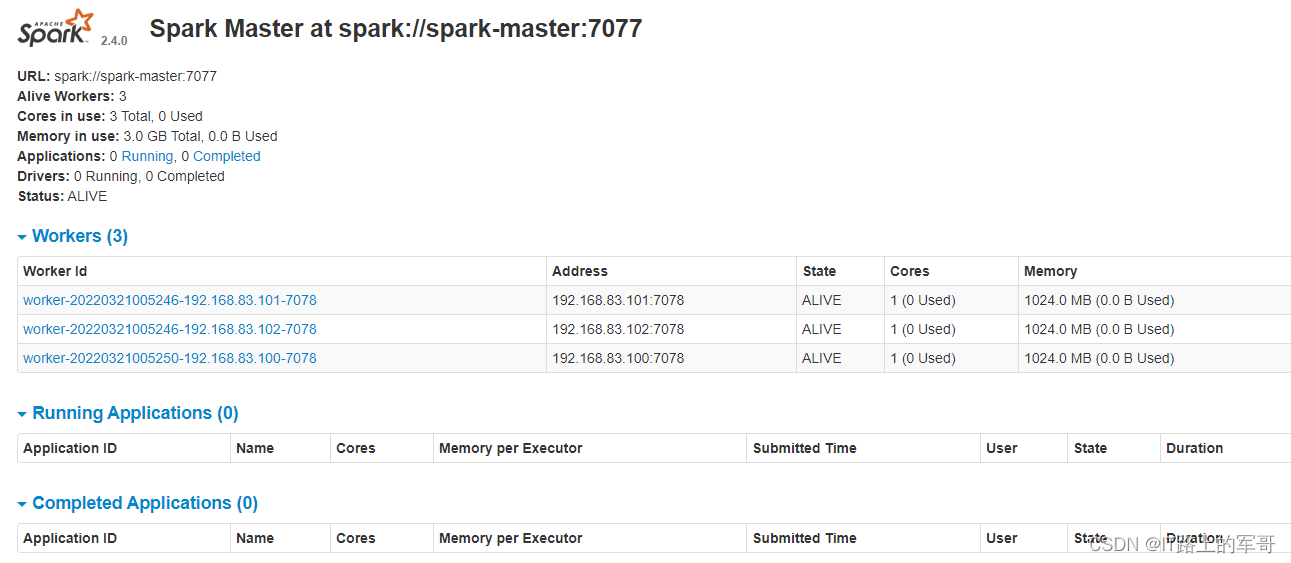
192.168.83.100:8088 # IP:端口号3)访问Spark
192.168.83.100:8080 # IP:端口号如图所示说明成功:
四、Spark On Yarn模式搭建
智能推荐
监听网络变化--含7.0以上适配_android.net.conn.connectivity_change-程序员宅基地
文章浏览阅读3.7k次,点赞3次,收藏7次。我们知道最早监听网络变化,是通过广播,静态或动态注册广播,处理"android.net.conn.CONNECTIVITY_CHANGE"这个action就可以了intent就可以了。我们发现"android.net.conn.CONNECTIVITY_CHANGE"这个action已经加了注解@Deprecated,不推荐使用了。根据注释说明,7.0及以上静态注册广播(manifest中)..._android.net.conn.connectivity_change
计算机学习目标_bytetrack+yolov5 c++-程序员宅基地
文章浏览阅读291次。开个坑_bytetrack+yolov5 c++
fatal error: filesystem: 没有那个文件或目录_fatal error: filesystem: no such file or directory-程序员宅基地
文章浏览阅读4.8k次,点赞12次,收藏39次。fatal error: filesystem: 没有那个文件或目录_fatal error: filesystem: no such file or directory
2020起重机械指挥作业考试题库及起重机械指挥模拟考试系统_换算英制直径5分钢丝绳为公制多少毫米?()。-程序员宅基地
文章浏览阅读1k次。题库来源:安全生产模拟考试一点通公众号小程序2020起重机械指挥作业考试题库及起重机械指挥模拟考试系统,包含起重机械指挥作业考试题库答案解析及起重机械指挥模拟考试系统练习。由安全生产模拟考试一点通公众号结合国家起重机械指挥考试最新大纲及起重机械指挥考试真题出具,有助于起重机械指挥考试试题考前练习。1、【判断题】指挥人员负责对可能出现的事故采取必要的防范措施。(√)2、【判断题】手势信号包括通用手势信号、专用手势信号和其它指挥信号。()(×)3、【判断题】吊装用的短环链,不..._换算英制直径5分钢丝绳为公制多少毫米?()。
大数据应用丨大数据时代的医学公共数据库与数据挖掘技术简介_dryad数据库-程序员宅基地
文章浏览阅读1.7k次,点赞2次,收藏25次。本文我们将介绍几种数据库和数据挖掘技术,帮助临床研究人员更好地理解和应用数据库技术。数据挖掘技术可以从大量数据中寻找潜在有价值的信息,主要分为数据准备、数据挖掘、以及结果表达和分析。数据库技术是研究、管理和应用数据库的一门软件科学。通过研究数据库的结构、存储、设计、管理和应用的基本理论和实现方法,对数据库中的数据进行处理和分析。_dryad数据库
Java实现生成数据库表结构文档(生成工具screw的使用)_java实现数据库表文档-程序员宅基地
文章浏览阅读1.8k次。screw_java实现数据库表文档
随便推点
SpringBoot整合Elastic-job实现_springboot + elasticjob-程序员宅基地
文章浏览阅读3.1k次,点赞3次,收藏13次。SpringBoot整合Elastic-job实现【基本整合】:原理参考:Elastic-Job原理(1)引用pom依赖:<dependency> <groupId>com.dangdang</groupId> <artifactId>elastic-job-lite-core</artifactId> <..._springboot + elasticjob
Attensleep:一种基于注意力的单通道EEG睡眠分期深度学习方法_an attention-based deep learning approach for slee-程序员宅基地
文章浏览阅读791次。AttenSleep 基于注意力的深度学习架构从单通道EEG信号中进行睡眠阶段分类从基于多分辨率卷积神经网络( MRCNN )和自适应特征重标定( AFR )的特征提取模块入手。MRCNN可以提取低频和高频特征,而AFR可以通过建模特征之间的相互依赖关系来提高提取特征的质量。第二个模块是时间上下文编码器( TCE ),它利用多头注意力机制来捕获提取特征之间的时间依赖关系。特别地,多头注意力利用因果卷积对输入特征中的时间关系进行建模。使用三个公共数据集来评估提出的AttnSleep模型的性能。_an attention-based deep learning approach for sleep stage classification wit
Myeclipse技巧-程序员宅基地
文章浏览阅读71次。在了解MyEclipse使用技巧之前我们来看看MyEclipse是什么呢?简单而言,MyEclipse是Eclipse的插件,也是一款功能强大的J2EE集成开发环境,支持代码编写、配置、测试以及除错。下面让我们看看MyEclipse使用技巧的具体内容。MyEclipse使用技巧第一步: 取消自动validationvalidation有一堆,什么xml、jsp、jsf..._myeclipse是什么
c语言统计数组每个数出现的次数,统计数组中某个元素出现的次数和重复的次数...-程序员宅基地
文章浏览阅读8.9k次。//出现的次数function times(arr){var m=0,times=0;//m是数组中的元素,times用来统计出现的次数// for循环遍历arr数组for(var i=0;iif(arr[i]==m){times++;//数组中有相同值就加1}}return times;console.log(times);//这是打印出的出现的次数}times([0, 1, 2, 0, 1, ..._c语言统计数组中每个数字出现的次数
Jmeter连接InfluxDB2.0.4_influxdborganization jmeter-程序员宅基地
文章浏览阅读2.5k次,点赞5次,收藏14次。Jmeter连接InfluxDB2.0.4问题描述:在用Jmeter+InfluxDB构建监控时,因为docker构建的InfluxDB的版本是2.0.4,按照网上的教程进行后端监听器的填写,但是一直出现错误提示401等问题。网上的教程大多是1.X版本的,怀疑是数据库版本不一致导致的数据无法写入,通过调研,问题已解决。以下为配置方法。一、InfluxDB搭建完成后,查看Organization和Bucket名称,这里是ORZ_test和bucket_nameOrganization在这里我的理解_influxdborganization jmeter
关于第三方支付,看这篇文章就够了!-程序员宅基地
文章浏览阅读1.6k次。目录 目录 1、第三方支付概述 2、第三方支付起源 PayPal 支付宝 3、牌照发放 4、支付牌照 5、第三方支付参与者 6、第三方支付行业监管 监管意图对第三方支付可能产生的影响..._第三方支付本行对本行的费用