MySQL搭建主从复制集群,实现读写分离_创建mysql集群,主从复制,读写分离,实现一主两从-程序员宅基地
技术标签: Java java mysql 编程环境安装 数据库
目录
一、准备
准备两台服务器,为每台都安装好mysql。
此时的两台服务器它们的mysql之间没有半毛钱关系,各自是独立的。
如果不会安装,后续我也会出一篇安装教程。请关注我的【编程环境安装】专栏。
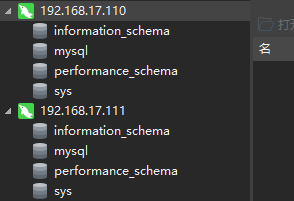
二、配置
2.1 配置主库
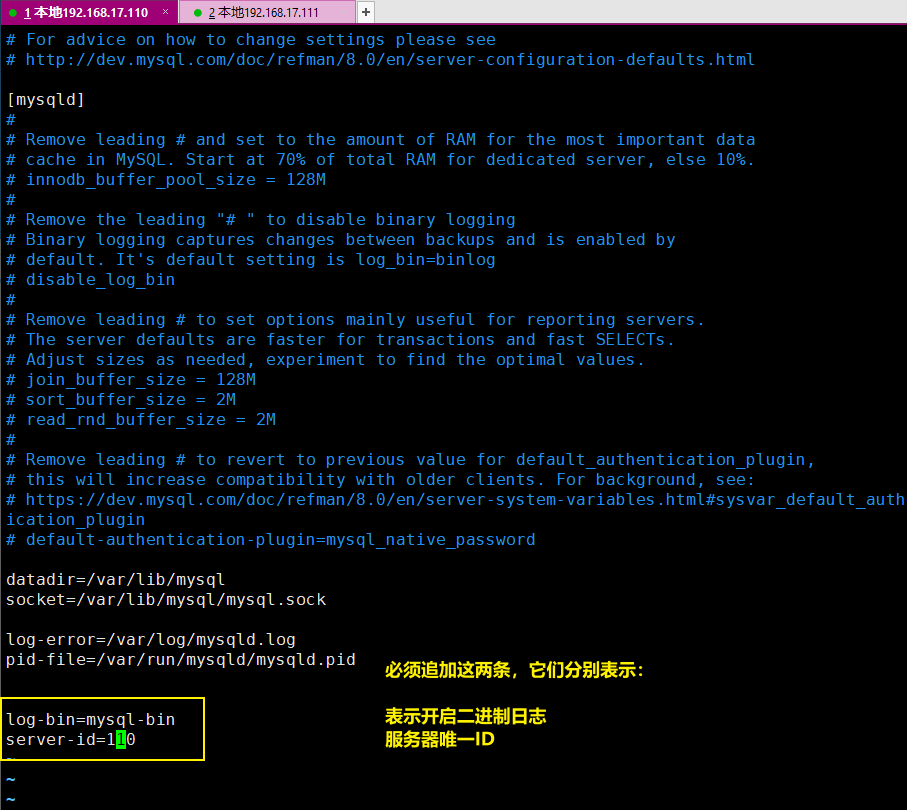
修改配置文件/etc/my.cnf
追加如下:
[mysqld]
log-bin=mysql-bin
server-id=110以后在进行增删改操作的时候,它都会进行记录日志。
重启服务
systemctl restart mysqld
为主库再创建一个账户并授权
CREATE USER '主库用户名'@'%' IDENTIFIED BY '主库用户名密码';
GRANT REPLICATION SLAVE ON *.* TO '主库名称'@'%';
ALTER USER '主库用户名'@'%' IDENDIFIED WITH mysql_native_password BY '主库用户名密码';
flush privileges;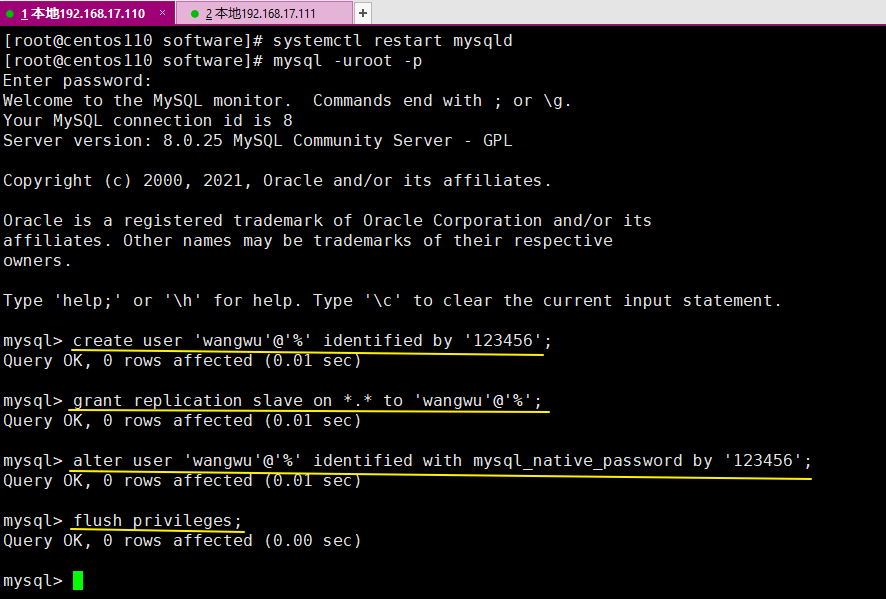
这一步是为主库创建一个用户,并为这个用户授予复制从库的权限。
查看状态
我们先记住这个File和Position的值

记得现在就不要再在主库操作了,否则这个位置就会发生变化。
2.2 配置从库
修改配置文件/etc/my.cnf
增加配置:服务器的唯一标识
server-id=111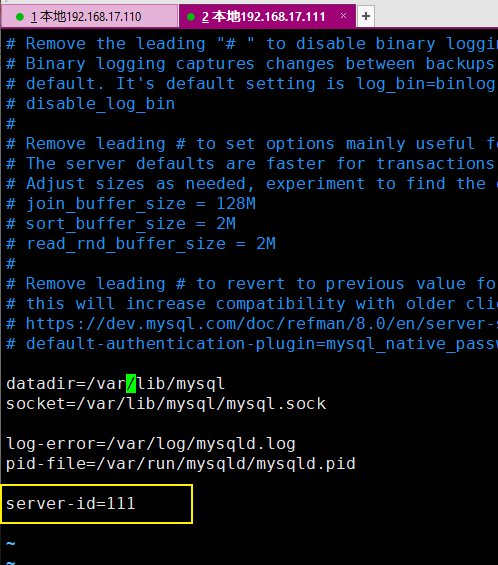
重启mysql服务
systemctl restart mysqld
配置需要同步的主机
CHANGE MASTER TO
MASTER_HOST='主机的ip地址',
MASTER_USER='主机刚才创建的用户名',
MASTER_PASSWORD='主机用户名的密码',
MASTER_LOG_FILE='主机上记录的File值',
MASTER_LOG_POS=主机上记录的Position值;
启动salve同步
start slave; 查看是否同步
查看是否同步
show slave status;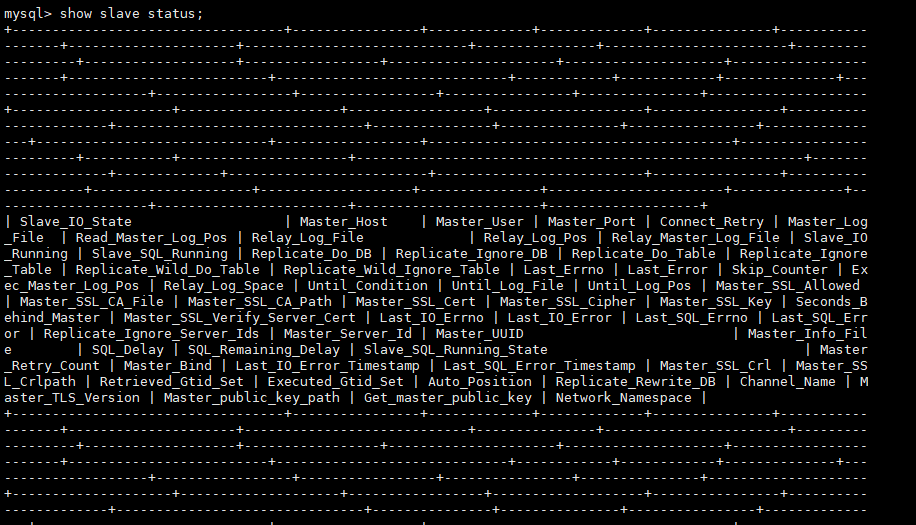 很乱啊,我们把它复制到文本编辑器上来看看
很乱啊,我们把它复制到文本编辑器上来看看

至此,主从复制集群就搭建完成了!
三、测试主从复制是否生效
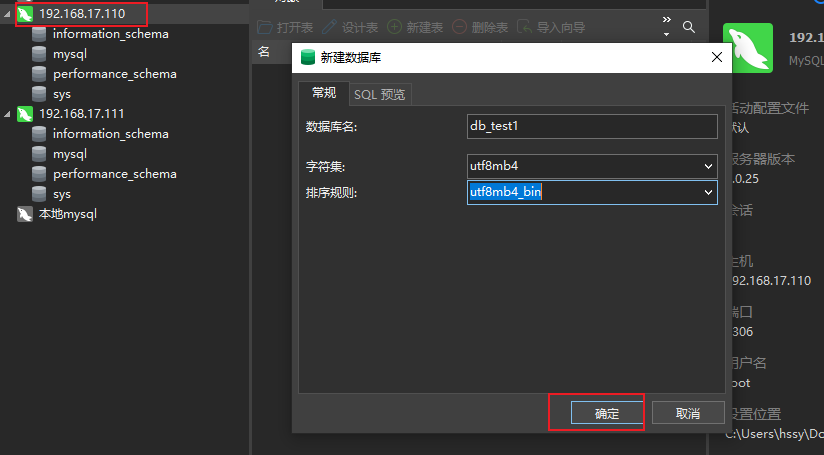
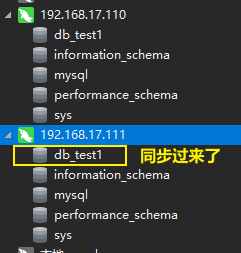
我们通过navicat连接上这两个数据库,通过操作看看,它们的变化。
在主库创建一个数据库。

四、读写分离案例
4.1 背景
如果系统的访问量增大,既要查询又要写入,单台数据库已经不能满足访问压力了。
这个时候就可以考虑主从复制。将数据库拆分成主库和从库。主库主要负责处理事务性的增删改操作,从库负责处理查询操作。
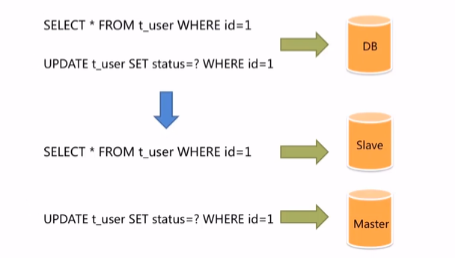
但是我们的系统怎么知道,我们的操作是查询操作,还是增删改操作?又怎么根据操作的类型选择主库还是从库呢?
这个时候就用到了Sharding-JDBC!
4.2 Sharding-JDBC介绍
Sharding-JDBC定位为轻量级的Java框架,在Java的jdbc层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可以理解为增强版的jdbc驱动,完全兼容jdbc和各种orm框架。
-
适用于任何基于JDBC的ORM框架,如:JPA,Hibernate,Mybatis,Spring JDBC Template或直接使用JDBC。
-
支持任何第三方的数据库连接池,如:DBCP,C3P0,Druid,HikariCP等。
-
支持任意实现JDBC规范的数据库。目前支持Mysql,Oracle,SQL server,PostgreSQL以及任何遵顼SQL92标准的数据库。
4.3 项目测试前期准备
在使用分库分表之前,先要搭建好主从复制的数据库。
然后我们先创建一个web项目:
数据库准备
CREATE TABLE `user` (
`id` int unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '姓名',
`age` tinyint DEFAULT NULL COMMENT '年龄',
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '住址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='用户'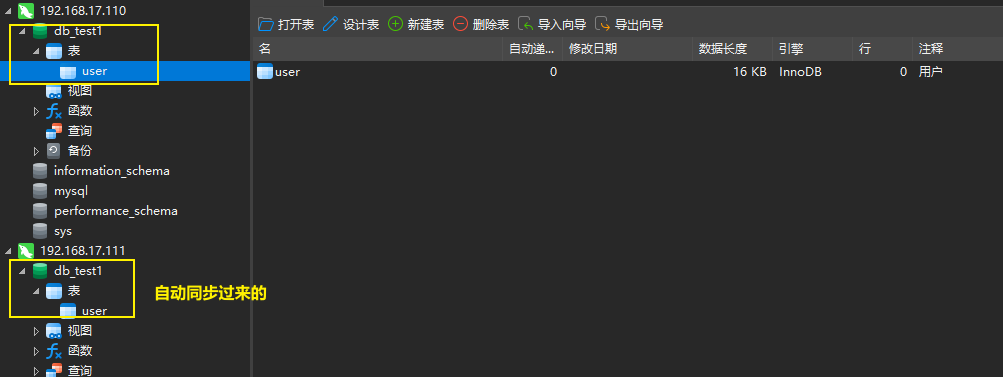
导入依赖
作为web项目基本的一些依赖,没什么好讲的。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.12</version>
</dependency>配置文件
目前只配置了端口号和mybatisplus的相关配置
连数据源连接我们都没有配置,这是因为后面要使用sharding-jdbc
server.port=8080
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
mybatis-plus.global-config.db-config.logic-delete-value=1
mybatis-plus.global-config.db-config.logic-not-delete-value=0
mybatis-plus.configuration.map-underscore-to-camel-case=true
mybatis-plus.global-config.db-config.id-type=assign_id代码生成器
使用代码生成器,快速生成刚才创建的表的controller、entity、service、mapper等文件。
这些做好以后,下面开始使用到sharding-jdbc!
添加依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>添加配置文件规则
# 定义数据源的名字,有几个填写几个,通过.隔开,名字随便取,但是后面配置主从数据源需要根据此名字进行设置
spring.shardingsphere.datasource.names=master-haha,slave-haha
# 数据源1
spring.shardingsphere.datasource.master-haha.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master-haha.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.master-haha.url=jdbc:mysql://192.168.17.110:3306/db_test1?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.master-haha.username=root
spring.shardingsphere.datasource.master-haha.password=123456
# 数据源2
spring.shardingsphere.datasource.slave-haha.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.slave-haha.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave-haha.url=jdbc:mysql://192.168.17.111:3306/db_test1?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.slave-haha.username=root
spring.shardingsphere.datasource.slave-haha.password=123456
# 配置从库负载均衡策略:轮询。就是说从库实际不一定只有一台,当每次查询操作进来的时候,轮询去查每台从库。
spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin
# 设置最终数据源的名称 其实就是spring中bean对象的名称
spring.shardingsphere.masterslave.name=dataSource
# 指定主库数据源名称
spring.shardingsphere.masterslave.master-data-source-name=master-haha
# 指定从库数据源名称 从库如果有多个,通过逗号隔开
spring.shardingsphere.masterslave.slave-data-source-names=slave-haha
# 开启控制台的sql显示,默认是false
spring.shardingsphere.props.sql.show=true以上规则定义好了,它查询就会去从库(每台从库轮询查),增删改去主库。
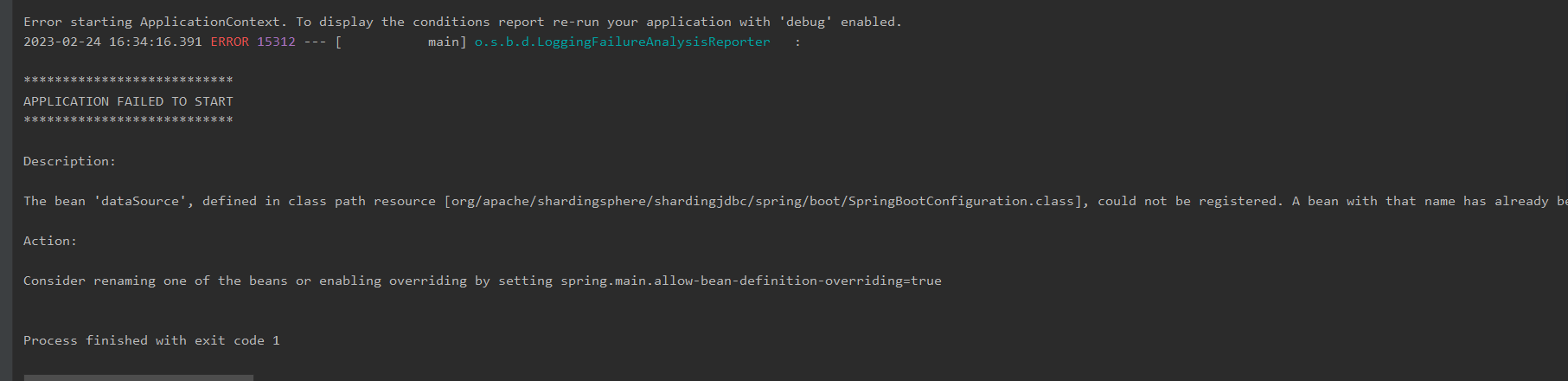
但是,最后还需要修改一下spring的bean覆盖策略,默认是不允许同名bean的。
为什么要修改呢?因为我们定义的bean的名称和druid中定义的bean的名字重复了。
而spring中默认不允许同名的bean的。
所以需要在配置文件中再加上一段配置
# 允许bean定义覆盖,后创建的bean会覆盖前面的同名bean对象
spring.main.allow-bean-definition-overriding=true否则启动项目会报错
 ok,下面我们创建一些测试方法来验证一下。
ok,下面我们创建一些测试方法来验证一下。
4.4 验证
创建测试方法,包含增删改查
注意这里引入了一个DataSource对象,虽然实际业务代码并没有使用到,但是我们只是想看看它到底是谁。
@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {
@Autowired
private DataSource dataSource;
@Autowired
private UserService userService;
@PostMapping
public User save(User user){
userService.save(user);
return user;
}
@DeleteMapping("/{id}")
public void delete(@PathVariable Long id){
userService.removeById(id);
}
@PutMapping
public User update(User user){
userService.updateById(user);
return user;
}
@GetMapping("/{id}")
public User getById(@PathVariable Long id){
User user = userService.getById(id);
return user;
}
@GetMapping("/list")
public List<User> list(User user){
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(user.getId() != null,User::getId,user.getId());
queryWrapper.eq(user.getName() != null,User::getName,user.getName());
List<User> list = userService.list(queryWrapper);
return list;
}
}打上断点,以DEBUG的方式启动
断点的位置我们如图
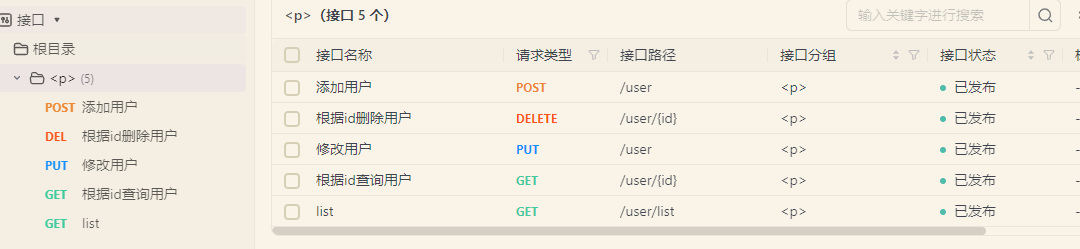
发送请求测试
我们可以通过postman来发送请求试试,我这里使用apifox来测试。
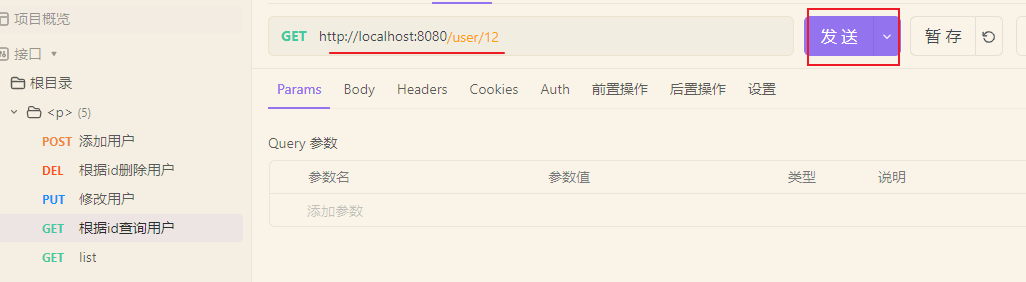
先来查询一下
我们发现这个datasource是shardingjdbc提供的

接着放行该请求
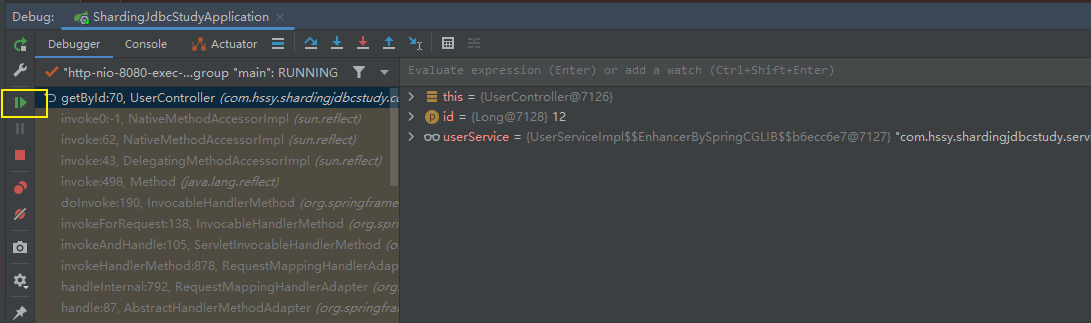
我们通过控制台看到,这条sql是从库去查询的!
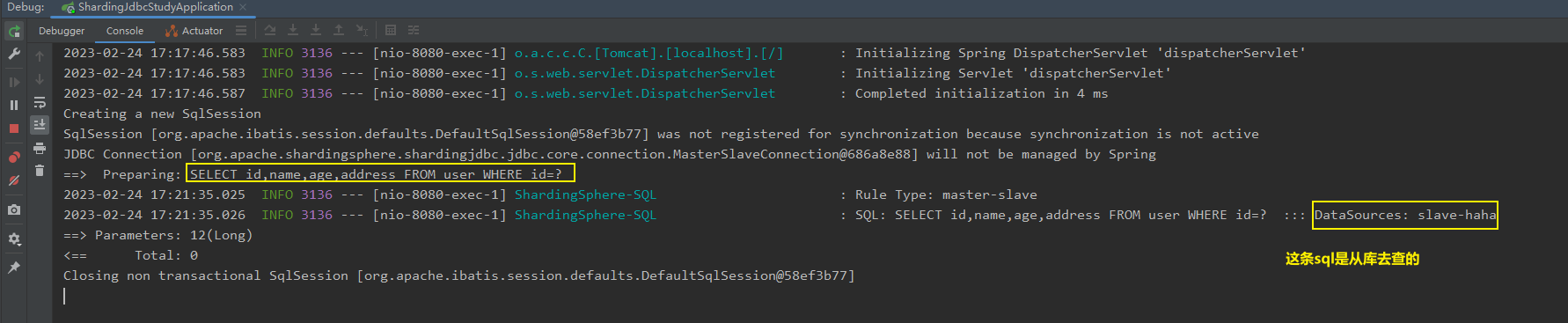
ok,再发送添加请求试试。
我们直接放行,发现添加操作是主库执行的。
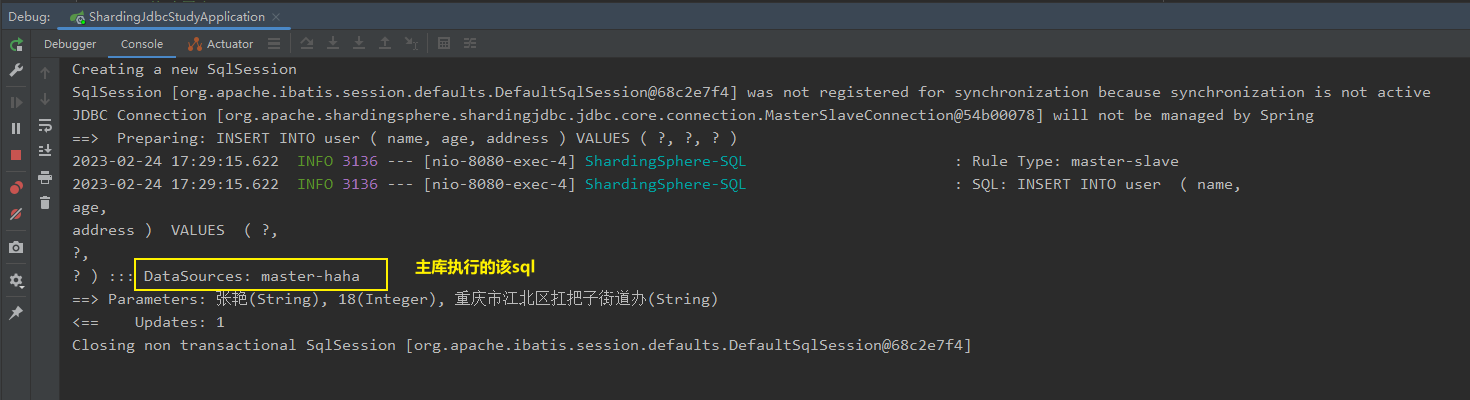
ok,下面我们再检查一下数据库

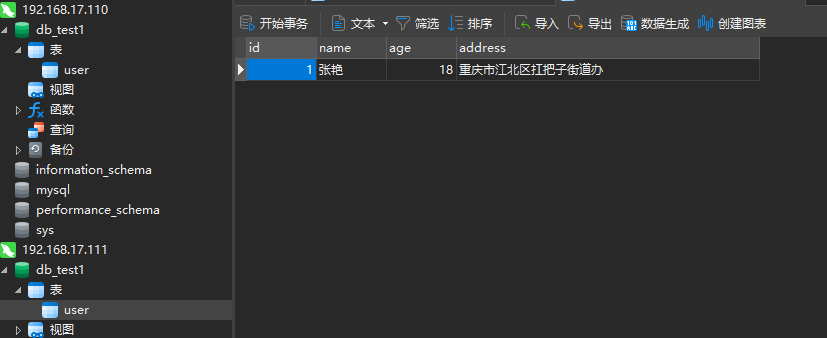
ok,主库也同步到了从库了。
五、主从复制数据不同步的问题
案例:误操作向从库添加了数据。
我通过navicat向从库的user表中生成假数据1w条,这肯定不会同步到主库的。
因为是主库写,从库读。不能乱来。
这就导致从库出现问题。我们通过show slave status;命令查看从库是否同步,发现sql转储线程停掉了。那肯定就不能继续同步数据了。
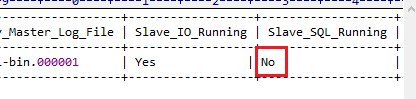
这个时候解决办法就是重新同步。具体方法时间关系就不再赘述了。附上思维导图:
MySQL主从复制那些事儿| ProcessOn免费在线作图,在线流程图,在线思维导图
文章花费了我大量心血和时间,
吃水不忘挖井人,如果对你有帮助,别忘了三连,点赞收藏评论 ~
智能推荐
如何在 Linux 上安装设备驱动程序_name-of-desired-driver-程序员宅基地
文章浏览阅读2.7k次。学习 Linux 设备驱动如何工作,并知道如何使用它们。对于一个熟悉 Windows 或者 MacOS 的人,想要切换到 Linux,它们都会面临一个艰巨的问题就是怎么安装和配置设备驱动。这是可以理解的,因为 Windows 和 MacOS 都有一套机制把这个过程做得非常的友好。比如说,当你插入一个新的硬件设备, Windows 能够自动检测并会弹出一个窗口询问你是否要继续驱动程序的安装。你也可以从网络上下载驱动程序,仅仅需要双击解压或者是通过设备管理器导入驱动程序即可。而这在 Linux 操作系.._name-of-desired-driver
安装ArcGIS10.2-详细图文安装教程_arcgis安装教程10.2-程序员宅基地
文章浏览阅读2.6w次,点赞42次,收藏120次。说明:ArcGIS Decktop安装结束后,如果需要操作上面的第10和第11步来设置License的读取,可点击“开始”-“程序”-“ArcGIS”-“ArcGIS Administrator”弹出的界面中操作。说明:ArcGIS Server安装完后,只需首次进行新站点的创建,以后只需点击“开始”-“程序”-“ArcGIS”-“ArcGIS 10.2 for Server”-“Manager”进入管理界面。5.如上信息设置完成后,点击“ok”。若界面中出现“success”的字样,表示创建成功。_arcgis安装教程10.2
synchronize锁升级-程序员宅基地
文章浏览阅读625次,点赞13次,收藏11次。Java中的synchronized关键字用于实现线程同步,保证多个线程对共享资源的操作具有原子性和可见性。在不同的JDK版本中,对synchronized的优化过程可能有所不同。在旧版本的JDK中,synchronized关键字的底层实现是依赖于操作系统的底层互斥量(mutex)来实现的。每次进入synchronized块时,会使用操作系统提供的互斥量进行加锁和解锁。这种方式在竞争不激烈的情况下效率较高,但在高并发场景下可能存在性能问题。从JDK 1.6开始,Java引入了和来优化。
日常软件集合-程序员宅基地
文章浏览阅读90次。2019独角兽企业重金招聘Python工程师标准>>> ..._mac astah community
服务器能ping通外界,但是外界无法ping通服务器_linux服务器能ping外面但是不能被ping-程序员宅基地
文章浏览阅读4.5k次。服务器直接接入路由器来获取ip(192.168.1.101)等等,所以可以直接ping通外界ip,但是不能被外界直接访问。先是关闭了防火墙,发现无济于事serivce iptables stop后来发现新服务器是通过路由器在连接到公网,所以外界根本不可能直接ping通这个192.168.2.101于是需要进入到路由器的设置界面进行修改,直接打开浏览器,输入路由器地址192.168.1.1,输入管理员密码进行设置。需要设置两处:1.设置DMZ,需要将DMZ打开2.设置虚拟路由器,让路由器能够转_linux服务器能ping外面但是不能被ping
11个值得珍藏的4K高清壁纸网站推荐_wallpaper abyss 官网-程序员宅基地
文章浏览阅读5.4w次,点赞33次,收藏248次。前言由于前几天因需求须找一些视觉素材,翻来覆去整了一些,整理了10个图片素材网站可以给大家收藏使用&作为打开电脑 or 手机第一眼就看到的桌面,给它设置一个赏心悦目的桌面壁纸还是必不可少的。下面分享了 10 个值得珍藏的高清桌面壁纸网站,支持各种图片比例和分辨率,从 720P 到 4K、8K 应有尽有,电脑和手机都可以使用。高清桌面壁纸网站1. Awesome Wallpapers - wallhaven.cc官网:https://alpha.wallhaven.cc/.._wallpaper abyss 官网
随便推点
2023年MathorCup数学建模C题思路 - 电商物流网络包裹应急调运与结构优化问题_数学建模物流配网络问题-程序员宅基地
文章浏览阅读720次。1 赛题C 题 电商物流网络包裹应急调运与结构优化问题电商物流网络由物流场地(接货仓、分拣中心、营业部等)和物流场地之间的运输线路组成,如图 1 所示。受节假日和“双十一”、“618”等促销活动的影响,电商用户的下单量会发生显著波动,而疫情、地震等突发事件导致物流场地临时或永久停用时,其处理的包裹将会紧急分流到其他物流场地,这些因素均会影响到各条线路运输的包裹数量,以及各个物流场地处理的包裹数量。_数学建模物流配网络问题
图解机器学习算法(1) | 机器学习基础知识(机器学习通关指南·完结)_机器自学习算法示意框图-程序员宅基地
文章浏览阅读1.5w次,点赞23次,收藏260次。本文覆盖机器学习常见知识要点,包括机器学习流程、算法分类(监督学习、无监督学习、强化学习)、依托的问题场景(分类、回归、聚类、降维)、机器学习模型评估与选择等。_机器自学习算法示意框图
厦门大学数据结构MOOC 5-2 Knowledge (20 point(s))-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏3次。每个人的学识水平化为09,用09表示其学识高低程度。众所周知,与新生婴儿讨论微积分是一个非常扯淡的事情,所以,学识不为0的人群才可以参与讨论, 现在给定一个m*n的人群,给定每个人的文化程度,每个人仅可和上下左右进行讨论,所以请你求出学术讨论组的个数。输入格式:用空格隔开的整数m,n(m行,n列)矩阵(1≤m,n≤100)。输出格式:学识组的个数。输入样例:4 10067480001..._厦门大学数据结构mooc 5-2 knowledge (20 point(s))
国内免费可用的stun服务器(2020.7.14)_国内stun-程序员宅基地
文章浏览阅读5.2w次,点赞3次,收藏18次。端口号都是3478stun.xten.com stun.voipbuster.com stun.sipgate.net stun.ekiga.netstun.ideasip.comstun.schlund.destun.voiparound.comstun.voipbuster.comstun.voipstunt.comstun.counterpath.comstun.1und1.destun.gmx.netstun.callwithus.comstun.cou..._国内stun
FIFO溢出-FIFO上溢和FIFO下溢区别_fifo上溢和下溢-程序员宅基地
文章浏览阅读2.5k次,点赞3次,收藏7次。By: Ailson JackDate: 2021.11.28个人博客:http://www.only2fire.com/本文在我博客的地址是:http://www.only2fire.com/archives/141.html,排版更好,便于学习,也可以去我博客逛逛,兴许有你想要的内容呢。在调试芯片的某个外设的时候,如果该外设带有FIFO,那么一般情况下都有FIFO上溢和FIFO下溢的错误标志位,用于表示驱动对外设的FIFO操作是否正确,下面就是FIFO上溢和FIFO下溢对应的概念:FIFO上_fifo上溢和下溢
win10系统玩部分老游戏时提示0xc0000022的解决方法._游戏0xc0000032-程序员宅基地
文章浏览阅读2.6k次。在win10系统中玩一些游戏时会碰到以下提示,"应用程序无法正常启动(0xc0000022)",这是因为win10缺少了系统的某种组件引起的,因为win10相对之前的版本会有一些旧的组件被淘汰,而那些远古游戏需要依赖那些组件才能运行,于是出现以上报错.当开启游戏时系统会主动出现以下提示,只需要点击"安装此功能"将该组件下载即可.点击搜索栏,输入"控制面板" ,然后打开控制面板.之后点击程序, 进入程序界面后点击启用或关闭windows功能. 然后下拉找到旧版组件,点击左侧+号. 将组件勾选然后单击下方确_游戏0xc0000032