在线算法(online algorithm)--竞争性分析-程序员宅基地
文章目录
基于参考材料,和自己的理解,本文主要整理了在线学习中的竞争性分析,和它的典型例子:page replacement问题。便于自己后续查阅。
说到这里,真的是不得不吐槽国内的算法课以及百度,几乎不教或者没有这方面的中文资料。必须要去google上去找国外lecture的资料和书。由于自己之前其实也没有接触过competitve analysis,所以才想记录一下自己的了解过程。一些基础的概念就不再记录了。
一、Problem Setting
1.1 competitve analysis
竞争分析是指,将在线算法所产生的费用与离线算法(假设所有信息都知道)所产生的费用进行比较和分析。
参考文献【1】是难得的一个用中文描述的资料。胡老师在PPT中介绍:

这里有一个重要的概念在于:对于任意给定的 S S S,算法 A A A产生的cost最多是最优算法OPT的 α \alpha α倍。
1.2 page replacement
We give a machine with a slow memory that can hold N pages, and a fast memory with k slots. Page requests arrive one at a time, and must be served out of fast memory. If the page is already in fast memory (cache), then a hit occurs, and the operation is free. Otherwise, there is a cache miss, the page is brought into fast memory, and one of the k existing pages in the cache is evicted. The goal is to minimize the number of cache misses over the sequence of page requests.
简单来说,就是有一个页面请求序列,如果序列里的元素在cache中了,那么就算命中,没有开销;如果不在cache里,必须要evict cache中的一个element,设计出一个算法使得整个序列的miss最少。
接下来,我们以这个问题为背景展开介绍。
二、Deterministic Online Algorithms
2.1 deterministic online algorithm
在操作系统课上,已经学过不少的确定性的页面置换算法了。这里做个简单的总结:
- LIFO(last input first output):”后进新出原则“,将最近一次放入cache中的页面交换出去。
- LFU (leasy frequency used):“最少调用原则”,交换出去最少被调用的页面。
- LRU(least recently used): “最近最久未使用原则”,交换出这样一个页面它最近的一次调用是最早产生的。
- FIFO(first input first out):”先进先出原则“,交换出去在cache中时间最长的页面。
当然,对于离线算法来说,它已经知道了序列的未来,所以就有一个offline 最优的算法(有时候称为MIN),这就是Bedaly在1966年提出的一种算法,选择以后永远不会被访问的页面或者未来最长时间内不再被访问的页面。
有时候,也被称为LFD (longest-forwarded-distance)。关于它是最优算法的证明,可以参考这篇文章。我们这里省略。
2.1.1 LIFO和LFU不是 α \alpha α-竞争算法
定理2-1:LIFO不是 α \alpha α-竞争算法
证明:若request序列长度为 N N N, 为<p,q,p,q,p,q…>,且初始状态q在cache中,p不在cache中。

因为,For any α \alpha α, there exists a sequence of requests such that #misses(FIFO) ≥ α \alpha α #misses (LFD)。在上面的分析中,算法的开销为 N N N,而最优策略是1,因此算法的开销/最优的开销为N,也就是说是无穷大了。
根据竞争分析的定义,存在了一个序列使得 算法的开销/最优的开销 不小于 α \alpha α,因此不能用于竞争性分析。
下面来看LFU算法:

定理2-2:LFU不是 α \alpha α-竞争算法
证明:如果cache k k k=3,元素是a,b,c,则我们可以构造一个序列,即出现 m m m次a,再出现 m m m次b,再出现1次d,接着出现1次c,dc这样的组合共出现 m m m次。
我们可以看到,按照LFU算法,在出现d时,会发生miss替换掉c,接着出现1次c,会发生miss替换掉d。这样就会产生 2 m 2m 2m个miss,而最优算法只会产生1次miss(即第一次出现d时替换掉a即可),因此如果m无穷大,则LFU算法仍然没有bounded。
换句话说,对于LFU算法,也存在了一个序列使得 算法的开销/最优的开销 不小于 α \alpha α,因此不能用于竞争性分析。
注:以上2个算法的形式化的证明可以在参考文献【2】中找到。

2.1.2 LRU和FIFO是 k k k-竞争算法
定理2-3:LRU是 k k k-竞争算法
这里其实有两个思路来证明定义2-3。我们以参考文献【2】中的证明来举例:
我们将序列 σ \sigma σ来划分phrase,phrase1以序列的第一个元素开始;phrase i开始是以从阶段i-1开始后,我们看到的第 k k k个元素开始。从图中就可以看到

我们可以分析,由于LRU算法的性质,在每一个阶段,最多出现 k k k次cache miss(不可能出现 k + 1 k+1 k+1次,否则不符合阶段的定义了)如果我们可以证明:每一个阶段OPT算法至少会出现1次cache miss。那么竞争ratio就是小于等于 k k k的。
我们具体分析:如果 p 2 i p_2^i p2i到 p k i p_k^i pki中没有发现miss,那么在OPT下 p 1 i + 1 p_1^{i+1} p1i+1必然要发生miss,因为 p 2 i p_2^i p2i到 p 1 i + 1 p_1^{i+1} p1i+1已经是 k k k个不同的元素了,且此时 p 1 i p_1^i p1i已经在cache中了,而cache只有 k k k个位置;
如果在OPT下 p 2 i p_2^i p2i到 p k i p_k^i pki中发现miss,那更说明了每一轮最少发生1次miss了。

当然还有另外一种证明的思路,参考文献【3】和【1】。它划分阶段的方式不一样。但是在【3】中,它提供了一个引理,如果我们可以证明出引理,实际也就证明了定理。
它划分阶段如下:

接着提出一个引理并证明:这个引理是如果 P ( i ) P(i) P(i)中含有 k k k个不同的且不用于上个阶段最后一个页面 p p p的页面,那么其实就说明OPT下必然至少发生一次miss(因为这样就有 k + 1 k+1 k+1个不同的页面了),而由于我们阶段划分已经保证了每个阶段在LRU下发生 k k k次miss,所以实际就证明了LRU是 k k k-竞争算法。
证明引理的过程如下:如果在 P ( i ) P(i) P(i)中 k k k个miss是由于1个页面 q q q引起了2次,也就是说并非是 k k k个不同的页面引起的 k k k个miss,那么实际上这是不可能的事情。

在参考文献【1】中用中文已经举出了这个例子。这里的 p p p就是我们上面的说的 q q q。

FIFO的证明类似。我们这里不再证明。
2.2 deterministic online algorithm的竞争比是 Ω ( k ) \Omega(k) Ω(k)
这个定理的含义是,对于任意的确定性在线算法,它的竞争比至少是 k k k。换句话说,不可能再有一个在线的确定性算法的竞争比 比 k k k好了,其中 k k k是cache的size。
证明,参考文献【2】即可。
不妨假设ALG是某一确定性算法;假设序列长度 N > k N > k N>k,且目前的cache内容就是1,2,3,直到k。假设序列里的内容是1,2,3,k,k+1共k+1个不同的值。那么,对于一个adversary来讲,自然可以把序列变成使得ALG在每个request来的时候都发生miss,这时候ALG的miss是 N N N次。
对于OPT算法来说,一旦发生一个miss,则意味着它逐出的页面将在至少k个其他请求之后被请求,这是肯定的,因为MIN算法已经保证了这一点,即它逐出的永远都是最晚到来的,当发生下一次的miss的时候,最快也是第k+1个,这就意味着OPT每次发生miss的时候,ALG最少发生k次,也就是说竞争比至少为k,即 Ω ( k ) \Omega(k) Ω(k)。

上述的结果其实也扩充了,即如果online算法和offline算法的内存大小不一样,也产生产生类似的结果。证明过程可以参考文献【4】.
在这里,我对竞争性分析和符号 Ω \Omega Ω的关系总结一下,迷惑点在于竞争性分析是≤符号,即算法损失/最优损失 小于等于 一个值,代表了一个最坏的情况(worst-analysis),不管你找什么样的序列,我的算法最烂的损失也就是在这种情况下最优算法的 α \alpha α倍。而 Ω \Omega Ω是大于等于,代表了最优情况,是一个下限,再加上竞争比肯定是越小越好,所以对于一个算法来说 Ω ( l o g n ) \Omega(log n) Ω(logn)要好于 Ω ( n ) \Omega(n) Ω(n)。
如果我们说一个算法的竞争比为 Ω ( k ) \Omega(k) Ω(k),这意味着这个算法的竞争比的下限为 k k k,即属于这类算法的竞争比会大于等于 k k k, 但最好也不过是 k k k了。我们可以回想确定性算法LIFO和LFU都没有竞争比(即无穷大,没有Bounded),而确定性算法LRU和FIFO是 k k k竞争,是有bounded的。
这时候如果我们有另一类算法的竞争比是 Ω ( l o g n ) \Omega(log n) Ω(logn),那么它的下限是优于上面的算法的下限的。
三、Randomised Online Algorithms
3.1 Marker Algorithm
Marker算法是最经典的随机在线算法。它的过程如下:
Classic Marker algorithm: The algorithm runs in phases. At the beginning of each phase, all elements are unmarked. When an element arrives and is already in the cache, the element is marked. If it is not in the cache, a random unmarked element is evicted, the newly arrived element is placed in the cache and is marked. Once all elements are marked, the phase ends and we unmark all of the elements. In other word, each phase ends as soon as k k k distinct elements appear.
伪代码如下:

举一个例子:
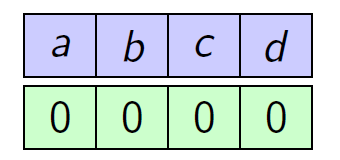
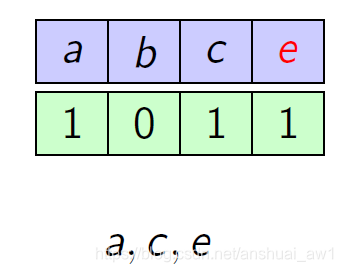

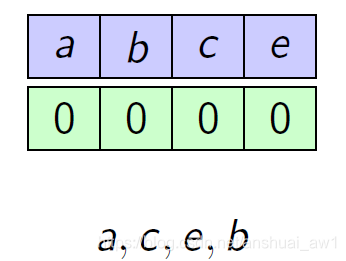
也就是加了一个对于cache中的每一个元素,加了一个marker位。然后分阶段进行分析。
在算法中,还有2个概念非常重要即clean元素和stale元素(有时,又被称为new和old,意义相同),它们的定义如下:
For the purposes of analysis, an element is called clean in phase r r r if it appears during phase r r r,
but does not appear during phase r − 1 r-1 r−1. In contrast, elements that also appeared in the previous
phase are called stale.
也就是说,clean元素是上一个阶段(有时,也称为轮,round) 没有,而这个阶段有的;而stale元素上个阶段有,这个阶段也有。
所以很显然,clean元素是必然会引起miss的。
接下来我们证明一些mark算法的性质。
3.2 The Marker algorithm is 2 H k 2H_k 2Hk-competitive.
3.2.1 marker算法的miss至多是 L H k LH_k LHk次
定理3-1:令L是总共的new元素的数目,则marker算法的miss至多是 L H k LH_k LHk次
我们先定义调和级数Harmonic number H k = 1 + 1 / 2 + 1 / 3 + … + 1 / k = O ( l o g k ) H_k= 1+1/2+1/3+…+1/k = O(log k) Hk=1+1/2+1/3+…+1/k=O(logk)
其实调和级数的确界也是 H k = Θ ( log k ) H_k = \Theta (\log k) Hk=Θ(logk),证明过程可以参考这里。
证明如下(以参考文献【5】为基础,加上自己的理解):
令 l r l_r lr为第 r r r轮(阶段)中new元素的个数。
根据new和old元素以及算法的流程。有2种情况会造成cache miss:
1、new page按照定义肯定会产生miss
2、old page在被evict后又request了,也会产生miss。这种情况较复杂。
对于第2种情况,我们分析最差的情况是,每轮先有 l r l_r lr个new都来,然后 k − l r k-l_r k−lr个old元素才来(因为每轮最多有 k k k个不同的元素来)。这里最差的意思是:反正 l r l_r lr个new迟早要来,不如要它们先全来,这样才会尽量的把old元素evict, 使得第2种情况的miss更多。
我们分析第一个old发生miss的概率,显然是: l r k \frac{l_r}{k} klr,我们可以这么想:一共有 k k k个未标记的old element,还在cache中的未标记的old有 k − l r k-l_r k−lr个,发生hit的可能是 k − l r k \frac{k-l_r}{k} kk−lr,自然发生miss的概率是 1 − k − l r k = l r k 1-\frac{k-l_r}{k}=\frac{l_r}{k} 1−kk−lr=klr
我们再仔细分析一下,如果第一个old发生了miss,那它肯定是被某个new元素驱逐了,不妨假设这个新元素是 N 2 N2 N2,那现在又来了第二个old元素 O 2 O2 O2,则 N 2 N2 N2不可能驱逐 O 2 O2 O2了(因为 N 2 N2 N2已经驱逐了 O 1 O1 O1了)。所以new元素能驱逐 O 2 O2 O2的,只剩下 l r − 1 l_r-1 lr−1个了。但是呢, O 1 O1 O1却有可能驱逐 O 2 O2 O2,所以实际上呢,能驱逐 O 2 O2 O2的元素还是 l r − 1 + 1 l_r-1+1 lr−1+1,即 l r l_r lr个。
如果第一个old发生了hit,则不会影响能驱逐 O 2 O2 O2的元素,即还是 l r l_r lr个。
所以,如果我们假设第一个old发生miss的概率是 p p p,则第二个old发生miss的概率:
= l r − 1 + 1 k − 1 p + l r k − 1 ( 1 − p ) = l r k − 1 =\frac{l_r-1+1}{k-1}p+\frac{l_r}{k-1}(1-p)=\frac{l_r}{k-1} =k−1lr−1+1p+k−1lr(1−p)=k−1lr
当然,我感觉这里这么分析更直观:在第二个old来的时候,一共有 k − 1 k-1 k−1个未标记的old element,在cache中的未标记的old有 k − l r − 1 k-l_r-1 k−lr−1个,发生hit的可能是 k − l r − 1 k − 1 \frac{k-l_r-1}{k-1} k−1k−lr−1,自然发生miss的概率是 1 − k − l r − 1 k − 1 = l r k − 1 1-\frac{k-l_r-1}{k-1}=\frac{l_r}{k-1} 1−k−1k−lr−1=k−1lr
类似地,第三个old发生miss的概率是 l r k − 2 \frac{l_r}{k-2} k−2lr
第 i i i个old发生miss的概率是 l r k − i + 1 \frac{l_r}{k-i+1} k−i+1lr
对于最后一个old页面 k − l r k-l_r k−lr,发生miss的概率是 l r k − ( k − l r ) + 1 = l r l r + 1 \frac{l_r}{k-(k-l_r)+1}=\frac{l_r}{l_r+1} k−(k−lr)+1lr=lr+1lr
所以,对于第 r r r轮来说,发生miss的期望为2种造成cache miss的累加,即有:
E = l r + l r k + l r k − 1 + l r k − 2 … … + l r l r + 1 = l r ( 1 + 1 k + 1 k − 1 + 1 k − 2 … … + 1 l r + 1 ) E=l_r+\frac{l_r}{k}+\frac{l_r}{k-1}+\frac{l_r}{k-2}……+\frac{l_r}{l_r+1}=l_r(1+\frac{1}{k}+\frac{1}{k-1}+\frac{1}{k-2}……+\frac{1}{l_r+1}) E=lr+klr+k−1lr+k−2lr……+lr+1lr=lr(1+k1+k−11+k−21……+lr+11)
其中 1 k + 1 k − 1 + 1 k − 2 … … + 1 l r + 1 = H k − H l r \frac{1}{k}+\frac{1}{k-1}+\frac{1}{k-2}……+\frac{1}{l_r+1}=H_k-H_{l_r} k1+k−11+k−21……+lr+11=Hk−Hlr
所以有 E = l r ( 1 + H k − H l r ) E=l_r(1+H_k-H_{l_r}) E=lr(1+Hk−Hlr) ≤ l r H k l_rH_k lrHk,因为 H l r H_{l_r} Hlr≥1
把所有的轮次加起来,有: E ( a l l r o u n d ) E(all round) E(allround)≤ L H k LH_k LHk
即marker算法的miss至多是 L H k LH_k LHk次,得证。
3.2.2 最优离线算法的miss至少是 L / 2 L/2 L/2次
定理3-2:令L是总共的new元素的数目,则最优离线算法的miss至少是 L / 2 L/2 L/2次
证明如下(以参考文献【5】为基础,加上自己的理解):
令 l r l_r lr为第 r r r轮(阶段)中new元素的个数。令 S O S_O SO为离线算法在cache中元素的集合;令 S M S_M SM为marker算法在cache中元素的集合,对于第 r r r轮来说,定义:
d I = ∣ S O − S M ∣ d_I=|S_O-S_M| dI=∣SO−SM∣在第 r r r轮开始时,offline算法和marker算法在cache中元素不同的个数;
d F = ∣ S O − S M ∣ d_F=|S_O-S_M| dF=∣SO−SM∣在第 r r r轮结束时,offline算法和marker算法在cache中元素不同的个数
根据new元素的定义,我们知道,在每一轮开始的时候,cache中是肯定没有new元素的(如果有的话,就违反了new元素的定义)。而offline算法在每一轮开始时,在cache中有 d I d_I dI个与mark算法不同的元素,所以至少就有 l r − d I l_r-d_I lr−dI个new元素不在offline的cache中,而new元素肯定是要发生miss的,所以offline算法至少有 l r − d I l_r-d_I lr−dI个miss发生。
offline算法还有一类cache miss,那就是对于每轮结束时。我们知道,marker算法在每轮结束时,标记缓存的内容是这轮期间请求的全部 k k k页,但是offline算法有 d F d_F dF个与marker算法不同,不同的地方肯定是要发生cache miss的,所以这种情况下offline算法至少发生 d F d_F dF个miss。
将这两种情况加起来,对于第 r r r轮有:
No. of misses ≥ m a x max max{
l r − d I l_r-d_I lr−dI, d F d_F dF} ≥ l r − d I + d F 2 \frac{l_r-d_I+d_F}{2} 2lr−dI+dF
我们又知道,第 r − 1 r-1 r−1轮的 d F d_F dF和第 r r r轮的 d I d_I dI是相同的(因为此时cache的内容没有变),所以我们累加所有的轮次就有:
No. of misses= ∑ r l r 2 \frac{\sum_{r}l_r}{2} 2∑rlr+ d F − d I 2 \frac{d_F-d_I}{2} 2dF−dI ≥ ∑ r l r 2 \frac{\sum_{r}l_r}{2} 2∑rlr= L / 2 L/2 L/2
这里 d F d_F dF是最后一轮的, d I d_I dI是第一轮的,都是常数,因此可以忽略。
得证。
3.2.3 The Marker algorithm is 2 H k 2H_k 2Hk-competitive.
结合定理3-1和3-2,以及竞争性分析的概念,不难得出 Marker algorithm is 2 H k 2H_k 2Hk-competitive,即
c ≤ L H k L / 2 = 2 H k c \le \frac{LH_k}{L/2}=2H_k c≤L/2LHk=2Hk
3.3 对于Oblivious Adversary, Randomised Online Algorithms的竞争比是 Ω ( l o g k ) \Omega(log k) Ω(logk)
3.3.1 Oblivious Adversary
我们这里先引进一个概念,叫做adversary(敌手),其实我们上面一直避开了这个较为晦涩的词语。这里解释一下:
我们之前讨论的确定性的在线算法,有一个缺点,即敌手算法总是知道在线算法在遇到某个实例时所采取的步骤,从而它可以邪恶地预设一个实例,使得在线算法陷入窘境。因而,人们提出了一种随机在线算法,它可以更好地对付敌手算法。所谓 随机算法 ,就是在执行过程中要做出随机选择的算法。显然marker算法就是这样一种随机算法。
不过请注意,当我们设计一个随机在线算法时,必须说明允许敌手算法知道在线算法什么信息。根据知道信息的不同,根据参考文献【3】,主要分为3种:
- Oblivious Adversary: The oblivious adversary has to generate a complete request sequence in advance, before any requests are served by the online algorithm. The adversary is charged the cost of the optimum offline algorithm for that sequence.
忘记的对手必须事先生成一个完整的请求序列,然后由在线算法处理任何请求。忘记的对手将被收取该序列的最佳离线算法的费用。 - Adaptive Online Adversary: This adversary may observe the online algorithm and generate the next request based on the algorithm’s (randomized) answers to all previous requests. The adversary must serve each request online, i.e., without knowing the random choices made by the online algorithm on the present or any future request.
- Adaptive Offline Adversary: This adversary also generates a request sequence adaptively. However, it is charged the optimum offline cost for that sequence.
本文不分析后面二种,只分析第一种Oblivious Adversary忘记的对手。包括前面mark算法的结论也都是针对忘记的对手 忘记的对手只知道这个序列,它不知道我们在线算法的策略,也没有办法去修改它的策略,在我们在线算法开始之后。
关于对手论证,有下面一段话。其实仔细思考一下就又说明了竞争性分析中的≤符号和 Ω \Omega Ω中的≥符号的关系。

3.3.2 Randomised Online Algorithms的竞争比是 Ω ( l o g k ) \Omega(log k) Ω(logk)
基于参考文献【3】【6】【7】,证明过程 :
先介绍一下The Yao’s Minimax theorem,

注:inf是下界,sup是上界。
其实这里是通过:

如果我们想求得随机在线算法的下界,就是求最优的确定算法在最坏的序列下的表现。也就是说,如果我们可以证明在一个分布 P P P上,即便是最差的序列,确定性的在线算法的竞争比是 Ω ( l o g k ) \Omega(log k) Ω(logk)或者 Ω ( H k ) \Omega(H_k) Ω(Hk),那么随机在线算法的竞争比也就是 Ω ( l o g k ) \Omega(log k) Ω(logk)或者 Ω ( H k ) \Omega(H_k) Ω(Hk)了。
其实我还是不知道为什么要这么算?可能是我不了解Yao的Minimax理论。有时间再了解,假设自己先懂了。
如果我们把序列划分成不重叠的phrase,每个阶段中至多有 k k k个不同的元素,那么显然,每个阶段的最优离线算法只发生1次miss。那么,确定性算法发生多少次呢?
确定性的在线算法的竞争比分析如下:
如果我们的序列集合 S S S是 k + 1 k+1 k+1个不同的元素,cache size是 k k k,那么对于随机从 S S S中取出的每一个request,不在cache中的概率是 1 k + 1 \frac{1}{k+1} k+11,即发生miss的概率为 1 k + 1 \frac{1}{k+1} k+11。那么每一个阶段有多少request?
我们已经知道,每个阶段中至多有 k k k个不同的元素,即根据彩票收集问题(Coupon Collector’s Problem),不难分析出每个阶段长度的期望 ( k + 1 ) H k (k+1)H_k (k+1)Hk,因为这相当于从 k + 1 k+1 k+1元素中挑选出 k k k个不同的元素的问题。具体:
如果阶段的第一个元素从 S S S取一个不同于以前的元素概率为 k + 1 k + 1 \frac{k+1}{k+1} k+1k+1,次数为 k + 1 k + 1 \frac{k+1}{k+1} k+1k+1;第二个元素从 S S S取一个不同于以前的元素概率为 k k + 1 \frac{k}{k+1} k+1k,次数为 k + 1 k \frac{k+1}{k} kk+1;第 k k k个元素从 S S S取一个不同于以前的元素概率为 2 k + 1 \frac{2}{k+1} k+12,次数为 k + 1 2 \frac{k+1}{2} 2k+1,所以期望总共为:
E = k + 1 k + 1 + k + 1 k + k + 1 k − 2 … … + k + 1 2 = ( k + 1 ) ( 1 k + 1 + 1 k + 1 k − 2 … … + 1 2 ) = ( k + 1 ) ( H k + 1 − 1 ) < ( k + 1 ) ( H k ) E=\frac{k+1}{k+1}+\frac{k+1}{k}+\frac{k+1}{k-2}……+\frac{k+1}{2}=(k+1)(\frac{1}{k+1}+\frac{1}{k}+\frac{1}{k-2}……+\frac{1}{2})=(k+1)(H_{k+1}-1)<(k+1)(H_{k}) E=k+1k+1+kk+1+k−2k+1……+2k+1=(k+1)(k+11+k1+k−21……+21)=(k+1)(Hk+1−1)<(k+1)(Hk),
所以确定性算法发生了 ( k + 1 ) ( H k ) 1 k + 1 = H k (k+1)(H_{k})\frac{1}{k+1}=H_{k} (k+1)(Hk)k+11=Hk次,又由于每个阶段的最优离线算法只发生1次miss,所以Randomised Online Algorithms的竞争比是 Ω ( H k ) \Omega(H_k) Ω(Hk)
注:感觉这里似乎推的有些问题,因为并非是≤号?感觉上面写错了很多地方。。。
这里暂时先停下,确实没有想明白。
参考文献【6】应该是写的最清楚的。有时间再看看吧,头疼。
参考文献【8】也不错。
参考文献
【1】 运筹学_在线算法(中科院胡晓东)
【2】CS787: Advanced Algorithms:Topic: Caching Algorithms
【3】Competitive Online Algorithms: Susanne Albers
【4】Stanford University — CS261: Optimization
【5】CSL 758: Advanced Algorithms
【6】Competitive Analysis of Paging: A Survey
【7】Randomised Online Algorithms
【9】CS880: Approximation and Online Algorithms 另外一种证明marker算法竞争分析的方法
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法