6、Flink四大基石之Window详解与详细示例(一)_flink四大基石之window详解与详细示例(一)-程序员宅基地
技术标签: flink flink 流批一体化 checkpoint # Flink专栏 flink window 大数据 flink state watermarker
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
本文主要介绍Flink的window,针对常用的window详细介绍。具体示例在下一篇进行介绍。
本文部分图片来源于互联网。
截至本篇之前,针对Flink的基本操作已经完成。通过前面的内容,可以熟练的使用Flink的基本功能,比如source、transformation、sink。从本篇开始介绍Flink的四大基石,即Windows、State、Time-watermarker和Checkpoint,本篇为第一篇,开始介绍Window。
一、Flink的window
1、window介绍
Windows是处理无限流的核心。Windows将流划分为有限大小的“buckets”,我们可以在其上进行计算。
窗口Flink程序的一般结构如下所示。第一个片段指的是键控流,而第二个片段指非键控流。可以看出,唯一的区别是对键控流的keyBy(…)调用和对非键控流变为windowAll(…)的window(…)。这也将作为页面其余部分的路线图。
流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算。Flink提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口。
在流处理应用中,数据是连续不断的,有时需要做一些聚合类的处理,例如在过去的1分钟内有多少用户点击了我们的网页。
在这种情况下,必须定义一个窗口(window),用来收集最近1分钟内的数据,并对这个窗口内的数据进行计算。
2、window API
- Keyed Windows
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
- Non-Keyed Windows
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
在上文中,方括号([…])中的命令是可选的。
这表明Flink允许您以多种不同的方式自定义窗口逻辑,使其最适合您的需求。
使用keyby的流,应该使用window方法
未使用keyby的流,应该调用windowAll方法
1)、WindowAssigner
window/windowAll 方法接收的输入是一个 WindowAssigner, WindowAssigner 负责将每条输入的数据分发到正确的 window 中,Flink提供了很多各种场景用的WindowAssigner:
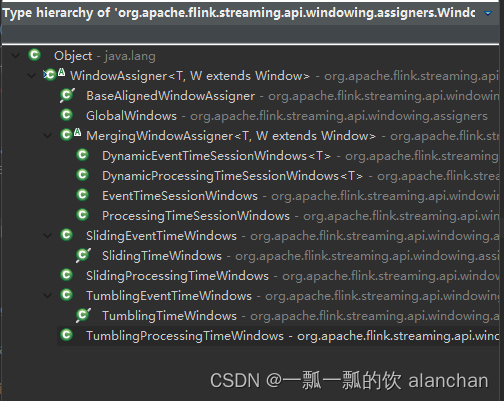
如果需要自己定制数据分发策略,则可以实现一个 class,继承自 WindowAssigner。
2)、Trigger
trigger 用来判断一个窗口是否需要被触发,每个 WindowAssigner 都自带一个默认的trigger,如果默认的 trigger 不能满足你的需求,则可以自定义一个类,继承自Trigger 即可。
- onElement()
- onEventTime()
- onProcessingTime()
此抽象类的这三个方法会返回一个 TriggerResult, TriggerResult 有如下几种可能的选择: - CONTINUE 不做任何事情
- FIRE 触发 window
- PURGE 清空整个 window 的元素并销毁窗口
- FIRE_AND_PURGE 触发窗口,然后销毁窗口
Trigger 的抽象类源码如下
package org.apache.flink.streaming.api.windowing.triggers;
import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.api.common.state.MergingState;
import org.apache.flink.api.common.state.State;
import org.apache.flink.api.common.state.StateDescriptor;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.metrics.MetricGroup;
import org.apache.flink.streaming.api.windowing.windows.Window;
import java.io.Serializable;
/**
* A {@code Trigger} determines when a pane of a window should be evaluated to emit the
* results for that part of the window.
*
* <p>A pane is the bucket of elements that have the same key (assigned by the
* {@link org.apache.flink.api.java.functions.KeySelector}) and same {@link Window}. An element can
* be in multiple panes if it was assigned to multiple windows by the
* {@link org.apache.flink.streaming.api.windowing.assigners.WindowAssigner}. These panes all
* have their own instance of the {@code Trigger}.
*
* <p>Triggers must not maintain state internally since they can be re-created or reused for
* different keys. All necessary state should be persisted using the state abstraction
* available on the {@link TriggerContext}.
*
* <p>When used with a {@link org.apache.flink.streaming.api.windowing.assigners.MergingWindowAssigner}
* the {@code Trigger} must return {@code true} from {@link #canMerge()} and
* {@link #onMerge(Window, OnMergeContext)} most be properly implemented.
*
* @param <T> The type of elements on which this {@code Trigger} works.
* @param <W> The type of {@link Window Windows} on which this {@code Trigger} can operate.
*/
@PublicEvolving
public abstract class Trigger<T, W extends Window> implements Serializable {
/**
* Called for every element that gets added to a pane. The result of this will determine
* whether the pane is evaluated to emit results.
* 每次往 window 增加一个元素的时候都会触发
* @param element The element that arrived.
* @param timestamp The timestamp of the element that arrived.
* @param window The window to which the element is being added.
* @param ctx A context object that can be used to register timer callbacks.
*/
public abstract TriggerResult onElement(T element, long timestamp, W window, TriggerContext ctx) throws Exception;
/**
* Called when a processing-time timer that was set using the trigger context fires.
* 当 processing-time timer 被触发的时候会调用
* @param time The timestamp at which the timer fired.
* @param window The window for which the timer fired.
* @param ctx A context object that can be used to register timer callbacks.
*/
public abstract TriggerResult onProcessingTime(long time, W window, TriggerContext ctx) throws Exception;
/**
* Called when an event-time timer that was set using the trigger context fires.
* 当 event-time timer 被触发的时候会调用
* @param time The timestamp at which the timer fired.
* @param window The window for which the timer fired.
* @param ctx A context object that can be used to register timer callbacks.
*/
public abstract TriggerResult onEventTime(long time, W window, TriggerContext ctx) throws Exception;
/**
* Returns true if this trigger supports merging of trigger state and can therefore
* be used with a
* {@link org.apache.flink.streaming.api.windowing.assigners.MergingWindowAssigner}.
*
* <p>If this returns {@code true} you must properly implement
* {@link #onMerge(Window, OnMergeContext)}
*/
public boolean canMerge() {
return false;
}
/**
* Called when several windows have been merged into one window by the
* {@link org.apache.flink.streaming.api.windowing.assigners.WindowAssigner}.
* 对两个 `rigger 的 state 进行 merge 操作
* @param window The new window that results from the merge.
* @param ctx A context object that can be used to register timer callbacks and access state.
*/
public void onMerge(W window, OnMergeContext ctx) throws Exception {
throw new UnsupportedOperationException("This trigger does not support merging.");
}
/**
* Clears any state that the trigger might still hold for the given window. This is called
* when a window is purged. Timers set using {@link TriggerContext#registerEventTimeTimer(long)}
* and {@link TriggerContext#registerProcessingTimeTimer(long)} should be deleted here as
* well as state acquired using {@link TriggerContext#getPartitionedState(StateDescriptor)}.
* window 销毁的时候被调用
*/
public abstract void clear(W window, TriggerContext ctx) throws Exception;
// ------------------------------------------------------------------------
/**
* A context object that is given to {@link Trigger} methods to allow them to register timer
* callbacks and deal with state.
*/
public interface TriggerContext {
/**
* Returns the current processing time.
*/
long getCurrentProcessingTime();
/**
* Returns the metric group for this {@link Trigger}. This is the same metric
* group that would be returned from {@link RuntimeContext#getMetricGroup()} in a user
* function.
*
* <p>You must not call methods that create metric objects
* (such as {@link MetricGroup#counter(int)} multiple times but instead call once
* and store the metric object in a field.
*/
MetricGroup getMetricGroup();
/**
* Returns the current watermark time.
*/
long getCurrentWatermark();
/**
* Register a system time callback. When the current system time passes the specified
* time {@link Trigger#onProcessingTime(long, Window, TriggerContext)} is called with the time specified here.
*
* @param time The time at which to invoke {@link Trigger#onProcessingTime(long, Window, TriggerContext)}
*/
void registerProcessingTimeTimer(long time);
/**
* Register an event-time callback. When the current watermark passes the specified
* time {@link Trigger#onEventTime(long, Window, TriggerContext)} is called with the time specified here.
*
* @param time The watermark at which to invoke {@link Trigger#onEventTime(long, Window, TriggerContext)}
* @see org.apache.flink.streaming.api.watermark.Watermark
*/
void registerEventTimeTimer(long time);
/**
* Delete the processing time trigger for the given time.
*/
void deleteProcessingTimeTimer(long time);
/**
* Delete the event-time trigger for the given time.
*/
void deleteEventTimeTimer(long time);
/**
* Retrieves a {@link State} object that can be used to interact with
* fault-tolerant state that is scoped to the window and key of the current
* trigger invocation.
*
* @param stateDescriptor The StateDescriptor that contains the name and type of the
* state that is being accessed.
* @param <S> The type of the state.
* @return The partitioned state object.
* @throws UnsupportedOperationException Thrown, if no partitioned state is available for the
* function (function is not part os a KeyedStream).
*/
<S extends State> S getPartitionedState(StateDescriptor<S, ?> stateDescriptor);
/**
* Retrieves a {@link ValueState} object that can be used to interact with
* fault-tolerant state that is scoped to the window and key of the current
* trigger invocation.
*
* @param name The name of the key/value state.
* @param stateType The class of the type that is stored in the state. Used to generate
* serializers for managed memory and checkpointing.
* @param defaultState The default state value, returned when the state is accessed and
* no value has yet been set for the key. May be null.
*
* @param <S> The type of the state.
* @return The partitioned state object.
* @throws UnsupportedOperationException Thrown, if no partitioned state is available for the
* function (function is not part os a KeyedStream).
* @deprecated Use {@link #getPartitionedState(StateDescriptor)}.
*/
@Deprecated
<S extends Serializable> ValueState<S> getKeyValueState(String name, Class<S> stateType, S defaultState);
/**
* Retrieves a {@link ValueState} object that can be used to interact with
* fault-tolerant state that is scoped to the window and key of the current
* trigger invocation.
*
* @param name The name of the key/value state.
* @param stateType The type information for the type that is stored in the state.
* Used to create serializers for managed memory and checkpoints.
* @param defaultState The default state value, returned when the state is accessed and
* no value has yet been set for the key. May be null.
*
* @param <S> The type of the state.
* @return The partitioned state object.
* @throws UnsupportedOperationException Thrown, if no partitioned state is available for the
* function (function is not part os a KeyedStream).
* @deprecated Use {@link #getPartitionedState(StateDescriptor)}.
*/
@Deprecated
<S extends Serializable> ValueState<S> getKeyValueState(String name, TypeInformation<S> stateType, S defaultState);
}
/**
* Extension of {@link TriggerContext} that is given to
* {@link Trigger#onMerge(Window, OnMergeContext)}.
*/
public interface OnMergeContext extends TriggerContext {
<S extends MergingState<?, ?>> void mergePartitionedState(StateDescriptor<S, ?> stateDescriptor);
}
}
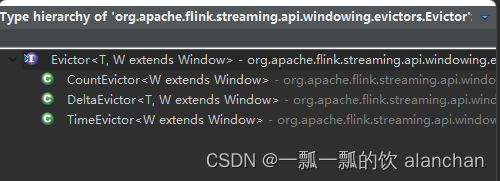
3)、Evictor
evictor 主要用于做一些数据的自定义操作,可以在执行用户代码之前,也可以在执行用户代码之后。
evictBefore() 包含要在窗口函数之前应用的eviction逻辑,而evictAfter()包含将在窗口函数之后应用的逻辑。在应用窗口函数之前eviction的元素将不会被它处理。
CountEvictor:保留窗口中最多用户指定数量的元素,并丢弃窗口缓冲区开头的剩余元素。
DeltaEvictor:取一个DeltaFunction和一个阈值,计算窗口缓冲区中最后一个元素和其余元素之间的增量,并删除增量大于或等于阈值的元素。
TimeEvictor:以毫秒为单位的间隔作为参数,对于给定的窗口,它在其元素中找到最大时间戳max_ts,并删除所有时间戳小于max_ts-interval的元素。
本接口提供了两个重要的方法,即evicBefore 和 evicAfter两个方法,具体如下:
@PublicEvolving
public interface Evictor<T, W extends Window> extends Serializable {
/**
* Optionally evicts elements. Called before windowing function.
*
* @param elements The elements currently in the pane.
* @param size The current number of elements in the pane.
* @param window The {@link Window}
* @param evictorContext The context for the Evictor
*/
void evictBefore(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
/**
* Optionally evicts elements. Called after windowing function.
*
* @param elements The elements currently in the pane.
* @param size The current number of elements in the pane.
* @param window The {@link Window}
* @param evictorContext The context for the Evictor
*/
void evictAfter(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
/**
* A context object that is given to {@link Evictor} methods.
*/
interface EvictorContext {
/**
* Returns the current processing time.
*/
long getCurrentProcessingTime();
/**
* Returns the metric group for this {@link Evictor}. This is the same metric
* group that would be returned from {@link RuntimeContext#getMetricGroup()} in a user
* function.
*
* <p>You must not call methods that create metric objects
* (such as {@link MetricGroup#counter(int)} multiple times but instead call once
* and store the metric object in a field.
*/
MetricGroup getMetricGroup();
/**
* Returns the current watermark time.
*/
long getCurrentWatermark();
}
}
Flink 提供了如下三种通用的 evictor:
- CountEvictor 保留指定数量的元素
- TimeEvictor 设定一个阈值 interval,删除所有不再 max_ts - interval 范围内的元素,其中 max_ts 是窗口内时间戳的最大值
- DeltaEvictor 通过执行用户给定的 DeltaFunction 以及预设的 theshold,判断是否删
除一个元素。
3、window的生命周期
应该属于该窗口的第一个元素到达后,就会立即创建一个窗口,并且当时间(事件或处理时间)超过其结束时间戳加上用户指定的允许延迟时,该窗口将被完全删除(请参阅允许延迟)。
Flink只保证删除基于时间的窗口,而不保证删除其他类型的窗口,例如全局窗口(请参见窗口分配器)。
例如,使用基于事件时间的窗口策略,该策略每5分钟创建一个不重叠(或滚动)的窗口,并且允许的延迟为1分钟,当时间戳位于该时间间隔内的第一个元素到达时,Flink将为12:00到12:05之间的时间间隔创建一个新窗口,并且当水印超过12:06时间戳时,它将删除该窗口。
此外,每个窗口都将有一个触发器(请参阅触发器)和一个附加的函数(ProcessWindowFunction、ReduceFunction或AggregateFunction)(请参阅窗口函数)。
该函数将包含要应用于窗口内容的计算,而触发器指定了窗口被视为准备应用该函数的条件。
触发策略可能类似于“当窗口中的元素数超过4时”,或者“当水印经过窗口末尾时”。
触发器还可以决定在创建和删除窗口之间的任何时间清除窗口的内容。在这种情况下,清除仅指窗口中的元素,而不是窗口元数据。
这意味着仍然可以向该窗口添加新数据。
除此之外,您还可以指定一个Evictor(请参见Evictor),该Evictor能够在触发器触发后以及应用该函数之前和/或之后从窗口中删除元素。
简单的说,当有第一个属于该window的元素到达时就创建了一个window,当时间或事件触发该windowremoved的时候则结束。每个window都有一个Trigger和一个Function,function用于计算,trigger用于触发window条件。同时也可以使用Evictor在Trigger触发前后对window的元素进行处理。
4、window的分类
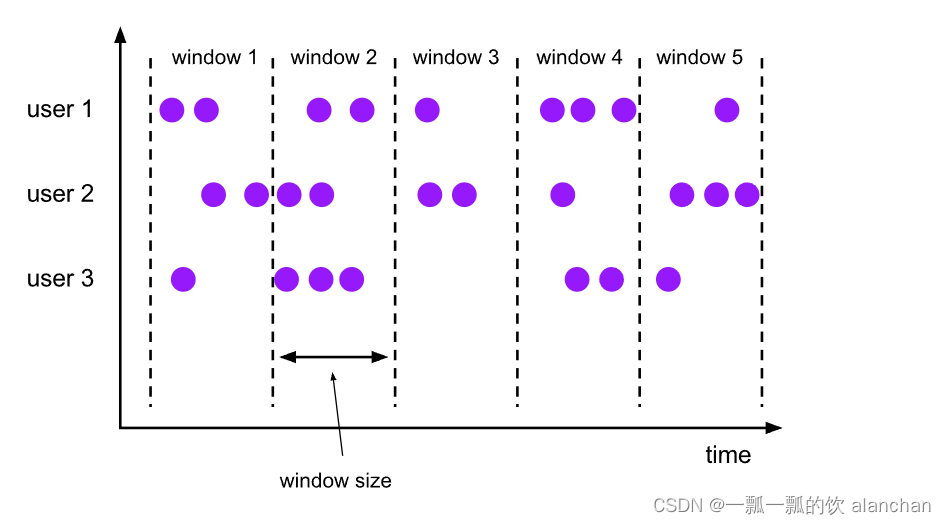
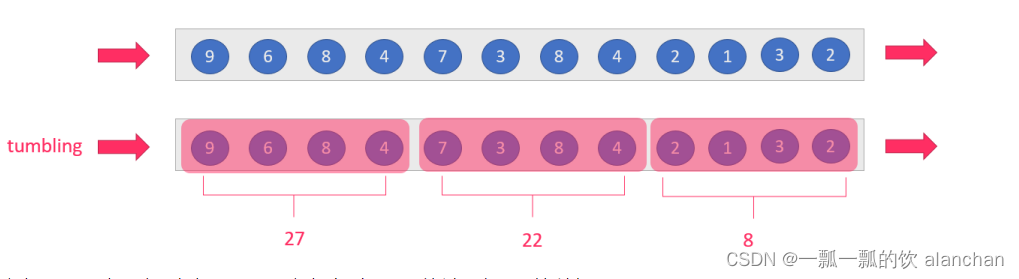
1)、Tumbling Windows
滚动窗口分配器(Tumbling windows assigner)将每个元素分配给指定窗口大小的窗口。滚动窗口具有固定大小,不会重叠。例如,如果指定大小为 5 分钟的滚动窗口,则将评估当前窗口,并且每 5 分钟启动一个新窗口,如下图所示。
示例代码
DataStream<T> input = ...;
// tumbling event-time windows
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// tumbling processing-time windows
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// daily tumbling event-time windows offset by -8 hours.
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>);
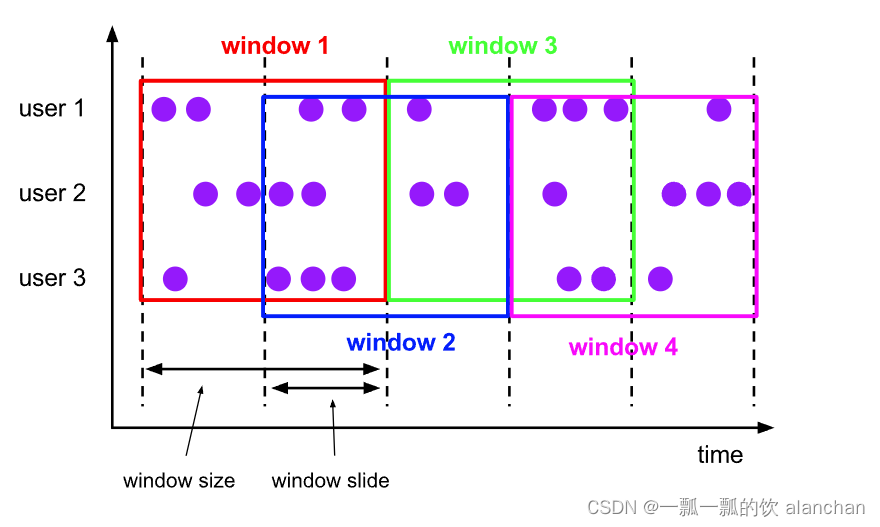
2)、Sliding Windows
滑动窗口分配器(sliding windows assigner)将元素分配给固定长度的窗口。与滚动窗口分配器类似,窗口的大小由窗口大小参数配置。窗口滑动参数控制滑动窗口的启动频率。因此,如果 sliding小于size,则滑动窗口可能会重叠。在这种情况下,元素被分配给多个窗口。例如,可以有大小为 10 分钟的窗口,该窗口滑动 5 分钟。这样,您每 5 分钟就会得到一个窗口,其中包含过去 10 分钟内到达的事件,如下图所示。
示例代码
ataStream<T> input = ...;
// sliding event-time windows
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
// sliding processing-time windows
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
// sliding processing-time windows offset by -8 hours
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation>(<window function>);
3)、Session Windows
会话窗口分配器(session windows assigner)按活动会话对元素进行分组。与滚动窗口和滑动窗口相比,会话窗口不重叠,也没有固定的开始和结束时间。相反,当会话窗口在一段时间内未收到元素时(即,当出现不活动间隙时),会话窗口将关闭。会话窗口分配器可以配置静态会话间隙或会话间隙提取器功能,该函数定义不活动时间的时间。当此时间段到期时,当前会话将关闭,后续元素将分配给新的会话窗口。
会话窗口分配器按活动会话对元素进行分组。
与滚动窗口和滑动窗口不同,会话窗口不重叠,也没有固定的开始和结束时间。
相反,当会话窗口在一定时间段内没有接收到元素时,即,当出现不活动间隙时,会话窗口将关闭。
会话窗口分配器可以配置有静态会话间隙,也可以配置有会话间隙提取器功能,该功能定义不活动时段的长度。
当这段时间到期时,当前会话将关闭,随后的元素将分配给新的会话窗口。
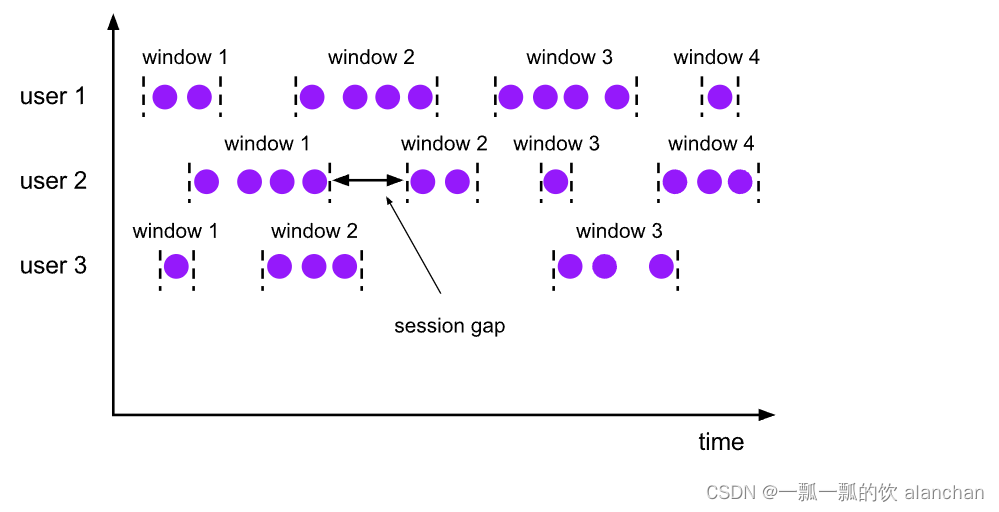
代码示例
DataStream<T> input = ...;
// event-time session windows with static gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>);
// event-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withDynamicGap((element) -> {
// determine and return session gap
}))
.<windowed transformation>(<window function>);
// processing-time session windows with static gap
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>);
// processing-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withDynamicGap((element) -> {
// determine and return session gap
}))
.<windowed transformation>(<window function>);
由于会话窗口没有固定的开始和结束,因此它们的计算方式与翻转和滑动窗口不同。在内部,会话窗口运算符为每个到达记录创建一个新窗口,如果窗口彼此靠近而不是定义的间隙,则将它们合并在一起。为了可合并,会话窗口运算符需要一个合并触发器和一个合并窗口函数,例如 ReduceFunction、AggregateFunction 或 ProcessWindowFunction。
4)、Global Windows
全局窗口分配器(global windows assigner)将具有相同键的所有元素分配给同一个全局窗口。只有自己自定义触发器的时候该窗口才能使用。否则,将不会执行任何计算,因为全局窗口没有一个自然的终点,我们可以在该端点处理聚合元素。

代码示例
DataStream<T> input = ...;
input
.keyBy(<key selector>)
.window(GlobalWindows.create())
.<windowed transformation>(<window function>);
5)、按照时间time和数量count分类
- time-window,时间窗口,根据时间划分窗口,如:每xx小时统计最近xx小时的数据
- count-window,数量窗口,根据数量划分窗口,如:每xx条/行数据统计最近xx条/行数据
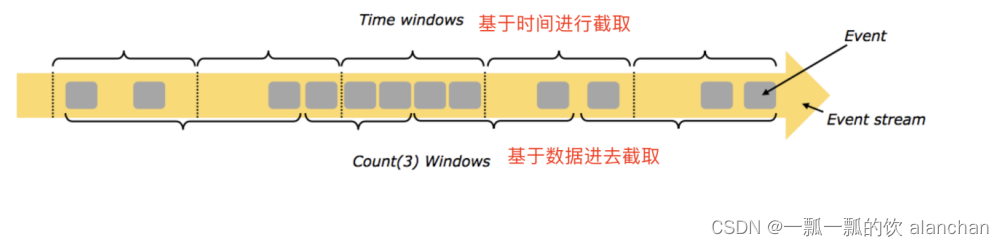
6)、按照滑动间隔slide和窗口大小size分类
-
tumbling-window,滚动窗口,size=slide,如,每隔10s统计最近10s的数据
-
sliding-window,滑动窗口,size>slide,如,每隔5s统计最近10s的数据
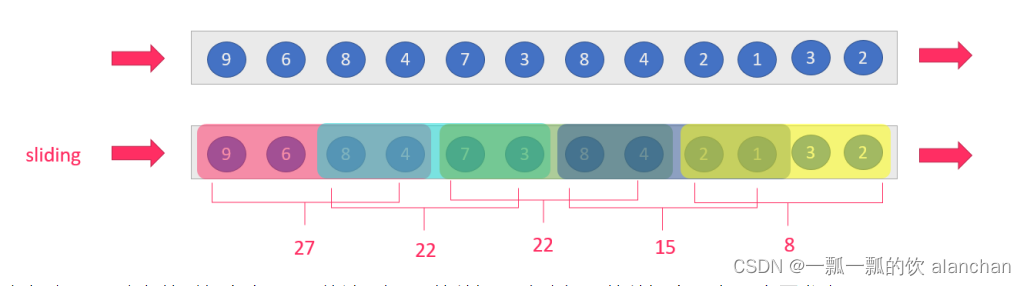
当size<slide的时候,如每隔15s统计最近10s的数据,会有数据丢失,视具体情况而定是否使用
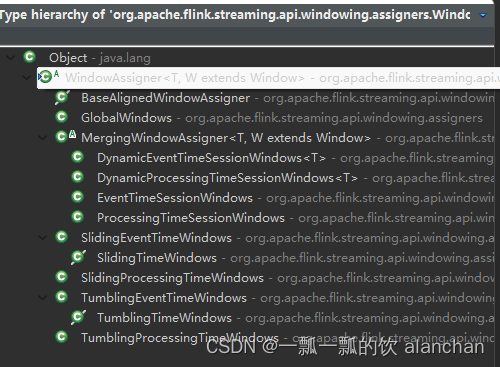
结合实际的业务应用选择适用的接口很重要,一般而言,TumblingTimeWindows、SlidingTimeWindows需要重点关注,而EventTimeSessionWindows和ProcessingTimeSessionWindows是Flink的session会话窗口,需要设置会话超时时间,如果超时则触发window计算。
5、窗口函数
定义窗口分配器(window assigner)后,需要指定要在每个窗口上执行的计算。这是 window 函数的职责,一旦系统确定窗口已准备好处理,它就用于处理每个(可能是keyed)窗口的元素。
window 函数有 ReduceFunction、AggregateFunction 或 ProcessWindowFunction 。前两个可以更有效地执行,因为 Flink 可以在每个窗口到达时增量聚合元素。ProcessWindowFunction 获取窗口中包含的所有元素的可迭代对象,以及有关元素所属窗口的其他元信息。
使用 ProcessWindowFunction 的窗口化转换不能像其他情况那样有效地执行,因为 Flink 在调用函数之前必须在内部缓冲窗口的所有元素。通过将 ProcessWindowFunction 与 ReduceFunction 或 AggregateFunction 结合使用来获取窗口元素的增量聚合和 ProcessWindowFunction 接收的其他窗口元数据,可以缓解此问题。
1)、ReduceFunction
ReduceFunction 指定如何将输入中的两个元素组合在一起以生成相同类型的输出元素。Flink 使用 ReduceFunction 以增量方式聚合窗口的元素。
代码示例-计算2个字段的和
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(new ReduceFunction<Tuple2<String, Long>> {
public Tuple2<String, Long> reduce(Tuple2<String, Long> v1, Tuple2<String, Long> v2) {
return new Tuple2<>(v1.f0, v1.f1 + v2.f1);
}
});
2)、AggregateFunction
聚合函数是 ReduceFunction 的通用版本,具有三种类型:输入类型 (IN)、累加器类型 (ACC) 和输出类型 (OUT)。输入类型是输入流中的元素类型,AggregateFunction 具有将一个输入元素添加到累加器的方法。该接口还具有用于创建初始累加器、将两个累加器合并为一个累加器以及从累加器中提取输出(OUT 类型)的方法。与 ReduceFunction 相同,Flink 将在窗口的输入元素到达时增量聚合它们。
代码示例-计算两个字段的平均值
private static class AverageAggregate
implements AggregateFunction<Tuple2<String, Long>, Tuple2<Long, Long>, Double> {
@Override
public Tuple2<Long, Long> createAccumulator() {
return new Tuple2<>(0L, 0L);
}
@Override
public Tuple2<Long, Long> add(Tuple2<String, Long> value, Tuple2<Long, Long> accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<Long, Long> accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> a, Tuple2<Long, Long> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate());
3)、ProcessWindowFunction
ProcessWindowFunction 获取一个包含窗口所有元素的 Iterable,以及一个可以访问时间和状态信息的 Context 对象,这使其能够提供比其他窗口函数更大的灵活性。这是以性能和资源消耗为代价的,因为元素不能增量聚合,而是需要在内部缓冲,直到窗口被认为准备好进行处理。
代码示例-统计个数
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(t -> t.f0)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction());
/* ... */
public class MyProcessWindowFunction
extends ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow> {
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Long>> input, Collector<String> out) {
long count = 0;
for (Tuple2<String, Long> in: input) {
count++;
}
out.collect("Window: " + context.window() + "count: " + count);
}
}
将 ProcessWindowFunction 用于简单的聚合(如计数)效率非常低。一般是将 ReduceFunction 或 AggregateFunction 与 ProcessWindowFunction 结合使用,以获取增量聚合和 ProcessWindowFunction 的添加信息。
4)、ProcessWindowFunction with Incremental Aggregation
ProcessWindowFunction 可以与 ReduceFunction 或 AggregateFunction 结合使用,以便在元素到达窗口时以增量方式聚合元素。当窗口关闭时,将向进程窗口函数提供聚合结果。这允许它以增量方式计算窗口,同时可以访问 ProcessWindowFunction 的其他窗口元信息。
1、Incremental Window Aggregation with ReduceFunction
下面的示例演示如何将增量 ReduceFunction 与 ProcessWindowFunction 结合使用,以返回窗口中的最小事件以及窗口的开始时间。
DataStream<SensorReading> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce(new MyReduceFunction(), new MyProcessWindowFunction());
// Function definitions
private static class MyReduceFunction implements ReduceFunction<SensorReading> {
public SensorReading reduce(SensorReading r1, SensorReading r2) {
return r1.value() > r2.value() ? r2 : r1;
}
}
private static class MyProcessWindowFunction
extends ProcessWindowFunction<SensorReading, Tuple2<Long, SensorReading>, String, TimeWindow> {
public void process(String key,
Context context,
Iterable<SensorReading> minReadings,
Collector<Tuple2<Long, SensorReading>> out) {
SensorReading min = minReadings.iterator().next();
out.collect(new Tuple2<Long, SensorReading>(context.window().getStart(), min));
}
}
2、Incremental Window Aggregation with AggregateFunction
下面的示例演示如何将增量聚合函数与 ProcessWindowFunction 结合使用以计算平均值,并发出键和窗口以及平均值。
DataStream<Tuple2<String, Long>> input = ...;
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate(), new MyProcessWindowFunction());
// Function definitions
/**
* The accumulator is used to keep a running sum and a count. The {@code getResult} method
* computes the average.
*/
private static class AverageAggregate
implements AggregateFunction<Tuple2<String, Long>, Tuple2<Long, Long>, Double> {
@Override
public Tuple2<Long, Long> createAccumulator() {
return new Tuple2<>(0L, 0L);
}
@Override
public Tuple2<Long, Long> add(Tuple2<String, Long> value, Tuple2<Long, Long> accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<Long, Long> accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> a, Tuple2<Long, Long> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
private static class MyProcessWindowFunction
extends ProcessWindowFunction<Double, Tuple2<String, Double>, String, TimeWindow> {
public void process(String key,
Context context,
Iterable<Double> averages,
Collector<Tuple2<String, Double>> out) {
Double average = averages.iterator().next();
out.collect(new Tuple2<>(key, average));
}
}
以上,详细的介绍了Flink的window的概念、编码示例,下一篇详细的介绍每个window的用法。
智能推荐
合肥练车记_合肥滨湖车管所科目四考场在哪里-程序员宅基地
文章浏览阅读3k次。吐槽首先吐槽一下123123以及交管所,在APP上根本看不到考试时间,想知道当天几点考试,还要当天到车管所才能看到。如果上午8点半到了,结果下午才考试,难道要等一下午吗? 我是自主预约的科目四,不知道当天什么时候考试,问了教练,教练表示也不知道,看考场那边安排。如果我当时预约周一或者周四的考试,教练是知道时间的,只可惜忘记了。为了拿到驾照,我早起一次,9点左右就到了车管所,进去之后发现我所在的驾校是下午1点钟才开始考,我此时心里一万个草泥马,,无奈,我显然是不能在这里傻等到下午1点钟再考试了。那真的太难_合肥滨湖车管所科目四考场在哪里
qemu源码编译以及启动arm应用程序和arm镜像_qemu arm源码编译-程序员宅基地
文章浏览阅读655次。源码下载git clone --recursive https://github.com/qemu/qemu.git编译源码 mkdir build cd build mkdir qemu_arm ../configure --target-list=arm-softmmu --prefix=./qemu_arm运行arm 程序运行arm镜像# 其他注意事项1.下载源..._qemu arm源码编译
2016年腾讯实习生面试技术面一面二面_技术一面没说二面-程序员宅基地
文章浏览阅读4.5k次。2016年4月10日晚上我接到初试的通知,当时也知道表哥已经内推进了微信,敬佩之余也要奋发图强,要拿一个offer回来。当晚看了一下项目源码,看了一会jvm以及android listview的缓存机制便睡觉面试。 4月11日上午11点,由于HR的过早通知,导致在师兄门口呆了半个小时。11点半准备一面,得知我做得项目其中有一个是关于华工食堂的,师兄觉得特别好玩,才透露出他是我直系大师兄_技术一面没说二面
代码属性图之-joern简易教程_joern 教程-程序员宅基地
文章浏览阅读4.4k次,点赞4次,收藏14次。一 Joern实例分析在Joern中发现了一个实例教程,本着学习的态度,尝试复现这个过程,以增加自己的经验!严谨转载,欢迎讨论!1 正常安装joern以及neo4j。2 建议下载教程中的VLC版本。cd $JOERN #joern目录mkdir tutorial; cd tutorial #创建并转入tutorialwget http://download.videolan...._joern 教程
如何修改iphone服务器,iPhone手机配置教程-程序员宅基地
文章浏览阅读1.6k次。以下以iPhone为例,设置POP3方式收发邮件。如果想使用IMAP方式,配置的时候选择IMAP协议,并把接收服务器的端口改成143接口,其它设置和POP3设置大致类似。其它智能手机或移动设备的设置步骤可参照此处。范例邮箱信息:用户邮箱账号 :[email protected]邮箱服务器地址:mail.comingchina.com(设置的时候请相应更改成自己的信息)(1)进入“设置”,点..._苹果手机可以更改服务器吗
ACM算法模板-程序员宅基地
文章浏览阅读819次,点赞18次,收藏25次。算法模板
随便推点
Python : 批量替换代码文件内容,批量移动/覆盖文件_自动更换代码-程序员宅基地
文章浏览阅读2.4w次,点赞6次,收藏20次。Python : 批量自动替换代码文件内容,批量移动/覆盖代码文件使用背景代码解析 - getCppHppFileList代码解析 - replace_StrInFile代码解析 - reName_File代码解析 -Tkinter 图形界面,完整代码使用背景在设备端GUI页面显示上,很多是通过GUI上位机软件自动生成代码,然后把生成的代码copy到开发工程中编译使用。但由于种种原因,存在生成的代码与实际工程有些不兼容的情况,则生成的代码不能直接copy使用,我这遇到的是每次都需要改动一部分代码及文_自动更换代码
使用小程序云开发添加背景音乐_小储云怎么添加音乐播放-程序员宅基地
文章浏览阅读4.4k次,点赞2次,收藏31次。使用小程序云开发添加背景音乐且实现后台播放在网上看了很多种方法,有一些对浏览器有一定的要求,于是懒癌患者想出了另一种办法首先,要在小程序里添加音频,需要在js里写一段代码:(此方法来自微信官方https://developers.weixin.qq.com/miniprogram/dev/api/media/background-audio/BackgroundAudioManager.ht..._小储云怎么添加音乐播放
spark程序打包为jar包,并且导出所有第三方依赖的jar包_spark打出的包格式-程序员宅基地
文章浏览阅读3k次。Impala 操作/读写 Kudu,使用druid连接池 Kudu 原理、API使用、代码 Kudu Java API 条件查询 spark读取kudu表导出数据为parquet文件(spark kudu parquet) kudu 导入/导出 数据 Kudu 分页查询的两种方式 map、flatMap(流的扁平化)、split 的区别 Spark(SparkSql) 写数据到 ..._spark打出的包格式
NBIOT连接阿里云控制台(MQTT连接阿里云控制台)_nb-lot上传数据到阿里云-程序员宅基地
文章浏览阅读7.3k次,点赞3次,收藏46次。首先使用MQTT工具连接阿里云平台进行测试之后再使用NBIOT连接控制台,这里主要讲解MQTT连接阿里云的步骤1、注册或登录阿里云账号 自行前往阿里云官网注册2、进入物联网界面首先点击阿里云旁边1位置的选项进入如下界面,找到物联网IOt里面的物联网平台,点击进入3、首先进入公共示例然后创建一个产品,然后在产品里面创建设备进入设备信息,找到红色箭头处的查看并点击会出来证书信息一键复制设备证书,用于生成MQTT.fx连..._nb-lot上传数据到阿里云
【Java集合系列】ArrayList源码分析_arraylist集合源码-程序员宅基地
文章浏览阅读360次。本次学习分析ArrayList;ArrayList作为util包下的常用类,因此必须学习源码的写作手法;ArrayList源码分析1 基本数据结构 private static final int DEFAULT_CAPACITY = 10; private static final Object[] EMPTY_ELEMENTDATA = {}; private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; tr_arraylist集合源码
Python基础知识——第二天_python里解包赋值为什么不能用int-程序员宅基地
文章浏览阅读933次。Python打卡第二天赋值链式赋值 ,用于同一对象赋值给多个变量;x=y=123 #相当于:x=123,y=123系列解包赋值 ,系列数据赋值给对应相同个数的变量(个数必须保持一致);a,b,c=4,5,6 #相当于a=4;b=5;c=6重点:使用系列解包赋值可以实现变量交换(常用)数据类型整型,浮点型(3.14=314e-2=314E-2),布尔型,字符串型1.整型(int)Python中,除十进制外,还有其它三种进制:—0b(0B):二进制—0o(0O):八进制_python里解包赋值为什么不能用int