正则化的作用以及L1和L2正则化的区别_l1l2正则化原理和区别-程序员宅基地
0 正则化的作用
正则化的主要作用是防止过拟合,对模型添加正则化项可以限制模型的复杂度,使得模型在复杂度和性能达到平衡。
常用的正则化方法有L1正则化和L2正则化。L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。 L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归。但是使用正则化来防止过拟合的原理是什么?L1和L2正则化有什么区别呢?
1 L1正则化与L2正则化
L1正则化的表达如下,其中 α ∣ ∣ w ∣ ∣ 1 \alpha||w||_1 α∣∣w∣∣1为L1正则化项,L1正则化是指权值向量w 中各个元素的绝对值之和。
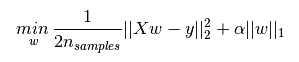
L2正则化项表达式如下,其中 α ∣ ∣ w ∣ ∣ 2 2 \alpha||w||_2^2 α∣∣w∣∣22为L2正则化项,L2正则化是指权值向量w 中各个元素的平方和然后再求平方根。
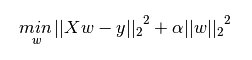
L1和L2正则化的作用:
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择,一定程度上,L1也可以防止过拟合
- L2正则化可以防止模型过拟合(overfitting)
下面看李飞飞在CS2312中给的更为详细的解释:
- L2正则化可以直观理解为它对于大数值的权重向量进行严厉惩罚,倾向于更加分散的权重向量。由于输入和权重之间的乘法操作,这样就有了一个优良的特性:使网络更倾向于使用所有输入特征,而不是严重依赖输入特征中某些小部分特征。 L2惩罚倾向于更小更分散的权重向量,这就会鼓励分类器最终将所有维度上的特征都用起来,而不是强烈依赖其中少数几个维度。。这样做可以提高模型的泛化能力,降低过拟合的风险。
- L1正则化有一个有趣的性质,它会让权重向量在最优化的过程中变得稀疏(即非常接近0)。也就是说,使用L1正则化的神经元最后使用的是它们最重要的输入数据的稀疏子集,同时对于噪音输入则几乎是不变的了。相较L1正则化,L2正则化中的权重向量大多是分散的小数字。
- 在实践中,如果不是特别关注某些明确的特征选择,一般说来L2正则化都会比L1正则化效果好。
2 L1和L2正则化的原理
上面讲到L1倾向于学得稀疏的权重矩阵,L2倾向于学得更小更分散的权重?但是L1和L2是怎样起到这样的作用的呢?背后的数学原理是什么呢?
模型的学习优化的目标是最小化损失函数,学习的结果是模型参数。在原始目标函数的基础上添加正则化相当于,在参数原始的解空间添加了额外的约束。
L1正则化对解空间添加的约束是:
∑ ∣ ∣ w ∣ ∣ 1 < = C \sum||w||_1 <= C ∑∣∣w∣∣1<=C
L2正则化对解空间添加的约束是:
∑ ∣ ∣ w ∣ ∣ 2 2 < = C \sum||w||_2^2 <= C ∑∣∣w∣∣22<=C
为了形象化的说明以假设有两个空间,以二维参数空间为例,假设有两个参数W1和W2。
则L1正则化对解空间的约束为:
∣ w 1 ∣ + ∣ w 2 ∣ < = C |w1| + |w2| <= C ∣w1∣+∣w2∣<=C
L2对解空间的约束为:
w 1 2 + w 2 2 < = C w1^2 + w2^2 <= C w12+w22<=C
在二维平面上绘制以上两个式子的图像,可得L1约束的范围是一个顶点在坐标轴上的菱形,L2约束的范围是一个圆形。

上面的图,左面是L2约束下解空间的图像,右面是L1约束下解空间的图像。
蓝色的圆圈表示损失函数的等值线。同一个圆上的损失函数值相等的,圆的半径越大表示损失值越大,由外到内,损失函数值越来越小,中间最小。
如果没有L1和L2正则化约束的话,w1和w2是可以任意取值的,损失函数可以优化到中心的最小值的,此时中心对应的w1和w2的取值就是模型最终求得的参数。
但是填了L1和L2正则化约束就把解空间约束在了黄色的平面内。黄色图像的边缘与损失函数等值线的交点,便是满足约束条件的损失函数最小化的模型的参数的解。 由于L1正则化约束的解空间是一个菱形,所以等值线与菱形端点相交的概率比与线的中间相交的概率要大很多,端点在坐标轴上,一些参数的取值便为0。L2正则化约束的解空间是圆形,所以等值线与圆的任何部分相交的概率都是一样的,所以也就不会产生稀疏的参数。
但是L2为什么倾向于产生分散而小的参数呢?那是因为求解模型的时候要求,在约束条件满足的情况下最小化损失函数, ∑ ∣ ∣ w ∣ ∣ 2 2 \sum||w||_2^2 ∑∣∣w∣∣22也应该尽可能的小。
看这样一个例子:
设输入向量x=[1,1,1,1],两个权重向量w_1=[1,0,0,0],w_2=[0.25,0.25,0.25,0.25]。那么 w 1 T x = w 2 T x = 1 w^T_1x=w^T_2x=1 w1Tx=w2Tx=1,两个权重向量都得到同样的内积,但是 w 1 w_1 w1的L2惩罚是1.0,而 w 2 w_2 w2的L2惩罚是0.25。因此,根据L2惩罚来看, w 2 w_2 w2更好,因为它的正则化损失更小。从直观上来看,这是因为 w 2 w_2 w2的权重值更小且更分散。所以L2正则化倾向于是特征分散,更小。
3 正则化参数 λ
我们一般会为正则项参数添加一个超参数λ或者α,用来平衡经验风险和结构风险(正则项表示结构风险)。
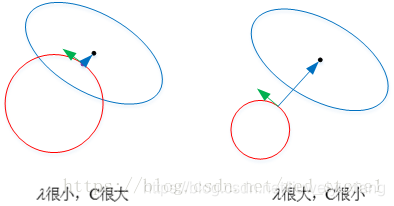 以 L2 为例,若 λ 很小,就是说我们考虑经验风险更多一些,对于结构风险没有那么重视,约束条件更为宽松。对应上文中的 C 值就很大。这时候,圆形区域很大,能够让 w 更接近中心最优解的位置。若 λ 近似为 0,相当于圆形区域覆盖了最优解位置,这时候,正则化失效,容易造成过拟合。
以 L2 为例,若 λ 很小,就是说我们考虑经验风险更多一些,对于结构风险没有那么重视,约束条件更为宽松。对应上文中的 C 值就很大。这时候,圆形区域很大,能够让 w 更接近中心最优解的位置。若 λ 近似为 0,相当于圆形区域覆盖了最优解位置,这时候,正则化失效,容易造成过拟合。
相反,若 λ 很大,约束条件更为严格,对应上文中的 C 值就很小。这时候,圆形区域很小,w 离中心最优解的位置较远。w 被限制在一个很小的区域内变化,w 普遍较小且接近 0,起到了正则化的效果。但是,λ 过大容易造成欠拟合。欠拟合和过拟合是两种对立的状态。
4 总结
- 添加正则化相当于参数的解空间添加了约束,限制了模型的复杂度
- L1正则化的形式是添加参数的绝对值之和作为结构风险项,L2正则化的形式添加参数的平方和作为结构风险项
- L1正则化鼓励产生稀疏的权重,即使得一部分权重为0,用于特征选择;L2鼓励产生小而分散的权重,鼓励让模型做决策的时候考虑更多的特征,而不是仅仅依赖强依赖某几个特征,可以增强模型的泛化能力,防止过拟合。
- 正则化参数 λ越大,约束越严格,太大容易产生欠拟合。正则化参数 λ越小,约束宽松,太小起不到约束作用,容易产生过拟合。
- 如果不是为了进行特征选择,一般使用L2正则化模型效果更好。
参考文章:
1.【通俗易懂】机器学习中 L1 和 L2 正则化的直观解释
2. 机器学习中正则化项L1和L2的直观理解
智能推荐
彻底扒光 通过智能路由器拆解看其本质-程序员宅基地
文章浏览阅读1.7k次。可以看到很多联发科的MT芯片摘自:https://net.zol.com.cn/531/5312999.html彻底扒光 通过智能路由器拆解看其本质2015-07-23 00:40:00[中关村在线 原创] 作者:陈赫|责编:白宁收藏文章 分享到 评论(24)关注智能路由器拆解的朋友们注意啦!我们已经将这五款产品彻底扒开,将主板的真容展现在了大家的眼前。网友们可以看见这些智能路由器主板的做工和用料,我们还为网友们展示了主要的电子元器件,供大家品评观赏。..._路由器拆解
Java--深入JDK和hotspot底层源码剖析Thread的run()、start()方法执行过程_jdk的源码hotspot跟jdk是分开的-程序员宅基地
文章浏览阅读2.1k次,点赞101次,收藏78次。【学习背景】今天主要是来了解Java线程Thread中的run()、start()两个方法的执行有哪些区别,会给出一个简单的测试代码样例,快速理解两者的区别,再从源码层面去追溯start()底层是如何最终调用Thread#run()方法的,个人觉得这样的学习不论对面试,还是实际编程来说都是比较有帮助的。进入正文~学习目录一、代码测试二、源码分析2.1 run()方法2.2 start()方法三、使用总结一、代码测试执行Thread的run()、start()方法的测试代码如下:public_jdk的源码hotspot跟jdk是分开的
透视俄乌网络战之一:数据擦除软件_俄乌网络战观察(一)-程序员宅基地
文章浏览阅读4.4k次,点赞90次,收藏85次。俄乌冲突中,各方势力通过数据擦除恶意软件破坏关键信息基础设施计算机的数据,达到深度致瘫的效果,同时窃取重要敏感信息。_俄乌网络战观察(一)
Maven私服仓库配置-Nexus详解_nexus maven-程序员宅基地
文章浏览阅读1.7w次,点赞23次,收藏139次。Maven 私服是一种特殊的Maven远程仓库,它是架设在局域网内的仓库服务,用来代理位于外部的远程仓库(中央仓库、其他远程公共仓库)。当然也并不是说私服只能建立在局域网,也有很多公司会直接把私服部署到公网,具体还是得看公司业务的性质是否是保密的等等,因为局域网的话只能在公司用,部署到公网的话员工在家里也可以办公使用。_nexus maven
基于AI的计算机视觉识别在Java项目中的使用 (四) —— 准备训练数据_java ocr ai识别训练-程序员宅基地
文章浏览阅读934次。我先用所有的样本数据对模型做几轮初步训练,让深度神经模型基本拟合(数万条记录的训练集,识别率到99%左右),具备初步的识别能力,这时的模型就是“直男”。相较于训练很多轮、拟合程度很高的“油腻男”,它的拟合程度较低,还是“直男愣头青”。..............._java ocr ai识别训练
hibernate 数据库类型 date没有时分秒解决_hibernate解析時間只有年月日沒有時分秒-程序员宅基地
文章浏览阅读688次。一、问题现象: 在数据库表中日期字段中存的日期光有年月日,没有时分秒。二、产生原因:三 解决办法 检查表的相应映射xml文件。 <property name="operateDate" type="Date">如果同上面所写,那问题出在 type类型上了正确写法 :<property name="operateDate" type="java.util..._hibernate解析時間只有年月日沒有時分秒
随便推点
springbbot运行无法编译成功,找不到jar包报错:Error:(3, 46) java: 程序包org.springframework.context.annotation不存在-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏2次。文章目录问题描述:解决方案:问题描述:提示:idea springbbot运行无法编译成功,找不到jar包报错E:\ideaProject\demokkkk\src\main\java\com\example\demo\config\WebSocketConfig.javaError:(3, 46) java: 程序包org.springframework.context.annotation不存在Error:(4, 46) java: 程序包org.springframework.conte_error:(3, 46) java: 程序包org.springframework.context.annotation不存在
react常见面试题_recate面试-程序员宅基地
文章浏览阅读6.4k次,点赞6次,收藏36次。1、redux中间件中间件提供第三方插件的模式,自定义拦截 action -> reducer 的过程。变为 action -> middlewares -> reducer 。这种机制可以让我们改变数据流,实现如异步 action ,action 过滤,日志输出,异常报告等功能。常见的中间件:redux-logger:提供日志输出redux-thunk:处理异步操作..._recate面试
交叉编译jpeglib遇到的问题-程序员宅基地
文章浏览阅读405次。由于要在开发板中加载libjpeg,不能使用gcc编译的库文件给以使用,需要自己配置使用另外的编译器编译该库文件。/usr/bin/ld:.libs/jaricom.o:RelocationsingenericELF(EM:40)/usr/bin/ld:.libs/jaricom.o:RelocationsingenericELF(EM:40)...._jpeg_utils.lo: relocations in generic elf (em: 8) error adding symbols: file
【办公类-22-06】周计划系列(1)“信息窗” (2024年调整版本)-程序员宅基地
文章浏览阅读578次,点赞10次,收藏17次。【办公类-22-06】周计划系列(1)“信息窗” (2024年调整版本)
SEO优化_百度seo resetful-程序员宅基地
文章浏览阅读309次。SEO全称为Search Engine Optimization,中文解释为搜索引擎优化。一般指通过对网站内部调整优化及站外优化,使网站满足搜索引擎收录排名需求,在搜索引擎中提高关键词排名,从而把精准..._百度seo resetful
回归预测 | Matlab实现HPO-ELM猎食者算法优化极限学习机的数据回归预测_猎食者优化算法-程序员宅基地
文章浏览阅读438次。回归预测 | Matlab实现HPO-ELM猎食者算法优化极限学习机的数据回归预测_猎食者优化算法