【大数据实训】—Hadoop开发环境搭建(一)-程序员宅基地
【大数据实训】—Hadoop开发环境搭建(一)
第一关、任务描述
本关任务:配置JavaJDK。
相关知识
配置开发环境是我们学习一门IT技术的第一步,Hadoop是基于Java开发的,所以我们学习Hadoop之前需要在Linux系统中配置Java的开发环境。
下载JDK
前往Oracle的官网下载JDK:点我前往Oracle的官网下载JDK
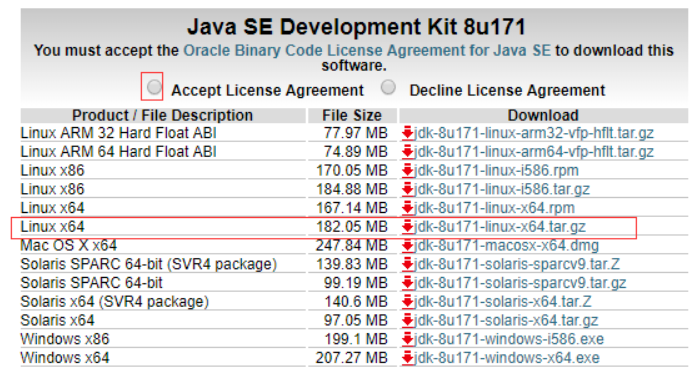
我们可以先下载到本地,然后从Windows中将文件传入到虚拟机中。
也可以复制链接地址,在Linux系统中下载,不过复制链接地址不能直接下载,因为Oracle做了限制,地址后缀需要加上它随机生成的随机码,才能下载到资源。
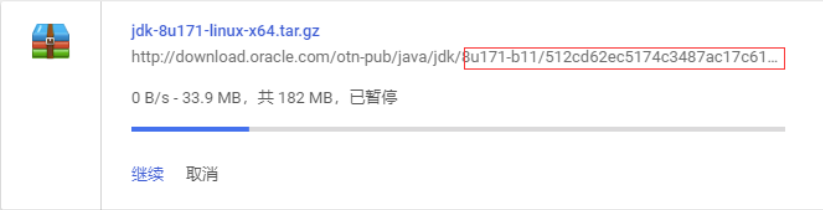
所以我们可以点击下载,然后暂停,最后在下载管理中复制链接地址就可以在Linux系统中下载啦。

因为JDK的压缩包有大概200M,所以我们已经在平台中为你下载好了JDK,不用你再去Oracle的官网去下载了,如果你要在自己的Linux系统中安装,那么还是需要下载的。
我们已经将JDK的压缩包放在系统的/opt目录下了,在命令行中切换至该目录下即可。
解压
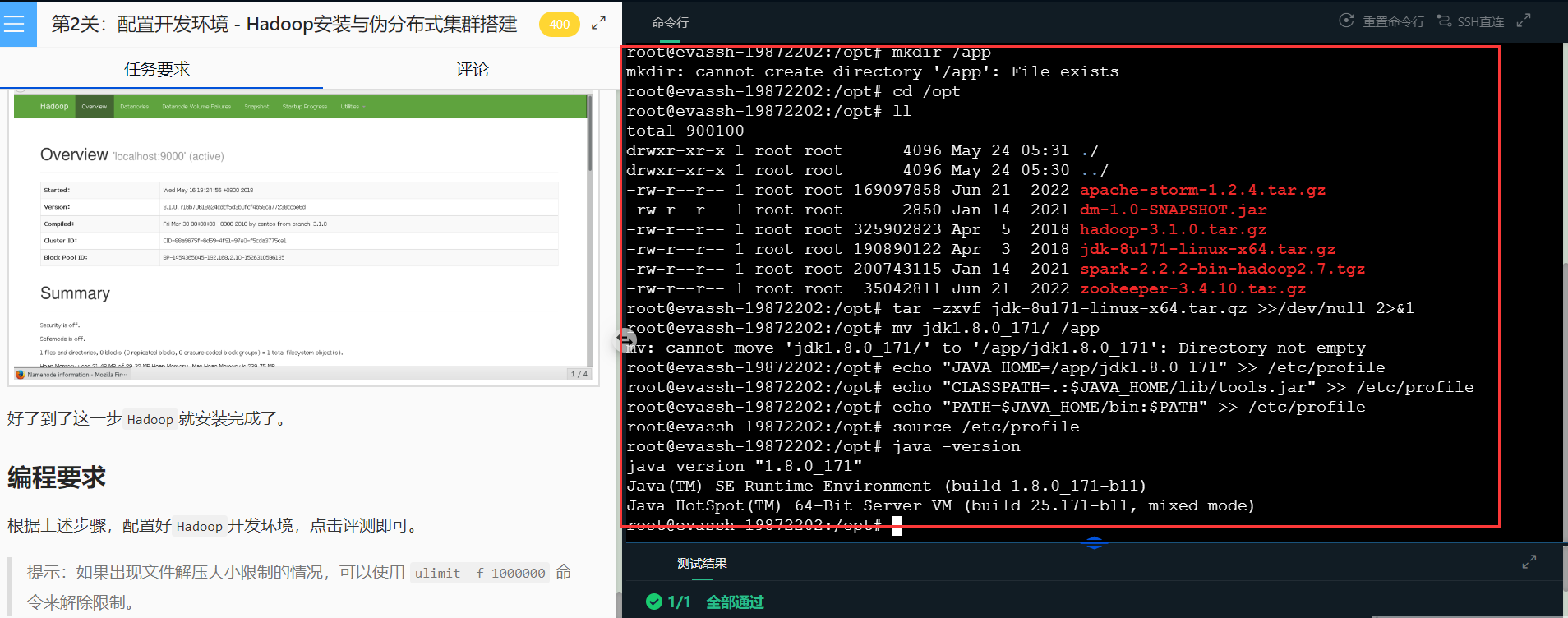
首先在右侧命令行中创建一个/app文件夹,我们之后的软件都将安装在该目录下。
命令:mkdir /app
然后,切换到/opt目录下,来查看一下提供的压缩包。

可以看到我们已经帮你下载好了JDK和Hadoop的安装文件。
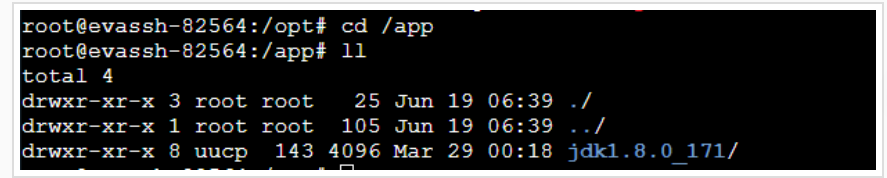
现在我们解压JDK并将其移动到/app目录下。
tar -zxvf jdk-8u171-linux-x64.tar.gz
mv jdk1.8.0_171/ /app
可以切换到/app目录下查看解压好的文件夹。
配置环境变量
解压好JDK之后还需要在环境变量中配置JDK,才可以使用,接下来就来配置JDK。
输入命令:vim /etc/profile 编辑配置文件;
在文件末尾输入如下代码(不可以有空格)。

然后,保存修改的配置文件。
保存方法:处于编辑模式下,先按 ESC 键,然后按 shift+: 之后,最后输入 wq 后,回车后就可以保存修改的配置文件。
最后:source /etc/profile使刚刚的配置生效。
测试
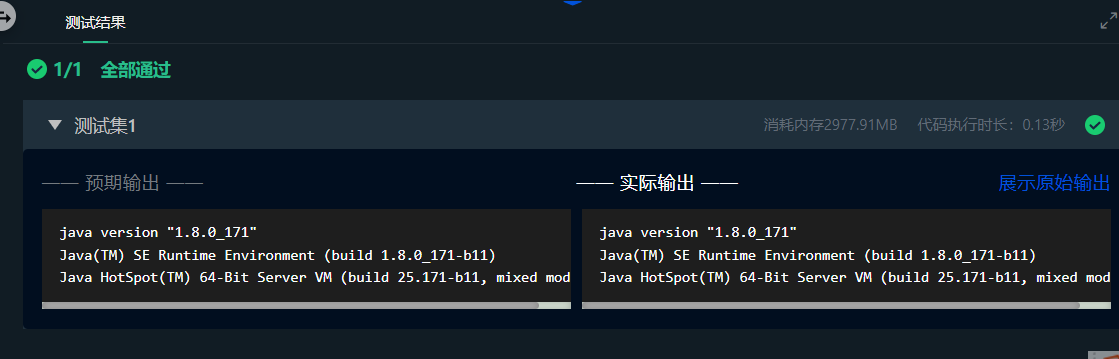
最后我们可以测试一下环境变量是否配置成功。
输入:java -version 出现如下界面代表配置成功。
编程要求
根据上述步骤完成Java开发环境的配置即可。
注意:因为下次再开启实训,环境会重置,所以最好的方式是一次性通过所有关卡。
开始配置JDK吧,go on。
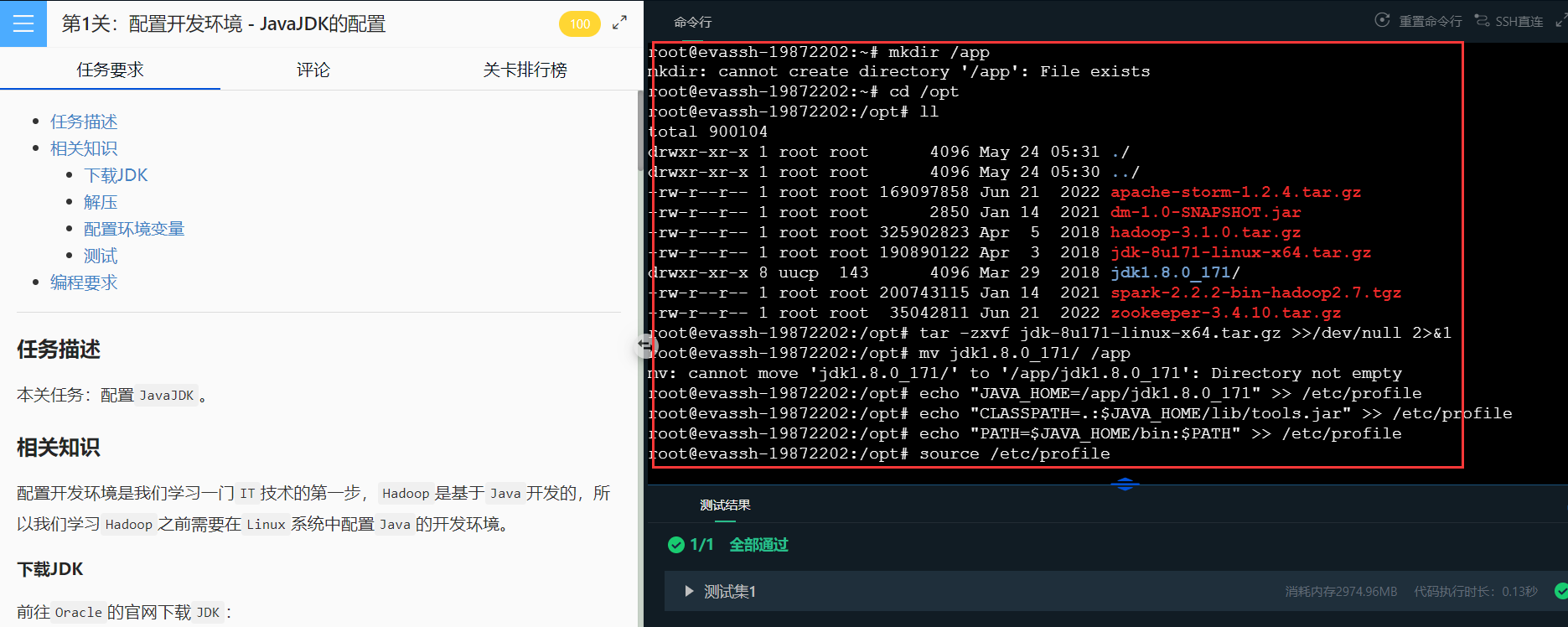
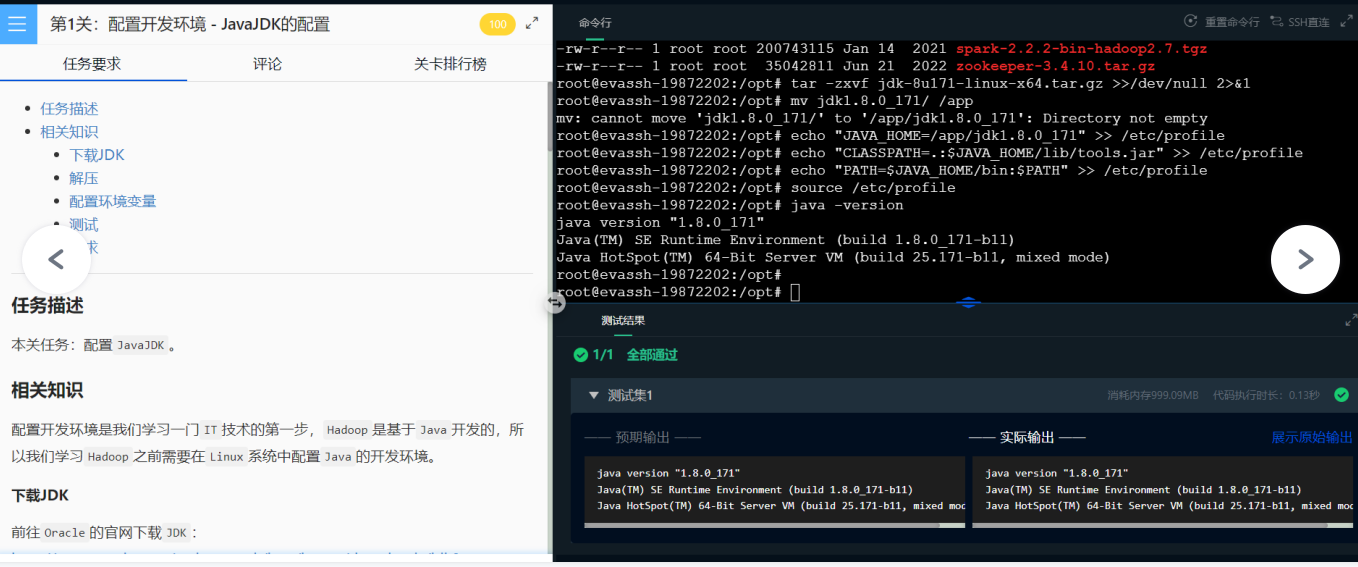
简单粗暴法:不想码字的小伙伴可以把下面的代码直接复制到命令行,配置就完成啦!!!
mkdir /app
cd /opt
ll
tar -zxvf jdk-8u171-linux-x64.tar.gz >>/dev/null 2>&1
mv jdk1.8.0_171/ /app
echo "JAVA_HOME=/app/jdk1.8.0_171" >> /etc/profile
echo "CLASSPATH=.:$JAVA_HOME/lib/tools.jar" >> /etc/profile
echo "PATH=$JAVA_HOME/bin:$PATH" >> /etc/profile
source /etc/profile
java -version
第二关
第2关:配置开发环境 - Hadoop安装与伪分布式集群搭建
任务描述
本关任务:安装配置Hadoop开发环境。
相关知识
下载Hadoop
我们去官网下载:http://hadoop.apache.org/
在平台上已经帮你下载好了(在/opt目录下),这里只是展示一下下载步骤。
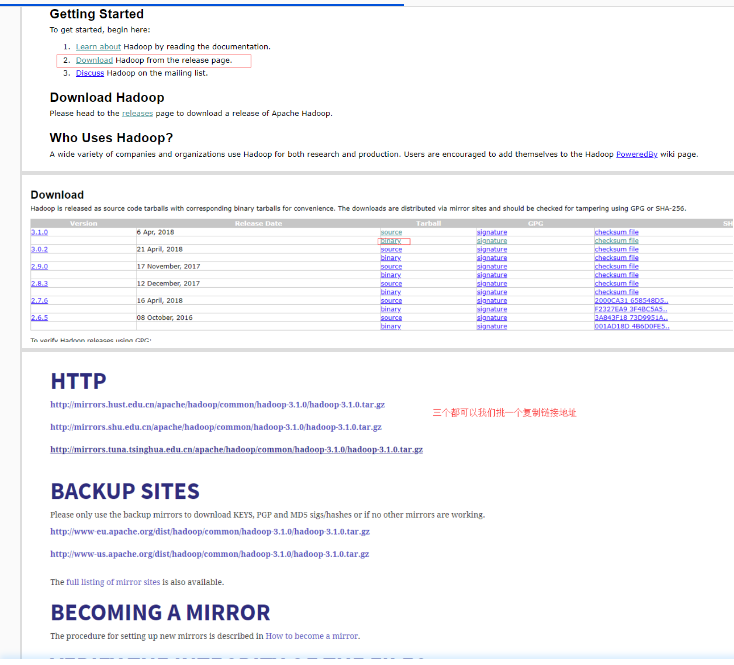
输入wget下载Hadoop;
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
如果是生产环境就需要验证文件的完整性,在这里就偷个懒了。
由于解压包有大概300M,所以我们已经预先帮你下载好了,切换到/opt目录下即可看到。
接下来解压Hadoop的压缩包,然后将解压好的文件移动到/app目录下。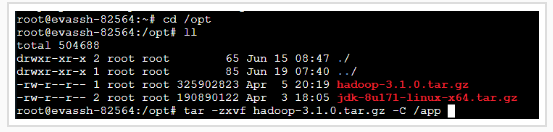
我们来切换到app目录下修改一下hadoop文件夹的名字。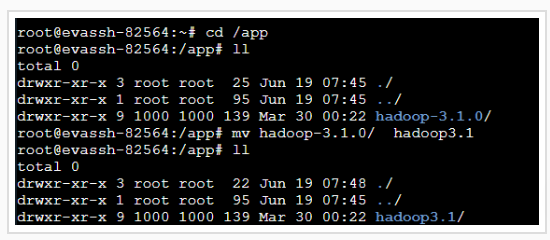
提示:如果出现文件解压大小限制的情况,可以使用 ulimit -f 1000000 命令来解除限制。
配置Hadoop环境
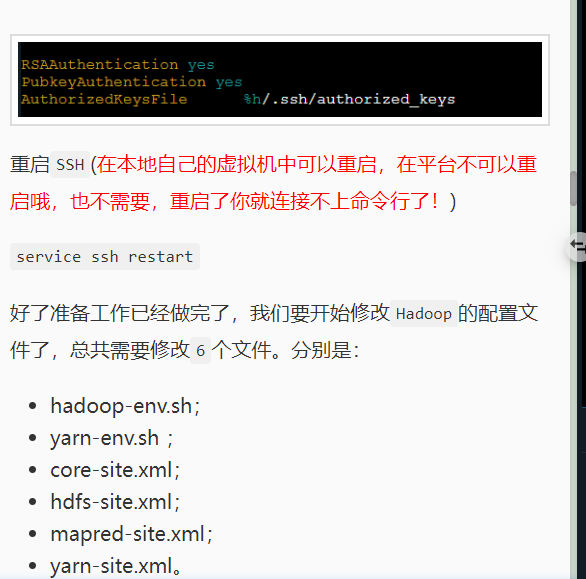
设置SSH免密登录
在之后操作集群的时候我们需要经常登录主机和从机,所以设置SSH免密登录时有必要的。
输入如下代码:
ssh-keygen -t rsa -P ''
生成无密码密钥对,询问保存路径直接输入回车,生成密钥对:id_rsa和id_rsa.pub,默认存储在~/.ssh目录下。
接下来:把id_rsa.pub追加到授权的key里面去。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
然后修改权限:chmod 600 ~/.ssh/authorized_keys


# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/app/jdk1.8.0_171

export JAVA_HOME=/app/jdk1.8.0_171

<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>

<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml文件配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml配置
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.2.10:8099</value>
<description>这个地址是mr管理界面的</description>
</property>
</configuration>
创建文件夹
我们在配置文件中配置了一些文件夹路径,现在我们来创建他们,在/usr/hadoop/目录下使用hadoop用户操作,建立tmp、hdfs/name、hdfs/data目录,执行如下命令:
mkdir -p /usr/hadoop/tmp
mkdir /usr/hadoop/hdfs
mkdir /usr/hadoop/hdfs/data
mkdir /usr/hadoop/hdfs/name
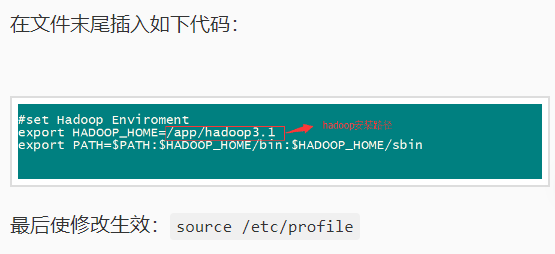
将Hadoop添加到环境变量中
vim /etc/profile
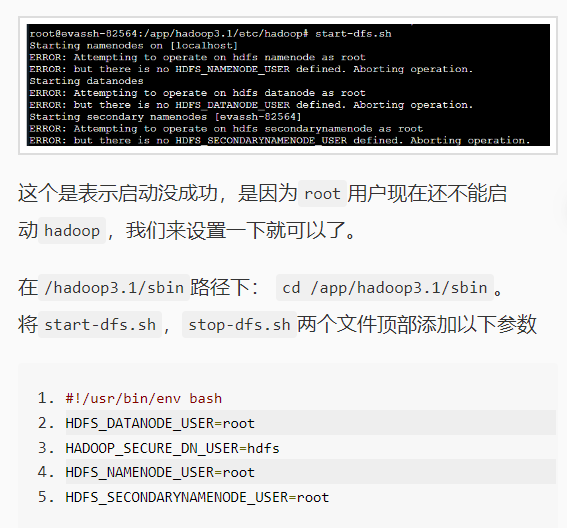
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
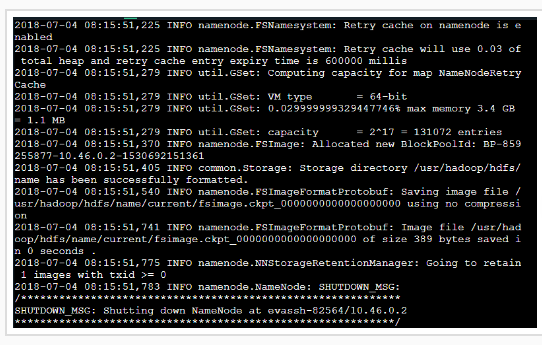
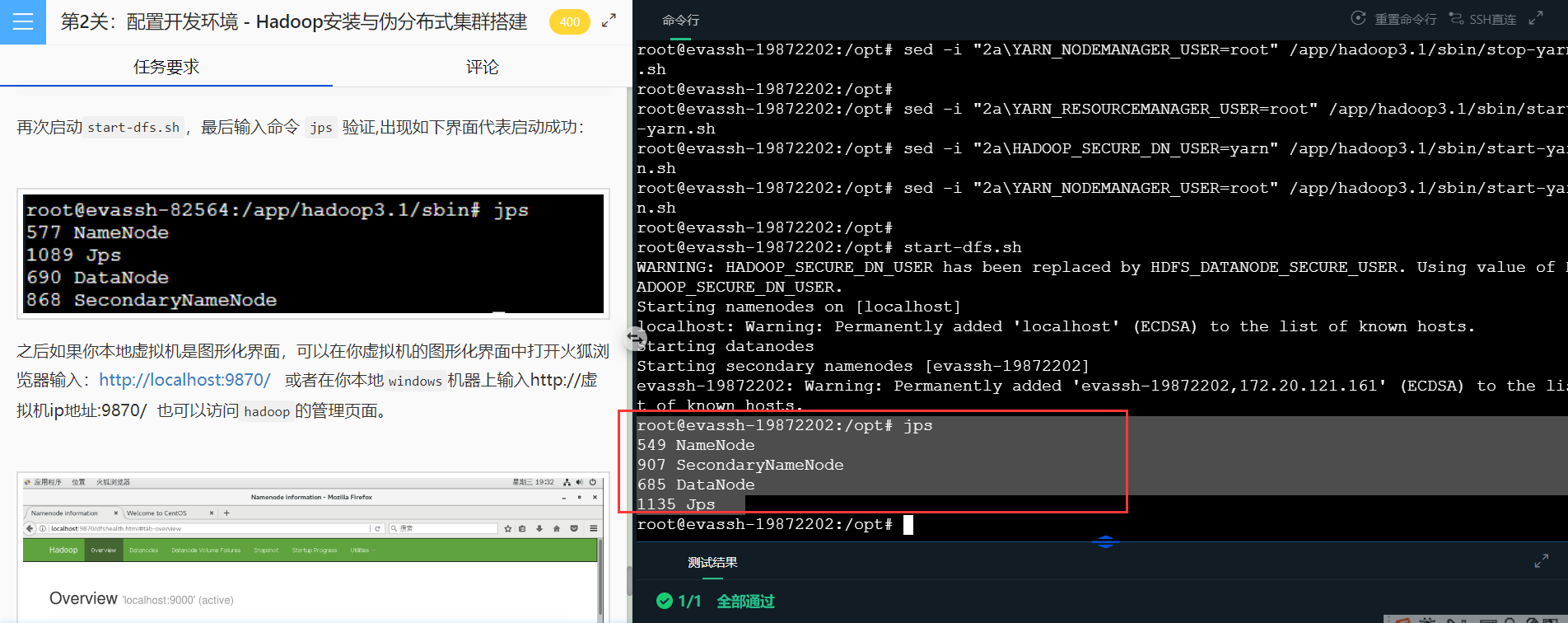
再次启动start-dfs.sh,最后输入命令 jps 验证,出现如下界面代表启动成功:
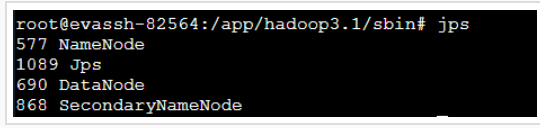
之后如果你本地虚拟机是图形化界面,可以在你虚拟机的图形化界面中打开火狐浏览器输入:http://localhost:9870/ 或者在你本地windows机器上输入http://虚拟机ip地址:9870/ 也可以访问hadoop的管理页面。
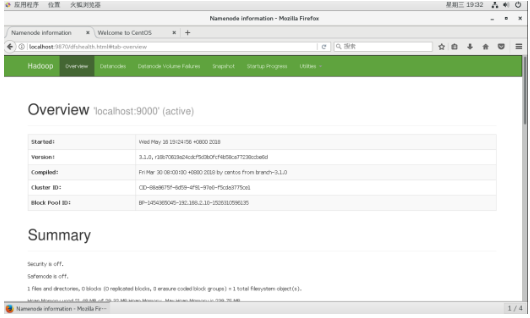
好了到了这一步Hadoop就安装完成了。
简单粗暴法:不想码字的小伙伴可以把下面的代码直接复制到命令行,配置就完成啦!!!
mkdir /app
cd /opt
ll
tar -zxvf jdk-8u171-linux-x64.tar.gz >>/dev/null 2>&1
mv jdk1.8.0_171/ /app
echo "JAVA_HOME=/app/jdk1.8.0_171" >> /etc/profile
echo "CLASSPATH=.:$JAVA_HOME/lib/tools.jar" >> /etc/profile
echo "PATH=$JAVA_HOME/bin:$PATH" >> /etc/profile
source /etc/profile
java -version
tar -zxvf /opt/hadoop-3.1.0.tar.gz -C /app >>/dev/null 2>&1
mv /app/hadoop-3.1.0 /app/hadoop3.1 2>/dev/null
ssh-keygen -t rsa -P '' <<< $'\n'
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
echo "AuthorizedKeysFile %h/.ssh/authorized_keys" >> /etc/ssh/sshd_config
echo "export JAVA_HOME=/app/jdk1.8.0_171" >> /app/hadoop3.1/etc/hadoop/hadoop-env.sh
echo "export JAVA_HOME=/app/jdk1.8.0_171" >> /app/hadoop3.1/etc/hadoop/yarn-env.sh
sed -i 's|</configuration>||g' /app/hadoop3.1/etc/hadoop/core-site.xml
sed -i 's/<configuration>//g' /app/hadoop3.1/etc/hadoop/core-site.xml
echo "<configuration>" >> /app/hadoop3.1/etc/hadoop/core-site.xml
echo "<property>" >> /app/hadoop3.1/etc/hadoop/core-site.xml
echo "<name>fs.default.name</name>" >> /app/hadoop3.1/etc/hadoop/core-site.xml
echo "<value>hdfs://localhost:9000</value>" >> /app/hadoop3.1/etc/hadoop/core-site.xml
echo "<description>HDFSURI://namenode</description>" >> /app/hadoop3.1/etc/hadoop/core-site.xml
echo "</property>" >> /app/hadoop3.1/etc/hadoop/core-site.xml
echo "<property>" >> /app/hadoop3.1/etc/hadoop/core-site.xml
echo "<name>hadoop.tmp.dir</name>" >> /app/hadoop3.1/etc/hadoop/core-site.xml
echo "<value>/usr/hadoop/tmp</value>" >> /app/hadoop3.1/etc/hadoop/core-site.xml
echo "<description>namenode</description>" >> /app/hadoop3.1/etc/hadoop/core-site.xml
echo "</property>" >> /app/hadoop3.1/etc/hadoop/core-site.xml
echo "</configuration>" >> /app/hadoop3.1/etc/hadoop/core-site.xml
sed -i 's|</configuration>||g' /app/hadoop3.1/etc/hadoop/hdfs-site.xml
sed -i 's/<configuration>//g' /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "<configuration>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "<property>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "<name>dfs.name.dir</name>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "<value>/usr/hadoop/hdfs/name</value>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "<description>namenode</description>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "</property>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "<property>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "<name>dfs.data.dir</name>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "<value>/usr/hadoop/hdfs/data</value>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "<description>datanode</description>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "</property>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "<property>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "<name>dfs.replication</name>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "<value>1</value>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "</property>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
echo "</configuration>" >> /app/hadoop3.1/etc/hadoop/hdfs-site.xml
sed -i 's|</configuration>||g' /app/hadoop3.1/etc/hadoop/mapred-site.xml
sed -i 's/<configuration>//g' /app/hadoop3.1/etc/hadoop/mapred-site.xml
echo "<configuration>" >> /app/hadoop3.1/etc/hadoop/mapred-site.xml
echo "<property>" >> /app/hadoop3.1/etc/hadoop/mapred-site.xml
echo "<name>mapreduce.framework.name</name>" >> /app/hadoop3.1/etc/hadoop/mapred-site.xml
echo "<value>yarn</value>" >> /app/hadoop3.1/etc/hadoop/mapred-site.xml
echo "</property>" >> /app/hadoop3.1/etc/hadoop/mapred-site.xml
echo "</configuration>" >> /app/hadoop3.1/etc/hadoop/mapred-site.xml
sed -i 's|</configuration>||g' /app/hadoop3.1/etc/hadoop/yarn-site.xml
sed -i 's/<configuration>//g' /app/hadoop3.1/etc/hadoop/yarn-site.xml
echo "<configuration>" >> /app/hadoop3.1/etc/hadoop/yarn-site.xml
echo "<property>" >> /app/hadoop3.1/etc/hadoop/yarn-site.xml
echo "<name>yarn.nodemanager.aux-services</name>" >> /app/hadoop3.1/etc/hadoop/yarn-site.xml
echo "<value>mapreduce_shuffle</value>" >> /app/hadoop3.1/etc/hadoop/yarn-site.xml
echo "</property>" >> /app/hadoop3.1/etc/hadoop/yarn-site.xml
echo "<property>" >> /app/hadoop3.1/etc/hadoop/yarn-site.xml
echo "<name>yarn.resourcemanager.webapp.address</name>" >> /app/hadoop3.1/etc/hadoop/yarn-site.xml
echo "<value>192.168.2.10:8099</value>">> /app/hadoop3.1/etc/hadoop/yarn-site.xml
echo "<description></description>" >> /app/hadoop3.1/etc/hadoop/yarn-site.xml
echo "</property>" >> /app/hadoop3.1/etc/hadoop/yarn-site.xml
echo "</configuration>" >> /app/hadoop3.1/etc/hadoop/yarn-site.xml
mkdir -p /usr/hadoop/tmp
mkdir /usr/hadoop/hdfs
mkdir /usr/hadoop/hdfs/data
mkdir /usr/hadoop/hdfs/name
echo "export HADOOP_HOME=/app/hadoop3.1" >> /etc/profile
echo "export PATH=\$PATH:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin" >> /etc/profile
source /etc/profile
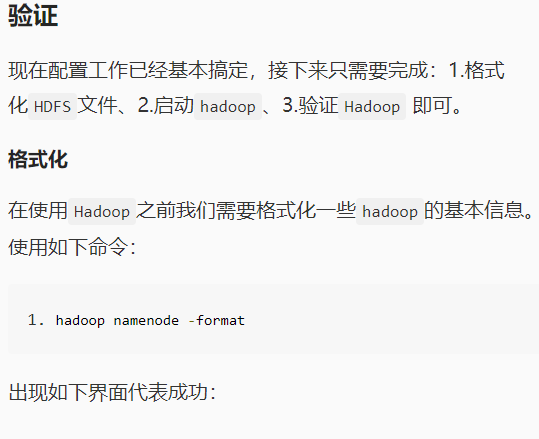
hadoop namenode -format
start-yarn.sh
sed -i "2a\HDFS_DATANODE_USER=root" /app/hadoop3.1/sbin/start-dfs.sh
sed -i "2a\HADOOP_SECURE_DN_USER=hdfs" /app/hadoop3.1/sbin/start-dfs.sh
sed -i "2a\HDFS_NAMENODE_USER=root" /app/hadoop3.1/sbin/start-dfs.sh
sed -i "2a\HDFS_SECONDARYNAMENODE_USER=root" /app/hadoop3.1/sbin/start-dfs.sh
sed -i "2a\HDFS_DATANODE_USER=root" /app/hadoop3.1/sbin/stop-dfs.sh
sed -i "2a\HADOOP_SECURE_DN_USER=hdfs" /app/hadoop3.1/sbin/stop-dfs.sh
sed -i "2a\HDFS_NAMENODE_USER=root" /app/hadoop3.1/sbin/stop-dfs.sh
sed -i "2a\HDFS_SECONDARYNAMENODE_USER=root" /app/hadoop3.1/sbin/stop-dfs.sh
sed -i "2a\YARN_RESOURCEMANAGER_USER=root" /app/hadoop3.1/sbin/stop-yarn.sh
sed -i "2a\HADOOP_SECURE_DN_USER=yarn" /app/hadoop3.1/sbin/stop-yarn.sh
sed -i "2a\YARN_NODEMANAGER_USER=root" /app/hadoop3.1/sbin/stop-yarn.sh
sed -i "2a\YARN_RESOURCEMANAGER_USER=root" /app/hadoop3.1/sbin/start-yarn.sh
sed -i "2a\HADOOP_SECURE_DN_USER=yarn" /app/hadoop3.1/sbin/start-yarn.sh
sed -i "2a\YARN_NODEMANAGER_USER=root" /app/hadoop3.1/sbin/start-yarn.sh
start-dfs.sh
jps
如果还是有不明白的小伙伴欢迎评论区留言!!!
智能推荐
CentOS6.7+Mysql5.5.54的rpm安装步骤_mysql-5.5.54-1.linux2.6.x86_64.rpm-bundle.tar-程序员宅基地
文章浏览阅读954次。本次安装Mysql使用的是rpm安装包,可在官网下载。 mysql: MySQL-5.5.54-1.linux2.6.x86_64 linux:CentOS6.7 虚拟机:VMWare12 切换到root用户下 1、首先运行一下两行代码安装必要的依赖,我第一次没有这样做,后续安装会提示缺少perl的依赖等信息yum -y install gcc gcc-c++_mysql-5.5.54-1.linux2.6.x86_64.rpm-bundle.tar
ArcGIS提取影像边界-程序员宅基地
文章浏览阅读1w次,点赞3次,收藏61次。ArcGIS提取影像边界方法1ArcToolbox → 3D Analyst Tools → 转换 → 由栅格转出 → 栅格范围方法2ArcToolbox → 转换工具 → 由栅格转出 → 栅格转面 (这个方法转的面是:栅格中相同值的区域转一个面)方法3利用镶嵌数据集Footprint图层的方法来获取step 1:新建文件型地理数据库test.gdbstep 2:在test.gdb中创建镶嵌数据集Mosaic Datasetstep 3:向镶嵌数据集中添加栅格影像.
【元壤教育AI提示工程系列】『KeepChatGPT教程』轻松解决ChatGPT网络报错,畅享无忧沟通!_! something went wrong. if this issue persists ple-程序员宅基地
文章浏览阅读4.2k次,点赞2次,收藏9次。我们使用ChatGPT时,总是因为网络魔法不力的原因导致页面总是报错,如下图所示:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v8QeslNn-1682088798331)(https://file.liyuechun.com/%E6%8F%92%E4%BB%B6.gif)]享受免费的,它代表着你的AI体验发生了骤变:喜欢暗调的朋友可以鼠标移到选择修改为:step one:step two:**step four:**Tampermonkey 搜索,并将 Tamperm_! something went wrong. if this issue persists please contact us through our
3万字智慧交通数字化建设方案_智慧交通中心数字化建设技术方案-程序员宅基地
文章浏览阅读422次。目 录第一章 系统架构 31.1短信系统 41.2数据交换系统 51.3地理信息基础支撑平台 51.4身份及权限管理系统 6第二章 综合管理平台 72.1综合运输监管系统 72.2行业监督管理系统 122.3安全生产监管系统 162.4固定资产管理系统 182.5电子监察系统 192.6行政执法系统 22第三章 公众服务平台 233.1智能手机交通信息服务 233.2出行服务系统 243.3在线呼叫系统 253.4联网售票系统 273.5停车场诱导系统 283.6物流_智慧交通中心数字化建设技术方案
计算机课程教学辅助系统小程序 免费赠送项目完整源码,可做计算机毕业设计JAVA、PHP、爬虫、APP、小程序、C#、C++、python、数据可视化、大数据、全套文案等-程序员宅基地
文章浏览阅读92次。计算机课程教学辅助系统小程序的设计主要是对系统所要实现的功能进行详细考虑,确定所要实现的功能后进行界面的设计,在这中间还要考虑如何可以更好的将功能及页面进行很好的结合,方便用户可以很容易明了的找到自己所需要的信息,还有系统平台后期的可操作性,通过对信息内容的详细了解进行技术的开发。
了解微内核_微内核谁开发的-程序员宅基地
文章浏览阅读4.4k次。网络上不断地出现微内核OS的概念。特别是华为的鸿蒙OS 将采用微内核,更激发了对微内核的热情。其实Google Fuchsia OS 也采用了微内核Zircon。收集了一些内容,帮助自己理解什么是微内核。术语微内核(Microkernel)在微内核中,大部分内核都作为单独的进程在特权状态下运行,他们通过消息传递进行通讯。在典型情况下,每个概念模块都有一个进程。因此,假如在设计中有一个系..._微内核谁开发的
随便推点
【图文详细 】Kafka消息队列——kafka 集群部署_kafka集群入口-程序员宅基地
文章浏览阅读414次。5.1、Kafka 初体验 单机 Kafka 试玩 官网网址:http://kafka.apache.org/quickstart中文官网:http://kafka.apachecn.org/quickstart.html 5.2、集群部署的基本流程总结 1、下载安装包2、解压安装包到对应的目录3、修改配置文件4、分发安装包5、启动集群,进行验证 5.3、集群部..._kafka集群入口
golang动态限制并发数量_golang 限制最大并发-程序员宅基地
文章浏览阅读2.2k次。golang动态控制并发数量_golang 限制最大并发
线段树的基本知识-程序员宅基地
文章浏览阅读175次。好的博客:笨蛋花的小窝qwq一、什么是线段树- 线段树是表示区间及线段的树什么是区间,什么又是线段呢?这里有图- 这样的一棵树,可以解决区间的覆盖问题。例题- 输入m条线段,问这m条线段被覆盖的面积有多大。Sample Input1 23 41 72 13Sample Output13那么这道题怎么做呢?方法一:模拟(容易爆)方法二:首先,由于1-13这个区间跨...
IOS 键盘的显示与关闭-程序员宅基地
文章浏览阅读170次。为什么80%的码农都做不了架构师?>>> ..._双击显示键盘 ios
Neo4j数据导入的几种方式总结_neo4j导入数据-程序员宅基地
文章浏览阅读8k次。1. 通过Cypher语法直接创建该方法适合于数据量小的情况下:例如:create(n:ability {name:"沟通"})create(m:train {name:"培训"})create(n)-[r0:has]->(a:method {name:"交流"})create(n)-[r1:has]->(b:method {name:"会议"})create(n)-..._neo4j导入数据
EASY UI tree如何根据部分值来选中checkbox_ftvedos-程序员宅基地
文章浏览阅读7.1w次。首先tree需要设置checkbox:true _ftvedos