Sqoop 从入门到精通_李昊哲小课-程序员宅基地
技术标签: Java 数据分析 sqoop hadoop 大数据
Sqoop
Sqoop 架构解析
概述
Sqoop是Hadoop和关系数据库服务器之间传送数据的一种工具。它是用来从关系数据库如:MySQL,Oracle到Hadoop的HDFS,并从Hadoop的文件系统导出数据到关系数据库。
传统的应用管理系统,也就是与关系型数据库的使用RDBMS应用程序的交互,是产生大数据的来源之一。这样大的数据,由关系数据库生成的,存储在关系数据库结构关系数据库服务器。
当大数据存储器和分析器,如MapReduce, Hive, HBase, Cassandra, Pig等,Hadoop的生态系统等应运而生图片,它们需要一个工具来用的导入和导出的大数据驻留在其中的关系型数据库服务器进行交互。在这里,Sqoop占据着Hadoop生态系统提供关系数据库服务器和Hadoop HDFS之间的可行的互动。
Sqoop:“SQL 到 Hadoop 和 Hadoop 到SQL”
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
下图描述了Sqoop的工作流程。
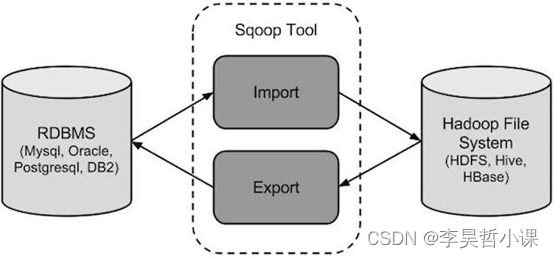
Sqoop导入
导入工具从RDBMS到HDFS导入单个表。表中的每一行被视为HDFS的记录。所有记录被存储在文本文件的文本数据或者在Avro和序列文件的二进制数据。
Sqoop导出
导出工具从HDFS导出一组文件到一个RDBMS。作为输入到Sqoop文件包含记录,这被称为在表中的行。那些被读取并解析成一组记录和分隔使用用户指定的分隔符。
sqoop1与sqoop2对比
两代之间是两个完全不同的版本,不兼容
sqoop1:1.4.x
sqoop2:1.99.x
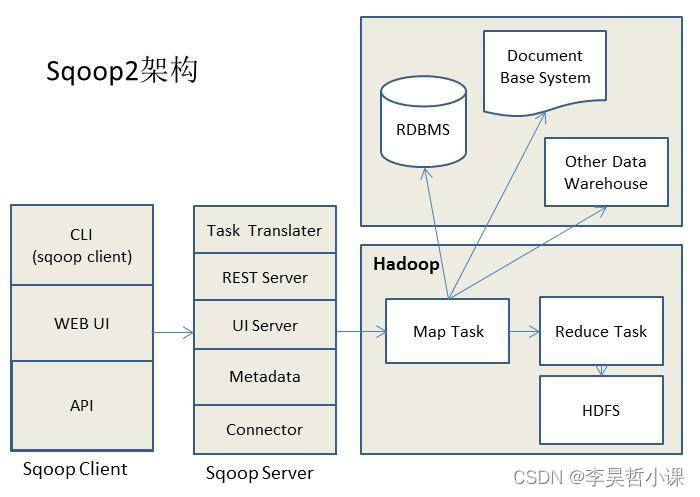
sqoop2比sqoop1的改进
(1) 引入sqoop server,集中化管理connector等
(2) 多种访问方式:CLI,Web UI,REST API
(3) 引入基于角色 的安全机制

Sqoop1
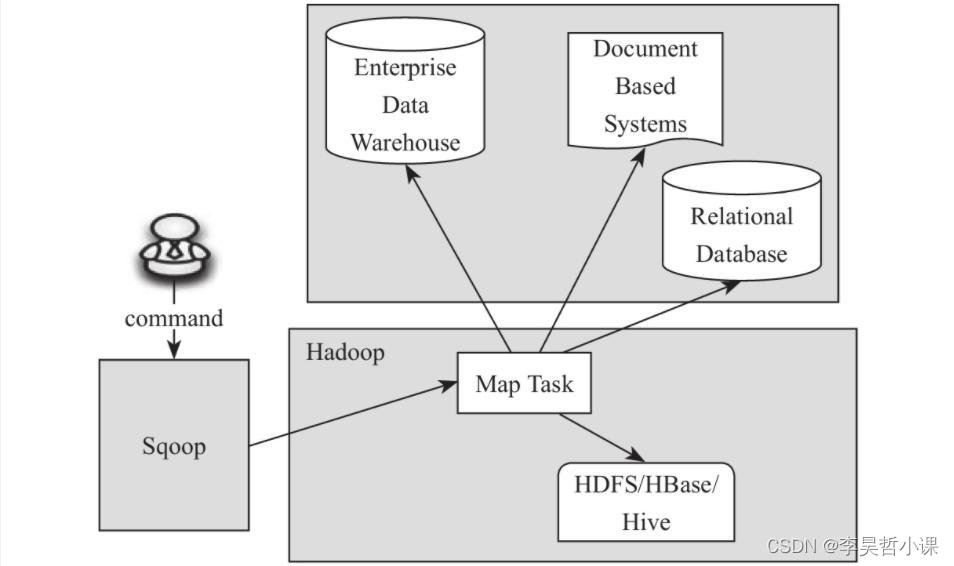
Sqoop2
Sqoop1安装
wget http://archive.apache.org/dist/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop-1
vim /etc/profile/my_env.sh
export HCAT_HOME=/opt/soft/hive-3/hcatalog
export SQOOP_HOME=/opt/soft/sqoop-1
export PATH=$PATH:$HCAT_HOME/bin:$SQOOP_HOME/bin
cd sqoop-1/conf/
cp sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
export HADOOP_COMMON_HOME=/opt/soft/hadoop-3
export HADOOP_MAPRED_HOME=/opt/soft/hadoop-3
export HIVE_HOME=/opt/soft/hive-3
export ZOOKEEPER_HOME=/opt/soft/zookeeper-3
export ZOOCFGDIR=/opt/soft/zookeeper-3/conf
# 上传
commons-lang-2.6.jar
hive-common-3.1.3.jar
mysql-connector-j-8.0.33.jar
protobuf-java-3.22.2.jar
# 到lib目录
Sqoop1案例
# 以上导入到hdfs中
sqoop import
--connect jdbc:mysql://ip:3306/databasename #指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名
--table tablename #要读取数据库database中的表名
--username root #用户名
--password 123456 #密码
--target-dir /path #指的是HDFS中导入表的存放目录(注意:是目录)
--fields-terminated-by '\t' #设定导入数据后每个字段的分隔符,默认;分隔
--lines-terminated-by '\n' #设定导入数据后每行的分隔符
-m 1 #并发的map数量1,如果不设置默认启动4个map task执行数据导入,则需要指定一个列来作为划分map task任务的依据
-- where ’查询条件‘ #导入查询出来的内容,表的子集
--incremental append #增量导入
--check-column:column_id #指定增量导入时的参考列
--last-value:num #上一次导入column_id的最后一个值
--null-string ‘’ #导入的字段为空时,用指定的字符进行替换
# 导入到hive
--hive-import
--hive-overwrite #可以多次写入
--hive-database databasename #创建数据库,如果数据库不存在的必须写,默认存放在default中
--create-hive-table #sqoop默认自动创建hive表
--delete-target-dir #删除中间结果数据目录
--hive-table tablename #创建表名
4. 导入所有的表放到hdfs中:
sqoop import-all-tables --connect jdbc:mysql://ip:3306/库名 --username 用户名 --password 密码 --target-dir 导入存放的目录
5. 导出(目标表必须在mysql数据库中已经建好,数据存放在hdfs中):
sqoop export
--connect jdbs:mysql://ip:3600/库名 #指定JDBC的URL 其中database指的是(Mysql或者Oracle)中的数据库名
--username用户名 #数据库的用户名
--password密码 #数据库的密码
--table表名 #需要导入到数据库中的表名
--export-dir导入数据的名称 #hdfs上的数据文件
--fields-terminated-by '\t' #HDFS中被导出的文件字段之间的分隔符
--lines-terminated-by '\n' #设定导入数据后每行的分隔符
--m 1 #并发的map数量1,如果不设置默认启动4个map task执行数据导入,则需要指定一个列来作为划分map task任务的依据
--incremental append #增量导入
--check-column:column_id #指定增量导入时的参考列
--last-value:num #上一次导入column_id的最后一个值
--null-string ‘’ #导出的字段为空时,用指定的字符进行替换
6. 创建和维护sqoop作业:sqoop作业创建并保存导入和导出命令。
A.创建作业:
sqoop job --create作业名 -- import --connect jdbc:mysql://ip:3306/数据库 --username 用户名 --table 表名 --password 密码 --m 1 --target-dir 存放目录
注意加粗的地方是有空格的
B. 验证作业(显示已经保存的作业):
sqoop job --list
C. 显示作业详细信息:
sqoop job --show作业名称
D.删除作业:
sqoop job --delete作业名
E. 执行作业:
sqoop job --exec作业
7. eval:它允许用户针对各自的数据库服务器执行用户定义的查询,并在控制台中预览结果,可以使用期望导入结果数据。
A.选择查询:
sqoop eval -connect jdbc:mysql://ip:3306/数据库 --username 用户名 --password 密码 --query ”select * from emp limit 1“
查看指定MySQL8数据库涉及的库
sqoop list-databases \
--connect jdbc:mysql://spark03:3306?characterEncoding=UTF-8 \
--username root --password 'Lihaozhe!!@@1122'
查看指定MySQL8数据库涉及的表
sqoop list-tables \
--connect jdbc:mysql://spark03:3306/hive?characterEncoding=UTF-8 \
--username root --password 'Lihaozhe!!@@1122'
MySQL 8 指定数据库中的表导入Hive中
sqoop import \
--connect jdbc:mysql://spark03:3306/chap02?characterEncoding=UTF-8 \
--username root --password 'Lihaozhe!!@@1122' --table region \
-m 1 \
--hive-import \
--create-hive-table \
--hive-table region
MySQL 8 指定数据库中的表导入Hive指定数据库中
sqoop import \
--connect jdbc:mysql://spark03:3306/chap02?characterEncoding=UTF-8 \
--username root --password 'Lihaozhe!!@@1122' --table region \
-m 1 \
--hive-import \
--create-hive-table \
--hive-table lihaozhe.region
MySQL 8 指定数据库中的表导入Hive指定数据库中
sqoop import \
--connect jdbc:mysql://spark03:3306/chap02?characterEncoding=UTF-8 \
--username root --password 'Lihaozhe!!@@1122' --table region \
-m 1 \
--hive-import \
--create-hive-table \
--hive-table lihaozhe.region \
--fields-terminated-by ','
Hive 指定数据库中的表导出 MySQL 8指定数据库中
先在 mysql 上创建数据表
create table person(
id_card char(18),
real_name varchar(50),
mobile char(11)
);
sqoop export \
-Dsqoop.export.records.per.statement=10 \
-Dmapreduce.job.max.split.locations=2000 \
--hcatalog-database chap07 \
--hcatalog-table partition_2 \
--hcatalog-partition-keys province_code \
--hcatalog-partition-values 21 \
--m 1 \
--connect jdbc:mysql://spark03:3306/chap02?characterEncoding=UTF-8 \
--username root \
--password 'Lihaozhe!!@@1122' \
--table person \
--columns id_card,real_name,mobile \
--update-mode allowinsert \
--batch
sqoop export \
-Dsqoop.export.records.per.statement=10 \
--connect jdbc:mysql:///quiz?characterEncoding=UTF-8 \
--username root \
--password 'Lihaozhe!!@@1122' \
--table category \
--update-mode allowinsert \
--batch \
--hcatalog-database tmall \
--hcatalog-table category \
--m 1
sqoop export \
-Dsqoop.export.records.per.statement=10 \
-Dmapreduce.job.max.split.locations=2000 \
--connect jdbc:mysql:///lihaozhe?characterEncoding=UTF-8 \
--username root \
--password 'Lihaozhe!!@@1122' \
--table info \
--columns name,amount \
--update-mode allowinsert \
--batch \
--hcatalog-database lihaozhe \
--hcatalog-table info \
--m 1
将hive计算结果保存到hdfs上
insert overwrite directory '/root/sort-result'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
select t2.category_id,t2.sku_id from (select sku.category_id,t1.sku_id,
rank() over (partition by sku.category_id order by t1.total_sku_num desc ) ranking
from
(select sku_id,sum(sku_num) as total_sku_num from order_detail group by sku_id) t1
left join sku on t1.sku_id = sku.sku_id) t2 where t2.ranking < 4;
insert overwrite directory '/root/sort-result'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
select id_card,real_name,mobile from partition_2;
将hdfs数据导出到MySQL数据表中
create table word_count(
word varchar(100),
count int
);
sqoop export \
--connect jdbc:mysql://spark03:3306/chap02?characterEncoding=UTF-8 \
--username root \
--password 'Lihaozhe!!@@1122' \
--table word_count \
--columns word,count \
--update-mode allowinsert \
--batch \
--m 1 \
--export-dir /out \
--fields-terminated-by '\t' \
--lines-terminated-by '\n'
MySQL 8 指定数据库中的表导入HDFS
sqoop import \
--connect jdbc:mysql://spark03:3306/chap02?characterEncoding=UTF-8 \
--username root \
--password 'Lihaozhe!!@@1122' \
--table region \
--delete-target-dir \
--input-fields-terminated-by ',' \
--input-lines-terminated-by '\n' \
--m 1 \
--target-dir /sqoopresult
智能推荐
使用UmcFramework和unimrcpclient.xml连接多个SIP设置的配置指南及C代码示例
在多媒体通信领域,MRCP(Media Resource Control Protocol)协议被广泛用于控制语音识别和合成等媒体资源。UniMRCP是一个开源的MRCP实现,提供了客户端和服务端的库。UmcFramework是一个基于UniMRCP客户端库的示例应用程序框架,它帮助开发者快速集成和测试MRCP客户端功能。本文将详细介绍如何使用UmcFramework和unimrcpclient.xml配置文件连接到多个SIP设置,以及如何用C代码进行示例说明。
java.net.ProtocolException: Server redirected too many times (20)-程序员宅基地
文章浏览阅读3k次。报错:java.net.ProtocolException: Server redirected too many times (20)1.没有检查到cookie,一直循环重定向。解决:CookieHandler.setDefault(new CookieManager(null, CookiePolicy.ACCEPT_ALL));URL url = new URL(url); ..._java.net.protocolexception: server redirected too many times (20)
springboot启动报错 Failed to scan *****/derbyLocale_ja_JP.jar from classloader hierarchy_failed to scan from classloader hierarchy-程序员宅基地
文章浏览阅读4.1k次。问题这是部分报错信息2019-07-11 14:03:34.283 WARN [restartedMain][DirectJDKLog.java:175] - Failed to scan [file:/D:/repo/org/apache/derby/derby/10.14.2.0/derbyLocale_ja_JP.jar] from classloader hierarchyjava...._failed to scan from classloader hierarchy
MATLAB-ones函数_matlab中ones函数-程序员宅基地
文章浏览阅读2.8k次,点赞3次,收藏7次。在MATLAB中,ones函数用于创建一个指定大小的由1组成的矩阵或数组。_matlab中ones函数
解决PS等软件出现应用程序无法正常启动(0xc000007b)_photoshop应用程序无法正常启动0xc000007b。请单击“确认”关闭应用程序。-程序员宅基地
文章浏览阅读3.9w次,点赞2次,收藏9次。 在使用电脑办公过程中,安装应用程序时难免遇到无法安装或者无法正常启动的问题,这对我们使用电脑带来了诸多不便。那遇到应用程序无法正常启动的问题要如何解决呢?相信大家肯定都是十分疑问的,每次都是只能忍痛重新安装软件。今天,小编就和大家探讨下应用程序无法正常启动的解决方法,帮助大家排忧解难。0xc000007b电脑图解1 第一种方案:SFC检查系统完整性来尝试修复丢失文件 1、打开电脑搜索输入cmd.exe,选择以管理员身份运行,跳出提示框时选择继续。0xc000007b电脑图解2_photoshop应用程序无法正常启动0xc000007b。请单击“确认”关闭应用程序。
oracle介质恢复和实例恢复的异同-程序员宅基地
文章浏览阅读396次。1、概念 REDO LOG是Oracle为确保已经提交的事务不会丢失而建立的一个机制。实际上REDO LOG的存在是为两种场景准备的:实例恢复(INSTANCE RECOVERY);介质恢复(MEDIA RECOVERY)。 实例恢复的目的是在数据库发生故障时,确保BUFFER CACHE中的数据不会丢失,不会造成数据库的..._oracle 实例恢复和介质恢复
随便推点
轻松搭建CAS 5.x系列(5)-增加密码找回和密码修改功能-程序员宅基地
文章浏览阅读418次。概述说明CAS内置了密码找回和密码修改的功能; 密码找回功能是,系统会吧密码重置的连接通过邮件或短信方式发送给用户,用户点击链接后就可以重置密码,cas还支持预留密码重置的问题,只有回答对了,才可以重置密码;系统可配置密码重置后,是否自动登录; 密码修改功能是,用户登录后输入新密码即可完成密码修改。安装步骤`1. 首先,搭建好cas sso server您需要按..._修改cas默认用户密码
springcloud(七) feign + Hystrix 整合 、-程序员宅基地
文章浏览阅读141次。之前几章演示的熔断,降级 都是 RestTemplate + Ribbon 和RestTemplate + Hystrix ,但是在实际开发并不是这样,实际开发中都是 Feign 远程接口调用。Feign + Hystrix 演示: eruka(略)order 服务工程: pom.xml<?xml version="1.0" encoding="U..._this is order 服务工程
YOLOv7如何提高目标检测的速度和精度,基于优化算法提高目标检测速度-程序员宅基地
文章浏览阅读3.4k次,点赞35次,收藏43次。学习率是影响目标检测精度和速度的重要因素之一。合适的学习率调度策略可以加速模型的收敛和提高模型的精度。在YOLOv7算法中,可以使用基于余弦函数的学习率调度策略(Cosine Annealing Learning Rate Schedule)来调整学习率。
linux中进程退出函数:exit()和_exit()的区别_linux结束进程可以用哪些函数,它们之间有何区别?-程序员宅基地
文章浏览阅读4k次,点赞4次,收藏9次。 linux中进程退出函数:exit()和_exit()的区别(1)_exit()执行后立即返回给内核,而exit()要先执行一些清除操作,然后将控制权交给内核。(2)调用_exit函数时,其会关闭进程所有的文件描述符,清理内存以及其他一些内核清理函数,但不会刷新流(stdin, stdout, stderr ...). exit函数是在_exit..._linux结束进程可以用哪些函数,它们之间有何区别?
sqlserver55555_sqlserver把小数点后面多余的0去掉-程序员宅基地
文章浏览阅读134次。select 5000/10000.0 --想变成0.5select 5500/10000.0 --想变成0.55select 5550/10000.0 --想变成0.555select 5555/10000.0 --想变成0.5555其结果分别为:0.5000000 0.5500000 0.5550000 0.5555000一、如果想去掉数字5后面多余的0 ,需要转化一下:selec..._sql server 去小数 0
Angular6 和 RXJS6 的一些改动_angular6,requestoptions改成了什么-程序员宅基地
文章浏览阅读3.1k次。例一:import { Injectable } from '@angular/core';import { Observable } from 'rxjs';import { User } from "./model/User";import { map } from 'rxjs/operators';import { Http, Response, Headers, RequestOp..._angular6,requestoptions改成了什么