mysql集群搭建与总结_mysql 不同端口组成集群-程序员宅基地
文章目录
好久没写博客了,最近做了分布式的项目,调查和搭建了mysql集群,踩坑无数,特此记录。
1. 主从复制集群
主从复制是选取一个mysql数据库作为主库,然后一个或者多个mysql数据库作为从库。将主库的数据单向异步的复制到从库中,使得主库和从库的数据一致.
1.1 搭建主从复制
这里使用docker,通过映射不同的mysql端口来模拟搭建mysql主从复制(一主一从)
-
下载mysql镜像,并且启动两个mysql
Master:3000 Slave:3001
docker pull mysql:5.7
docker run -itd -p 3000:3306 --name mysql-master -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
docker run -itd -p 3001:3306 --name mysql-slave -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
- 配置Master(3000)
- 进入容器,安装vim
apt-get update
apt-get install vim
- 修改my.cnf配置文件,开启binlog,重启容器使得配置生效
#vim /etc/mysql/my.cnf
!includedir /etc/mysql/conf.d/
!includedir /etc/mysql/mysql.conf.d/
[mysqld]
server-id=100 #局域网内唯一
log-bin=master-bin #开启binlog
binlog-format=ROW
- 重新进入进入容器,创建slave用户(Slave容器用此用户访问binlog,进行数据同步),并授权
mysql -uroot -p123456
CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO 'slave'@'%';
-
查看并记录Master状态,用于Slave进行同步
记录下Position后就不要对Master进行操作了,不然Position可能会发生变化
show master status

- 配置Slave(3001)
- 进入容器,安装vim
apt-get update
apt-get install vim
- 修改my.cnf配置文件,开启binlog,relay log,重启容器使得配置生效
#vim /etc/mysql/my.cnf
!includedir /etc/mysql/conf.d/
!includedir /etc/mysql/mysql.conf.d/
[mysqld]
server-id=101 #局域网内唯一
log-bin=slave-bin #开启binlog,以备Slave作为Master
relay_log=mysql-relay-bin #开启relay log
#read_only=1 #设置Slave只读,不设置则可读写
- 进行主从复制
首先查看Master和Slave容器ip
docker inspect --format='{
{.NetworkSettings.IPAddress}}' mysql-master
docker inspect --format='{
{.NetworkSettings.IPAddress}}' mysql-slave

进入容器,Slave连接Master,进行主从复制
mysql -uroot -p123456
#Slave连接Master
change master to master_host='172.17.0.2', master_user='slave', master_password='123456', master_port=3306, master_log_file='master-bin.000001', master_log_pos=617, master_connect_retry=30;
#开始主从复制
start slave;
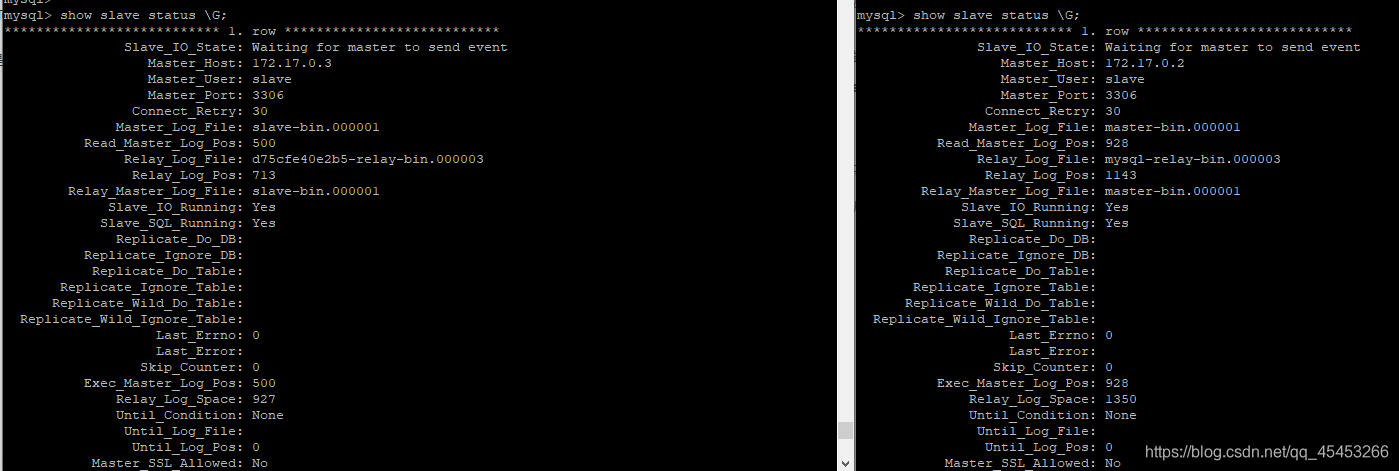
查看主从复制状态
show slave status \G;
Slave_IO_Running和Slave_SQL_Running都为Yes,代表主从复制搭建成功
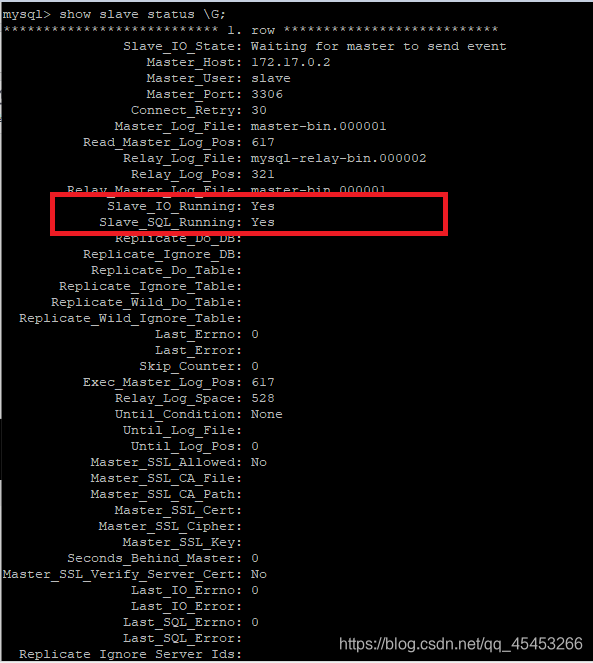
如果不都为Yes,则看Last_IO_Error与Last_SQL_Error的报错。
报错:
Got fatal error 1236 from master when reading data from binary log: 'Could not find first log file name in binary log index file
解决办法:
重置主从复制,在Slave的mysql内执行
stop slave;
reset slave;
start slave
报错:
Error ‘Operation CREATE USER failed for ‘slave’@’%’’ on query. Default database: ‘’. Query: ‘CREATE USER ‘slave’@’%’ IDENTIFIED WITH ‘mysql_native_password’ AS ‘*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9’’
解决办法:
删除此用户,刷新权限后重新开启主从复制
stop slave;
drop user 'slave'@'%';
flush privileges;
start slave;
1.2 主从复制验证
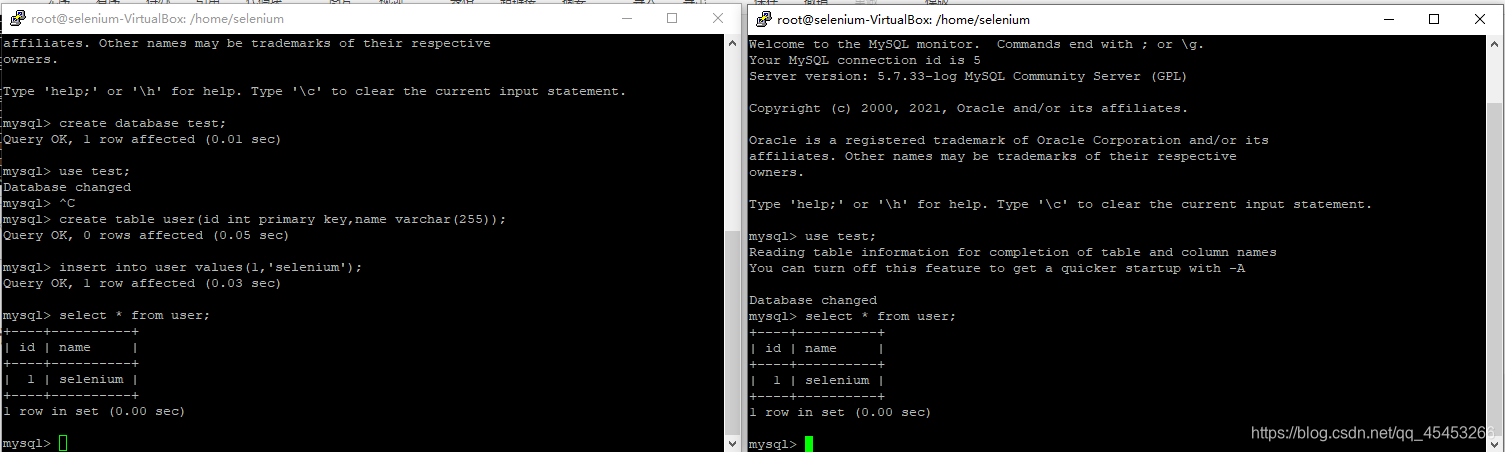
进入Master容器的mysql,建库建表并插入一条数据。
create database test;
use test;
create table user(id int primary key,name varchar(255));
insert into user values(1,'selenium');
select * from user;
然后进入Slave容器的mysql查看,发现也能看到Master容器的mysql中刚刚新建的表和数据,证明主从复制有效。
1.3 主从数据不一致的解决方案(pt-table-sync)
虽然理想的情况下,Master与Slave上的数据都是一致的,但是由于Slave网络等原因,可能会出现Master与Slave上的数据不一致。
最简单的方法,是删掉从库数据,重新建立主从复制,但是这样从库需要进行全量复制,性能很差,并且只能将Master上的数据同步到Slave上,无法将Slave上的数据同步到Master上。
而比较好的方法是利用pt-table-sync工具进行数据同步,它可以将Master与Slave上的数据互相进行同步。
以Master同步Slave数据为例:
insert into user values(2,'sakura');
在slave上插入一条数据,由于主从复制是单向复制的,Master无法查看到Slave上刚刚插入的数据.

- 下载并解压pt-table-sync
apt-get install libdbd-mysql-perl
wget https://downloads.percona.com/downloads/percona-toolkit/3.2.1/source/debian/percona-toolkit_3.2.1-1.tar.gz
tar -xvf percona-toolkit_3.2.1-1.tar.gz
- 进入解压后目录的bin目录,执行下面命令进行同步
./pt-table-sync --execute h=192.168.56.103,P=3001,u=root,p=123456 --databases test h=192.168.56.103,P=3000 --print
再次查看,发现Master与Slave数据已经一致

pt-table-sync不仅能够将Master同步为Slave的数据,也能将Slave同步为Master数据哦~
1.4 主从复制的原理

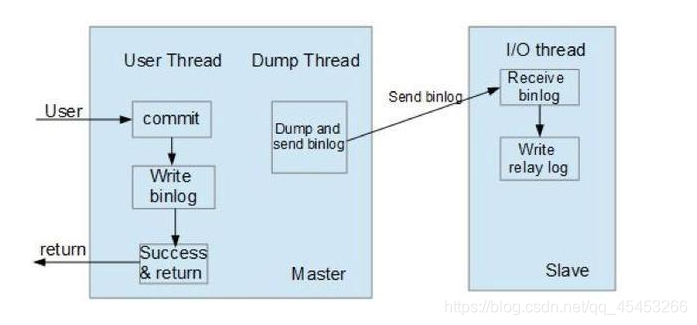
- Master 数据库数据发生改变,将改变的数据写入到binlog日志中
- Master的Dump Thread与Slave的IO Thread建立连接,从库根据change to master时的binlog文件名和position信息向Dump Thread请求,IO Thread接收到binlog event后写入到Relay log
- Slave的Sql Thread从Relay log中读取后,往Slave数据库中写入数据
2. 主主复制集群
之前说过主从复制只能Master往Slave单向异步复制数据,而主主复制则是Master与Slave互相进行数据复制。
主主复制是基于主从复制的,实际上就是在之前的Slave与Master角色互换,在原Master上执行Slave的操作,在原Slave上执行Master的操作。
3.pxc集群
之前我们提过很多次mysql主从复制是异步提交的,一个事务提交到了Master,可能还没有同步到Slave,事务就已经返回了,可能导致Master与Slave数据不一致,数据被丢失.
由于主从复制的弱一致性,所以主从复制不适用于数据可靠性要求比较高的系统,如订单系统。
这类系统适合采用基于同步复制,数据强一致性的pxc集群。
pxc集群主要特点:
- 同步复制
- 任何节点都可以读写
- 数据同步的强一致性
pxc集群使用的端口:
- 3306: mysql服务端口
- 4444: 请求全量同步(SST)端口
- 4567: 数据库节点之间通信端口
- 4568 :请求增量同步(IST)端口
3.1 搭建pxc集群
PXC1: 3002 PXC2:3003 PXC3: 3004
#下载pxc集群镜像
docker pull percona/percona-xtradb-cluster:5.7.31
# 创建容器网络
docker network create pxc
#创建数据卷,持久化mysql数据
docker volume create --name v1
docker volume create --name v2
docker volume create --name v3
docker run -itd --net=pxc --name=pxc1 -p 3002:3306 -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=pxc -e XTRABACKUP_PASSWORD=123456 -v v1:/var/lib/mysql percona/percona-xtradb-cluster:5.7.31
docker run -itd --net=pxc --name=pxc2 -p 3003:3306 -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=pxc -e XTRABACKUP_PASSWORD=123456 -e CLUSTER_JOIN=pxc1 -v v2:/var/lib/mysql percona/percona-xtradb-cluster:5.7.31
docker run -itd --net=pxc --name=pxc3 -p 3004:3306 -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=pxc -e XTRABACKUP_PASSWORD=123456 -e CLUSTER_JOIN=pxc1 -v v3:/var/lib/mysql percona/percona-xtradb-cluster:5.7.31
注意: 不要启动的太快,pxc1完全启动后再启动pxc2和pxc3
3.2 pxc集群验证
# 1.确保容器都是up状态
docker ps

# 2.进入任意一个容器查看集群状态
docker exec -it pxc1 /bin/bash
mysql -uroot -p123456
show status like '%wsrep%';
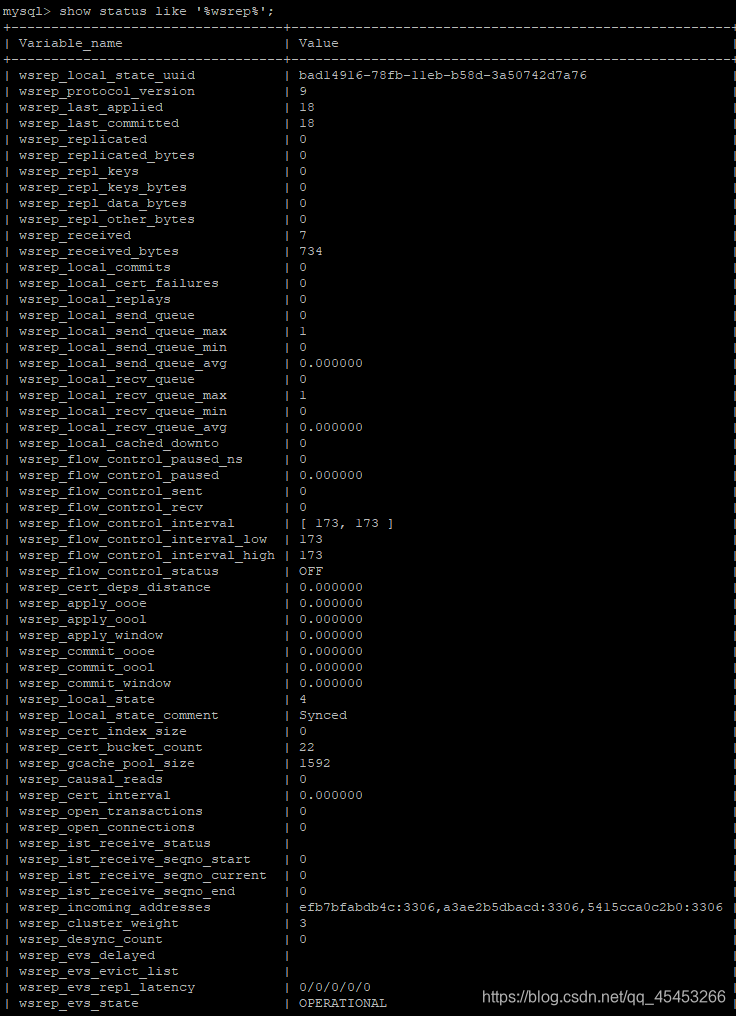
主要参数说明:
| 变量名 | 值 | 说明 |
|---|---|---|
| wsrep_cluster_size | 3 | 集群中有三个节点 |
| wsrep_cluster_status | Primary | Primary 集群状态正常 Non-Primary 集群出现异常,如脑裂 Disconnected 集群无法连接 |
全部详细参数可见: https://www.percona.com/doc/percona-xtradb-cluster/5.7/wsrep-status-index.html
因为pxc集群中的每一个节点都是可读写的,所以在任何一个节点进行修改,都会同步到其他节点.
3.3 pxc集群实战总结
因为pxc集群搭建起来很简单,所以公司的项目mysql集群最终选择的方案是搭建pxc集群。但是由于第一次使用,很多pxc集群的特性与自己预计的不符合,也算是踩了很多的坑。
1.pxc集群停掉一个Slave节点(pxc2)后,集群仍然可用
docker stop pxc2后可以看到集群节点数变为2,但仍然是Primary状态,代表节点可用

2.pxc集群Slave节点(pxc2)恢复后,自动加入集群,集群可用
docker start pxc2后可以看到集群节点数变为3,仍然是Primary状态.

3.pxc集群停掉Master节点(pxc1)后,集群仍然可用
docker stop pxc1后可以看到集群节点数变为2,但仍然是Primary状态,代表节点可用

4.pxc集群Master节点(pxc1)恢复后,无法自动加入集群
docker start pxc1后,发现pxc容器启动后很快自动退出。
docker logs pxc1查看启动日志,发现报错:
2021-02-27T14:13:55.876477Z 0 [ERROR] WSREP: It may not be safe to bootstrap the cluster from this node. It was not the last one to leave the cluster and may not contain all the updates. To force cluster bootstrap with this node, edit the grastate.dat file manually and set safe_to_bootstrap to 1 .
2021-02-27T14:13:55.876582Z 0 [ERROR] WSREP: Provider/Node (gcomm://) failed to establish connection with cluster (reason: 7)
2021-02-27T14:13:55.876677Z 0 [ERROR] Aborting
原因:
pxc通过grastate.dat文件中的safe_to_bootstrap的值区分该节点是Master节点还是Slave节点。
safe_to_bootstrap为1代表为Master节点,safe_to_bootstrap为0代表为Slave节点。
pxc集群Master节点Down掉后,safe_to_bootstrap会变为0,集群会从剩下的结点中推选出来新的Master.但是原节点的配置信息仍然是作为Master的,所以无法启动。只是简单的将safe_to_bootstrap强制修改为1,那么将会脑裂,也是毫无意义的。
解决方案:
方案一(推荐):
将原Master(px1)作为Slave重新加入集群.
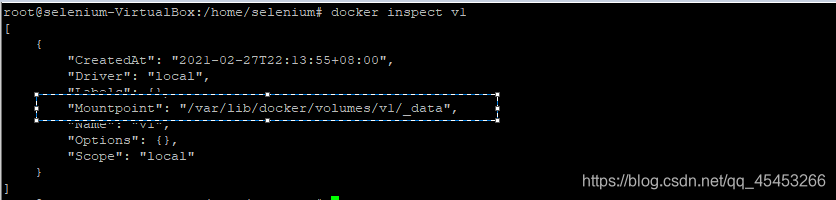
# 找到v1数据卷在宿主机上的位置
docker inspect v1
cd /var/lib/docker/volumes/v1/_data
# 删除grastate.dat文件
rm -rf grastate.dat
# 删掉pxc1重启,复用数据卷,选择剩下的结点作为Master,重新加入集群
docker rm pxc1
docker run -itd --net=pxc --name=pxc1 -p 3002:3306 -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=pxc -e XTRABACKUP_PASSWORD=123456 -e CLUSTER_JOIN=pxc2 -v v1:/var/lib/mysql percona/percona-xtradb-cluster:5.7.31
方案二:
新建节点px4作为Slave加入集群.
docker volume create --name=v4
docker run -itd --net=pxc --name=pxc4 -p 3005:3306 -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=pxc -e XTRABACKUP_PASSWORD=123456 -e CLUSTER_JOIN=pxc2 -v v4:/var/lib/mysql percona/percona-xtradb-cluster:5.7.31
方案一和方案二都是将剩下的节点中的pxc2节点作为新Master,唯一的区别就是,方案一的数据卷还在,所以集群恢复后,只用做增量同步,而方案二要做全量同步。
方案三(不推荐):
将原Master仍然作为Master,恢复集群
# 找到v1数据卷在宿主机上的位置
docker inspect v1
cd /var/lib/docker/volumes/v1/_data
# 删除grastate.dat文件
rm -rf grastate.dat
# 停止和删除pxc2和pxc3容器
docker stop pxc2 && docker rm pxc2 && docker stop pxc3 && docker rm pxc3
# 删除v2和v3数据卷
docker volume rm v2 && docker volume rm v3
# 重启pxc1容器和创建pxc2和pxc3容器
docker start pxc1
docker volume create --name=v2
docker volume create --name=v3
docker run -itd --net=pxc --name=pxc2 -p 3003:3306 -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=pxc -e XTRABACKUP_PASSWORD=123456 -e CLUSTER_JOIN=pxc1 -v v2:/var/lib/mysql percona/percona-xtradb-cluster:5.7.31
docker run -itd --net=pxc --name=pxc3 -p 3004:3306 -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=pxc -e XTRABACKUP_PASSWORD=123456 -e CLUSTER_JOIN=pxc1 -v v3:/var/lib/mysql percona/percona-xtradb-cluster:5.7.31
很明显,这个方案会丢失一部分数据(Master节点停掉后,插入到剩下节点的数据),而且两个剩下的节点都要做全量同步…唯一的优点就是,机器间的关系比较清楚,哪个机器是Master,它就一直是Master,不会发生变化
5.pxc集群节点超过半数退出后,集群不可用
在此次单机通过端口模拟pxc集群中,停掉pxc2和pxc3,pxc1仍然能够可用,没有出现集群节点超过半数退出后,集群不可用的现象。(不理解为什么)
但是在实际三台主机的开发环境中,停掉了两台Slave,Master仍然不可用,查看集群状态为Non-Primary,即出现了脑裂的现象。并且此时访问Master,会发现报错log:WSREP has not yet prepared node for application use,这时只要恢复节点到半数以上就好了.
其实pxc这样子设计,也是为了避免异地机房部署PXC集群,因为网络故障,导致一个PXC集群分裂成两个集群。
6.pxc集群的启动顺序与停止顺序相反
pxc集群每次肯定最先启动Master,再启动Slave,这样才能够选择Master,加入集群。
但是为了避免各种奇奇怪怪的错误,在停止集群的时候,一定要停掉Slave再停掉Master。
因为最后停掉的一定是存储数据最多的结点,只有下次首先启动,别的节点才方便去做增量同步.
4. InnoDB Cluster集群
虽然我们项目最终选用了pxc集群的方案,但是和我们对接的项目组却选用了InnoDB Cluster集群方案,暂时还未了解,等以后了解了,再来补上这块内容…
智能推荐
python简易爬虫v1.0-程序员宅基地
文章浏览阅读1.8k次,点赞4次,收藏6次。python简易爬虫v1.0作者:William Ma (the_CoderWM)进阶python的首秀,大部分童鞋肯定是做个简单的爬虫吧,众所周知,爬虫需要各种各样的第三方库,例如scrapy, bs4, requests, urllib3等等。此处,我们先从最简单的爬虫开始。首先,我们需要安装两个第三方库:requests和bs4。在cmd中输入以下代码:pip install requestspip install bs4等安装成功后,就可以进入pycharm来写爬虫了。爬
安装flask后vim出现:error detected while processing /home/zww/.vim/ftplugin/python/pyflakes.vim:line 28_freetorn.vim-程序员宅基地
文章浏览阅读2.6k次。解决方法:解决方法可以去github重新下载一个pyflakes.vim。执行如下命令git clone --recursive git://github.com/kevinw/pyflakes-vim.git然后进入git克降目录,./pyflakes-vim/ftplugin,通过如下命令将python目录下的所有文件复制到~/.vim/ftplugin目录下即可。cp -R ...._freetorn.vim
HIT CSAPP大作业:程序人生—Hello‘s P2P-程序员宅基地
文章浏览阅读210次,点赞7次,收藏3次。本文简述了hello.c源程序的预处理、编译、汇编、链接和运行的主要过程,以及hello程序的进程管理、存储管理与I/O管理,通过hello.c这一程序周期的描述,对程序的编译、加载、运行有了初步的了解。_hit csapp
18个顶级人工智能平台-程序员宅基地
文章浏览阅读1w次,点赞2次,收藏27次。来源:机器人小妹 很多时候企业拥有重复,乏味且困难的工作流程,这些流程往往会减慢生产速度并增加运营成本。为了降低生产成本,企业别无选择,只能自动化某些功能以降低生产成本。 通过数字化..._人工智能平台
electron热加载_electron-reloader-程序员宅基地
文章浏览阅读2.2k次。热加载能够在每次保存修改的代码后自动刷新 electron 应用界面,而不必每次去手动操作重新运行,这极大的提升了开发效率。安装 electron 热加载插件热加载虽然很方便,但是不是每个 electron 项目必须的,所以想要舒服的开发 electron 就只能给 electron 项目单独的安装热加载插件[electron-reloader]:// 在项目的根目录下安装 electron-reloader,国内建议使用 cnpm 代替 npmnpm install electron-relo._electron-reloader
android 11.0 去掉recovery模式UI页面的选项_android recovery 删除 部分菜单-程序员宅基地
文章浏览阅读942次。在11.0 进行定制化开发,会根据需要去掉recovery模式的一些选项 就是在device.cpp去掉一些选项就可以了。_android recovery 删除 部分菜单
随便推点
echart省会流向图(物流运输、地图)_java+echart地图+物流跟踪-程序员宅基地
文章浏览阅读2.2k次,点赞2次,收藏6次。继续上次的echart博客,由于省会流向图是从echart画廊中直接取来的。所以直接上代码<!DOCTYPE html><html><head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width,initial-scale=1,minimum-scale=1,maximum-scale=1,user-scalable=no" /&_java+echart地图+物流跟踪
Ceph源码解析:读写流程_ceph 发送数据到其他副本的源码-程序员宅基地
文章浏览阅读1.4k次。一、OSD模块简介1.1 消息封装:在OSD上发送和接收信息。cluster_messenger -与其它OSDs和monitors沟通client_messenger -与客户端沟通1.2 消息调度:Dispatcher类,主要负责消息分类1.3 工作队列:1.3.1 OpWQ: 处理ops(从客户端)和sub ops(从其他的OSD)。运行在op_tp线程池。1...._ceph 发送数据到其他副本的源码
进程调度(一)——FIFO算法_进程调度fifo算法代码-程序员宅基地
文章浏览阅读7.9k次,点赞3次,收藏22次。一 定义这是最早出现的置换算法。该算法总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面予以淘汰。该算法实现简单,只需把一个进程已调入内存的页面,按先后次序链接成一个队列,并设置一个指针,称为替换指针,使它总是指向最老的页面。但该算法与进程实际运行的规律不相适应,因为在进程中,有些页面经常被访问,比如,含有全局变量、常用函数、例程等的页面,FIFO 算法并不能保证这些页面不被淘汰。这里,我_进程调度fifo算法代码
mysql rownum写法_mysql应用之类似oracle rownum写法-程序员宅基地
文章浏览阅读133次。rownum是oracle才有的写法,rownum在oracle中可以用于取第一条数据,或者批量写数据时限定批量写的数量等mysql取第一条数据写法SELECT * FROM t order by id LIMIT 1;oracle取第一条数据写法SELECT * FROM t where rownum =1 order by id;ok,上面是mysql和oracle取第一条数据的写法对比,不过..._mysql 替换@rownum的写法
eclipse安装教程_ecjelm-程序员宅基地
文章浏览阅读790次,点赞3次,收藏4次。官网下载下载链接:http://www.eclipse.org/downloads/点击Download下载完成后双击运行我选择第2个,看自己需要(我选择企业级应用,如果只是单纯学习java选第一个就行)进入下一步后选择jre和安装路径修改jvm/jre的时候也可以选择本地的(点后面的文件夹进去),但是我们没有11版本的,所以还是用他的吧选择接受安装中安装过程中如果有其他界面弹出就点accept就行..._ecjelm
Linux常用网络命令_ifconfig 删除vlan-程序员宅基地
文章浏览阅读245次。原文链接:https://linux.cn/article-7801-1.htmlifconfigping <IP地址>:发送ICMP echo消息到某个主机traceroute <IP地址>:用于跟踪IP包的路由路由:netstat -r: 打印路由表route add :添加静态路由路径routed:控制动态路由的BSD守护程序。运行RIP路由协议gat..._ifconfig 删除vlan