爬虫中常见的反爬手段和解决方法-程序员宅基地
每日分享:
欲成大树,莫与草争;将军有剑,不斩草蝇;遇烂入及时止损,遇烂事及时抽身。格局小的人喜欢诋毁和嫉妒,因为我不好,我也不想让你好。格局大的人都懂得一个道理,强者互帮,弱者互撕。人性最大的愚蠢就是互相为难。人生匆匆:自渡是一种能力,渡人就是一种格局。
- 了解反爬的三个方向
- 了解常见基于身份识别进行反爬
- 了解常见基于爬虫行为进行反爬
- 了解常见基于数据加密进行反爬
一、反爬的三个方向
- 基于身份识别进行反爬
- 基于爬虫行为进行反爬
- 基于数据加密进行反爬
二、常见基于身份识别进行反爬
1. 通过headers字段来反爬
headers中有很多字段,这些字段都有可能会被对方服务器拿过来判断是否为爬虫
1.1 通过headers中的user-agent字段进行反爬
- 反爬原理:爬虫默认情况下没有user-agent,而是使用模块默认设置
- 解决方法:请求之前添加user-agent即可;更好的方式是使用user-agent池来解决(收集一堆user-agent或者随机生成user-agent)
1.2 通过referer字段或者是其他字段来反爬
- 反爬原理:爬虫默认情况下不会带上referer字段,服务器通过判断请求发起的源头,以此判断请求是否合法
- 解决方法:添加referer字段
1.3 通过cookie来反爬
- 反爬原因:通过检查cookies来查看发起请求的用户是否具备相应权限,以此来进行反爬
- 解决方案:进行模拟登录,成功获取cookies之后再进行数据爬取
2. 通过请求参数来反爬
请求参数的获取方法有很多,向服务器发送请求,很多时候需要携带请求参数,通常服务器端可以通过检查请求参数是否正确来判断是否为爬虫
2.1 通过从html静态文件中获取请求数据
- 反爬原因:通过增加获取请求参数的难度进行反爬
- 解决方案:仔细分析抓包得到的每一个包,搞清楚请求之间的联系
2.2 通过发送请求获取请求数据
- 反爬原因:通过增加获取请求参数的难度进行反爬
- 解决方案:仔细分析抓包得到的每一个包,搞清楚请求之间的联系,搞清楚请求参数的来源
2.3 通过js生成请求参数
- 反爬原理:js生成了请求参数
- 解决方法:分析js,观察加密的实现过程,通过js2py获取js的执行结果,或者使用selenium来实现
2.4 通过验证码来反爬
- 反爬原理:对方服务器通过弹出验证码强制验证用户浏览行为
- 解决方法:打码平台或者是机器学习的方法识别验证码,其中打码平台廉价易用,更值得推荐
三、常见基于爬虫行为进行反爬
3.1 基于请求频率或总请求数量
爬虫的行为与普通用户有着明显的区别,爬虫的请求频率与请求次数要远高于普通用户
3.1.1 通过请求ip/账号单位时间内总请求数量进行反爬
- 反爬原理:正常浏览器请求网络,速度不会太快,同一个ip/账号大量请求了对方服务器,有更大的可能性会被识别为爬虫
- 解决方法:对应的通过购买高质量的ip的方式能够解决问题/购买多个账号
3.1.2 通过同一ip/账号请求之间的间隔进行反爬
- 反爬原理:正常人操作浏览器浏览网站,请求之间的时间间隔是随机的,而爬虫前后两个请求之间间隔通常比较固定同时时间间隔较短,因此可用来反爬
- 解决方法:请求之间进行随机等待,模拟真实用户操作,在添加时间间隔后,为了能够高速获取数据,尽量使用代理池,如果是账号,则将账号请求之间设置随机休眠
3.1.3 通过对请求ip/账号每天请求次数设置阈值进行反爬
- 反爬原理:正常的浏览行为,其一天的请求次数是有限的,通常超过某一个值,服务器就会拒绝响应
- 解决方法:对应的通过购买高质量的ip/多账号的方法,同时设置请求间随机休眠
3.2 根据爬虫行为进行反爬,通常在爬取步骤上做分析
3.2.1 通过js实现跳转来反爬
- 反爬原理:js实现页面跳转,无法在源码中获取下一页url
- 解决方法:多次抓包获取条状url,分析规律
3.2.2 通过蜜罐(陷阱)获取爬虫ip(或代理ip),进行反爬
- 反爬原理:在爬虫获取链接进行请求的过程中,爬虫会根据正则,xpath,css等方式进行后续链接的提取,此时服务器端可以设置一个陷阱url,会被提取规则获取,但是正常用户无法获取,这样就能有效的区分爬虫和正常用户
- 解决方法:完成爬虫的编写之后,使用代理批量爬取测试/仔细分析响应内容结构,找出页面中存在的陷阱
3.2.3 通过假数据反爬
- 反爬原理:向返回的响应中添加假数据污染数据库,通常假数据不会被正常用户看到
- 解决方法:长期运行,核对数据库中数据同实际页面中数据对应情况,如果存在问题/仔细分析响应内容
3.2.4 阻塞任务队列
- 反爬原理:通过生成大量垃圾url,从而阻塞任务队列,降低爬虫的实际工作效率
- 解决方法:观察运行过程中请求影响状态/仔细分析源码获取垃圾url生成规则,对url进行过滤
3.2.5 阻塞网络io
- 反爬原理:发送请求获取响应的过程实际上就是下载的过程,在任务队列中混入一个大文件的url,当爬虫在进行该请求时将会占用网络io,如果是有多线程则会占用线程
- 解决方法:观察爬虫运行状态/多线程对请求线程计时/发送请求线
3.2.6 运维平台综合审计
- 反爬原理:通过运维平台进行综合管理,通常采用复合型反爬策略,多种手段同时使用
- 解决方法:仔细观察分析,长期运行测试目标网站,检查数据采集速度,多方面处理
四、常见基于数据加密进行反爬
4.1 对响应中含有的数据进行特殊化处理
通常的特殊化处理主要指的是css数据偏移/自定义字体/数据加密/数据图片/特殊编码格式
4.1.1 通过自定义字体来反爬
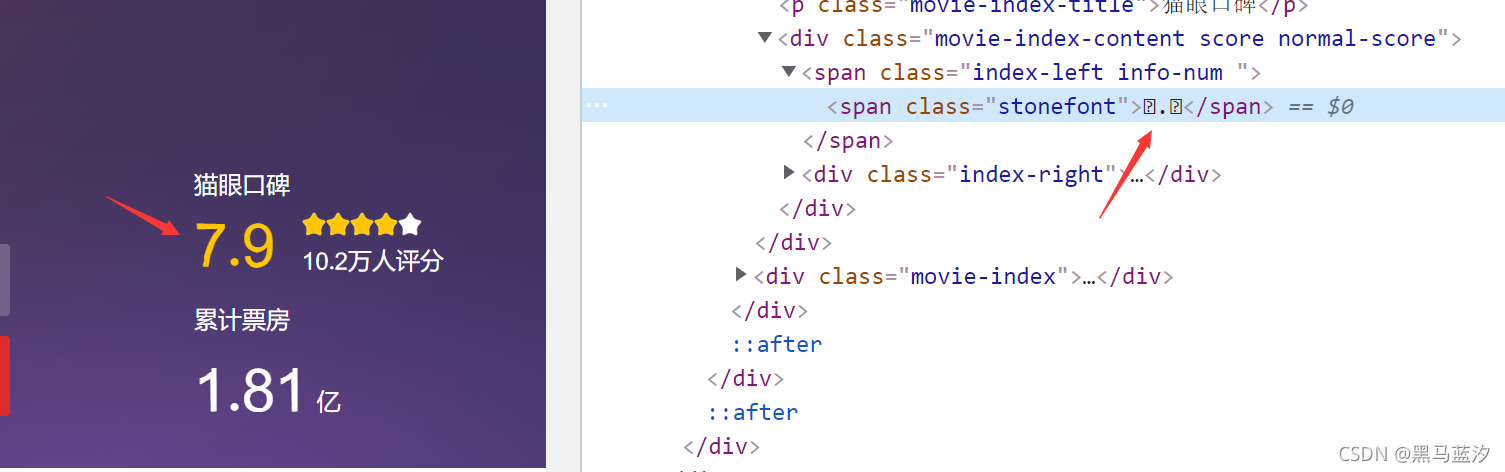
左面写的口碑7.9,检查之后,右面根本不会显示该数字,而是显示几个方框
在无痕模式准备抓包,打开网址,可以找到它的数字就像一段乱码,这就是它自定义的字体:
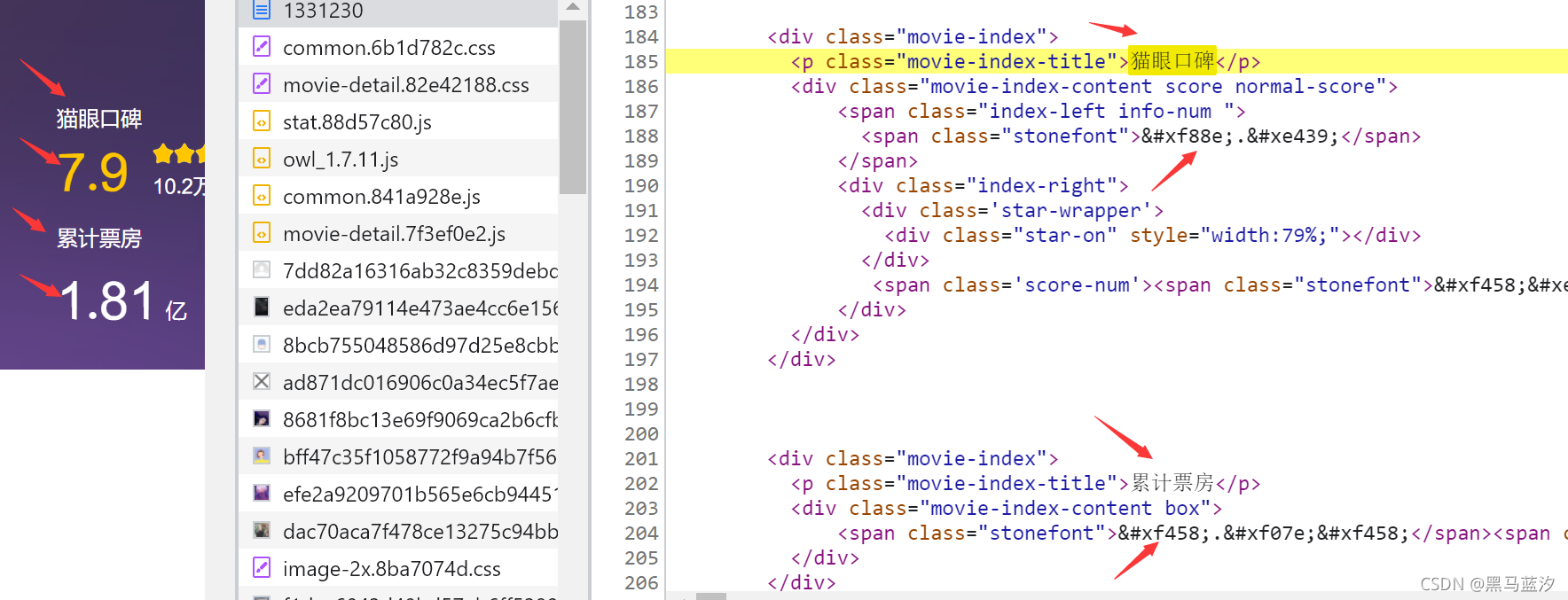
处理方法:我们可以将数字和自定义字体对应起来,比如7对应的就是
4.1.2 通过css来反爬
- 反爬思路:源码数据不为真正数据,需要通过css位移才能产生真正数据
- 解决思路:计算css偏移
4.1.3 通过js动态生成数据进行反爬
- 反爬原理:通过js动态生成
- 解决思路:解析关键js,获得数据生成流程,模拟生成数据
4.1.4 通过数据图片化反爬
- 一串数字在做成图片显示
- 解决思路:通过使用图片解析引擎从图片中解析数据
4.1.5 通过编码格式进行反爬
- 反爬原理:不适用默认编码格式,在获取响应后通常爬虫使用utf-8格式进行解码,此时解码结果将会是乱码或者报错
- 解决思路:根据源码进行多格式解码,或者真正的解码格式
智能推荐
Android修改ro.debuggable 的四种方法-程序员宅基地
文章浏览阅读2.7w次,点赞15次,收藏71次。目录一、使用一键Root工具二、使用mprop工具(重启失效)三、Magisk 重置 ro.debuggable (重启失效)四、MagiskHide Props Config 模块修改(永久有效)查看getprop ro.debuggable的值:adb shell getprop ro.debuggable一、使用一键Root工具使用Root工具,一键root后ro.debuggable一般就为1了常见的root工具:KingRoot、360超级Root、百度一键Ro_ro.debuggable
洛谷——P1075 [NOIP2012 普及组] 质因数分解_【noip2012普及组】质因数分解c++-程序员宅基地
文章浏览阅读480次。P1075 [NOIP2012 普及组] 质因数分解题目描述已知正整数nn是两个不同的质数的乘积,试求出两者中较大的那个质数。输入格式一个正整数nn。输出格式一个正整数pp,即较大的那个质数。输入输出样例输入 #1复制21输出 #1复制7java:package com.kk.luogu;import java.util.Scanner;//P1075 [NOIP2012 普及组] 质因数分解public class P1075 { public stati_【noip2012普及组】质因数分解c++
基于PysimpleGUI+pymysql建立的简单管理系统(6)—查找功能_pysimplegui 管理系统-程序员宅基地
文章浏览阅读116次。基于PysimpleGUI+pymysql建立的简单管理系统(6)_pysimplegui 管理系统
Java工作流详解(附6大工作流框架对比)-程序员宅基地
文章浏览阅读1.4w次,点赞7次,收藏58次。Jflow是一个国产的开源工作流引擎,与业务场景结合紧密,再带表单引擎,数据表较多,中文概念较多,可配置型性强,支持作为中间件模式的集成。配置点集中在,节点属性,流程属性,方向条件。概念名词比较清晰,文档全面。有qq群技术支持。流程设计器界面干净,从节点类型分类,分流,合流,分合流,子线程等等。表单与流程完美结合,与其它几款流程引擎设计理念不同。Jflow更适用,贴近用户操作。表单引擎中的精华是审核组件,满足国内审批要求的需求,退回,分合流审核,会签,并行处理,队列处理,概念清晰,容易理解。_工作流
TFRecord格式数据读取+划分训练集、验证集和测试集_如何从tfrecord拆出一个小数据集-程序员宅基地
文章浏览阅读1.3k次。可以参考深度学习笔记:在小数据集上从头训练卷积神经网络_笨牛慢耕的博客-程序员宅基地_小数据集训练ImageDataGenerator.flow_from_directory可以提取TFrecord数据格式。image_dataset_from_directory是更古老的东西也能作为TFrecord数据提取的工具,但是提取的是整个文件夹中的文件数据集,如果想要划分为训练集和验证集,可以尝试使flow_from_directory。示例如下:#使用原模块,subset参数.._如何从tfrecord拆出一个小数据集
程序猿头头(js数组reverse,sort,concat,slice, splice)_splice/sort/reverse js-程序员宅基地
文章浏览阅读274次。reversereverse不是排序方法,它只是数组颠倒方法,可以将数组的顺序颠倒过来。// 书中的例子,只是作为反向排序讲解,不够全面let values = [1, 2, 3, 4, 5]; values.reverse();console.log(values); // [5,4,3,2,1]let numbers = [5,1,2,6,3];numbers.reverse();console.log(numbers); // [3, 6, 2, 1, 5]let chars =_splice/sort/reverse js
随便推点
vue+vuex+router初体验_vue安装zeromq-程序员宅基地
文章浏览阅读587次。前言本人是java开发出生,工作需要研究node/vue,在学习期间参照很多博文,书写示例代码,文中肯定会有很多不专业的地方,记录一方面用于自己梳理知识脉络,一方面方便日后查询,同时还可以让和我处于相同情况的码农们有个参考,废话不多说了,开始撸代码,这才是每个码农关心的问题.vue环境搭建没有详细了解的npm的伙伴们不要紧张,照着做就可以,用的多了就了解了,至于他是怎么实现的需要有精力的童鞋们研究,_vue安装zeromq
Swift 语句(Statements)_swfit did you mean to use a 'do' statement?-程序员宅基地
文章浏览阅读529次。在 Swift 中,有两种类型的语句:简单语句和控制流语句。简单语句是最常见的,用于构造表达式或者声明。控制流语句则用于控制程序执行的流程,Swift 中有三种类型的控制流语句:循环语句、分支语句和控制传递语句。循环语句用于重复执行代码块;分支语句用于执行满足特定条件的代码块;控制传递语句则用于修改代码的执行顺序。在稍后的叙述中,将会详细地介绍每一种类型的控制流语句。是否将分号(;)添加到_swfit did you mean to use a 'do' statement?
Android 自定义FloatView实现悬浮视图_android floatview-程序员宅基地
文章浏览阅读6.3k次,点赞2次,收藏9次。 前言:自定义FlaotView不需要任何权限,继承FrameLayout,通过WindowManager实现悬浮。资源文件:drawable、drawable-hdpi、layout菜单背景(menu_bg.xml):<?xml version="1.0" encoding="utf-8"?><selector ="http://s..._android floatview
python plt.subplot_Python Matplotlib subplot函数详解:创建子图-程序员宅基地
文章浏览阅读1.7k次。使用 Matplotlib 除可以生成包含多条折线的复式折线图之外,它还允许在一张数据图上包含多个子图。调用 subplot() 函数可以创建一个子图,然后程序就可以在子图上进行绘制。subplot(nrows, ncols, index, **kwargs) 函数的 nrows 参数指定将数据图区域分成多少行;ncols 参数指定将数据图区域分成多少列;index 参数指定获取第几个区域。sub..._python plt.subplot
关于QT调试操作步骤_qtcreator 如何debug-程序员宅基地
文章浏览阅读2.6k次。关于QT调试操作步骤 1.首先,用QtCreator打开Qt工程,然后点击左下角的电脑图标,再在弹出的菜单中选择“Debug”。 **2.接下来,在需要进行调试的代码部分设下断点。设断点的方法是在要设断点的代码行前的空白处点击鼠标。****3.如果想清除断点,则在该断点上再点击一下即可清除。**..._qtcreator 如何debug
什么是BIOS?为什么开机先从BIOS开始?以及操作系统启动过程-程序员宅基地
文章浏览阅读1.1w次,点赞9次,收藏67次。1、什么是BIOS?BIOS是英文bai"Basic Input Output System"的缩略词,直译过来后中文名称就是"基本输入输出系统"。其实,它是一组固化到计算机内主板上一个daoROM芯片上的程序,它保存着计算机最重要的基本输入输出的程序、系统设置信息、开机后自检程序和系统自启动程序。 其主要功能是为计算机提供最底层的、最直接的硬件设置和控制。有人认为既然BIOS是"程序",那它就应该是属于软件,感觉就像自己常用的Word或Excel。但也很多人不这么认为,因为它与一般的软件还是有一些区别_bios