弱监督学习——A brief introduction to weakly supervised learning-程序员宅基地
技术标签: 机器学习
A brief introduction to weakly supervised learning
分类
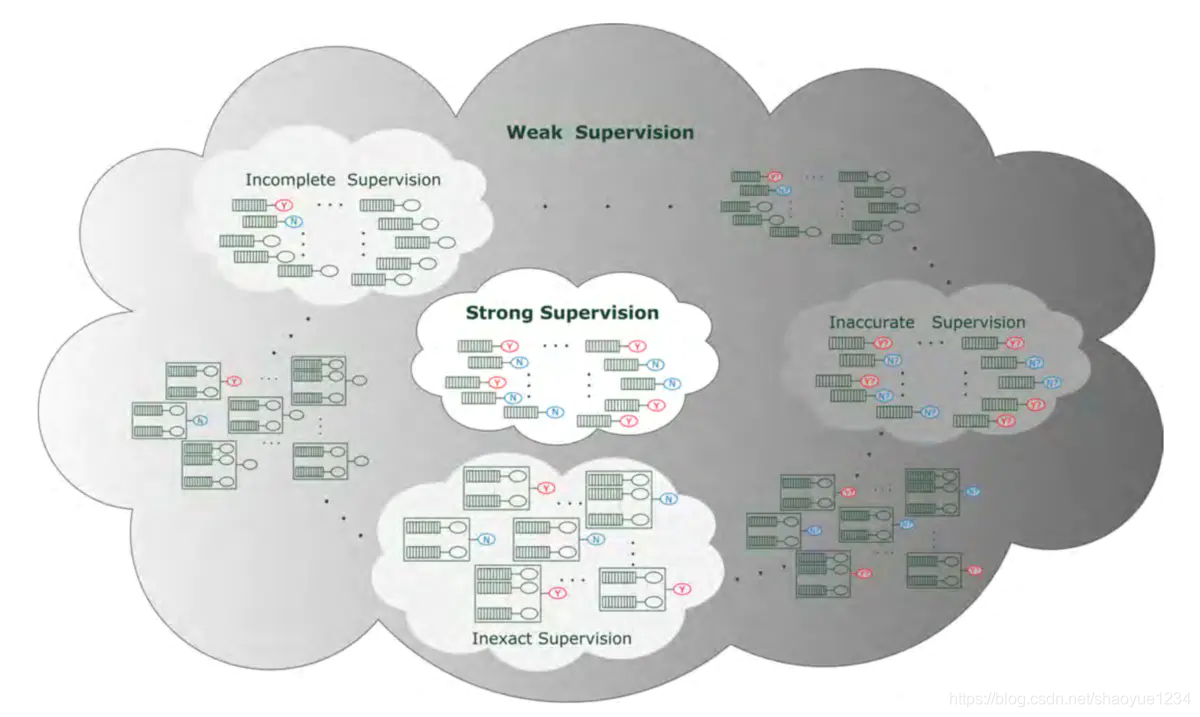
- incomplete supervision:只有一部分子集给出标签;
- inexact supervision:训练集样本只给出大概的标签;
- inaccurate supervision:训练集样本不一定可信。
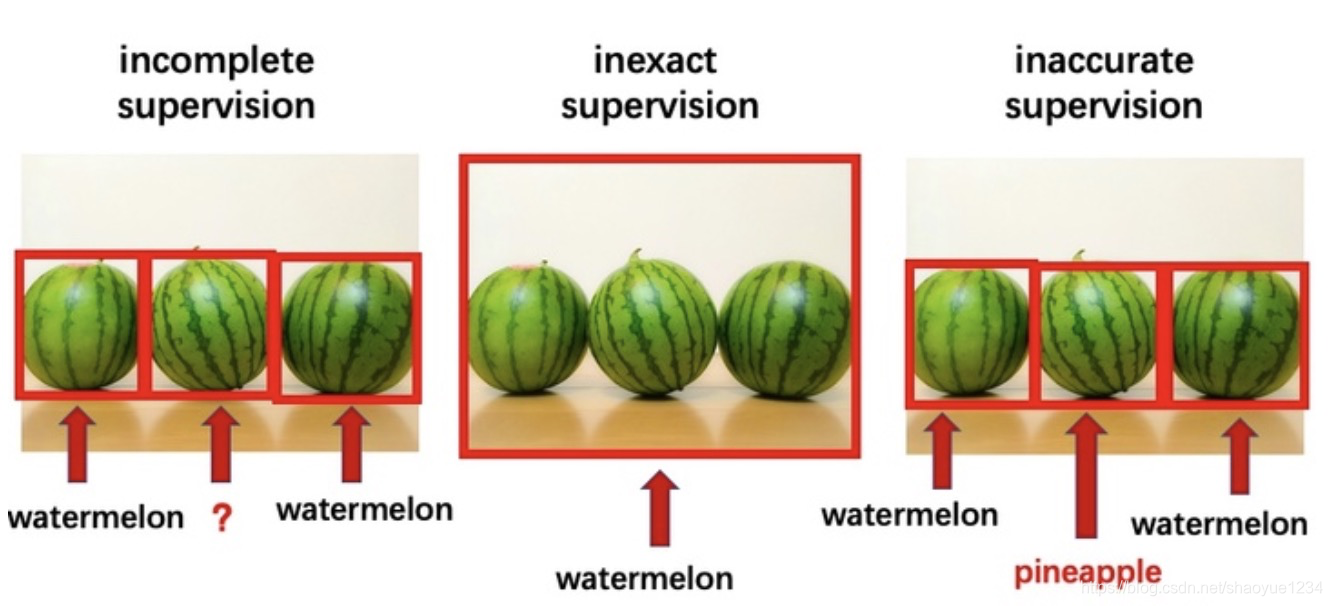
需要注意的是这三种方法往往可以同时运用。
应用

常用方法
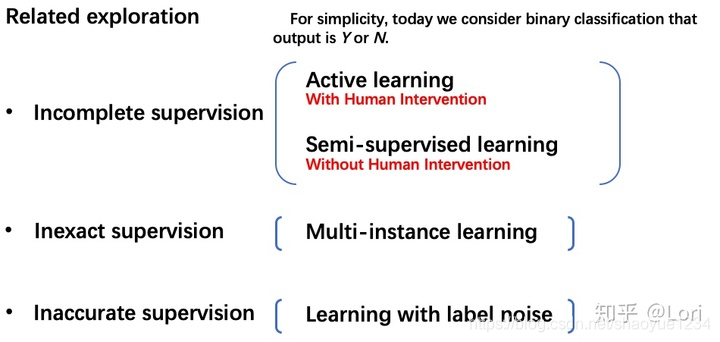
incomplete supervision
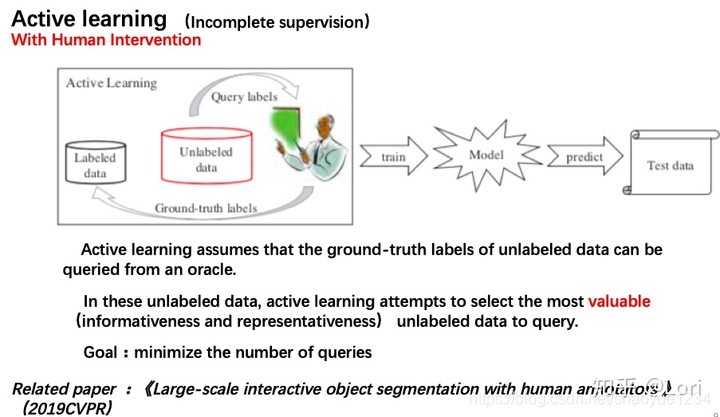
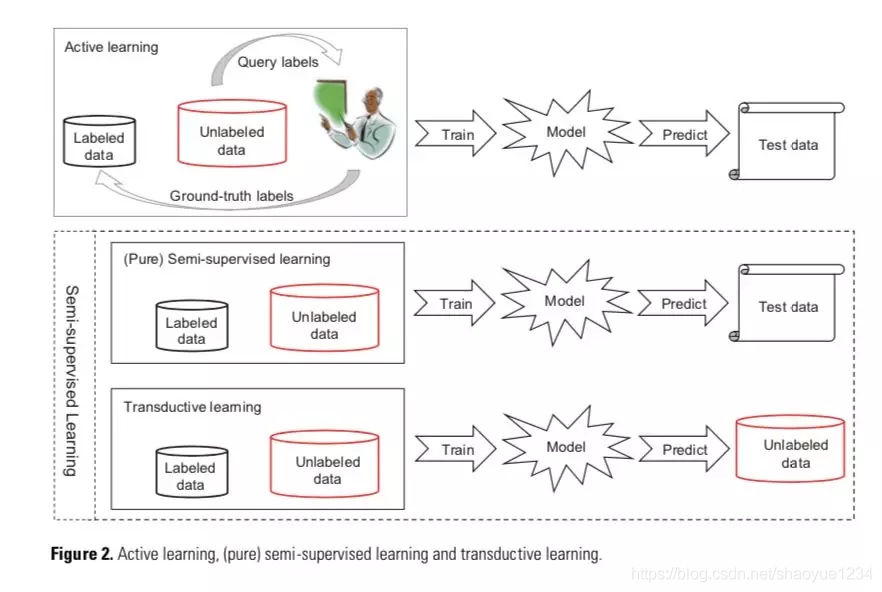
active learning
-
假设:未标注数据的真值标签可以向"先知”查询。
-
思想:标注成本只与查询次数有关->主动学习的目标就是最小化查询次数->
选最有价值的未标注数据来查询先知 -
价值衡量标准:
- 信息量(informativeness)一个未标注数据能够在多大程度上降低统计模型的不确定性。
- 不确定抽样(uncertainty sampling)训练单个学习器,选择学习器最不确信的样本向先知询问标签信息;投票询问(query-by-committee)生成多个学习器,选择各个学习器争议最大的样本向先知询问标签信息。
- 代表性(representativeness)衡量一个样本在多大程度上能代表模型的输入分布。
- 用聚类方法来挖掘未标注数据的集群结构
- 同时利用信息量和代表性度量:
- 基于信息量的方法,主要缺点是为了建立选择查询样本所需的初始模型,而严重依赖于标注数据,并且当标注样本较少时,其性能通常不稳定。基于代表性的方法,主要缺点在于其性能严重依赖于由未标注数据控制的的聚类结果,当标注数据较少时尤其如此。
- 信息量(informativeness)一个未标注数据能够在多大程度上降低统计模型的不确定性。
-
理论研究
- 已经证明对于可实现(realizable)情况(假设数据在假设的空间中完全可分),随着样本复杂性的增加,主动学习的性能可以获得指数提升。对于不可实现(non-realizable)的情况(即由于噪声的存在,以致数据在任何假设下都不完全可分),在没有对噪声模型的先验假设时,主动学习的下确界相当于被动学习的上确界,换句话说,主动学习并不是非常有用。当假设噪声为Tsybakov噪声模型时,我们可以证明,在噪声有界的条件下,主动学习的性能可呈指数级提升;如果能够挖掘数据的一些特定性质,像多视角结构(multi-view structure),那么即使在不对噪声进行限制的情况下,其性能也能呈指数级提升。换句话说,只要设计得巧妙,主动学习在解决困难问题时仍然有用。
- 已经证明对于可实现(realizable)情况(假设数据在假设的空间中完全可分),随着样本复杂性的增加,主动学习的性能可以获得指数提升。对于不可实现(non-realizable)的情况(即由于噪声的存在,以致数据在任何假设下都不完全可分),在没有对噪声模型的先验假设时,主动学习的下确界相当于被动学习的上确界,换句话说,主动学习并不是非常有用。当假设噪声为Tsybakov噪声模型时,我们可以证明,在噪声有界的条件下,主动学习的性能可呈指数级提升;如果能够挖掘数据的一些特定性质,像多视角结构(multi-view structure),那么即使在不对噪声进行限制的情况下,其性能也能呈指数级提升。换句话说,只要设计得巧妙,主动学习在解决困难问题时仍然有用。
semi-supervised learning
- 假设
- 聚类假设(cluster assumption):数据具有内在的聚类结构,因此,落入同一个聚类的样本类别相同。
- 流形假设(manifold assumption);数据分布在一个流形上,因此,相近的样本具有相似的预测。
- 方法
- 生成式方法(generative methods)
- 假设标注数据和未标注数据都由一个固有的模型生成。因此,未标注数据的标签可以看作是模型参数的缺失,并可以通过EM算法(期望-最大化算法)等方法进行估计。这类方法随着为拟合数据而选用的不同生成模型而有所差别。
- 基于图的方法(graph-based methods)
- 构建一个图,其节点对应训练样本,其边对应样本之间的关系(通常是某种相似度或距离),而后依据某些准则将标注信息在图上进行扩散;例如标签可以在最小分割图算法得到的不同子图内传播【23】。很明显,模型的性能取决于图是如何构建的【26-28】。值得注意的是,对于m个样本点,这种方法通常需要O(m^2 )存储空间和O(m^3)计算时间复杂度。因此,这种方法严重受制于问题的规模;而且由于难以在不重建图的情况下增加新的节点,所以这种方法天生难以迁移。
- 低密度分割法(low-density separation methods)
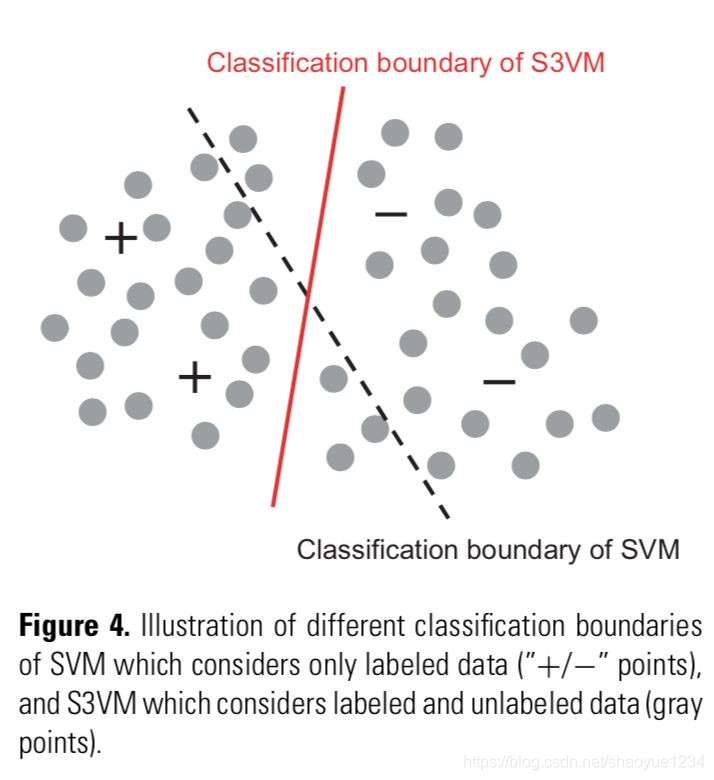
- 强制分类边界穿过输入空间的低密度区域。最著名的代表就是S3VMs(半监督支持向量机)。图示意了一般的监督SVM和S3VM的区别。很明显,S3VM试图在保持所有标注样本分类正确的情况下,建立一个穿过低密度区域的分类界面。这一目标可以通过用不同方法给未标注数据分配标签来达成,而这往往会造成优化问题很复杂。因此,在这个方向很多的研究都致力于开发高效的优化方法。
- 基于分歧的方法(disagreement methods)
- 生成多个学习器,并让它们合作来挖掘未标注数据,其中不同学习器之间的分歧是让学习过程持续进行的关键。最为著名的典型方法——联合训练(co-traing),通过从两个不同的特征集合(或视角)训练得到的两个学习器来运作。在每个循环中,每个学习器选择其预测置信度最高的未标注样本,并将其预测作为样本的伪标签来训练另一个学习器。这种方法可以通过学习器集成来得到很大提升【34,35】。值得注意的是,基于分歧的方法提供了一种将半监督学习和主动学习自然地结合在一起的方式:它不仅可以让学习器相互学习,对于两个模型都不太确定或者都很确定但相互矛盾的未标注样本,还可以被选定询问“先知”。
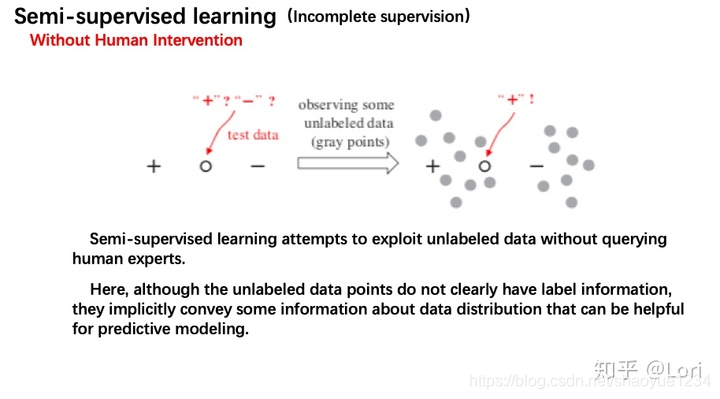
- 生成多个学习器,并让它们合作来挖掘未标注数据,其中不同学习器之间的分歧是让学习过程持续进行的关键。最为著名的典型方法——联合训练(co-traing),通过从两个不同的特征集合(或视角)训练得到的两个学习器来运作。在每个循环中,每个学习器选择其预测置信度最高的未标注样本,并将其预测作为样本的伪标签来训练另一个学习器。这种方法可以通过学习器集成来得到很大提升【34,35】。值得注意的是,基于分歧的方法提供了一种将半监督学习和主动学习自然地结合在一起的方式:它不仅可以让学习器相互学习,对于两个模型都不太确定或者都很确定但相互矛盾的未标注样本,还可以被选定询问“先知”。
- 生成式方法(generative methods)
二者的区别
inexact supervision
multi-instance learning

inaccurate supervision
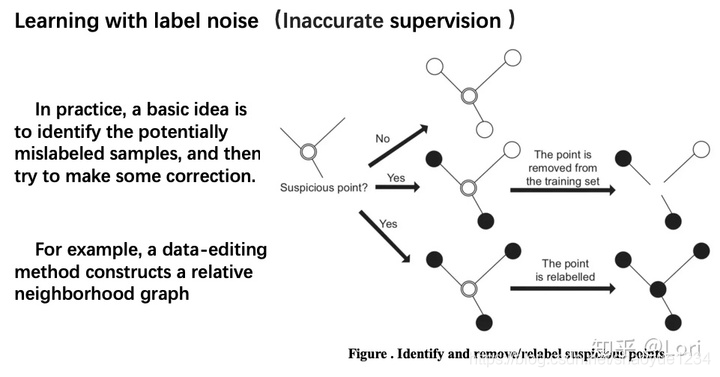
learning with label noise
参考
智能推荐
centos7.3(1611版本)安装增强工具(VirtualBox)-程序员宅基地
文章浏览阅读298次。一、场景说明: 虚拟软件使用VirtualBox,虚机操作系统使用CentOs7.3, 最小化安装后在虚机里面安装增强工具。 二、安装方法: 首先要先安装图形界面不然..._vboxwindowsadditions-amd64.exe下载
jdk32位连不上oracle64位,64位 jdk 读取32位dll-程序员宅基地
文章浏览阅读227次。执行上面的测试代码,发现使用 32 位的 JDK 通过配置的 testodbc 数据源 (32 位的驱动程序)能够正常的连接到 64 位的数据库,如下图所示。 这个场景并不完全真实,只是我个人的一个联想和猜测,中间极有可能出 现不正确或不完整的......在 face.h 的头文件中包含了 jni.h 头 文件,所以需要将 jdk 安装目录下 include 文件夹下的 jni.h 头文件和 in..._32位jdk连不上数据库
迄今为止最强大的开源 LLM,15 万亿 Token 预训练的 LLaMA3 强势来袭_如何解决llama3 token长度问题-程序员宅基地
文章浏览阅读607次,点赞19次,收藏18次。例如,虽然 8B 参数模型在 Chinchilla 的最佳训练计算量对应于约 200B 个Token,但我们发现,即使在模型训练完成之后,再接受了两个数量级以上的数据训练,模型性能仍在继续提高。此版本是在 15 万亿个 Token 上预训练的语言模型,具有 8B 和 70B 两种参数规模,可以支持广泛的用户场景,在各种行业基准上取得了最先进的性能,并提供一些了新功能,包括改进的推理能力,这些都是同时期最好的开源模型。此外,还进行了广泛的实验,以评估在最终预训练数据集中混合不同来源的数据的最佳方法。_如何解决llama3 token长度问题
svn命令使用总结_svn删除文件夹命令-程序员宅基地
文章浏览阅读347次。Ubuntu安装svnapt-get install subversiongit工具使用ubuntu 18.04下svn的安装与基本命令_svn删除文件夹命令
Linux 机器间配置 SSH 免密登录_从linux服务器上ssh连接其他主机免输密码-程序员宅基地
文章浏览阅读1.4k次。在日常工作中,服务器常常会有多台。特别是应用服务器存在多台的情况下,在每台机器手动部署或升级服务,每次登录多台机器特别麻烦,通过一台机器跳转每次输入密码(一般都是超强密码)也麻烦。所以说配置机器间的免密,对日常工作来说可以简化操作流程,节省宝贵时间。这篇就简单说说如何配置多台机器间的免密功能。_从linux服务器上ssh连接其他主机免输密码
python预测值和真实值_机器学习中用什么图可以表示预测数据与真实数据的差异?...-程序员宅基地
文章浏览阅读2.5k次。但是实际上学习机器学习可能很困难。您要么使用行为类似于“黑匣子”的预构建包,要么在其中传递数据,另一端则产生魔力,或者您必须处理高级数学和线性代数。每种方法都使学习机器学习充满挑战和威胁。用Python搭建机器学习模型预测房租价格旨在向您介绍机器学习的基本概念。在继续学习时,您将从头开始构建第一个模型以进行预测,同时准确地了解模型的工作原理。(用Python搭建机器学习模型预测房租价格基于我们的机..._python机器学习预测数据比较作图
随便推点
一些Docker常用命令,下载镜像和创建容器,Centos开启自启docker和对应mariadb(容器)_docker中怎么开机启动mariadb-程序员宅基地
文章浏览阅读2.7k次,点赞2次,收藏3次。觉得有帮助的同学可以点个赞!传递给更多人!docker进入容器docker exec -it 容器id bashcentos开机自启docker# 设置开机启动systemctl enable docker.service# 关闭开机启动systemctl disable docker.servicedocker容器设置自动启动# 启动时加--restart=alwaysdocker run -d --restart=always -p 3307:3306 -e MYSQL_ROO_docker中怎么开机启动mariadb
python爬取股票数据并存到数据库_id,ts_code,trade_date,close,open,high,low,pre_clos-程序员宅基地
文章浏览阅读3k次,点赞11次,收藏38次。Python 用Tushare接口获取股票数据并存储到Sqlite数据库使用技术介绍:关于接口 由于tushare旧版本即将不能用了,所以我们这里使用的是tushare pro 接口。关于数据库 使用了Sqlite轻量级数据库适合本地使用。具体实现Tushare Pro 爬取数据Pro接口需要前往官网(https://tushare.pro/)注册,并获取token,过程较为繁琐,而本文篇幅有限故将在之后更新获取token文章。将获取到的token值放进config文件中的tushare_id,ts_code,trade_date,close,open,high,low,pre_close,change,pct_chg,vol,amoun
IllegalStateException异常处理_illegalstateexception:falied to convert map to bea-程序员宅基地
文章浏览阅读1.6k次。java.lang.IllegalStateException: Failed to load ApplicationContext at org.springframework.test.context.CacheAwareContextLoaderDelegate.loadContext(CacheAwareContextLoaderDelegate.java:99) at or_illegalstateexception:falied to convert map to bean
计算机运行慢 卡是什么原因是什么原因,电脑很卡是什么原因?电脑卡的原因有哪些...-程序员宅基地
文章浏览阅读8k次。不管是手机还是电脑,刚买的时候运行都是挺快的,时间用久了,就开始出来卡顿和反应慢的现象。那么电脑很卡是什么原因?是什么原因造成电脑卡顿的呢?恐怕很多用户都不是很了解,下面,小编就来跟大家分享电脑卡的原因有哪些。电脑是与我们生活越来越相关的一个物品,使用电脑也成了我们聊天,学习,娱乐甚至工作的新方式,这时候,一个流畅的电脑使用就很重要了,电脑卡顿的原因有许多,为了用户更好的了解,下面,小编就来跟大家..._电脑很卡是什么原因
【计算机毕设文章】基于微信小程序的电子竞技信息交流 平台的设计与实现-程序员宅基地
文章浏览阅读31次。毕业论文(设计)题目(中文):基于微信小程序的电子竞技信息交流平台的设计与实现姓 名 学 号 院 (系) 专业、年级 指导教师2021年5月6日目 录1 绪 论 11.1课题研究背景 11.2设计原则 11.3研究内容 22系统关键技术 32.1 微信小程序 32.2微信Web开发者工具 32.3微信小程序API接口 32.4 WXML 、WXS、JS小程序编写语言 32.5 MYSQL数据库 43系统分析 53.1可行性分析 53.1.1
java https请求,https请求如何调用-程序员宅基地
文章浏览阅读1.1w次,点赞9次,收藏28次。https请求如何在代码中调用