Windows下安装Hive(包安装成功)_windows安装hive-程序员宅基地
Windows下安装Hive
Hive与Hadoop的版本选择很关键,千万不能选错,否则各种报错。
本篇
Hadoop版本为:2.7.2
Hive版本为:2.3.5
请严格按照版本来安装。
一、Hive
1.1、Hive简介
- Hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为MapReduce任务运行,通过自己的SQL查询分析需要的内容,这套SQL简称Hive SQL,使不熟悉mapreduce的用户可以很方便地利用SQL语言查询、汇总和分析数据。
- 而mapreduce开发人员可以把自己写的mapper和reducer作为插件来支持Hive做更复杂的数据分析。它与关系型数据库的SQL略有不同,但支持了绝大多数的语句如DDL、DML以及常见的聚合函数、连接查询、条件查询。它还提供了一系列的工具进行数据提取转化加载,用来存储、查询和分析存储在Hadoop中的大规模数据集,并支持UDF(User-Defined Function)、UDAF(User-Defined AggregateFunction)和UDTF(User-Defined Table-Generating Function),也可以实现对map和reduce函数的定制,为数据操作提供了良好的伸缩性和可扩展性。
- Hive不适合用于联机(online)事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。
1.2、Hive适用场景
- Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。
- 因此,Hive 并不适合那些需要高实时性的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的hiveSQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
1.3、Hive设计特征
Hive 是一种底层封装了Hadoop 的数据仓库处理工具,使用类SQL 的HiveSQL 语言实现数据查询,所有Hive 的数据都存储在Hadoop 兼容的文件系统(例如,Amazon S3、HDFS)中。Hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS 中Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。Hive 的设计特点如下。
- 支持创建索引,优化数据查询。
- 不同的存储类型,例如,纯文本文件、HBase 中的文件。
- 将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。
- 可以直接使用存储在Hadoop 文件系统中的数据。
- 内置大量用户函数UDF 来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF 函数来完成内置函数无法实现的操作。
- 类SQL 的查询方式,将SQL 查询转换为MapReduce 的job 在Hadoop集群上执行。
1.4、Hive体系结构
主要分为以下几个部分:
1.4.1、用户接口
- 用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 Cli,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
1.4.2、元数据存储
- Hive 将元数据存储在数据库中,如 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
1.4.3、解释器、编译器、优化器、执行器
- 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
1.4.4、Hadoop
- Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(不包含 * 的查询,比如 select * from tbl 不会生成 MapReduce 任务)。
1.5、Hive数据模型
Hive中包含以下四类数据模型:表(Table)、外部表(External Table)、分区(Partition)、桶(Bucket)。
1.5.1、Hive数据模型 - 表(Table)
- Hive中的Table和数据库中的Table在概念上是类似的。在Hive中每一个Table都有一个相应的目录存储数据。
1.5.2、Hive数据模型 - 外部表(External Table)
- 外部表是一个已经存储在HDFS中,并具有一定格式的数据。使用外部表意味着Hive表内的数据不在Hive的数据仓库内,它会到仓库目录以外的位置访问数据。
- 外部表和普通表的操作不同,创建普通表的操作分为两个步骤,即表的创建步骤和数据装入步骤(可以分开也可以同时完成)。在数据的装入过程中,实际数据会移动到数据表所在的Hive数据仓库文件目录中,其后对该数据表的访问将直接访问装入所对应文件目录中的数据。删除表时,该表的元数据和在数据仓库目录下的实际数据将同时删除。
- 外部表的创建只有一个步骤,创建表和装入数据同时完成。外部表的实际数据存储在创建语句。LOCATION参数指定的外部HDFS文件路径中,但这个数据并不会移动到Hive数据仓库的文件目录中。删除外部表时,仅删除其元数据,保存在外部HDFS文件目录中的数据不会被删除。
1.5.3、Hive数据模型 - 分区(Partition)
- 分区对应于数据库中的分区列的密集索引,但是hive中分区的组织方式和数据库中的很不相同。在Hive中,表中的一个分区对应于表下的一个目录,所有的分区的数据都存储在对应的目录中。
1.5.4、Hive数据模型 - 桶(Bucket)
- 桶对指定列进行哈希(hash)计算,会根据哈希值切分数据,目的是为了并行,每一个桶对应一个文件。
二、Hive下载
2.1、官网下载Hive
https://dlcdn.apache.org/hive/
2.2、网盘下载Hive
如果嫌慢,可以网盘下载:链接:
https://pan.baidu.com/s/1axk8C4Zw7CUuP1b1SGPyPg?pwd=yyds
三、解压安装包,配置Hive环境变量
解压安装包到(D:\bigdata\hive\2.3.5),注意路径不要有空格。
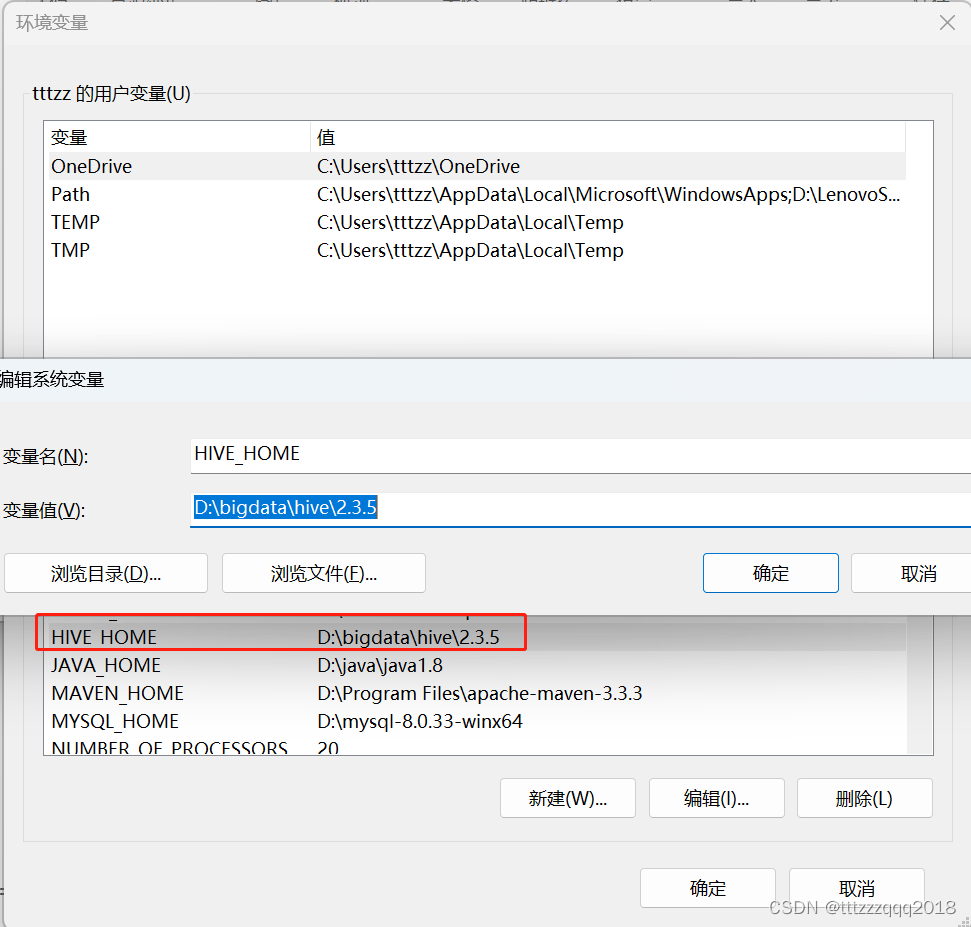
3.1、环境变量新增:HIVE_HOME
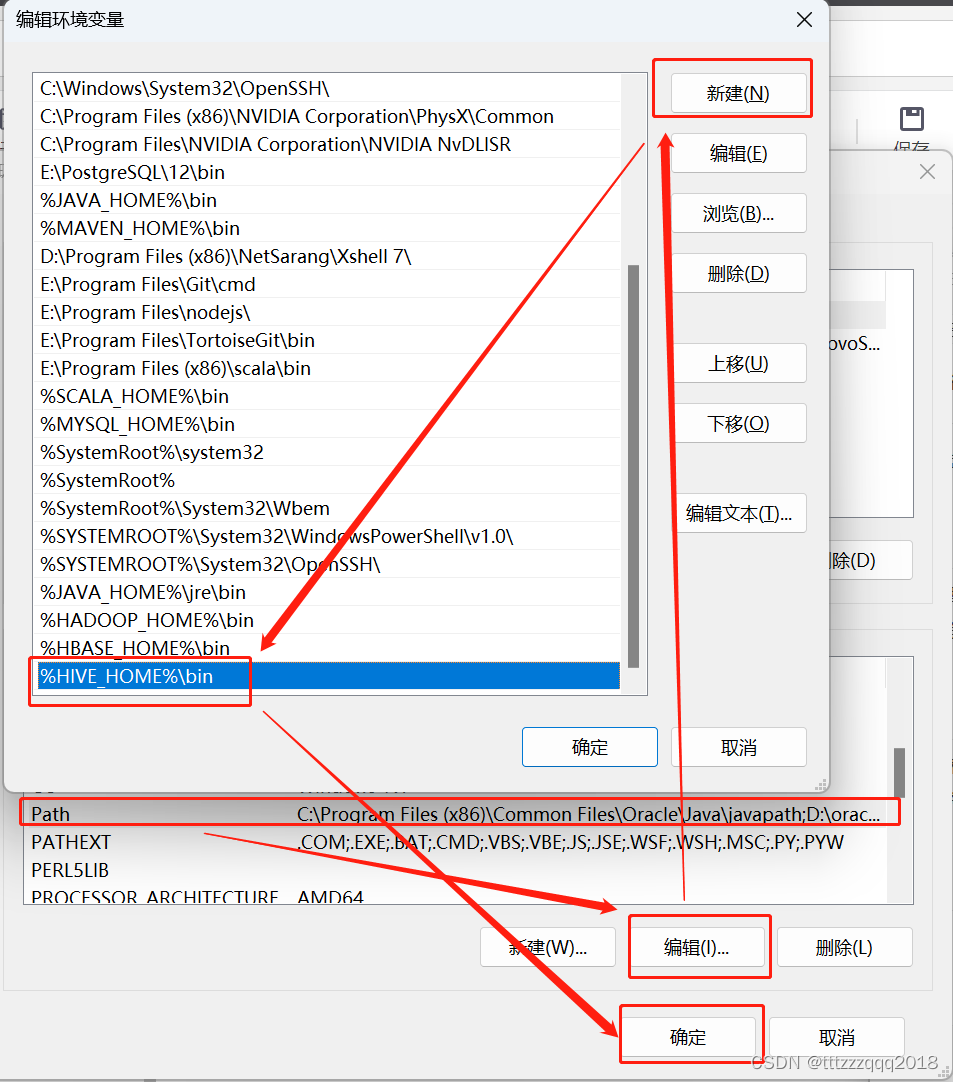
3.2、修改Path环境变量,增加Hive的bin路径
四、解决“Windows环境中缺少Hive的执行文件和运行程序”的问题
Hive 的Hive_x.x.x_bin.tar.gz 高版本在windows 环境中缺少 Hive的执行文件和运行程序。
解决方法:
4.1、下载低版本Hive(apache-hive-2.0.0-src)
下载地址:http://archive.apache.org/dist/hive/hive-2.0.0/apache-hive-2.0.0-bin.tar.gz
或者网盘下载:https://pan.baidu.com/s/1exyrc51P4a_OJv2XHYudCw?pwd=yyds
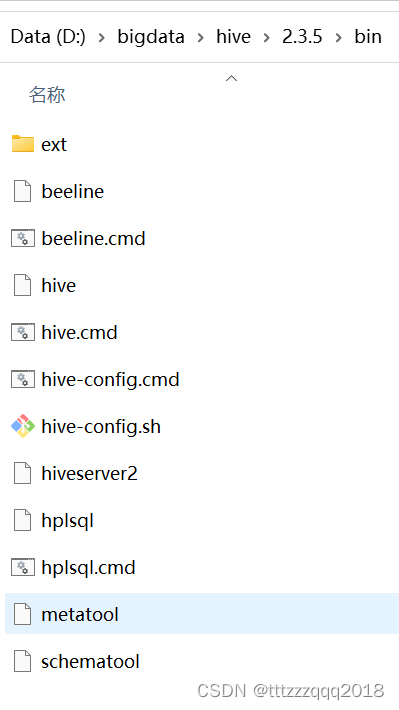
4.2、将低版本Hive的bin目录替换Hive原有的bin目录(D:\bigdata\hive\2.3.5\bin)
替换后:
五、给Hive添加MySQL的jar包
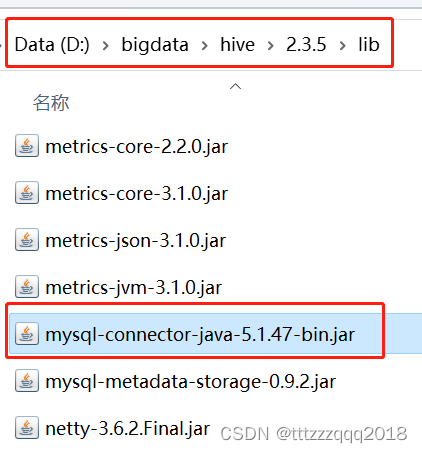
下载和拷贝一个 mysql-connector-java-5.1.47-bin.jar 到 $HIVE_HOME/lib 目录下。
5.1、下载连接MySQL的依赖jar包“mysql-connector-java-5.1.47-bin.jar”
官网下载地址:https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-5.1.47.zip
或者网盘下载:https://pan.baidu.com/s/1X6ZGyy3xNYI76nDoAjfVVA?pwd=yyds
5.2、拷贝到$HIVE_HOME/lib目录下
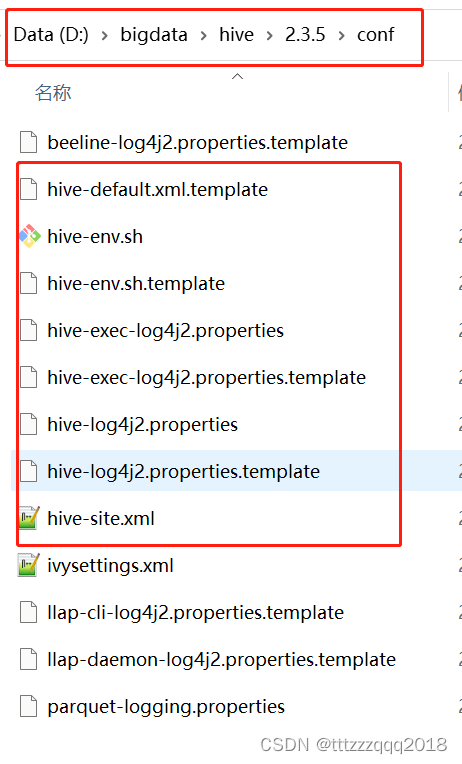
六、创建Hive配置文件(hive-site.xml、hive-env.sh、hive-log4j2.properties、hive-exec-log4j2.properties)
配置文件目录(%HIVE_HOME%\conf)有4个默认的配置文件模板拷贝成新的文件名
| 原文件名 | 拷贝后的文件名 |
|---|---|
| hive-log4j.properties.template | hive-log4j2.properties |
| hive-exec-log4j.properties.template | hive-exec-log4j2.properties |
| hive-env.sh.template | hive-env.sh |
| hive-default.xml.template | hive-site.xml |
七、新建Hive本地目录
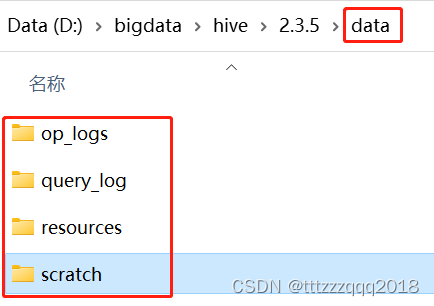
后面Hive的配置文件用到下面这些目录:
先在Hive安装目录下建立 data 文件夹,
然后再到在这个文件夹下建
op_logs
query_log
resources
scratch 这四个文件夹,建完后如下图所示:
八、修改Hive配置文件
8.1、修改Hive配置文件 hive-env.sh
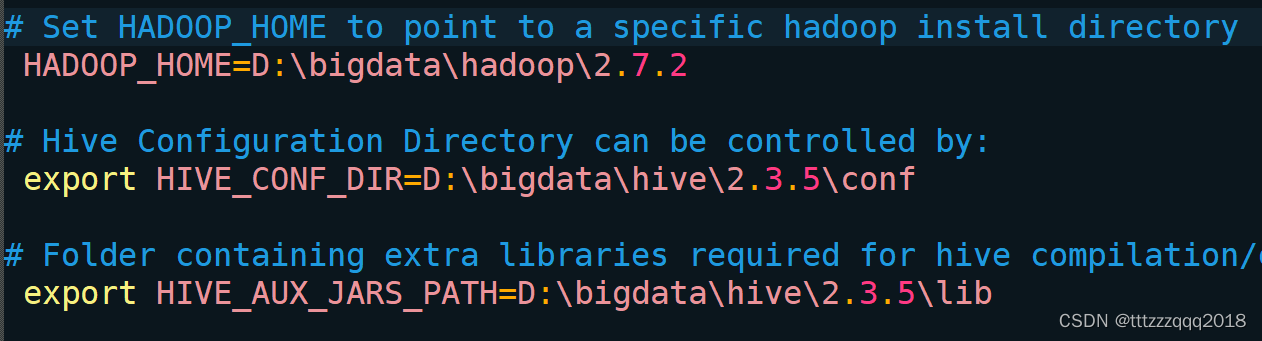
编辑 conf\hive-env.sh 文件:
根据自己的Hive安装路径(D:\bigdata\hive\2.3.5),添加三条配置信息:
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=D:\bigdata\hadoop\2.7.2
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=D:\bigdata\hive\2.3.5\conf
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=D:\bigdata\hive\2.3.5\lib
8.2、修改Hive配置文件 hive-site.xml
编辑 conf\hive-site.xml 文件:
根据自己的Hive安装路径(D:\bigdata\hive\2.3.5),修改下面几个参数的配置:
<property>
<name>hive.exec.local.scratchdir</name>
<value>D:/bigdata/hive/2.3.5/data/scratch</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>D:/bigdata/hive/2.3.5/data/op_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>D:/bigdata/hive/2.3.5/data/resources/${hive.session.id}_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3307/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
修改后的 hive-site.xml 下载地址:https://pan.baidu.com/s/1PvTCc_6Cu-1HJ44E2vEFQg?pwd=yyds
九、启动Hadoop
9.1、启动Hadoop
Hadoop安装及启动,请看这篇博文:Windows下安装Hadoop(手把手包成功安装)
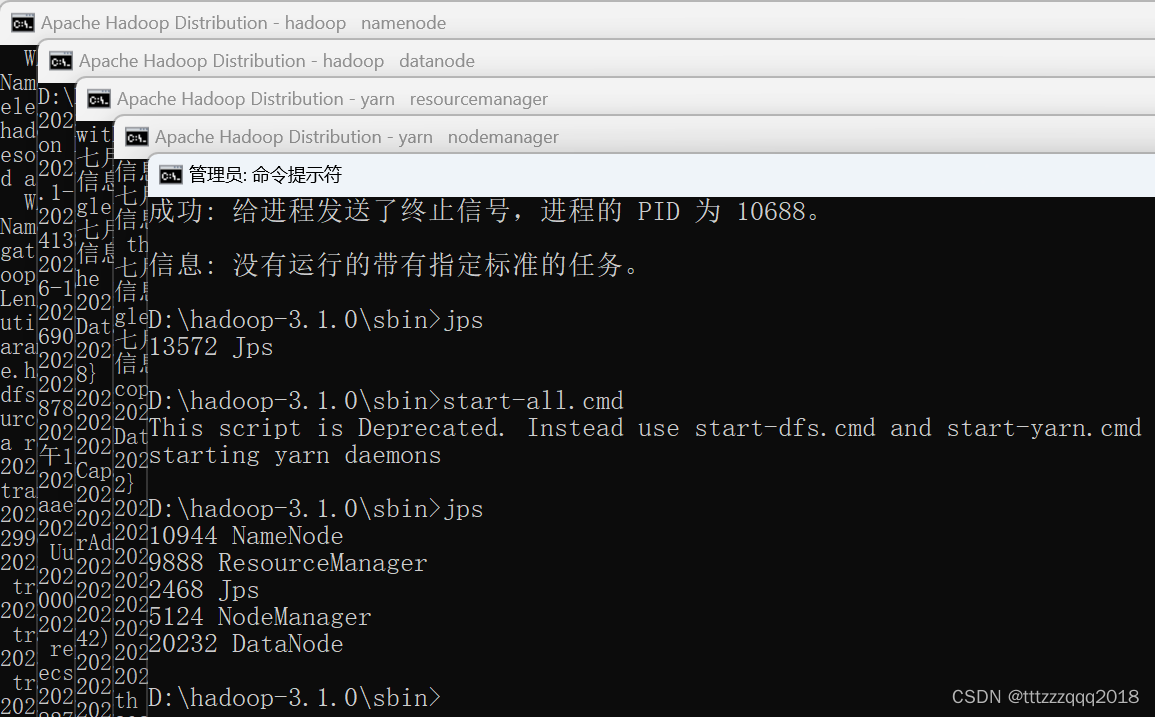
可以通过访问namenode和HDFS的Web UI界面(http://localhost:50070)
以及resourcemanager的页面(http://localhost:8088)
9.2、在Hadoop上创建HDFS目录并给文件夹授权(选做,可不做)
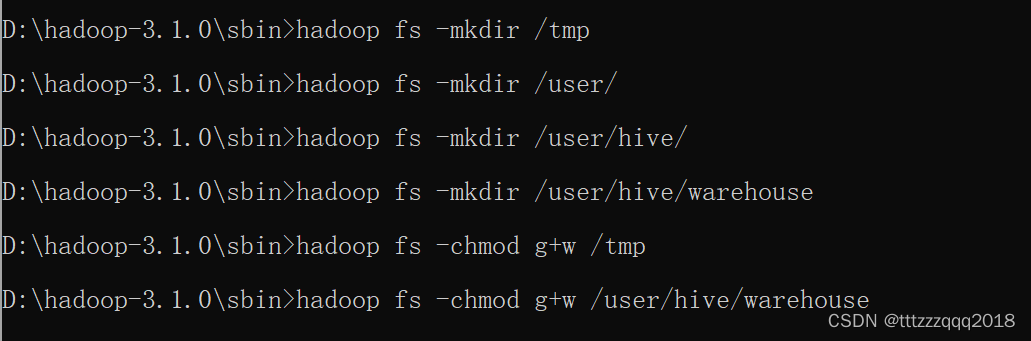
使用命令:
hadoop fs -mkdir /tmp
hadoop fs -mkdir /user/
hadoop fs -mkdir /user/hive/
hadoop fs -mkdir /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
或者使用命令:
hdfs dfs -mkdir /tmp
hdfs dfs -chmod -R 777 /tmp
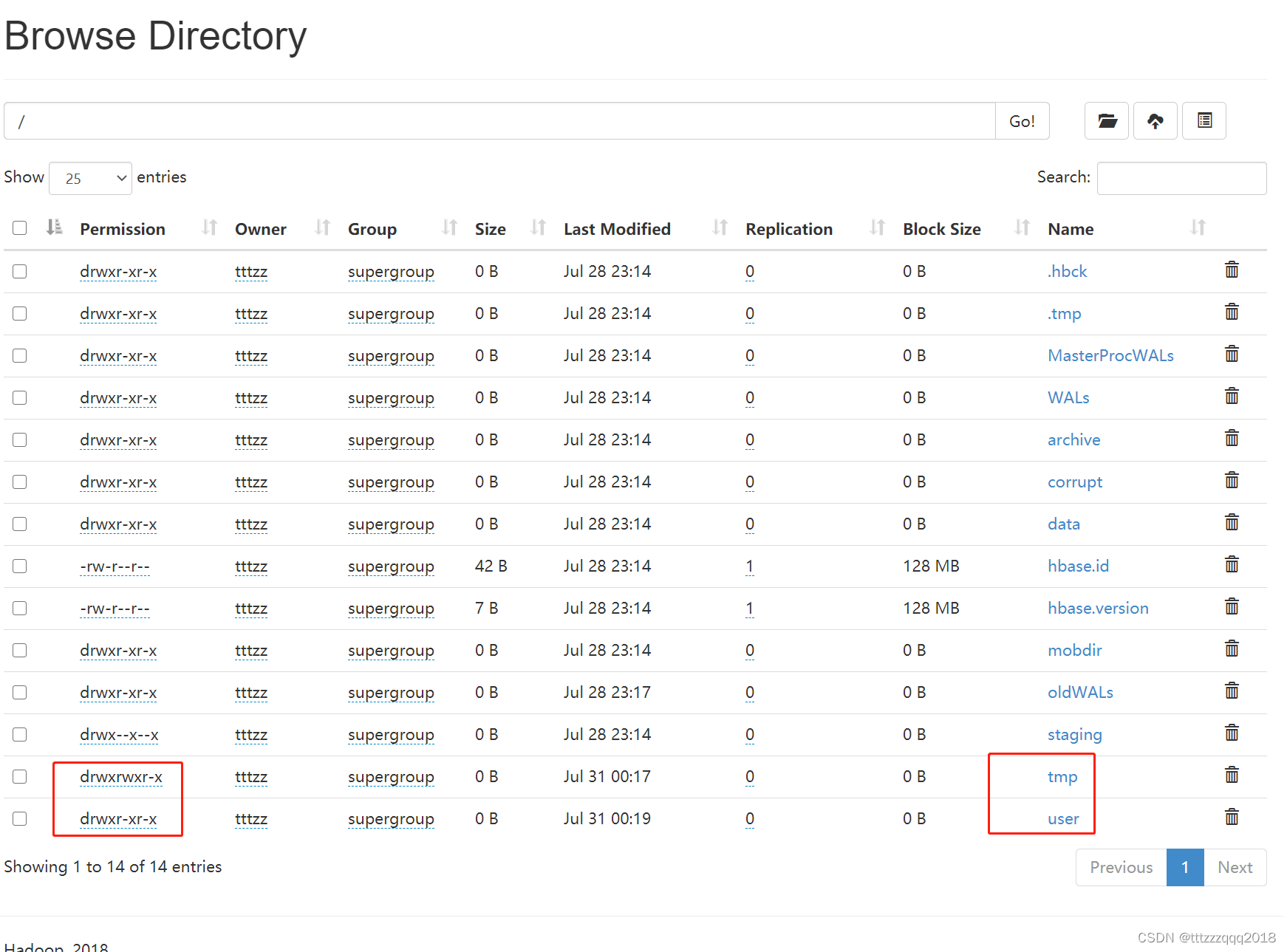
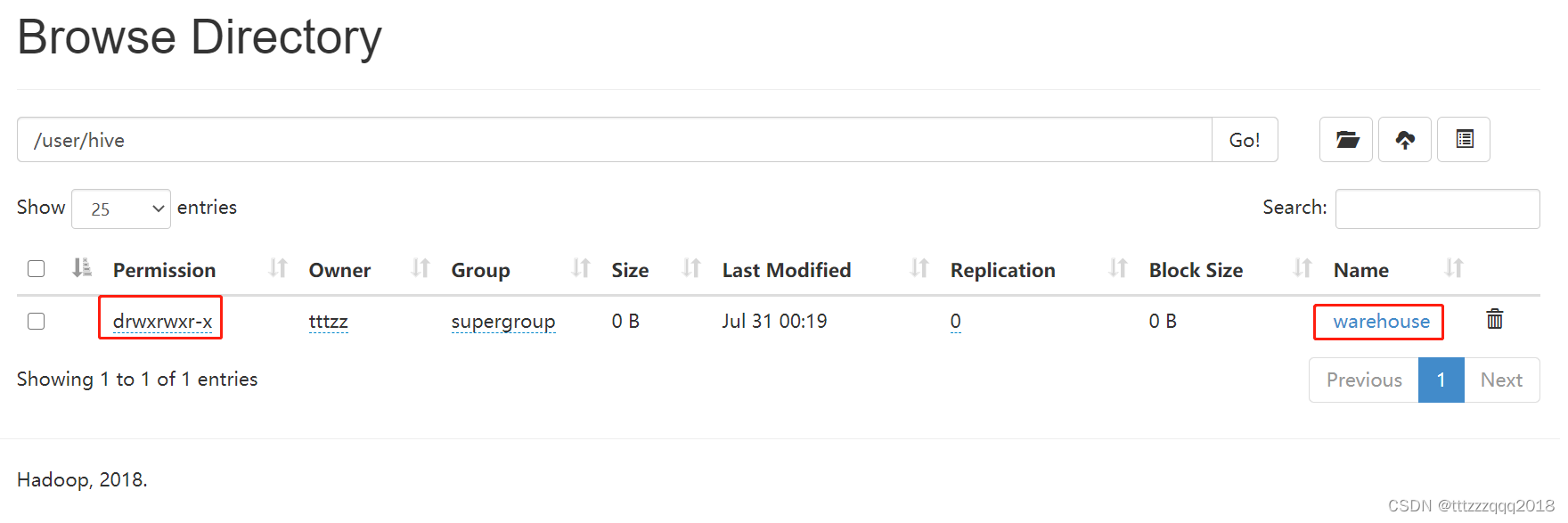
在Hadoop管理台(http://localhost:50070/explorer.html#/)可以看相应的情况:
十、启动Hive服务
10.1、初始化Hive元数据库(采用MySQL存储元数据)
在%HIVE_HOME%/bin目录下执行下面的脚本:
hive --service schematool -dbType mysql -initSchema
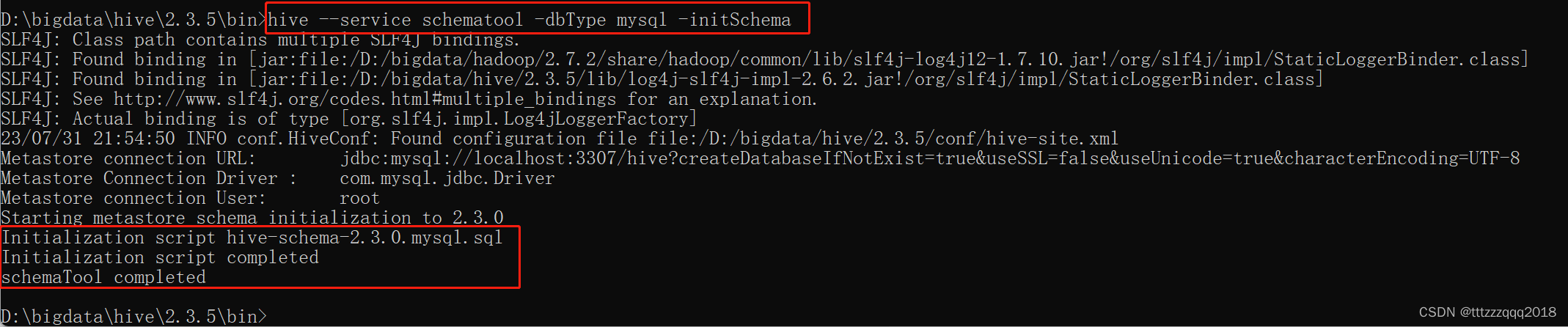
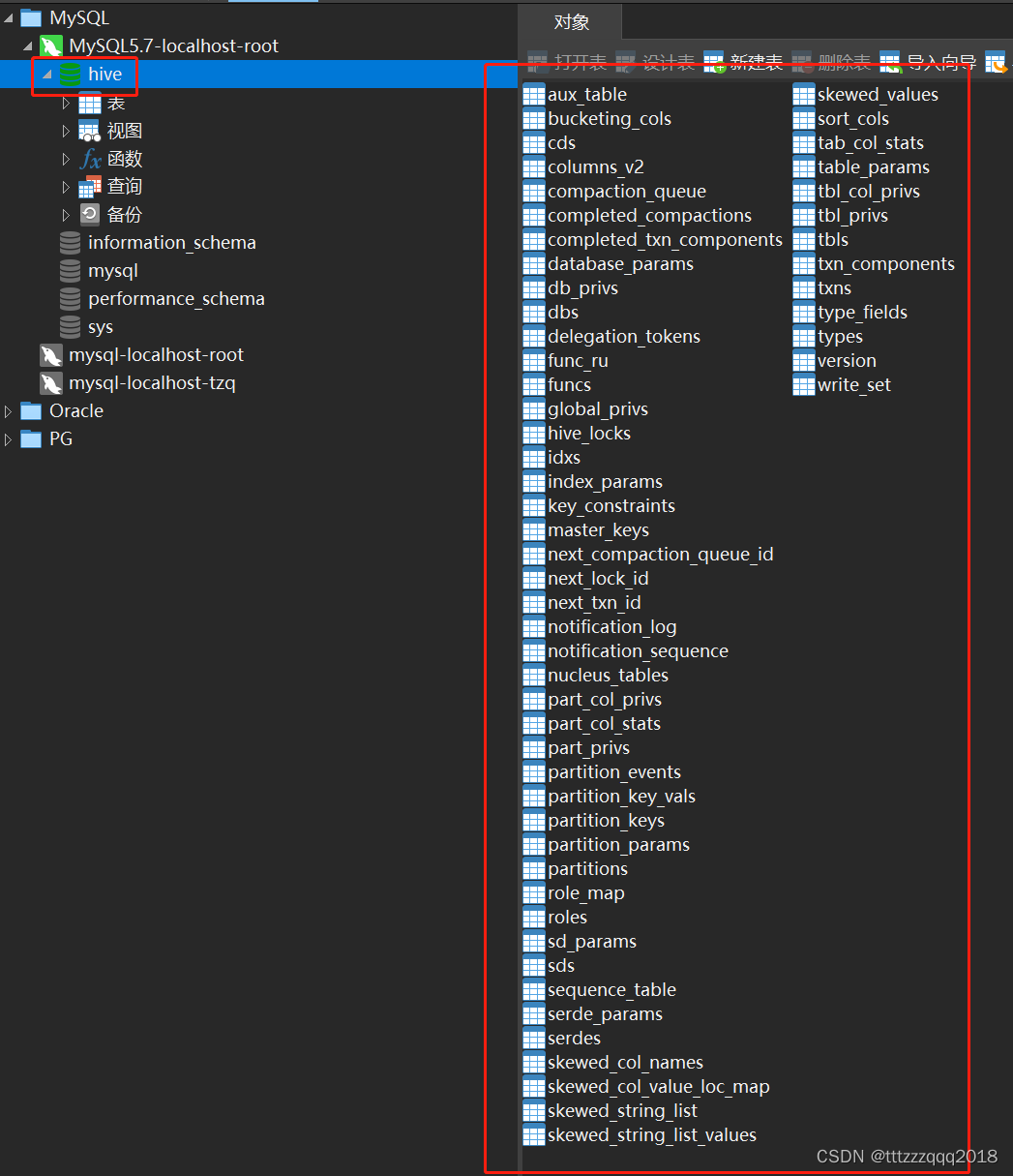
可以发现,Hive会自动连接MySQL去创建schema hive,并执行脚本。
10.2、启动并进入Hive
输入hive,进入hive:
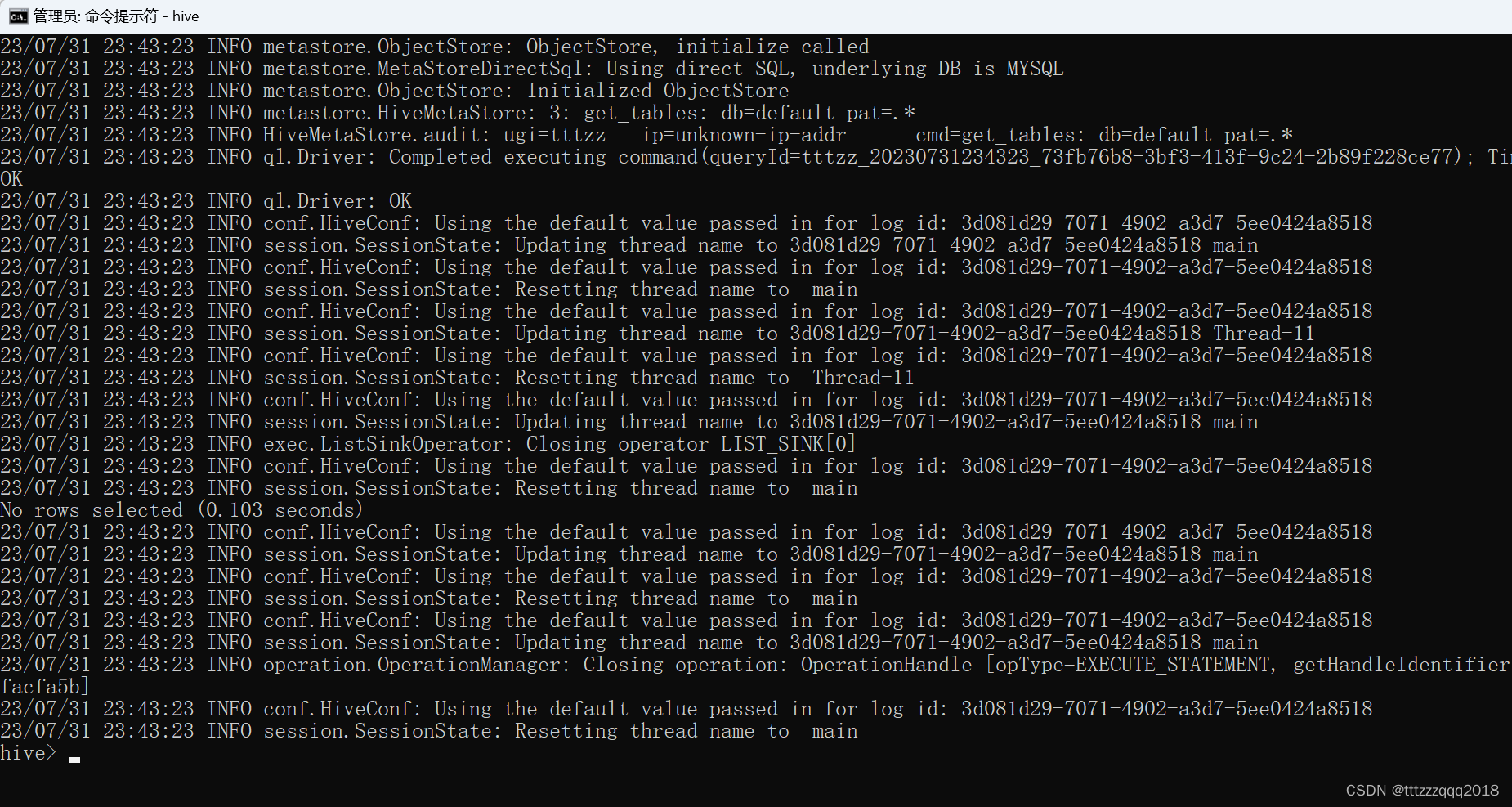
至此,Hive在Windows下安装成功了!
智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数