手把手带你玩转Spark机器学习-Spark的安装及使用_spark 安装使用-程序员宅基地
技术标签: Spark安装 spark hadoop 手把手带你玩转Spark机器学习 big data
系列文章目录
- 手把手带你玩转Spark机器学习-专栏介绍
- 手把手带你玩转Spark机器学习-问题汇总
- 手把手带你玩转Spark机器学习-Spark的安装及使用
- 手把手带你玩转Spark机器学习-使用Spark进行数据处理和数据转换
- 手把手带你玩转Spark机器学习-使用Spark构建分类模型
- 手把手带你玩转Spark机器学习-使用Spark构建回归模型
- 手把手带你玩转Spark机器学习-使用Spark构建聚类模型
- 手把手带你玩转Spark机器学习-使用Spark进行数据降维
- 手把手带你玩转Spark机器学习-使用Spark进行文本处理
- 手把手带你玩转Spark机器学习-深度学习在Spark上的应用
文章目录
前言
本文主要介绍了Apache的基础知识及Spark环境的搭建和运行。
一、Apache Spark的基础知识

几年前,Spark被其创造者定义成:A fast and general engine for large-scale data processing(用于大规模数据处理的快速通用引擎)。
其中"Fast"意味着它比以前的大数据处理方法更快(例如Hadoop的Mapreduce)。更快的秘诀在于Spark在内存(RAM)上运行,这使得处理速度比在磁盘上快的多。
"General"部分意味着它可以用于多种用途,例如运行分布式SQL、创建数据管道、将数据存储到数据库、运行机器学习算法、处理图形、数据流等等。现在随着Apache Spark项目的发展,Spark几乎可以做数据科学或机器学习工作流程中的所有事情,我们也可以将Spark框架单独应用到深度学习这样的端到端项目中。
“Large-scale"意味着这是一个可以完美处理大量数据的框架,我们过去称之为"大数据”。
RDD
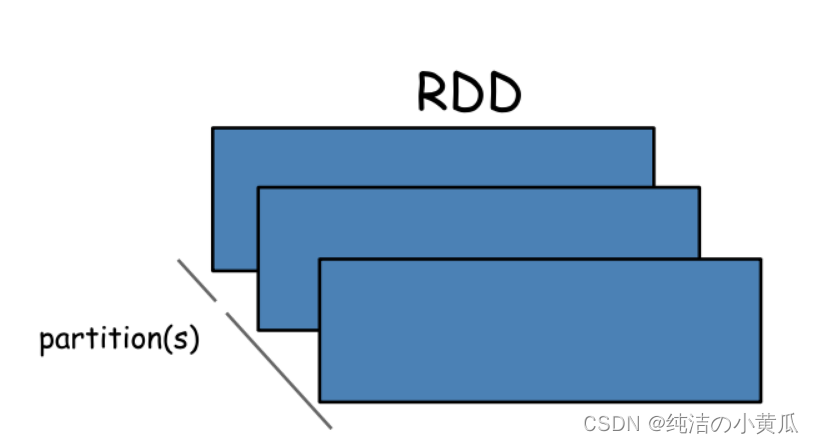
Apache Spark的核心抽象和起源是弹性分布式数据集(RDD)。
RDD是可以并行操作且具有一定容错性的元素集合。你可以在驱动程序中并行创建现有集合,或引用外部存储系统中的数据集,例如共享文件系统、HDFS、HBase或任何提供Hadoop InputFormat的数据源。
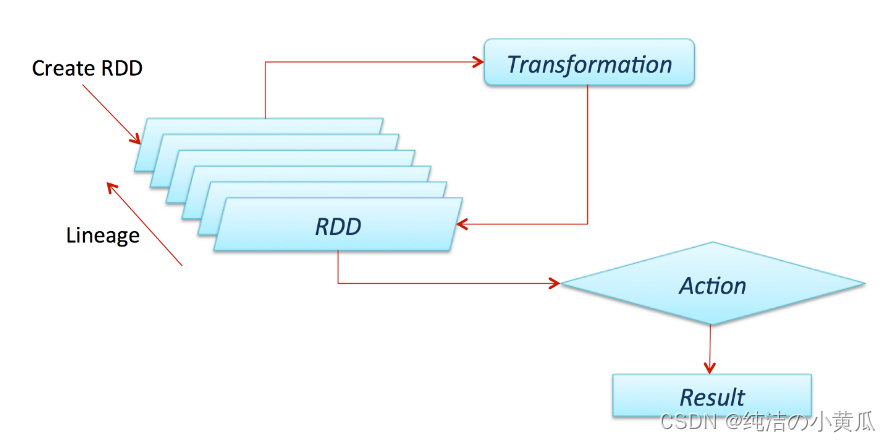
关于Spark其中有个非常重要的点是所有的Transformation操作都是不立即生效的,换句话说,Spark不会立即计算它的结果。相反,Spark只是记录下来对某些基础数据(例如文件)的Transformation操作。这些Transformation操作只会在Action需要将结果返回给驱动程序的时候才进行计算操作。
默认情况下,每个Transformation后的 RDD 可能会在模每次对其运行操作时重新计算。但是,你也可以使用Persist(或Cache)方法将 RDD 持久化在内存中,在这种情况下,Spark 会将元素保留在集群上,以便下次查询时更快地访问它。Spark还支持在磁盘上持久化 RDD 或跨多个节点复制的操作。
DataFrame
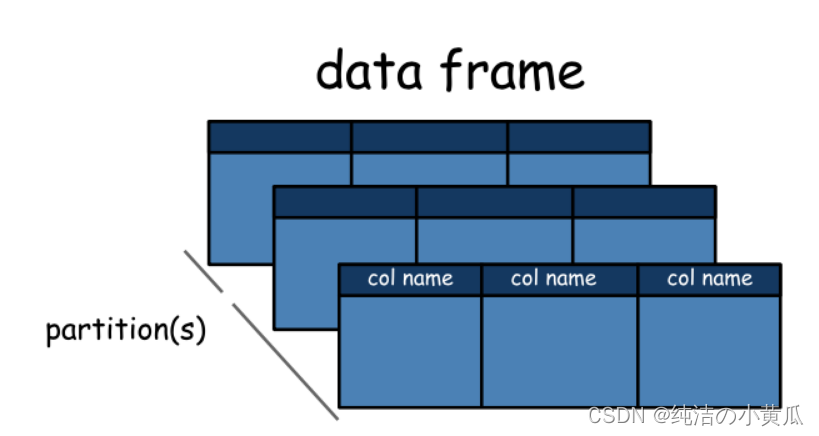
从 Spark 2.0.0 开始,DataFrame 是一个被组织成带有字段名的数据集【表格数据】。它在概念上等同于关系数据库中的表或 R/Python 中的 DataFrame,但在底层进行了更丰富的优化。
如下图所示,DataFrames 可以从多种来源构建,例如:结构化数据文件、Hive 中的表、外部数据库或现有 RDD。
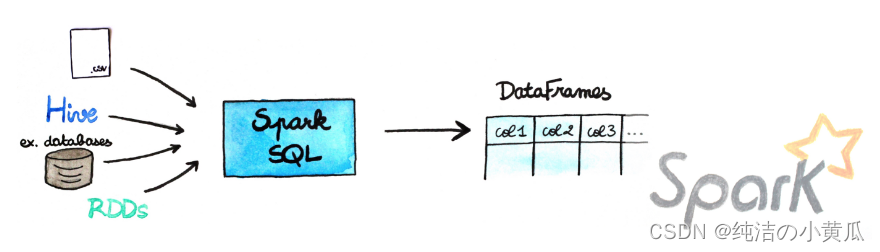
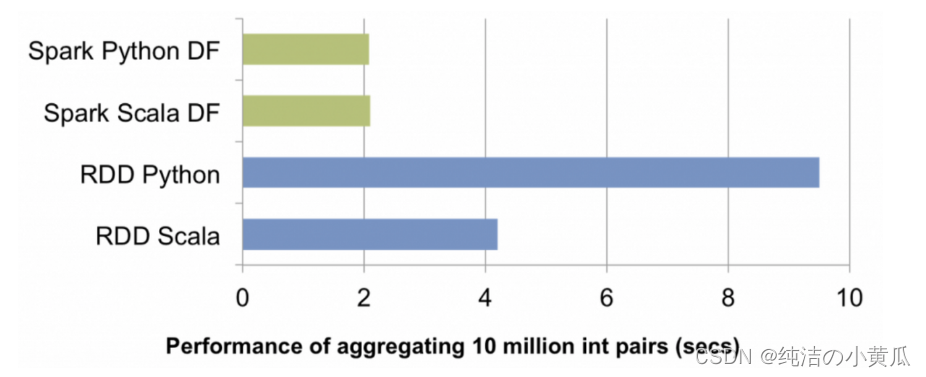
简而言之,Dataframes API 是 Spark creators 中的一种方法,可让你在框架中轻松使用数据。它们与 Pandas Dataframes 或 R Dataframes 非常相似,但有几个优点。第一个当然是它们可以被缓存在一个集群的内存里,因此它们可以处理大量数据,第二个是这种数据结构是经过特殊优化的,可以适配分布式环境。
在Spark发展起初,将 Spark 与 Scala 或 Java 一起使用要快得多。随着python语言越来越普及以及Spark整个生态的发展,使用 DF API,这不再是问题,现在我们可以在 R、Python、Scala 或 Java 中使用Spark获得相同的性能。
负责此优化的是 Catalyst。你可以把它想象成一个“巫师”,它会接受你的查询( 类似 SQL 的查询,它们也会被并行化)和操作并针对分布式计算进行优化。
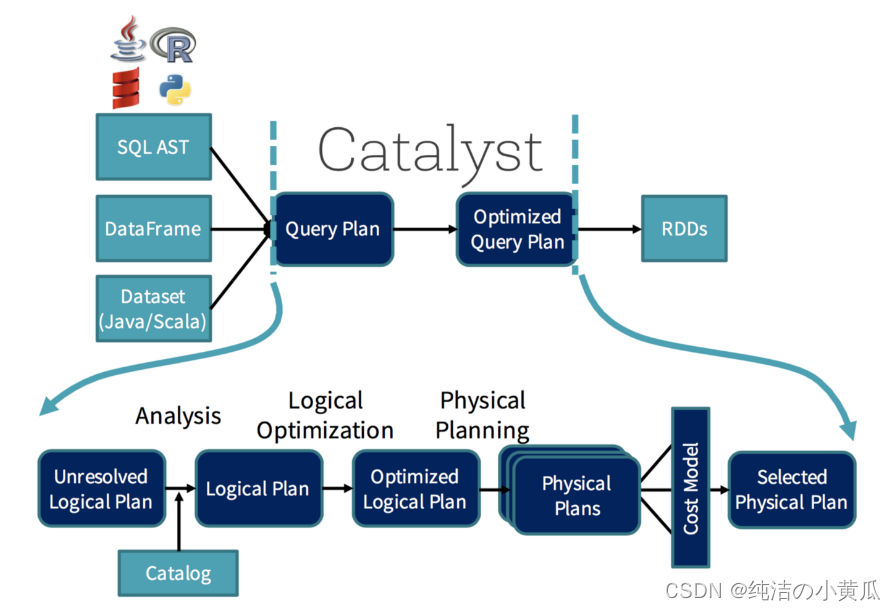
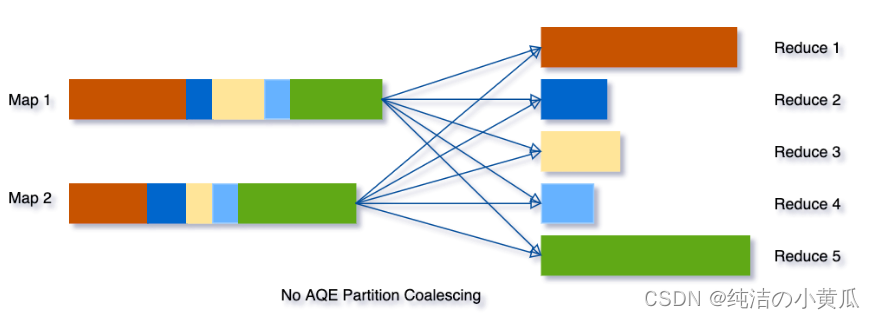
如上图所示,这个过程并不是那么简单,但作为程序员的你甚至不会注意到它,只是它一直在那里帮助你。 在 Spark 3.0 中,新增了一个“自适应查询执行”(AQE)的东西,它将根据在查询执行过程中收集到的统计信息重新优化和调整查询计划。这将对性能产生巨大影响,例如,假设我们正在运行查询
SELECT max(i) FROM table GROUP BY column
如果没有AQE,Spark将启动五个任务来进行最终数据的聚合:
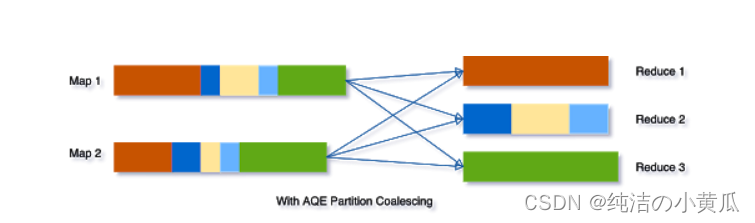
但是使用 AQE,Spark 会将上图中间的三个小分区合并为一个,因此,最终聚合现在只需要执行三个任务而不是五个:
二、安装及使用Spark
注意::
- "$"符号表示在shell中运行(但是不要复制该符号)
- “>>>”符号表示 Python shell(不要复制该符号)
Spark能通过内置的单机集群调度器在本地运行。此时,所有的Spark进程运行在同一个java虚拟机中。这实际上构造了一个独立、多线程版本的Spark环境。本地模式很适合程序的原型设计、开发、调试和测试。同样它也适用于在单机上进行多核并行计算的实际场景。
Spark的本地模式和集群模式完全兼容,本地编写和测试过的代码仅需要增加少许设置便能在集群上运行。
- 下载预编译包
首先第一步访问Spark项目的下载页面:https://spark.apache.org/downloads.html。一版选择最新的Spark版本包
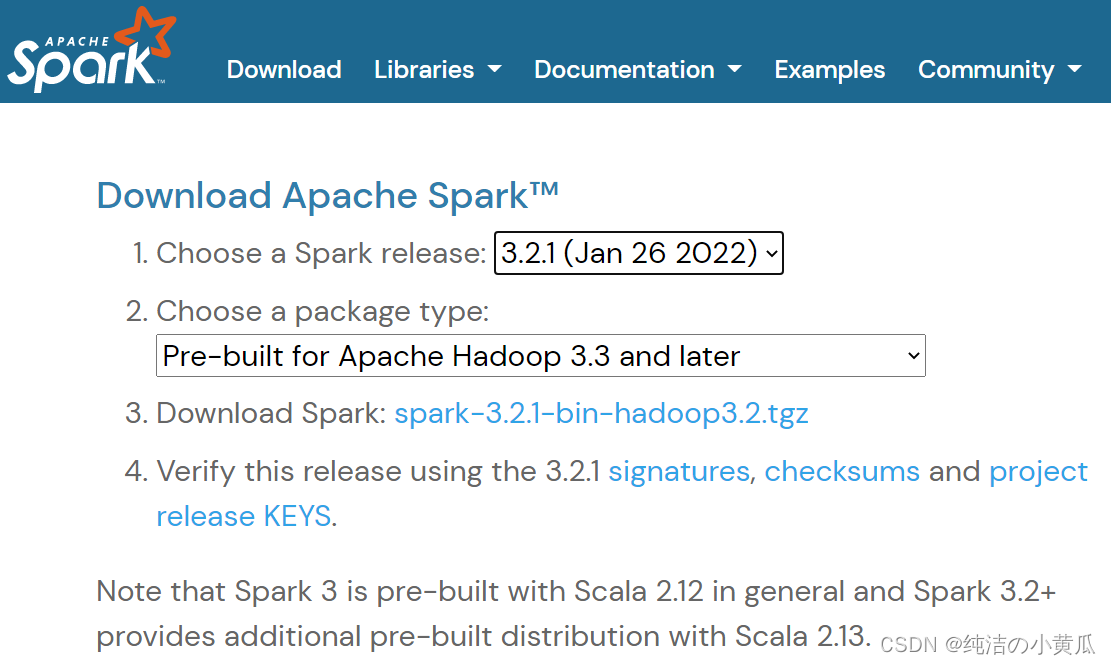
如上图所示,各个版本的版本包及源代码的github地址可以从Spark项目的下载页面找到。为了访问HDFS(Hadoop分布式文件系统)以及标准或定制的Hadoop输入源,Spark的编译版本要与Hadoop的版本对应。如上图所示,上面下载页面提供了针对Hadoop2.7的预编译版本。除非你想构建针对特定版本hadoop的Spark,否则还是建议你通过下载页面的推荐链接下载预编译的二进制包。在安装Spark之前,还要确保电脑上已经安装好了Java 8+以及anaconda。例如作者选了一台linux服务器,下载了spark-3.2.1预编译包及对应的hadoop3.3的预编译包,Java版本java1.8.0_251,python3.7。
- 解压并创建软链
下载完上述版本的包后,解压缩并将其移动到你的 /opt 文件夹下:
$ tar -xzf spark-3.2.1-bin-hadoop3.3.tgz
$ mv spark-3.2.1-bin-hadoop3.3 /opt/spark-3.2.1-bin-hadoop3.3
创建软链
$ ln -s /opt/spark-3.2.1-bin-hadoop3.3 /opt/spark̀
- 添加环境变量
最后,告诉你的 bash(或 zsh 等)在哪里可以找到 spark。为此,通过在 ~/.bashrc(或 ~/.zshrc)文件中添加以下行来配置 $PATH 变量:
export SPARK_HOME=/opt/spark
export PATH=$SPARK_HOME/bin:$PATH
- 安装pysaprk
这边使用清华源,下载快点
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
- 在IDE中使用PySpark
有时你需要一个完整的 IDE 来创建更复杂的代码,而 PySpark 默认不在 sys.path 上,但这并不意味着它不能用作常规库。你可以通过在运行时将 PySpark 添加到 sys.path 来解决此问题。findspark可以做到这点,可以输入如下命令:
$ pip install findspark
然后在你的 IDE(我使用的PyCharm)上初始化 PySpark,只需在代码中输入:
import findspark
findspark.init()
三、Spark编程模型及Spark python编程入门
SparkContext类与SparkConf类
任何Spark程序的编写都是从SparkContext开始的。SparkContext的初始化需要一个SparkConf对象,后者包含了Spark集群配置的各种参数(比如说主节点的URL)。
初始化后,我们便可以用SparkContext对象所包含的各种方法来创建或者操作分布式数据集和共享变量。Spark shell可以自动完成上述初始化:
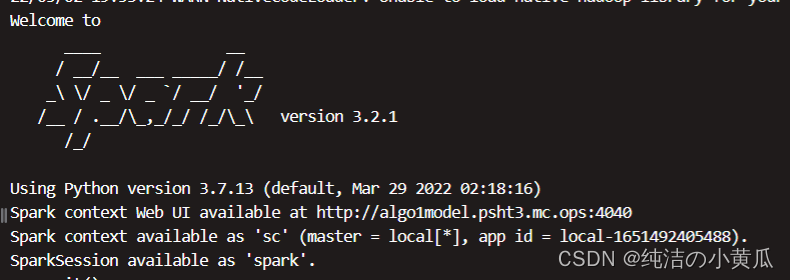
若是用python代码来实现的话。可以参考下面的代码:
import findspark
findspark.init()
from pyspark import SparkContext, SparkConf
conf = SparkConf() \
.setAppName('First Application') \
.setMaster("local[4]")
sc = SparkContext(conf=conf)
上述代码会创建一个四线程的SparkContext对象,并将其相应的任务命名为“First Application”。
编写第一个Spark python应用程序:计算pi
如下所示,我们编写了一个计算Pi的应用程序:
import findspark
findspark.init()
import random
from pyspark import SparkContext
sc = SparkContext(appName="EstimatePi")
def inside(p):
x, y = random.random(), random.random()
return x*x + y*y < 1
NUM_SAMPLES = 1000000
count = sc.parallelize(range(0, NUM_SAMPLES)) \
.filter(inside).count()
print("Pi is roughly %f" % (4.0 * count / NUM_SAMPLES))
sc.stop()

总结
本文首先介绍了Spark的基础知识以及RDD和DataFrame这些核心概念,然后演示了如何下载Spark二进制版本并搭建一个本地单机模式下的开发环境,最后通过Python语言来编写第一个Spark程序。
智能推荐
嵌入式怎么入门,嵌入式应该先学习什么_学fpga用先学嵌入式吗-程序员宅基地
文章浏览阅读1.8k次,点赞2次,收藏15次。嵌入式到底是什么,很多对这个概念都很迷糊,许多人都认为这是工程师的代名词。嵌入式工程师可以说是目前涵盖面最广、最火的职业之一,那么到底什么是嵌入式呢?狭义上嵌入式系统由硬件和软件组成.是能够独立进行运作的器件广义上嵌入式是一种系统首先,我想说的是嵌入式有很多种,例如嵌入式系统,嵌入式软件,Linux 嵌入式,Android 嵌入式,嵌入式 Web。一.嵌入式用途有什么1.共享单车2.丰巢快递柜3.充电桩4.智能家居5.Android 嵌入式开发.._学fpga用先学嵌入式吗
解决Could not find artifact org.springframework.boot:spring-boot-starter-parent:pom:2.6.2 in alimaven-程序员宅基地
文章浏览阅读2k次,点赞10次,收藏7次。在部署SpringBoot项目时遇到pom所有版本号爆红,而报错只有标题中的那句话,尝试了多种方法即便不再报错但仍爆红。在查阅和尝试了多种方法后,我决定删除之前的maven镜像配置尝试一下。_could not find artifact org.springframework.boot:spring-boot-starter-parent:
多个el-select下拉框无法选中相同内容_两个el-option 限制重复选择-程序员宅基地
文章浏览阅读786次。多个el-select下拉框无法选中相同内容。_两个el-option 限制重复选择
Android qualcomm WCNSS_qcom_cfg.ini_genablebmps-程序员宅基地
文章浏览阅读1.2k次。本文介绍WCNSS_qcom_cfg.ini中常用参数的作用。wifi 日志等级vosTraceEnableBAP=255 vosTraceEnableTL=255 vosTraceEnableWDI=255 vosTraceEnableHDD=255 vosTraceEnableSME=255 vosTraceEnablePE=255 vosTraceEnablePMC=255 vosTraceEnableWDA=255 vosTraceEnableSYS=255 vosTrac_genablebmps
剑指offer第五题:替换空格_class solution: # s 源字符串 def replacespace(self, s)-程序员宅基地
文章浏览阅读272次。思路应该使用指针从后向前替换字符串。不过python用不到。 class Solution: # s 源字符串 def replaceSpace(self, s): # write code here new_s='' for j in s: if j==' ': ne..._class solution: # s 源字符串 def replacespace(self, s): # write code here if
python学习之滚动页面函数execute_script-程序员宅基地
文章浏览阅读1.4w次,点赞7次,收藏60次。python学习之滚动页面函数execute_script滚动到底部:window.scrollTo(0,document.body.scrollHeight)滚动到顶部:window.scrollTo(0,0)说明:window:js的window对象scrollTo():window的方法,可以滚到页面的任何位置scrollHeight:是dom元素的通用属性,docu..._execute_script
随便推点
App上架/更新怕被拒? iOS过审“避雷秘籍”请查收 -程序员宅基地
文章浏览阅读67次。苹果爸爸对 App Store 的监管力度正在不断加强。2018年下半年,下架的App数量比上半年多161%,但上架的App却只增长了47%。上架困难成为App开发者们很揪心的事情。众所周知,应用在上架至App Store前,必须通过神秘的苹果审核团队的审核。能否在短时间内顺利通过审核,对App推广节奏和策略、以及迭代等应该是非常大的...
quartz java api,Quartz API-程序员宅基地
文章浏览阅读144次。Quartz API 的关键接口Scheduler - 用于与调度程序交互的主要API.Job - 运行任务(真正的业务实现类)实现的接口JobDetail - 用于定义任务的实例.Trigger - 用于定义执行给定Job的计划JobBuilder - 用于定义/构建JobDetail实例TriggerBuilder - 用于定义/构建Trigger 实例。DSL风格Quartz提供了“构建器”..._java scheduler api
Spring系列十:Spring MVC深度学习,Java基础面试常常死在这几个问题上-程序员宅基地
文章浏览阅读961次,点赞23次,收藏11次。这份清华大牛整理的进大厂必备的redis视频、面试题和技术文档祝大家早日进入大厂,拿到满意的薪资和职级~~~加油!!!这份清华大牛整理的进大厂必备的redis视频、面试题和技术文档祝大家早日进入大厂,拿到满意的薪资和职级~~~加油!!![外链图片转存中…(img-iqMfFBiE-1711963264277)]
Linux 运维工程师入门和学习之路——Linux命令篇-程序员宅基地
文章浏览阅读289次,点赞5次,收藏2次。Linux拥有大量的命令,涵盖了系统管理、文件操作、网络配置等多个方面。以下是一些常用的Linux命令集合,但这并不是全部,Linux的命令集合非常庞大,并且随着版本的更新和社区的发展,新的命令和工具也在不断涌现。命令可以获得shell内置命令的帮助信息。这些命令和工具为Linux用户提供了强大的系统管理和文件操作能力。命令可以查看命令的详细信息和用法,此外,还有许多其他命令和工具,如。
HDU 1010 Tempter of the Bone 搜索 奇偶剪枝-程序员宅基地
文章浏览阅读221次。Tempter of the Bone Time Limit: 1000MS Memory Limit: 32768KB 64bit IO Format: %I64d & %I64u SubmitStatusDescriptionThe doggie found a bone in an ancient maze, which fascinated him a lot. However,
SRv6 TE Policy场景-原理浅谈及配置示例-程序员宅基地
文章浏览阅读1.6k次,点赞2次,收藏12次。EVPN L3VPN for IPv4 Over SRv6 TE Policy场景介绍;SRv6 TE policy原理介绍;RFC9256简介_srv6 te policy