C++后台面试常见问题与回答(持续更新)_double a=1/2-程序员宅基地
技术标签: 面试 C++ C++基础 后台 内存 面试与笔试 stl
最近觉得自己的基础知识不够牢固,所以在网上找到一些常见的面试问题,自己试着去学习并解答,希望对找工作的朋友有一定的帮助。
由于C++面试涉及的知识非常多,我也是一边复习一边总结,所以这个文档会持续更新下去。有时间还会再每个问题后面添加一些相关书籍与链接等,方便进一步深入学习与理解。
**
C++基础
**
问:C++内存模型是什么?如何理解自由存储区与堆的区别?
在C++中,内存区分为5个区,分别是堆、栈、自由存储区、全局/静态存储区、常量存储区。malloc在堆上分配的内存,使用free释放内存,而new所申请的内存则是在自由存储区上,使用delete来释放,不过这只是表象。进一步来讲,基本上所有的C++编译器默认使用堆来实现自由存储,即缺省的全局运算符new和delete也会按照malloc和free的方式来被实现,这时藉由new运算符分配的对象,说它在堆上也对,说它在自由存储区上也正确。
所以,new所申请的内存区域在C++中称为自由存储区,如果是通过malloc实现的,那么他也是在堆上的。
https://www.cnblogs.com/QG-whz/p/5060894.html
问:reference和pointer的区别。哪些情况使用pointer
1.指针可以为空,而引用不可以指向空值。
2.指针可以不初始化,引用必须初始化。这意味着引用不需要检测合法性
3.指针可以随时更改指向的目标,而引用初始化后就不可以再指向任何其他对象
根据上面的情况我们知道什么时候需要使用指针,不过还有一种情况,在重载如[]符号的时候,建议返回引用,这样便于我们书写习惯也方便理解。因为平时我们都是这样使用, a[10] = 10;而不是 *a[10] = 10;
问:double a = 1/2; double a = (float)1.0/3; a分别是多少?
第一个是类型转换问题,1和2都是整数,所以结果也是整数,再把整数强转成double结果为0。第二个问题,不要求写对,需要明白第7位以后的结果就不精确了。 0.333333????
问:inline的优劣
优点减少函数调用开销
缺点增加函数体积,exe太大,占用CPU资源,可导致cache装不下(减小了cache的命中)
不方便调试debug下一般不内联,
每次修改会重新编译头文件增加编译时间
注意:inline只是一个请求,编译器有权利拒绝。有7种情况下都会拒绝,虚调用,体积过大,有递归,可变数目参数,通过函数指针调用,调用者异常类型不同,declspec宏等
forceinline字面意思上是强制内联,一般可能只是对代码体积不做限制了,但是对于上面的那些情况仍然不会内联,如果没有内联他会返回一个警告。
构造函数析构函数不建议内联,里面可能会有编译器添加的内容,比如说初始化列表里面的东西。
问:final和override的作用,以及使用场合
final:禁止继承该类或者覆盖该虚函数
override:必须覆盖基类的匹配的虚函数
场合final:不希望这个类被继承,比如vector,编码者可能不够了解vector的实现,或者说编写者不希望别人去覆盖某个虚函数,顾名思义,final就是最终么
场合override:第一种,在使用别人的函数库,或者继承了别人写的类时,想写一个新函数,可能碰巧与原来基类的函数名称一样,被编译器误认为要重写基类的函数。第二种情况是想覆写一个基类的函数,但是不小心参数不匹配或者名字拼错,结果导致写了一个新的虚函数
问:The rule of three是什么?
我就不翻译了 If you need to explicitly declare either the destructor, copy constructor or copy assignment operator yourself, you probably need to explicitly declare all three of them.
问:C++03有什么你不习惯或不喜欢的用法?
这个问题最简单的办法就是看下一个版本的C++有哪些特性,新的特性肯定是有意义的喽。如:auto,有一些迭代器或者map嵌套类型,遍历时比较麻烦,auto写起来很方便。vector以及其他容器的列表初始化,原来想像数组一样初始化,需要一个一个来,麻烦。类内初始值问题,总是需要放到构造函数里面初始化,初始化列表倒是不错,但是初始化数据太多就不行了。explicit,final, override等等。
当然,你要是能说出一些还没有改正的问题就更好了,比如内存管理的困难(没有GC),一些C#,java里面有而C++没有的特性等,要能深入一点说那就更好了
问:delegate是什么?实现思路?与event的区别?
代理简单来说就是让对象B去代理A执行A本身的操作,本质上就是通过指向其他成员函数或者全局函数的函数指针去代理执行。而函数指针有两种,成员函数指针与普通的函数指针,我们一般就是通过对这两种指针的封装来实现代理的效果。常见的实现方式有两种,一种是通过多态接口,另一种是通过宏。代理也分为单播代理与多播代理,单播就是一个调用只代理执行一个函数功能,多播代理就是一个调用可以绑定多个代理函数,可以触发多个代理的函数操作。
Event是一种特殊的多播delegate,只有声明事件的类可以调用事件的触发操作。最常见的也容易理解的就是MFC里面的按钮的鼠标点击事件了,他的调用只能在Button里面去执行。
虚函数机制相关
问:virtual function的优缺点
优点:多态
缺点:MFC中的消息机制没有采用C++中的虚函数机制,原因是消息太多,虚函数内存开销太大。在Qt中也没有采用C++中的虚函数机制,STL里的容器都没有虚析构函数。1.在子类很少覆盖基类函数实现的时候内存开销太大,每个类需要产生一张虚表,每生成一个对象的时候,需要在对象里存放一个vptr。2.基类指针指向派生类对象的情况下,无法内联优化3.在执行效率上肯定多了一些开销,需要寻找函数地址,也就是多了几个汇编指令吧
问:为什么要用virtual destructor?为什么没有virtual constructor?如何定义clone来实现类似virtual constructor的功能?
第一点,构造函数执行前,对象的内存信息都没有,vptr也没有初始化,如何找到虚函数表,实现虚调用。其次,需要理解虚函数的意义,他是为了实现多态,让子类去覆盖父类的操作。而构造函数与析构函数的执行不同,他是从父类开始一步一步的构造成一个子类(即使父类没有构造函数也可能会被编译器合成一个),所以你不能跳过父类的构造函数,子类的很多成员可能需要在父类的基础上去初始化。
不过,进一步深入理解的话。我们可能只是想去通过子类的构造函数做一些特别的初始化,所以排除C++构造函数底层的执行逻辑,调用虚构造函数也是有意义的。参考Delphi语言,因为他有一种类类型,所有的类都继承自这个类类型Tclass,那么当自定义一个类的时候,你的父类其实是通过调用子类的虚拟tclass->creat函数来创建一个子类对象,那这个操作就相当于C++里面的虚构造函数了。
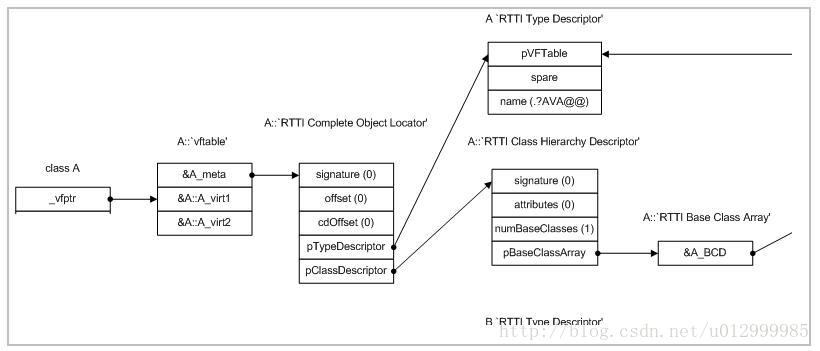
问:dynamic_cast是怎么实现的
dynamiccast属于RTTI,运行时类型识别的一个内容,他是c++realise1.0的主要扩充功能之一。主要内容是typeid与typeinfo的实现,基本思路就是在有虚函数的类的虚表的头部位置存放RTTI的相关信息。在VC里面可以看到是一个叫做RTTI Complete Object Locator的结构体里面存放相关的信息。在强转的时候,会读取里面对应的类的信息进而判断是否能转换成功
推荐参考:
C++内存管理相关
问:memory alignment and padding, 内存对齐的原理与意义
结构体以及类成员对齐,意义就是减少cpu读取的次数,提高效率。比如一个int变量长度为4个字节,cpu一次读4个字节,当然是一次读取比较好。但是如果前面有一个char,地址为0-1。那么这个int的地址就为1-4。导致cpu,分两次读取int值。
具体的对齐规则,要说的非常准确可能比较麻烦,简单来讲就是,每个变量看后面的变量,如果后面的变量大,就和后面的大小对齐并补充字节。最后一个变量后,按照成员内最大的对齐值,对齐并补充字节。
问:std::shared_ptr的实现,reference count在哪里定义
shared_ptr作为一种智能指针,本质上一个模板类,表现上与指针相同,是因为重载了&以及*这两个运算符(当然还有=等运算符)。由于其本身的计数机制,防止资源泄露上面很有意义。
Shareptr在实现上有两个核心的成员,一个是指向资源对象的指针变量,另一个是指向引用计数的指针变量。第一个参数不言而喻,第二个参数为什么也是指针?因为多个shared_ptr对象指向同一资源时,其中一个shared_ptr对象析构了count = count -1,是不会影响到其他shared_ptr对象的,所以使用指针可以达到多个shared_ptr对象指向同一资源的能够共享count目的。另外,原生的shared_ptr的读写在多线程当中是不安全的,因为读写不具有原子性,所以多线程使用shared_ptr一定要加锁。具体参考陈硕先生的“为什么多线程读写 shared_ptr 要加锁?”。循环引用会造成内存泄露。
问:new expression, operator new和malloc的联系
malloc:是从C语言移植过来的语义,表示申请一定大小的内存并返回void*指针,在堆上申请内存,申请失败会返回Null
New:C++里的关键字,针对对象而言,申请一块内存的然后并在内存上构造对应的对象,最后返回该对象的指针。深入:new是从自由存储区分配的内存,自由存储区可能不在堆上,在静态存储区(全局变量做的对象池)。申请失败会抛出异常。New可以通过new[]对数组进行内存申请与构造
Operator new:C++里面与Malloc类似的语义,只申请内存而不构造对象
New操作的第一步就是调用OperatorNew来执行内存的申请。深入:operatornew可以基于malloc实现,一般也都是这么做的,可以被重载
推荐参考:
http://blog.csdn.net/wudaijun/article/details/9273339
http://blog.jobbole.com/102002/#article-comment
问:placement new的意义
placement new作用不太像new,或者说只是一个不完整的new,因为他不分配内存,只是在给定地址上调用构造函数,在c++里面,placement new实际上就是operator new的一种重载方式之一。
一个普通的new可以拆分成两步,第一步,申请内存返回指针,执行一个非placement的operator new(可能通过malloc实现)。第二步,在指定位置上构造对象(这个操作一般是编译器帮我们做了,但是并不是执行placement new,虽然功能上差不多,这里面有细微的差别)。c++单独提供给我们一个placement new 来做第二步操作,因为有的时候我们可能想使用自己的内存申请方式(比如malloc),但是你发现除了placement new以外你好像没有其他办法在指定位置上调用构造函数。
另外,想要使用placement new,底层系统并不告诉你这个地址上是否已经有对象了,如果你在已经构造的对象上面执行,那么前一个对象就会被销毁,理论上析构函数也不会执行。总之,要避免这种情况。
问:allocator的实现与使用意义
c++11新标准里面加入,他本身是一个类模板,功能上其实就是把new拆开,把内存申请和对象构造分成两个步骤,是不是很熟悉?这不就是operator new和placement new么?实际上allocator就是利用operator new来实现的。
为什么要这么做?举个例子,假如我要new一个长度为100的string数组,那我在申请内存的同时还要构造100个string对象,而实际上我整个程序从开始到结束可能只用了10个string。那为了减小构造的开销,这里就将内存申请与对象构造分开,也就有了allocator。当然,我们也可以使用operator new来做这个操作,只不过allocator帮我们做了一些简单的封装,类型检查等。另外,说到allocator就不得不提一下stl里面的空间配置器alloc,他除了上面简单的封装外还还考虑到了以下三个方面:1.多线程内存分配(内存池互斥访问)2.内存分配失败的异常处理3.实现一个轻量级内存池来解决小块内存导致的内存碎片问题
第一种情况,基本的实现就是在构造时加锁,析构时解锁。
内存分配失败的话,给用户提供一个函数去定义异常时的处理逻辑。
针对内存碎片问题,sgi stl里面的allocator里面设计了一个双层配置器,当申请内存超过128byte,就认为足够大,直接调用malloc分配。反之,调用第二级配置器使用内存池来处理,内存池实现思路就是先申请一块比较大的内存,分成n块,每次有小的内存申请时就给他一块。
问:RAII是什么?有什么意义?
RAII 是 resource acquisition is initialization 的缩写,意为“资源获取即初始化”。其核心是把资源和对象的生命周期绑定,对象创建获取资源,对象销毁释放资源。常见的例子就是智能指针,通过声明一个包含资源对象指针的类,在这个类执行析构的时候释放指针指向的对象。
问:cpu cache是怎么运作的
每次CPU缺什么数据, 找内存拿了一次, 但是这被prefetcher记住了, 等一有空prefetcher就把页(Page)中其他相关数据都从内存里拿出来. 这就等于把他街坊邻居全叫了出来, CPU提取数据一般是有范围的, 横竖不超过这么多, 所以CPU第二次再缺数据, 就不用去找内存了, 都在Cache里! 实际上Cache可以同时监控很多个页, 这个过程反复几次, CPU就基本不再找内存要东西了.
STL相关
问:vector的实现与增长
vector是stl提供的动态数组,想了解他就要从他的特性开始分析。首先,他是一个模板类,意味着可以存放各种类型的元素,同时他也是一个数组,存储是连续的。
内存分配:常规的数组必须在定义的时候就分配好固定的大小,而vector可以动态的改变,也就说明他可以动态的申请与释放内存。我们要知道,频繁的申请与释放内存对程序的效率影响是非常大的,因为如果当前地址空间不够用的话,就需要重新找一块更大的空间来装数据,再把数据全部都拷贝过去。所以vector为了达到比较好的效果,在添加元素的时候会多申请一定大小的内存,从而减少内存分配的次数。capacity()返回的就是包括缓冲区在内的空间大小,而size()返回的就是当前实际使用的空间大小。如果想主动的提前分配内存,可以使用reserve(n),会强制重新分配一次内存,超出实际使用的部分就会成为缓存区。如果想直接构造出长度为n的动态数组可以使用resize(n),实际分配的空间肯定要比n大,不过如果n比当前size小的话,大于size的数据都会被清空,如果比capacity还大的话就会重新执行一次内存分配。
关于内存释放,如果只是简单的调用 clear()全部清空数据,erase()清空部分数据 都只是单纯的清空里面的数据并不会释放掉。默认只会在调用vector的析构函数的时候才会真正释放空间,所以如果想强制释放那就新建一个空的vector,然后对这个vector使用swap讲内存交换,那么原来的vector就会释放,新的vector呢?
另外,由于涉及到模板,也就会涉及到迭代器,凡是重新申请过内存,插入删除数据的,迭代器都会失效,理解上也很容易就是指针可能指向的不是你原来的那个位置了。
问:map的实现 unordered_map的原理;如果从空的table开始一直增加元素,会出现什么情况?
map分为有序map和无序map,实现的基本数据结构分别是红黑树与哈希表。(set同理)里面每一个元素是一个pair< const key_type,mapped_type >类型,注意key是const的,不可以修改。对于一个数据结构,常见的操作无非是查找,插入,删除。红黑树作为一种二叉搜索树,具有log(n)的查找效率,不过前提是数据具有足够的随机性。!!!
hashmap理想上则是具有常数平均时间的效率,或者说一次或几次就可以查到,当然如果数据量过大,散列表空间就不能和数据量保持1:1,这时候就要靠hash函数来处理数据,将数据尽可能的分散在不同的桶bucket里面。
sgi stl的hash使用的是开链操作来避免hash表空间过大又想保持一定效率的问题,开链就是在一个位置用链表来存储所有冲突项。其实hashmap里面常说的桶bucket就是vector数组的一个元素,每个桶里面的数据是以链表(开链)的形式存储,进一步来说这些操作与定义都是通过一个基本的数据结构hashtable来实现的,所有的无序关联容器都是。hashtable里面的hash函数就是常说的取模函数,根据存储数据key值(注意,是对key而不是value)对桶的长度取余数来存放。默认提供的hash函数无法处理常见内置类型以外的数据,如各种自定义类,其实string本身也算是特殊类型,但是语言内部可以转为const char*处理,他经过函数处理也会得到一个size类型(一般对字符串的哈希函数比较特别,参考各种字符串Hash函数比较)。
什么时候需要rehash?当你的桶里面的平均数量(Map大小/桶的数量)大于max(这个可以自己设置),就需要rehash。也可以主动调用rehash(n),保证桶的数量大于n,注意n是桶的数量。 改变桶的数量就相当于改变Vector的长度,如果超过vector的capacity就会调用Vector的扩容机制(但是实际上他每次hash的时候都会直接调用vector的reserve进行扩容)。
什么时候执行reserve(Java里好像是resize)?注意reserve与vector的reserve不一样,他的目的并不是扩容,而是希望当前哈希表里面可以容纳n个元素。如果n>桶的数量*负载因子 的时候就会触发rehash,否则不会触发。rehash有可能进一步触发vector的扩容。参考下面的英文注释。
Request a capacity change Sets the number of buckets in the container
(bucket_count) to the most appropriate to contain at least n elements.
If n is greater than the current bucket_count multiplied by the
max_load_factor, the container’s bucket_count is increased and a
rehash is forced. If n is lower than that, the function may have no
effect.
不过我发现 VC的STL里面的处理方式好像不太一样,他是自动先检测是否满足当前负载因子>最大负载因子,满足就会先触发重新设置桶的数量,如果桶的数量小于512就直接乘以8,否则如果小于Vector容量的一半的话就乘以2。这个过程我们看到他直接设置桶的数量并没有调用rehash函数,如果是主动调用rehash的话是直接翻倍的。而且不论是手动还是自动调整桶的数量,他都会触发Vector的扩容函数。
//手动调用:重新分配桶的数量
void rehash(size_type _Buckets)
{ // rebuild table with at least _Buckets buckets
size_type _Maxsize = _Vec.max_size() / 4;
size_type _Newsize = _Min_buckets;
for (; _Newsize < _Buckets && _Newsize < _Maxsize; )
_Newsize *= 2; // double until big enough
if (_Newsize < _Buckets)
_Xout_of_range("invalid hash bucket count");
while (!(size() / max_load_factor() < _Newsize)
&& _Newsize < _Maxsize)
_Newsize *= 2; // double until load factor okay
_Init(_Newsize);
_Reinsert();
}
//自动检查:设置桶的数量
void _Check_size()
{ // grow table as needed
if (max_load_factor() < load_factor())
{ // rehash to bigger table
size_type _Newsize = bucket_count();
if (_Newsize < 512)
_Newsize *= 8; // multiply by 8
else if (_Newsize < _Vec.max_size() / 2)
_Newsize *= 2; // multiply safely by 2
_Init(_Newsize);
_Reinsert();
}
}
//重新分配桶的数量,同时进行扩容
void _Init(size_type _Buckets = _Min_buckets)
{ // initialize hash table with _Buckets buckets, leave list alone
_Vec.reserve(2 * _Buckets); // avoid curdling _Vec if exception occurs
_Vec.assign(2 * _Buckets, _Unchecked_end());
_Mask = _Buckets - 1;
//赋值_Maxidx,重新设置桶的数量
_Maxidx = _Buckets;
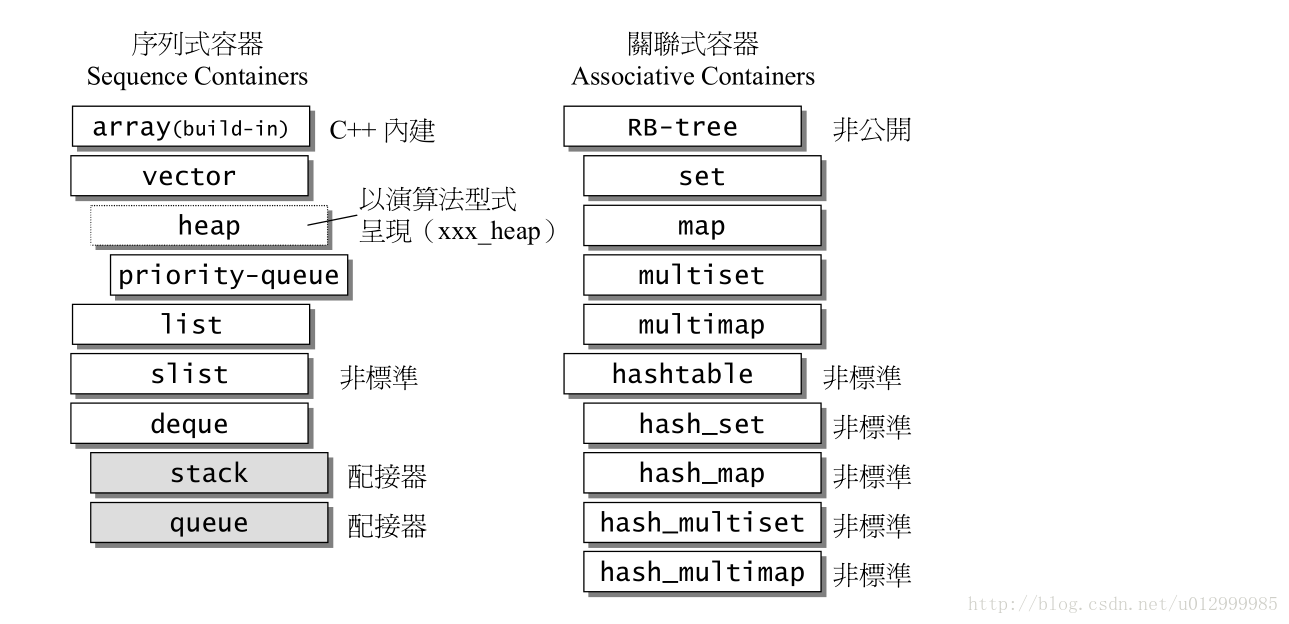
}问:stl里面各个容器的基础数据结构是?
图截自STL源码分析一书,常问的是优先级队列,hashmap,map底层的数据结构是什么。答案分别是Vector,hashtable以及RB—tree(红黑树),具体细节大家可以仔细看一下关于容器的这两章内容。
**
基本技能
**
问:平时用什么IDE?一般如何调试?
这个第一个看个人,一般Windows下就是VS比较多了。调试的话,常见的就是断点,日志,打印。断点需要强调一下,有一般的函数断点(这个基本上所有人都会),条件断点,针对数据变化的是内存断点(这个确实有很多人不知道)。
原文链接(转载请标明):http://blog.csdn.net/u012999985/article/details/78359151
智能推荐
hive使用适用场景_大数据入门:Hive应用场景-程序员宅基地
文章浏览阅读5.8k次。在大数据的发展当中,大数据技术生态的组件,也在不断地拓展开来,而其中的Hive组件,作为Hadoop的数据仓库工具,可以实现对Hadoop集群当中的大规模数据进行相应的数据处理。今天我们的大数据入门分享,就主要来讲讲,Hive应用场景。关于Hive,首先需要明确的一点就是,Hive并非数据库,Hive所提供的数据存储、查询和分析功能,本质上来说,并非传统数据库所提供的存储、查询、分析功能。Hive..._hive应用场景
zblog采集-织梦全自动采集插件-织梦免费采集插件_zblog 网页采集插件-程序员宅基地
文章浏览阅读496次。Zblog是由Zblog开发团队开发的一款小巧而强大的基于Asp和PHP平台的开源程序,但是插件市场上的Zblog采集插件,没有一款能打的,要么就是没有SEO文章内容处理,要么就是功能单一。很少有适合SEO站长的Zblog采集。人们都知道Zblog采集接口都是对Zblog采集不熟悉的人做的,很多人采取模拟登陆的方法进行发布文章,也有很多人直接操作数据库发布文章,然而这些都或多或少的产生各种问题,发布速度慢、文章内容未经严格过滤,导致安全性问题、不能发Tag、不能自动创建分类等。但是使用Zblog采._zblog 网页采集插件
Flink学习四:提交Flink运行job_flink定时运行job-程序员宅基地
文章浏览阅读2.4k次,点赞2次,收藏2次。restUI页面提交1.1 添加上传jar包1.2 提交任务job1.3 查看提交的任务2. 命令行提交./flink-1.9.3/bin/flink run -c com.qu.wc.StreamWordCount -p 2 FlinkTutorial-1.0-SNAPSHOT.jar3. 命令行查看正在运行的job./flink-1.9.3/bin/flink list4. 命令行查看所有job./flink-1.9.3/bin/flink list --all._flink定时运行job
STM32-LED闪烁项目总结_嵌入式stm32闪烁led实验总结-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏6次。这个项目是基于STM32的LED闪烁项目,主要目的是让学习者熟悉STM32的基本操作和编程方法。在这个项目中,我们将使用STM32作为控制器,通过对GPIO口的控制实现LED灯的闪烁。这个STM32 LED闪烁的项目是一个非常简单的入门项目,但它可以帮助学习者熟悉STM32的编程方法和GPIO口的使用。在这个项目中,我们通过对GPIO口的控制实现了LED灯的闪烁。LED闪烁是STM32入门课程的基础操作之一,它旨在教学生如何使用STM32开发板控制LED灯的闪烁。_嵌入式stm32闪烁led实验总结
Debezium安装部署和将服务托管到systemctl-程序员宅基地
文章浏览阅读63次。本文介绍了安装和部署Debezium的详细步骤,并演示了如何将Debezium服务托管到systemctl以进行方便的管理。本文将详细介绍如何安装和部署Debezium,并将其服务托管到systemctl。解压缩后,将得到一个名为"debezium"的目录,其中包含Debezium的二进制文件和其他必要的资源。注意替换"ExecStart"中的"/path/to/debezium"为实际的Debezium目录路径。接下来,需要下载Debezium的压缩包,并将其解压到所需的目录。
Android 控制屏幕唤醒常亮或熄灭_android实现拿起手机亮屏-程序员宅基地
文章浏览阅读4.4k次。需求:在诗词曲文项目中,诗词整篇朗读的时候,文章没有读完会因为屏幕熄灭停止朗读。要求:在文章没有朗读完毕之前屏幕常亮,读完以后屏幕常亮关闭;1.权限配置:设置电源管理的权限。
随便推点
目标检测简介-程序员宅基地
文章浏览阅读2.3k次。目标检测简介、评估标准、经典算法_目标检测
记SQL server安装后无法连接127.0.0.1解决方法_sqlserver 127 0 01 无法连接-程序员宅基地
文章浏览阅读6.3k次,点赞4次,收藏9次。实训时需要安装SQL server2008 R所以我上网上找了一个.exe 的安装包链接:https://pan.baidu.com/s/1_FkhB8XJy3Js_rFADhdtmA提取码:ztki注:解压后1.04G安装时Microsoft需下载.NET,更新安装后会自动安装如下:点击第一个傻瓜式安装,唯一注意的是在修改路径的时候如下不可修改:到安装实例的时候就可以修改啦数据..._sqlserver 127 0 01 无法连接
js 获取对象的所有key值,用来遍历_js 遍历对象的key-程序员宅基地
文章浏览阅读7.4k次。1. Object.keys(item); 获取到了key之后就可以遍历的时候直接使用这个进行遍历所有的key跟valuevar infoItem={ name:'xiaowu', age:'18',}//的出来的keys就是[name,age]var keys=Object.keys(infoItem);2. 通常用于以下实力中 <div *ngFor="let item of keys"> <div>{{item}}.._js 遍历对象的key
粒子群算法(PSO)求解路径规划_粒子群算法路径规划-程序员宅基地
文章浏览阅读2.2w次,点赞51次,收藏310次。粒子群算法求解路径规划路径规划问题描述 给定环境信息,如果该环境内有障碍物,寻求起始点到目标点的最短路径, 并且路径不能与障碍物相交,如图 1.1.1 所示。1.2 粒子群算法求解1.2.1 求解思路 粒子群优化算法(PSO),粒子群中的每一个粒子都代表一个问题的可能解, 通过粒子个体的简单行为,群体内的信息交互实现问题求解的智能性。 在路径规划中,我们将每一条路径规划为一个粒子,每个粒子群群有 n 个粒 子,即有 n 条路径,同时,每个粒子又有 m 个染色体,即中间过渡点的_粒子群算法路径规划
量化评价:稳健的业绩评价指标_rar 海龟-程序员宅基地
文章浏览阅读353次。所谓稳健的评估指标,是指在评估的过程中数据的轻微变化并不会显著的影响一个统计指标。而不稳健的评估指标则相反,在对交易系统进行回测时,参数值的轻微变化会带来不稳健指标的大幅变化。对于不稳健的评估指标,任何对数据有影响的因素都会对测试结果产生过大的影响,这很容易导致数据过拟合。_rar 海龟
IAP在ARM Cortex-M3微控制器实现原理_value line devices connectivity line devices-程序员宅基地
文章浏览阅读607次,点赞2次,收藏7次。–基于STM32F103ZET6的UART通讯实现一、什么是IAP,为什么要IAPIAP即为In Application Programming(在应用中编程),一般情况下,以STM32F10x系列芯片为主控制器的设备在出厂时就已经使用J-Link仿真器将应用代码烧录了,如果在设备使用过程中需要进行应用代码的更换、升级等操作的话,则可能需要将设备返回原厂并拆解出来再使用J-Link重新烧录代码,这就增加了很多不必要的麻烦。站在用户的角度来说,就是能让用户自己来更换设备里边的代码程序而厂家这边只需要提供给_value line devices connectivity line devices