超详细的图解 Numpy,不收藏后悔!_numpy、-程序员宅基地

Numpy是关于机器学习,数据处理的Python基础库,了解 NumPy 的工作原理可以提高你的编码效率,可以让你的代码看上去更加简洁和优雅。 NumPy 也可以GPU上运行代码而无需更改原始代码(或只做少量更改)。
NumPy 的核心概念是 多维数组。它的美妙之处在于,无论数组有多少维,大多数操作看起来都是一样的。但是 1D 和 2D 的情况有点特殊。文章由三部分组成:
- 向量,一维数组
- 矩阵,二维数组
- 3D及以上
Numpy 数组与 Python 列表(list)
粗看上去,NumPy 数组类似于 Python 列表。它们都用作容器,具有快速的原始获取和设置以及元素的插入和删除速度稍慢。
先看一个最简单的例子,Numpy能打败Python的list主要体现在算术计算上:

除此之外,NumPy 数组的优缺点主要体现在:
- Numpy更紧凑,尤其是当有多个维度时。
- Numpy的向量化操作List表更快。
- Numpy将元素附加到末尾时比List慢。
- Numpy和List共同特点是:只能快速处理一种类型的元素。

这里的大O表示运算的时间复杂度, O(N)表示运算的时间与数组的大小成正比。O*(1)表运算示时间一般不依赖于数组的大小。
1.向量,一维数组
向量初始化
创建 NumPy 数组的一种方法是通过将python的list 转换成numpy的数组:

NumPy 数组不能像 Python list 那样很方便的进行扩展(append):因为它在数组末尾没有保留空间以方便快速扩展。因此,通常的做法是先扩展 Python 列表然后将其转换为 NumPy 数组,或者使用 np.zeros,np.empty 预先分配必要的空间。

通常我们需要创建一个空数组来匹配现有数组的形状和元素类型 :

实际上,所有创建一个填充常量值的数组的函数都有_like对应的函数:

NumPy 中创建序列数组初始化的函数有两个:

如果您需要一个外观相似的浮点数数组,例如[0., 1., 2.],您可以更改arange输出的类型:arange(3).astype(float),但还有更好的方法,由于arange函数是类型敏感的:如果您输入整数作为参数,它将生成整数,如果您输入浮点数(例如arange(3.)),它将生成浮点数。
但arange不是特别擅长处理浮点数:

np.arange(start,stop,step)通常情况下比较擅长处理整数,也可以处理浮动数,但是处理浮动数时可读性较差,因为当参数start,stop,step的小数位数不一致时,生产的结果有时难以理解(比如上图中的solution1的结果),因为浮点数没有连续的概念。 当需要生成浮点数序列数组时更为有效的方法是使用np.linspace(start,stop,num)方法,其中num必须是整数,np.linspace生成的浮点数序列并不是连续的,它只是在start,stop之间均匀的生成num个浮点数(包含start,stop在内)。即x∈[start,stop]。但是有一些numpy生产的浮动数序列并不是闭区间的,比如用numpy生成随机数序列:

在Numpy中还有一个用于生成随机数组的新接口。它的特点是:
- 更适合多线程
- 速度更快
- 更可配置(您可以通过选择非默认的所谓“位生成器”来获得更快的速度或更高的质量)

向量索引
当将数据放入数组后,NumPy 非常擅长提供简单的方法来返回部分或全部的结果:

上面介绍的多种通过多种花哨的索引来裁剪数组的方法,但是它们的结果实际上都是所谓的“视图(view)”:如果数据在被索引后发生变化,它们不会存储数据并反映原始数组中的变(赋值操作除外)。下面是对list和numpy数组进行切片和赋值后的结果差异的对比:

从 NumPy 数组获取数据的另一种非常有用的方法是布尔索引,它允许使用各种逻辑运算符:

numpy数组通过使用布尔索引的方式也可以对原数组进行赋值。为此衍生出来的两个常用的方法:np.where和np.clip

请注意,np.where使用一个参数返回一个数组元组(1D 情况下为 1 元组,2D 情况下为 2 元组等),因此您需要在上面的示例中写入np.where(a>5)[0]这种方式来返回你想要的数组。
向量运算
向量化运算的速度是 Numpy最值得夸耀的地方。向量化运算达到了 c++ 运算的级别,使我们能够避免缓慢的 Python 循环的成本。NumPy 允许像普通数字一样操作整个数组:

和 Python 中一样,a//b 表示 整除(得到商),x**n 表示 xⁿ
当一个数组与一个数做加减乘除时,表示数组的每个元素都与这个数做相关的运算。(也称为广播):
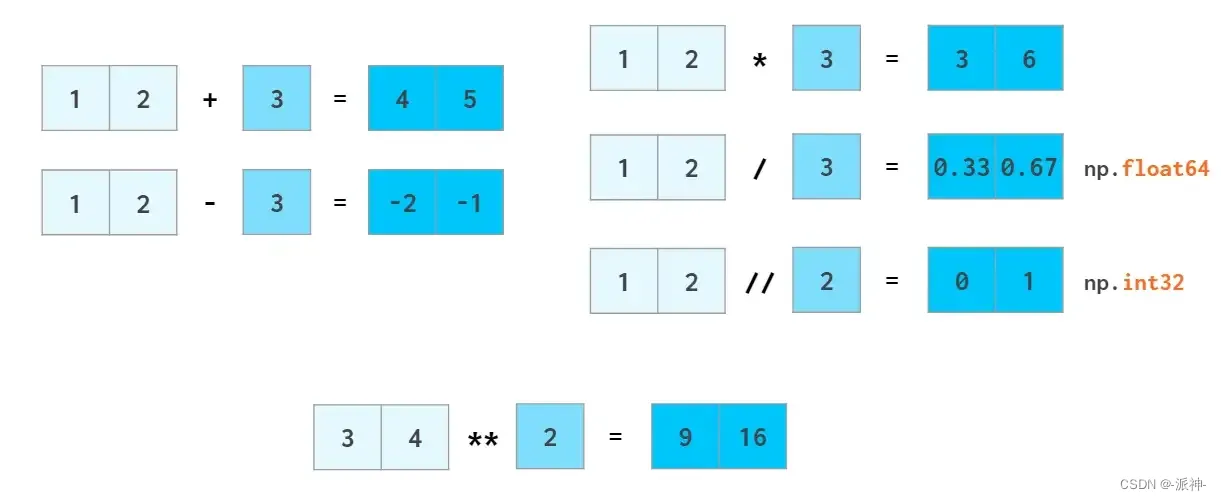
大多数数学函数都有NumPy函数与之对应:

在numpy中向量的点积与叉积有自己运算符:

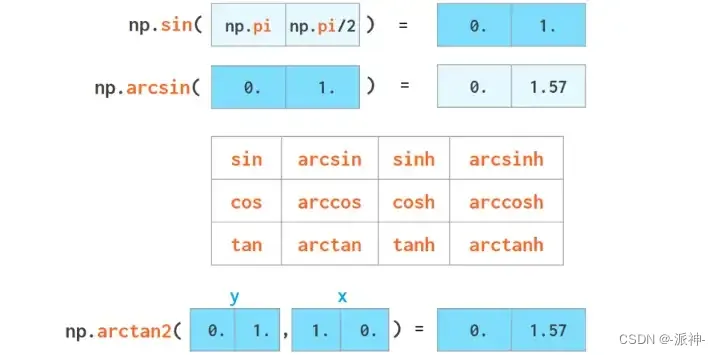
在numpy中也有三角函数运算符:
在numpy中还有多种不同的取整函数:

这里np.floor是向下取整,np.ceil是向上取整,而np.round 并非是“四舍五入”,而是“去奇存偶”,或者说 “4舍6入5凑偶”,与一般理解的四舍五入不同:当整数部分是偶数,小数部分是0.5时,向下取整,最后结果为偶数。当整数部分是奇数,小数部分是0.5时,则向上取整,最后结果为偶数。这样得到的结果在统计学上更精确。numpy的round函数采用的是这种方法。
numpy还有一些基本的统计函数:

这些函数中的每一个都有一个 nan-resistant 变体:例如nansum、nanmax等
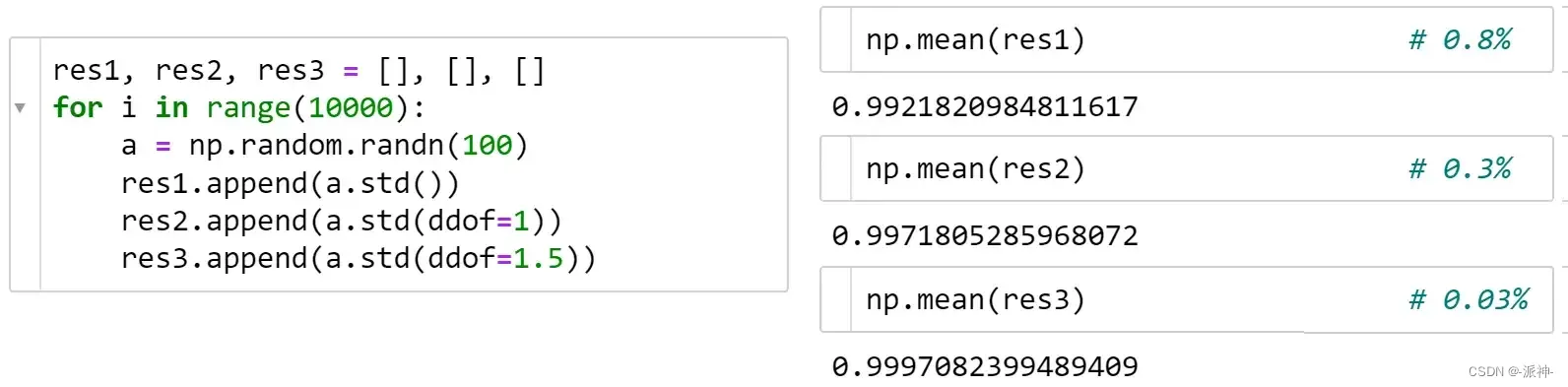
从上面的公式可以看出,在总体均值未知时从样本估计 std 的最典型用例中,std和都var忽略贝塞尔校正并给出有偏差的结果。获得较少偏差估计的标准方法是n-1在分母中使用ddof=1('delta degrees of freedom'):

Pandas std默认使用贝塞尔校正
随着样本量的增加,贝塞尔校正的效果会迅速减弱。此外,它不是一个标准的通用解决方案,例如正态分布ddof=1.5 更好:
排序函数的功能少于 Python 对应函数:

在一维情况下,reversed可以通过反转结果轻松补偿关键字的缺失。在 2D 中,它有点困难。
在向量中搜索元素
与Python的List不同,NumPy 数组没有index方法。 所以查找元素是Numpy的一个痛点:
- 一种查找元素的方法是np.where(a==x)[0][0],但它效率不高,因为它需要遍历数组的所有元素,即使要查找的元素在最开始位置。
- 另一种更快的方法是使用 Numba 加速 next((i[0] for i, v in np.ndenumerate(a) if v==x), -1) (否则在最坏的情况下比 where 还要慢).
- 一旦对数组进行排序,情况就会好转:v = np.searchsorted(a, x); return v if a[v]==x else -1 确实很快,复杂度为 O(log N),但首先需要 O(N log N) 时间进行排序。
浮点运算比较
函数np.allclose(a, b)用于比较具有给定公差的浮点数组:
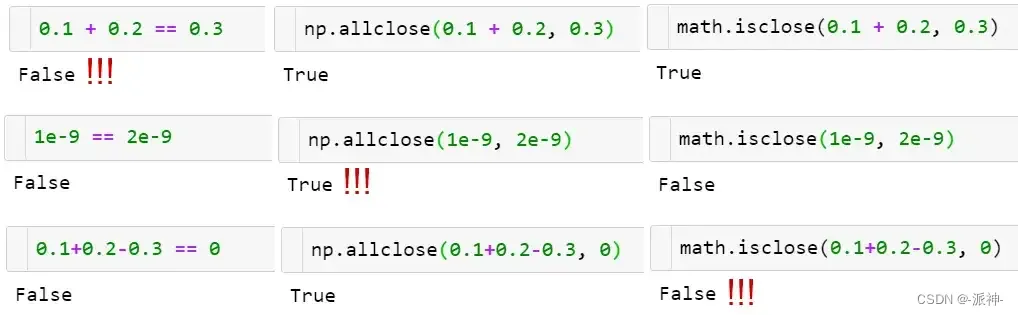
- np.allclose假设所有的比较数字的等级是1个单位。例如在上图中,它就认为1e-9和2e-9相同,如果要进行更细致的比较,需要通过atol指定比较等级1:np.allclose(1e-9, 2e-9, atol=1e-17) == False。
- math.isclose进行比较没有假设前提,而是基于用户给出的一个合理abs_tol值:math.isclose(0.1+0.2–0.3, abs_tol=1e-8) == True。
除此之外np.allclose在绝对和相对公差公式中还存在一些小问题,例如,对某些数存在allclose(a, b) != allclose(b, a)。这些问题已在math.isclose函数中得到解决。
2.矩阵,二维数组
NumPy 中曾经有一个专门的matrix类,但现在已弃用,因此我将交替使用矩阵和二维数组这两个词。
矩阵初始化语法类似于向量:

这里需要双括号,因为第二个位置参数是为(可选)dtype(也接受整数)保留的。
随机矩阵生成也类似于向量:

还有一种更简洁的随机数生成方式:

二维索引语法比嵌套列表更方便:

和一维数组一样,上图的view表示,切片数组实际上并未进行任何复制。修改数组后,更改也将反映在切片中。
axis参数
在许多操作(例如求和)中,我们需要告诉NumPy是否要跨行或跨列进行操作。为了使用任意维数的通用表示法,NumPy引入了axis的概念:axis参数实际上是所讨论索引的数量:第一个索引是axis=0,第二个索引是axis=1,等等。
因此在二维数组中,如果axis=0是按列,那么axis=1就是按行。

矩阵运算
除了按元素工作的普通运算符(如 +、-、*、/、// 和 **)之外,还有一个计算矩阵乘积的 @ 运算符:

在第一部分中,我们已经看到向量乘积的运算,NumPy允许向量和矩阵之间,甚至两个向量之间进行元素的混合运算:
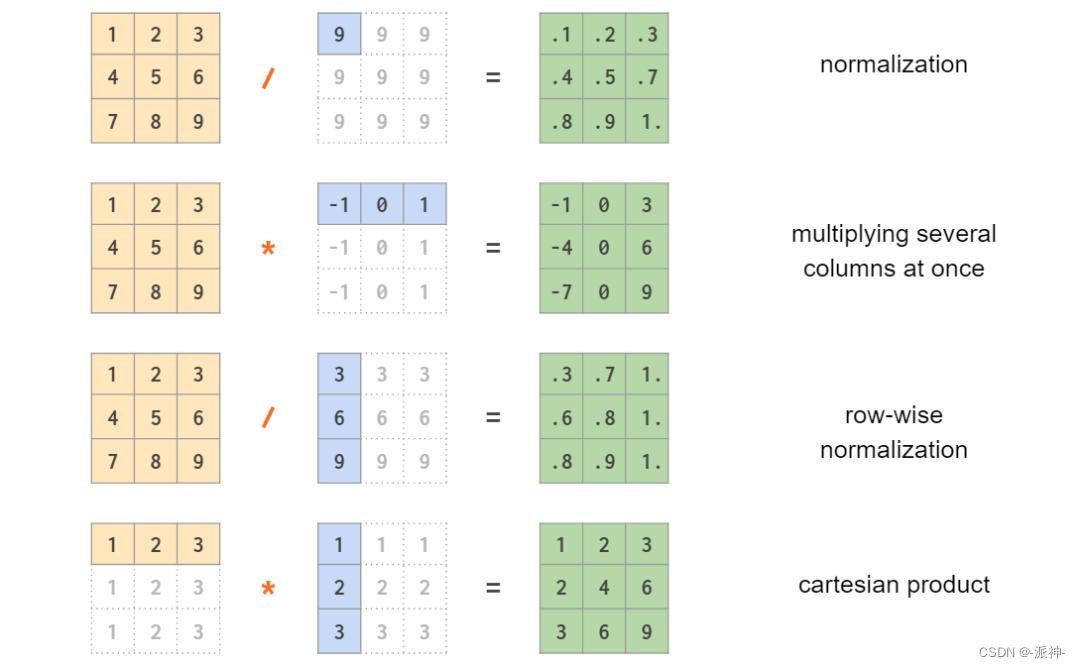
请注意,在最后一个示例中,它是一个对称的每元素乘法(笛卡尔积)。要使用非对称线性代数矩阵乘法计算外积,应颠倒操作数的顺序:

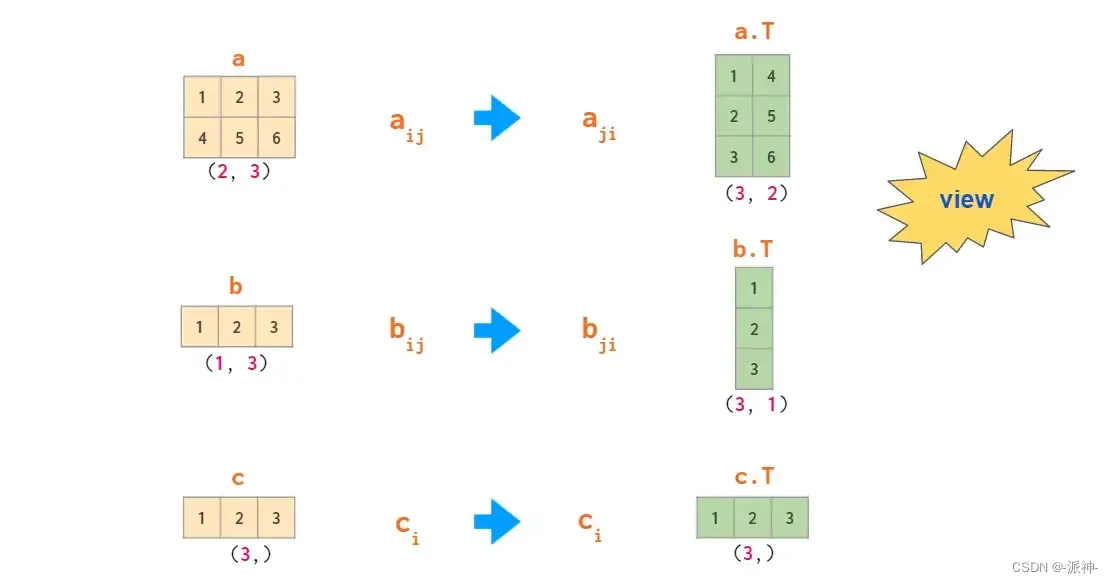
从上面的示例可以看出,在二维数组中,行向量和列向量被不同地对待。
默认情况下,一维数组在二维操作中被视为行向量。因此,将矩阵乘以行向量时,可以使用(n,)或(1,n),结果将相同。
如果需要列向量,则有转置方法对其进行操作:
能够从一维数组中生成二位数组列向量的两个操作是使用命令reshape重排和newaxis建立新索引:

这里的-1参数表示reshape自动计算第二个维度上的数组长度,None在方括号中充当np.newaxis的快捷方式,该快捷方式在指定位置添加了一个空axis。
因此,NumPy中总共有三种类型的向量:一维数组,二维行向量和二维列向量。这是两者之间显式转换的示意图:
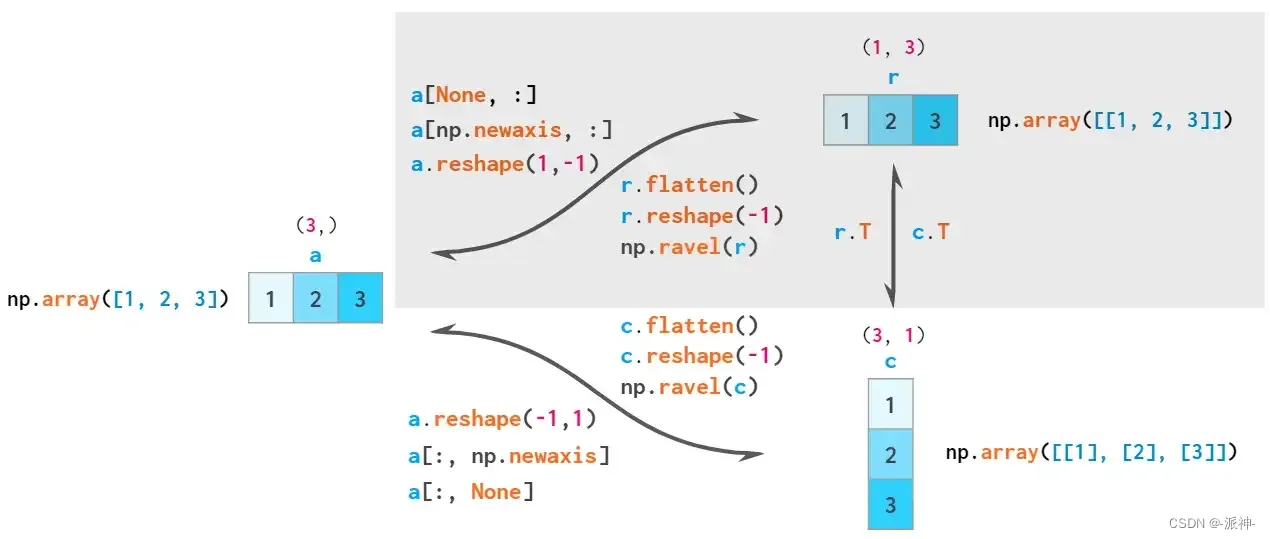
flatten始终是一个副本,reshape (-1) 始终是一个视图,ravel尽可能是一个视图
根据规则,一维数组被隐式解释为二维行向量,因此通常不必在这两个数组之间进行转换,相应区域用灰色标出。
矩阵操作
连接矩阵有两个主要函数:

这两个函数只堆叠矩阵或只堆叠向量时,都可以正常工作。但是当涉及一维数组与矩阵之间的混合堆叠时,vstack可以正常工作:hstack会出现尺寸不匹配错误。
因为如上所述,一维数组被解释为行向量,而不是列向量。解决方法是将其转换为列向量,或者使用column_stack自动执行:

堆叠的逆向操作是拆分:

所有split风格都接受要拆分的索引列表作为参数,或单个整数作为参数,即大小相等的部分的数量:

矩阵可以通过两种方式完成复制:tile类似于复制粘贴,repeat类似于分页打印。

特定的列和行可以用delete进行删除:

逆运算是插入(insert):

append就像hstack一样,该函数无法自动转置一维数组,因此再次需要对向量进行转置或添加长度,或者使用column_stack代替:

实际上,如果您需要做的只是将常量值添加到数组的边界,那么(稍微有点复杂)pad 函数就足够了:

Meshgrids
广播规会让使用 meshgrids 变得更简单。假设,您需要以下矩阵(但尺寸非常大):

两种明显的方法都很慢,因为它们使用 Python 循环。处理此类问题的MATLAB的方法是创建一个meshgrid:
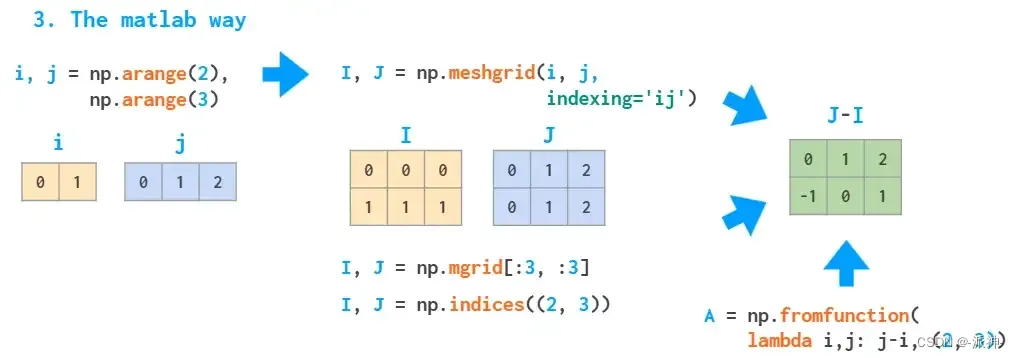
该meshgrid函数接受任意一组索引,该mgrid只是切片并且,indices只能生成完整的索引范围。fromfunction如上所述,使用 I 和 J 参数调用提供的函数一次。
但实际上,在 NumPy 中有更好的方法。没有必要在整个 I 和 J 矩阵上花费内存(即使meshgrid足够聪明,如果可能的话只存储对原始向量的引用)。只存储正确形状的向量就足够了,其余的由广播规则处理:

如果没有indexing=’ij’参数,meshgrid将更改参数的顺序:J, I= np.meshgrid(j, i)—它是一种“xy”模式,可用于可视化 3D 绘图(请参阅文档中的示例)。
除了在二维或三维网格上初始化函数外,网格对于索引数组也很有用:

也适用于稀疏网格
矩阵统计
就像 一样sum函数,所有其他统计函数 (min/max, argmin/argmax, mean/median/percentile, std/var)接受 axis 参数并相应地执行操作:

在二维及更高版本中的argminandargmax函数有返回扁平化索引(最小值和最大值的第一个实例)的麻烦。要将其转换为两个坐标,unravel_index需要一个函数 :
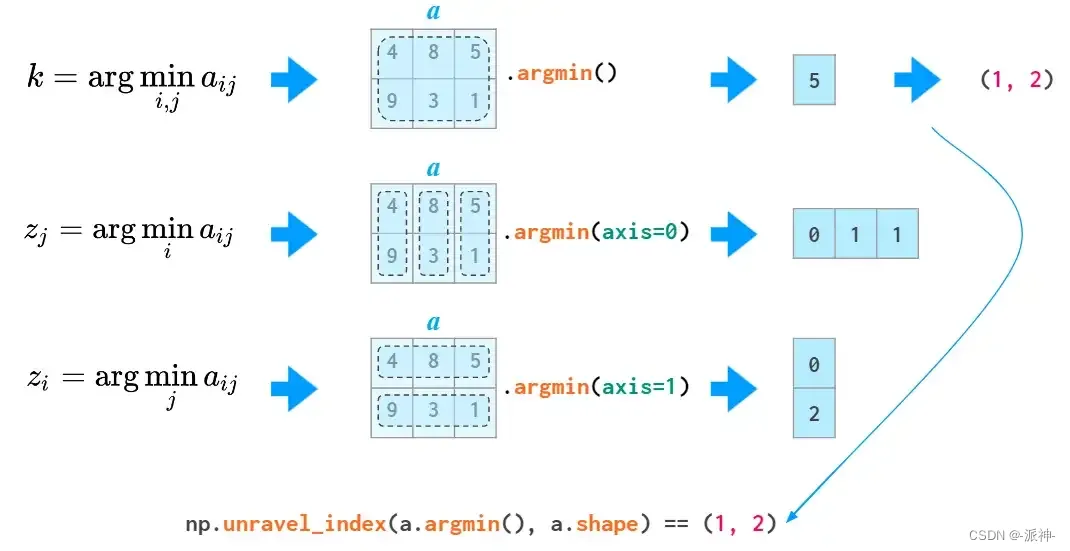
all和any两个函数也能使用axis参数:

矩阵排序
尽管axis参数对上面列出的函数有帮助,但对 二维 排序没有帮助

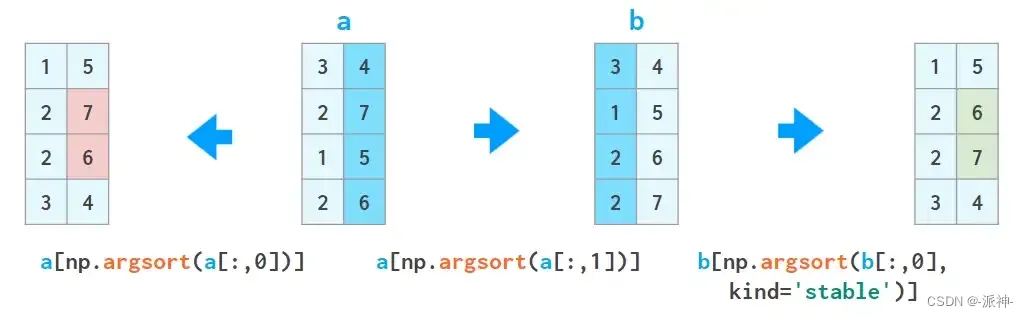
这通常不是您希望对矩阵或电子表格进行排序的结果:axis它根本不是key参数的替代品。但幸运的是,NumPy 有几个辅助函数,允许按列排序——如果需要,也可以按多列排序:
1. a[a[:,0].argsort()] 按第一列对数组排序:

这里argsort返回排序后原始数组的索引数组。
可以重复这个技巧,但必须注意下一次排序不会弄乱上一次的结果:a = a[a[:,2].argsort()]
a = a[a[:,1].argsort(kind='stable')]
a = a[a[:,0].argsort(kind='stable')]
2. 有一个辅助函数lexsort可以按照上面描述的方式对所有可用列进行排序,但它总是按行执行,并且要排序的行的顺序是倒置的(即从下到上)所以它的用法有点麻烦,例如:
–a[np.lexsort(np.rot90(a))]按从左到右的顺序按所有列排序。
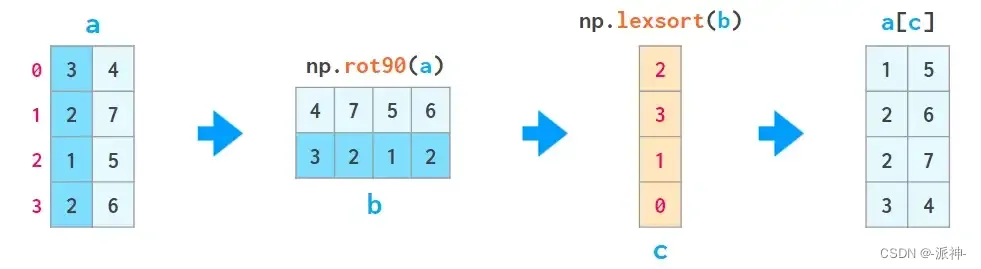
–a[np.lexsort(np.rot90(a[:,[2,5]]))]首先按第 2 列排序,然后(第 2 列中的值相等)按第 5 列排序。另一种形式是a[np.lexsort(np.flipud(a.T[[2,5]]))]
这里 flipud 在上下方向上翻转矩阵(准确地说,在axis=0方向上,与 相同a[::-1,...],其中三个点表示“所有其他维度”——所以突然flipud,而不是fliplr,翻转一维数组)并rot90旋转矩阵在正方向(即逆时针)旋转 90 度。flips 和 rot90 都返回视图。
3. 要使用 的order参数sort,首先将数组转换为结构化形式,然后对其进行排序,最后将其转换回普通(“非结构化”)形式:

这两种转换实际上都是视图,因此它们速度很快并且不需要任何额外的内存。但是功能u2s和s2u需要首先导入:
from numpy.lib.recfunctions
import unstructured_to_structured as u2s, structured_to_unstructured as s2u
4. 在 Pandas 中执行此操作可能是更好的选择,因为此特定操作在那里更具可读性且更不容易出错:
- pd.DataFrame(a).
sort_values(by=[2,5]).to_numpy():先按第 2 列排序,然后按第 5 列排序。 - pd.DataFrame(a).sort_values().to_numpy():按从左到右的顺序对所有列排序。
3. 3维及更高维
通过重排一维向量或转换嵌套的Python列表来创建3维数组时,索引的含义为(z,y,x)。第一个索引是平面的编号,然后是该平面中的坐标:

但是此索引顺序不是通用的。处理RGB图像时,通常使用(y,x,z)顺序:前两个是像素坐标,最后一个是颜色坐标(Matplotlib中是RGB ,OpenCV中是BGR ):
 RGB图像
RGB图像
这样,可以方便地引用特定像素:a[i,j]给出像素的RGB元组(i,j)。
因此,创建特定几何形状的实际命令取决于您正在处理的领域的约定:

显然,像 hstack、vstack、dstack 这样的 NumPy 函数并不知道这些约定。其中硬编码的索引顺序是 (y,x,z),RGB 图像顺序:

堆叠RGB图像(这里只有两种颜色)
如果您的数据布局不同,使用concatenate命令堆叠图像,在参数中为其提供显式索引号axis会更方便:
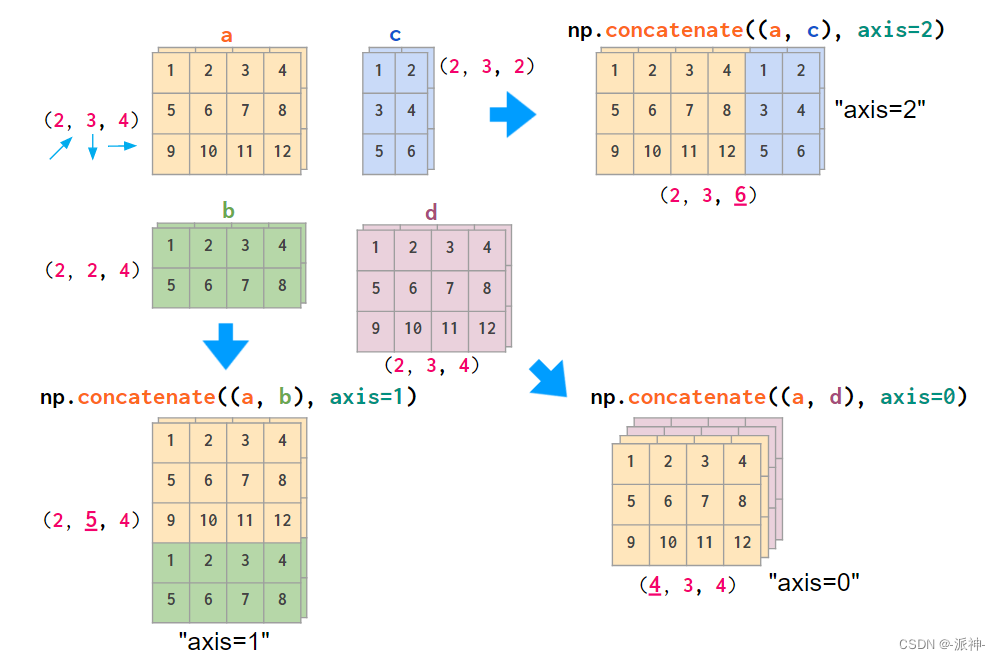
如果您不方便用数轴(axis)来思考问题,可以将数组转换硬编码为hstack的形式:
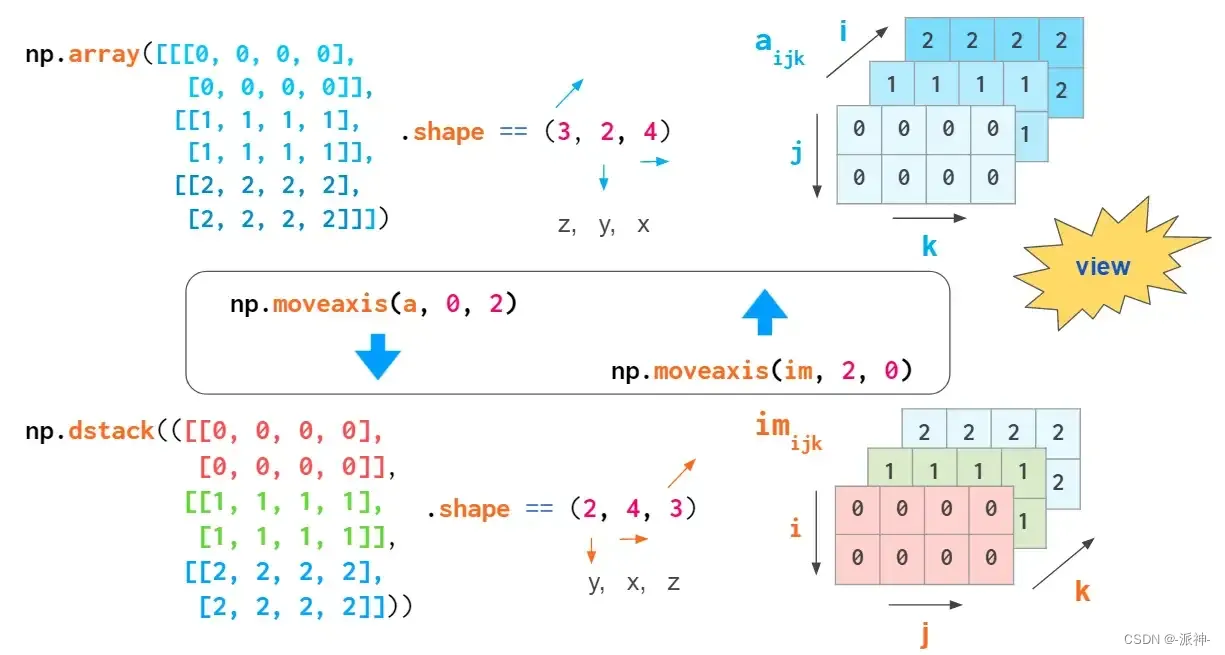
这种转换没有发生实际的复制操作。它只是混合索引的顺序。
另一个混合索引顺序的操作是数组转置。检查它可能会让您对 3维数组更加熟悉。根据您决定的轴(axis)顺序,转置数组所有平面的实际命令将有所不同:对于通用数组,它交换索引 1 和 2,对于RGB图像,它交换0和1:

有趣的是,默认transpose的轴参数axes(以及唯一的a.T操作模式)颠倒了索引顺序,这与上面描述的索引顺序约定都不一致。
广播也适用于更高维度,有关详细信息,请参阅我的简短文章“ NumPy 中的广播”。
最后,这里有一个函数可以在处理多维数组时为您节省大量的Python 循环,并可以使您的代码更简洁 — einsum(爱因斯坦求和):

它沿着重复索引对数组求和。在这个特定的例子中 np.tensordot(a, b, axis=1),这两种情况都足够了,但在更复杂的情况下 einsum 可能会工作得更快,而且通常更容易编写和阅读——一旦你理解了它背后的逻辑。
如果您想测试您的 NumPy 技能,GitHub 上有一套棘手的众包100 个 NumPy 练习¹⁰。
参考
- Scott Sievert,NumPy GPU 加速
- Jay Alammar,NumPy 和数据表示的可视化介绍
- Big-O备忘单网站
- Python 时间复杂度维基页面
- NumPy Issue #14989,排序函数中的反向参数
- NumPy Issue #2269,第一个非零元素
- Numba 图书馆主页
- 浮点指南,比较
- NumPy Issue #10161,numpy.isclose 与 math.isclose
- GitHub 上的 100 个 NumPy 练习
本文来自于Medium的一篇国外博主的博客文章 作者:Lev Maximov
原文地址:https://betterprogramming.pub/numpy-illustrated-the-visual-guide-to-numpy-3b1d4976de1d
\
智能推荐
【AD】CH340芯片PCB布线走差分线_ch340的接线需要差分吗-程序员宅基地
文章浏览阅读3.4k次。CH340 D+,CH340 D-,数据传输线需要使用差分走线步骤:点击Place->Interactive Differential Pair Routing两根差分线_ch340的接线需要差分吗
3d打印英语文献_多材料的增材制造(3D打印)-程序员宅基地
文章浏览阅读582次。点击江苏激光产业技术创新战略联盟关注/置顶公众号新闻资讯|技术文章|会议论坛|加工服务激光天地导读:本文主要介绍了多材料增材制造聚合物、金属-金属多材料以及金属-陶瓷多材料打印的应用,同时还讨论了多材料打印的优缺点。增材制造又叫3D打印,是一种革命性的制造技术,可以快速、经济的制造出复杂形状的制品。许多商业部门如汽车、航空航天、医疗甚至是食品工业部门均在开始大量采用..._增材制造外文文献csdn
Max31855测温的使用-程序员宅基地
文章浏览阅读4.9k次,点赞2次,收藏20次。最近在用stm32做关于max31855的程序,总结了一些使用经验。1.Max31855的介绍 MAX31855具有冷端补偿,将K、J、N、T或E型热电偶信号转换成数字量。 器件输出14位带符号数据,通过SPITM兼容接口、以只读 格式输出。转换器的温度分辨率为0.25℃,最高温度读数 为+1800℃,最低温度读数为-270℃,对于K型热电偶, 温度范围为-200℃至+700℃,保持±2℃精度 。总的来说,MAX31855测温范围非常广。2.使用Max31855的具体实现方法..._max31855
双边滤波-程序员宅基地
文章浏览阅读742次。双边滤波是一种非线性滤波,是结合图像的空间邻近度和像素值相似度的一种折中处理,同时考虑空域信息和灰度相似性,达到保边去噪的目的,具有简单、非迭代、局部的特点。可以做边缘保存。双边滤波器比高斯滤波多了一个高斯方差sigma-d,它是基于空间分布的高斯滤波函数,所以在边缘附近,离得较远的像素不会对边缘上的像素值影响太多,这样就保证了边缘附近像素值的保存。但是由于保存了过多的高频信息,对于彩色图像里的高..._双边滤波
ble- ATT profile详解_ble opcode-程序员宅基地
文章浏览阅读1.3k次。从数据格式了解ATTOpcode总体分为6种大类型的Opcoderequest / responseindicate / confirmcommandnotify所有的ATT数据,都是属于这6种类型的子类 request 和command从client 端发起,区别是request 必须要有response ,而command 不需要,单向 indicate和notify从server 端发起,区别是indicate必须要有confirm 返回,而notify不需要,单向 op_ble opcode
Python数据结构应用4——搜索(search)-程序员宅基地
文章浏览阅读394次。Search是数据结构中最基础的应用之一了,在python中,search有一个非常简单的方法如下:15 in [3,5,4,1,76]False不过这只是search的一种形式,下面列出多种形式的search用做记录:一、顺序搜索顺着list中的元素一个个找,找到了返回True,没找到返回Falsedef sequential_search(a_list, item): po..._python data search
随便推点
NLP新-自然语言处理表示学习_表示学习 nlp-程序员宅基地
文章浏览阅读321次。语义表示是自然语言处理的基础,我们需要将原始文本数据中的有用信息转换为计算机能够理解的语义表示,才能实现各种自然语言处理应用。表示学习旨在从大规模数据中自动学习数据的语义特征表示,并支持机器学习进一步用于数据训练和预测。以深度学习为代表的表示学习技术,能够灵活地建立对大规模文本、音频、图像、视频等无结构数据的语义表示,显著提升语音识别、图像处理和自然语言处理的性能,近年来引发了人工智能的新浪潮。本书是第一本完整介绍自然语言处理表示学习技术的著作。书中全面介绍了表示学习技术在自然语言处理领域的最新..._表示学习 nlp
python class和class(object)用法区别_class object)-程序员宅基地
文章浏览阅读2.6w次,点赞12次,收藏39次。转自:https://www.cnblogs.com/liulipeng/p/7069004.htmlhttps://blog.csdn.net/DeepOscar/article/details/80947155# -*- coding: utf-8 -*-# 经典类或者旧试类class A: passa = A()# 新式类class B(obj..._class object)
机器学习算法汇总:回归算法_机器学习回归算法有哪些-程序员宅基地
文章浏览阅读1k次。1、线性回归分类:一元线性回归、多元线性回归优缺点分析: 优点:模型简单、运算量小,即使数据量很大,仍然可以快速得到结果 模型的参数就是特征的权重,具有很好的解释性 缺点:对异常值敏感 当数据没有明显的线性关系时,效果很差原理分析: 主要思想:用一条直线或者一个平面去拟合所有的数据,使得真实值与预测值之间产生的误差(距离)最小 模型: ..._机器学习回归算法有哪些
高斯滤波器 matlab命令,【上海校区】3.过滤——高斯滤波器之Matlab、Octave实战_5...-程序员宅基地
文章浏览阅读300次。在Matlab使用高斯滤波器本文首先使用Matlab展示示例,我要做的是在Matlab中演示过滤中的代码和效果。基本上,Matlab构建过滤器和应用过滤器是非常常见,甚至琐碎的。Matlab,我们要做的是定义两件事:第一:我们将定义内核的大小;(请记住,这就是我们之前谈论的内容)>> hsize = 31;在这个例子它将是31乘31。注意是核大小为奇数,注意我才可以把中心像素画下来。第..._matlab中高斯滤波器截断范围
Android 在ListView的adapter里调用 activity里的方法_listview 调用 activity 方法-程序员宅基地
文章浏览阅读876次。如何在adapter里调用所在 Activity 所在类的方法呢,通过context . xx() ? 经过试验是不可以的,那该怎么办呢? 下面有几个方法: 1. 发广播: 定义一个局部广播,通过发广播,进行调用。具体怎么注册广播,发广播,就不具体写了,这些都是基本的。 2. 对传给 adapter的 context 进行强制转换: 注册_listview 调用 activity 方法
提升创造力:UI设计师不可错过的10个灵感网站-程序员宅基地
文章浏览阅读71次。同时,它还会不时更新设计资源,包含高质量的平面设计灵感内容,覆盖面广,你可以把它作为你的灵感来源,没有设计灵感,帮助你在监狱里快速找到设计灵感,属于不花钱就能得到的快乐。Uplabs是一个专门为设计师设计的资源推荐社区,汇集了大量的前端设计作品,以及大量的Android和iOSUI资源,是实时更新的。Pttrns是一个移动APP类集合网站,可以看到左侧导航栏有两个块,一个是按设备,(iPhone、iPad、Android、Watch),一个是根据APP界面模块搜索您想要的设计,非常详细。