SSD的基础知识介绍_ssd硬件基础知识-程序员宅基地
固态硬盘,英文名Solid State Disk或Solid State Drive,是一种以存储器作为永久性存储器的电脑存储设备。虽然SSD已不是使用“碟盘”来记存数据,也没有用于“驱动”的马达,但是人们依照命名习惯,仍然称为固态硬盘或固态驱动器。固态硬盘分易失性与非易失性两种,我们着重研究更适合作为传统硬盘替代品的非易失性固态硬盘。非易失性固态硬盘中数据的存取主要由NAND Flash及其主控芯片来实现,没有活动的机械部件,为纯芯片结构。
一,SSD的历史背景
1967.贝尔实验室的韩裔工程师姜大元和华裔工程师施敏发明了浮栅晶体管(Floating Gate Transistor) .
20世纪70年代,出现以RAM(内存芯片)为组装的SSD.缺点:体积大,容量小,掉电丢失数据.
1999年,BiTMICRO发布18GB的闪存SSD. RAM逐渐被闪存替代.
2003年,SSD开始被存储行业所熟知,各大存储厂商开始研究SSD.
2006年,三星发布32G的SSD,NextCom推出以SSD为存储的笔记本.
2007年,SSD的读写带宽和随机IOPS性能超越HDD,SSD和HDD的竞争正式开始.
2008年,全球SSD厂商突破100家,SanDisk成为全球SSD领头羊.
2009年,SSD容量超越HDD,各大厂商开始推出以TB为容量的SSD.
2010年,全球SSD市场达到10亿美元.企业级以SLC为主,消费级开始走向MLC.
2013年,企业级PCIE的SSD问世,容量大,速度快,数据掉电保护,SSD开始在协议上引发技术革命.
2015年,东芝发布了48层16GB的3D闪存样品,西部数据190亿美金收购Sandisk.
2016年,企业级SSD开始出现快速的技术更新,支持PCIE 4.0的SSD问世.
2020年,全球SSD出货量超越了HDD,HDD开始走向大容量发展的道路.
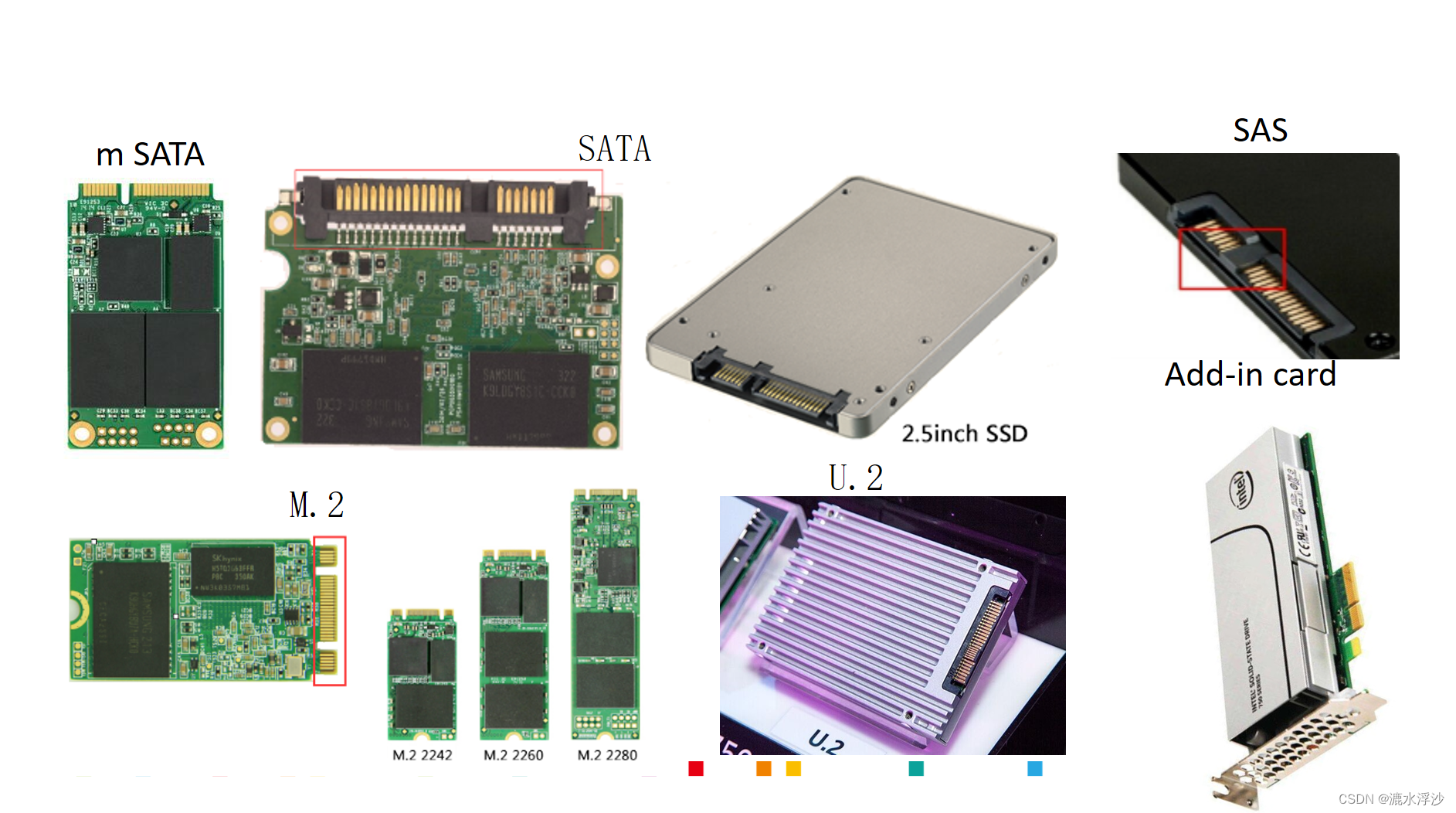
二 SSD常见的形态
NAND是半导体存储颗粒的一种(还有其他的种类,比如NOR), 简单来说,NAND可以视作是由很多很多个电容器组成的集成电路。制造NAND和制造CPU处理器类似,都是使用高纯度硅,切割成晶圆之后使用光刻机和化学溶剂将设计好的电路蚀刻上去,然后用金属材料“镶嵌”制作而成的。这样做出来的是一个布满NAND芯片的晶圆。将晶圆切开,然后对切割后的芯片精心挑选测试,封装后就可以出厂了。虽然整个工艺虽然和制造CPU类似,但是电路等方面还是简单不少的
常见的企业级SSD有SATA,NVME这两种。随着PCIE的不断提速,nvme的SSD产量越来越高,SATA的SSD在逐步减少。本文重点介绍NVME的SSD
三 SSD的内部结构
SSD主要由控制单元和存储单元(当前主要是FLASH闪存颗粒)组成,控制单元包括SSD控制器、主机接口、DRAM等,存储单元主要是NAND FLASH颗粒。

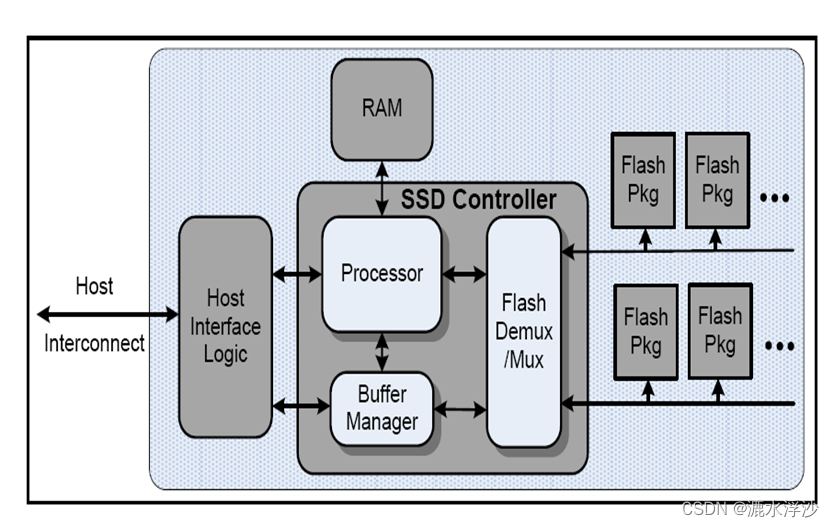
主机接口:主机访问SSD的协议和物理接口,常用的有SATA、SAS和PCIE等。
SSD控制器:负责主机到后端介质的读写访问和协议转换,表项管理、数据缓存及校验等,是SSD的核心部件。
DRAM:FTL表项和数据的缓存,以提供数据访问性能。
NAND FLASH:数据存储的物理器件载体。
四 SSD的读写原理
SSD的内部构造比较简单,一般是主控和NAND这两大部分。下面我看看SSD是如何工作的
SSD主控通过若干个通道(channel)并行操作多块FLASH颗粒,类似RAID0,大大提高底层的带宽。举个例子,假设主控与FLASH颗粒之间有8个通道,每个通道上挂载了一个闪存颗粒,HOST与FLASH之间数据传输速率为200MB/s。该闪存颗粒Page大小为8KB,FLASH page的读取时间为Tr=50us,平均写入时间为Tp=800us,8KB数据传输时间为Tx=40us。那么底层读取最大带宽为(8KB/(50us+40us))*8 = 711MB/s,写入最大带宽为 (8KB/(800us+40us))*8 = 76MB/s。从上可以看出,要提高底层带宽,可以增加底层并行的颗粒数目,也可以选择速度快的FLASH颗粒(或者让速度慢的颗粒变快,比如MLC配成SLC使用)。
我们以8通道为例,来讲讲HOST怎么读写SSD。主控通过8通道连接8个FLASH DIE,为方便解释,这里只画了每个DIE里的一个Block,其中每个小方块表示一个Page (假设大小为4KB)。
HOST写入4KB数据
HOST继续写入16KB数据
HOST继续写入,最后整个Block都写满
当所有Channel上的Block都写满的时候,SSD主控会挑选下一个Block以同样的方式继续写入。
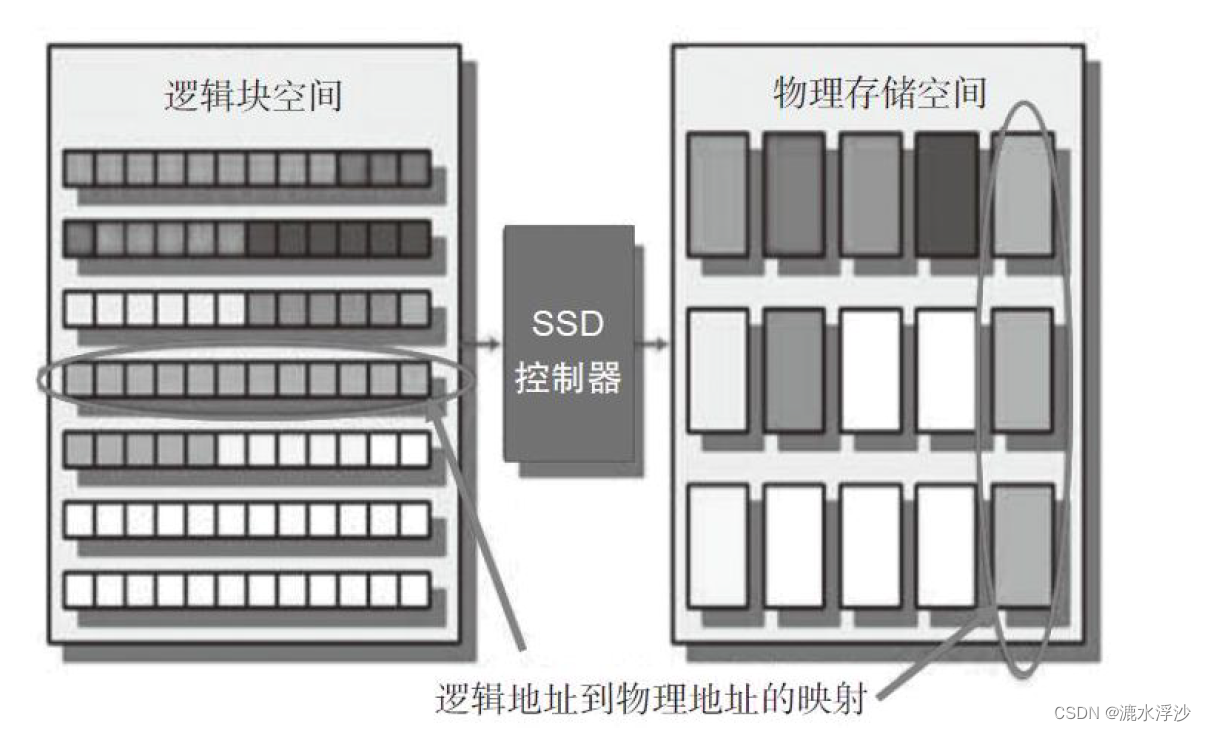
HOST是通过LBA(Logical Block Address,逻辑地址块)访问SSD的,每个LBA代表着一个Sector(一般为512B大小),操作系统一般以4K为单位访问SSD,我们把HOST访问SSD的基本单元叫用户页(Host Page)。而在SSD内部,SSD主控与FLASH之间是FLASH Page为基本单元访问FLASH的,我们称FLASH Page为物理页(Physical Page)。HOST每写入一个Host Page, SSD主控会找一个Physical Page把Host数据写入,SSD内部同时记录了这样一条映射(Map)。有了这样一个映射关系后,下次HOST需要读某个Host Page 时,SSD就知道从FLASH的哪个位置把数据读取上来。
SSD内部维护了一张映射表(Map Table),HOST每写入一个Host Page,就会产生一个新的映射关系,这个映射关系会加入(第一次写)或者更改(覆盖写)Map Table;当读取某个Host Page时, SSD首先查找Map Table中该Host Page对应的Physical Page,然后再访问Flash读取相应的Host数据。
由于闪存页和逻辑页大小不同,一般前者大于后者,所以实际上不会是一个逻辑页对应一个物理页,而是若干个逻辑页写在一个物理页中,逻辑页其实是和子物理页一一对应的。
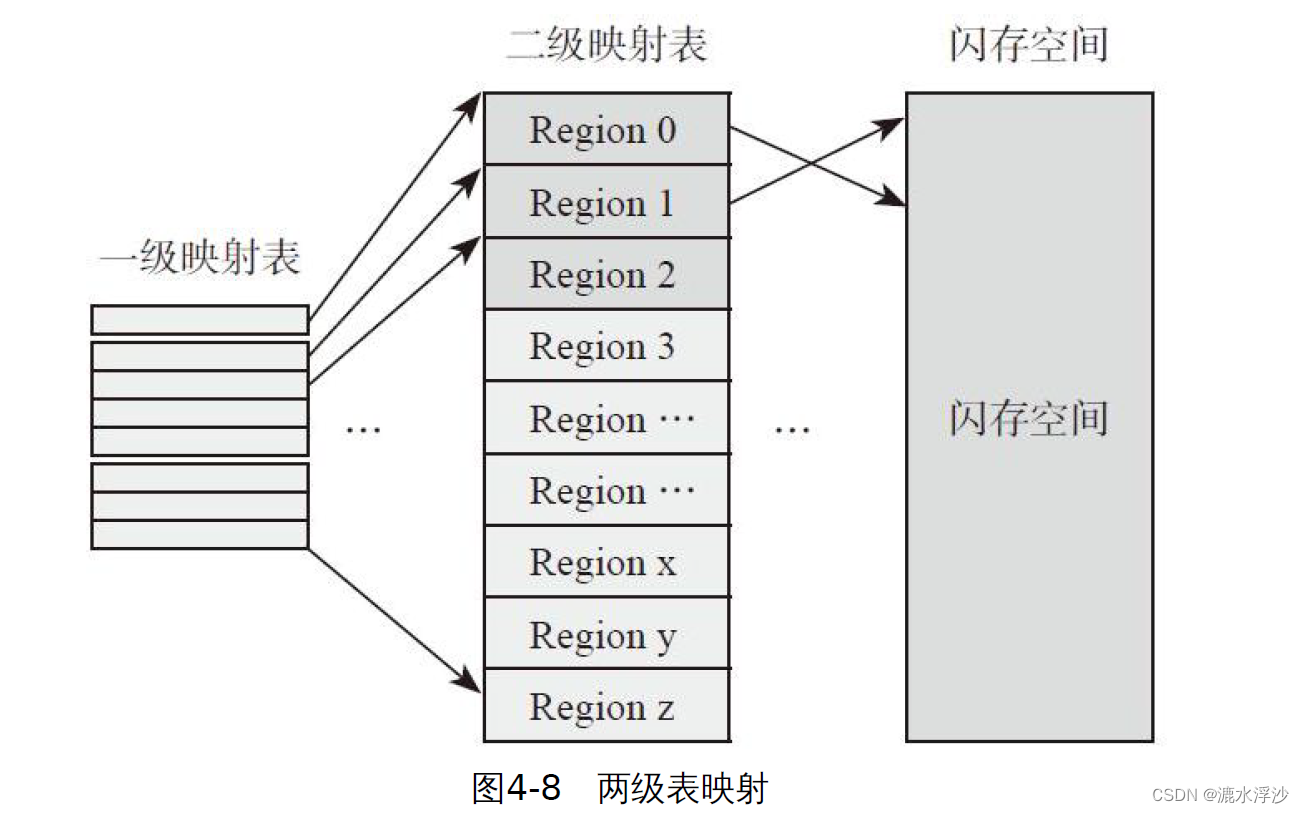
一张映射表有多大呢?
这里假设我们有一个256GB的SSD,以4KB大小的逻辑页为例,那么用户空间一共有64M(256GB/4KB)个逻辑页,也就意味着SSD需要有能容纳64M条映射关系的映射表。映射表中的每个单元(entry)存储的就是物理地址(Physical Page Address),假设其为4字节(32bits),那么整个映射表的大小为64M×4B=256MB。一般来说,映射表大小为SSD容量大小的千分之一。
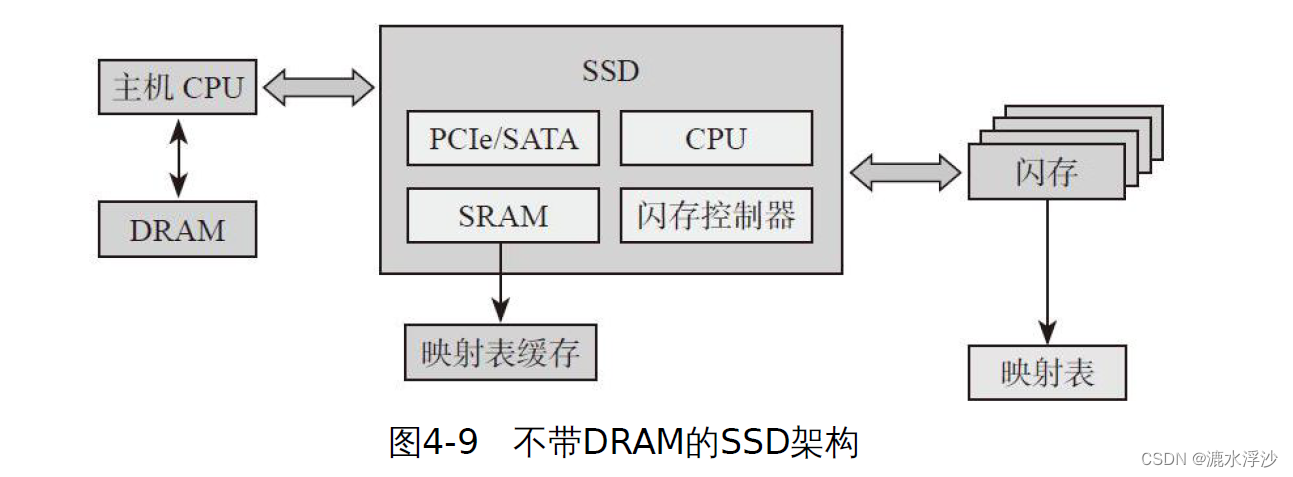
准确来说,映射表大小是SSD容量大小的1/1024。前提条件是:映射页大小为4KB,物理地址用4Byte表示。这里假设了SSD内部映射粒度等于逻辑页大小,当然它们可以不一样。对于绝大多数SSD,我们可以看到上面都有板载DRAM,其主要作用就是存储这张映射表,如图4-7所示。在SSD工作时,全部或绝大部分的映射表都可以放在DRAM上,映射关系可以快速访问。
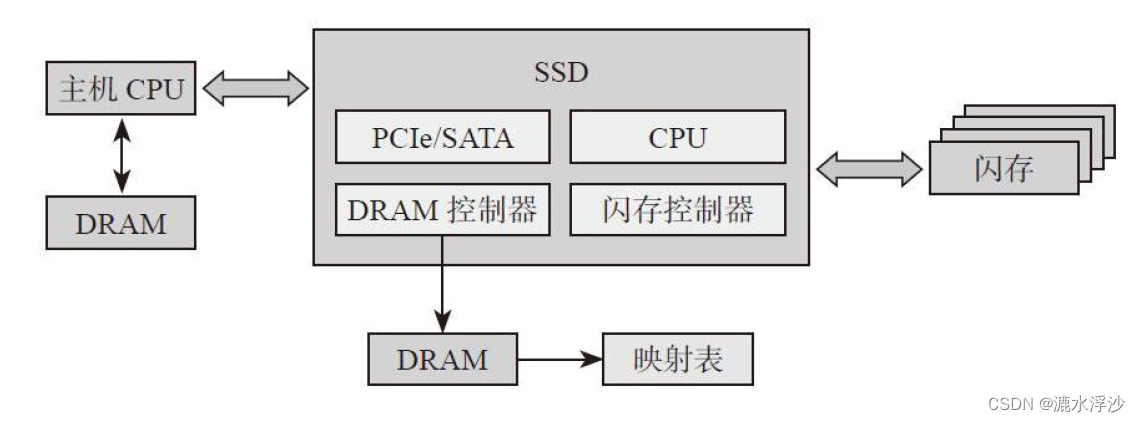
对绝大多数SSD,我们可以看到上面都有板载DRAM,其主要作用就是用来存储这张映射表。也有例外,比如基于Sandforce主控的SSD,它并不支持板载DRAM,那么它的映射表存在哪里呢?SSD工作时,它的绝大部分映射是存储在FLASH里面,还有一部分存储在片上RAM上。当HOST需要读取一笔数据时,对有板载DRAM的SSD来说,只要查找DRAM当中的映射表,获取到物理地址后访问FLASH从而得到HOST数据.这期间只需要访问一次FLASH;而对Sandforce的SSD来说,它首先看看该Host Page对应的映射关系是否在RAM内,如果在,那好办,直接根据映射关系读取FLASH;如果该映射关系不在RAM内,那么它首先需要把映射关系从FLASH里面读取出来,然后再根据这个映射关系读取Host数据,这就意味着相比有DRAM的SSD,它需要读取两次FLASH才能把HOST数据读取出来,底层有效带宽减半。对HOST随机读来说,由于片上RAM有限,映射关系Cache命中(映射关系在片上RAM)的概率很小,所以对它来说,基本每次读都需要访问两次FLASH,所以我们可以看到基于Sandforce主控的SSD随机读取性能是不太理想的。
当整个SSD写满后,从用户角度来看,如果想写入新的数据,则必须删除一些数据,然后腾出空间再写。用户在删除和写入数据的过程中,会导致一些Block里面的数据变无效或者变老。由于闪存不能覆盖写,闪存块需擦除才能写入。主机发来的某个数据块,它不是写在闪存固定位置,SSD可以为其分配任何可能的闪存空间写入。因此,SSD内部需要FTL这样一个东西,完成逻辑数块到闪存物理空间的转换或者映射。
Block中的数据变老或者无效,是指没有任何映射关系指向它们,用户不会访问到这些FLASH空间,它们被新的映射关系所取代。比如有一个Host Page A,开始它存储在FLASH空间的X,映射关系为A->X。后来,HOST重写了该Host Page,由于FLASH不能覆盖写,SSD内部必须寻找一个没有写过的位置写入新的数据,假设为Y,这个时候新的映射关系建立:A→Y,之前的映射关系解除,位置X上的数据变老失效,我们把这些数据叫垃圾数据。
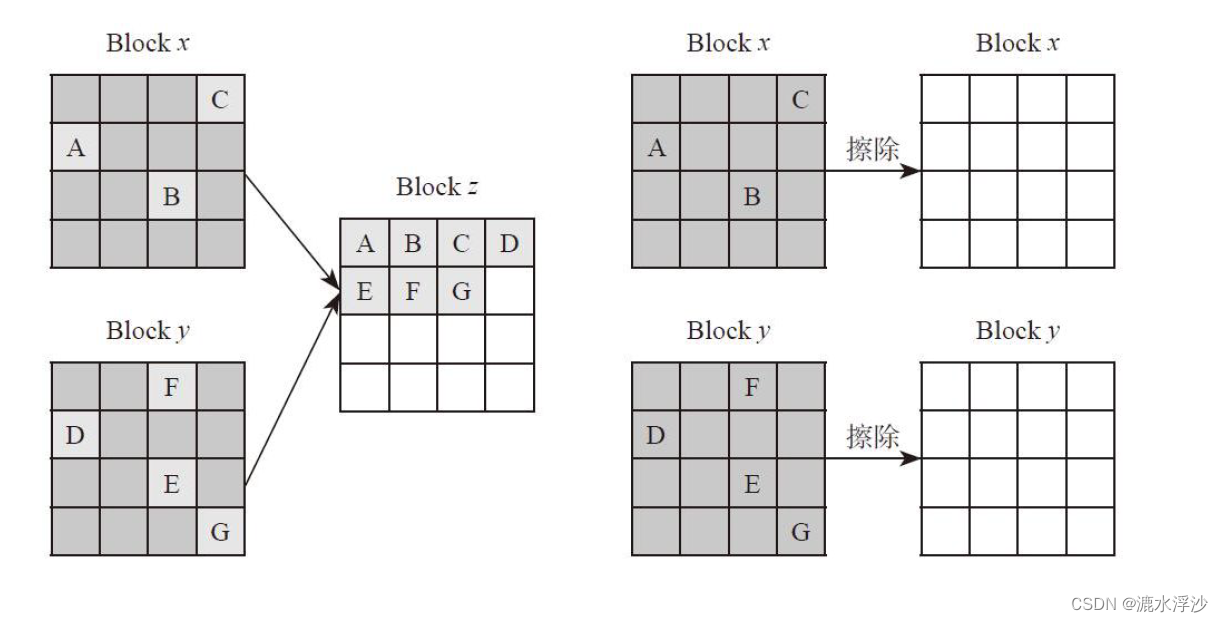
随着HOST的持续写入,FLASH存储空间慢慢变小,直到耗尽。如果不及时清除这些垃圾数据,HOST就无法写入。SSD内部都有垃圾回收机制,它的基本原理是把几个Block中的有效数据(非垃圾数据,上图中的绿色小方块表示的)集中搬到一个新的Block上面去,然后再把这几个Block擦除掉,这样就产生新的可用Block了。
上图中,Block x上面有效数据为A,B,C,Block y上面有效数据为D,E,F,G,红色方块为无效数据。垃圾回收机制就是先找一个未写过的可用Block z,然后把Block x和Block y的有效数据搬移到Block z上面去,这样Block x和Block y上面就没有任何有效数据,可以擦除变成两个可用的Block。
一块刚买的SSD,你会发现写入速度很快,那是因为一开始总能找到可用的Block来进行写入。但是,随着你对SSD的使用,你会发现它会变慢。原因就在于SSD写满后,当你需要写入新的数据,往往需要做上述的垃圾回收:把若干个Block上面的有效数据搬移到某个Block,然后擦掉原先的Block,然后再把你的Host数据写入。这比最初单纯的找个可用的Block来写耗时多了,所以速度变慢也就可以理解了。
还是以上图为例。假设HOST要写入4KB数据 (H) ,由于当前可用Block过少,SSD开始做垃圾回收。从上图可以看出,对Block x来说,它需要把Page A,B,C的数据读出并写入到Block z,然后Block x擦除用于HOST数据写入。从Host角度,它只写了4KB数据,但从SSD内部来说,它实际写入了4个Page(Page A, B, C写入Block z,4KB数据H写入到Block x)
2008年,Intel公司和SiliconSystems公司(2009 年被西部数字收购)第一次提出了写入放大(Write Application)并在公开稿件里用到这个术语。
在上面例子中,Host写了4KB数据,闪存写了4个4KB数据,所以上面例子中写放大为4。
假设一个SSD,底下所有FLASH容量为256GB,开放给用户使用也是256GB,那么问题就来了。想象一个场景,HOST持续写满整个SSD,接着删除一些文件,写入新的文件数据,试问新的数据能写入吗?在SSD底层,如果要写入新的数据,必须要有可用的空闲Block,但由于之前256GB空间已经被HOST数据占用了,根本就没有空闲Block来写你的数据。不对,你刚才不是删了一些数据吗?你可以垃圾回收呀。不错,但问题来了,在上面介绍垃圾回收的时候,我们需要有Block z来写回收来的有效数据,我们这个时候连Block z都找不到,谈什么垃圾回收?所以,最后是用户写失败。
上面这个场景至少说明了一点,SSD内部需要预留空间(需要有自己的小金库,不能工资全部上缴),这部分空间HOST是看不到的。这部分预留空间,不仅仅用以做垃圾回收,事实上,SSD内部的一些系统数据,也需要预留空间来存储,比如前面说到的映射表(Map Table),比如SSD固件,以及其它的一些SSD系统管理数据。
一般从HOST角度来看,1GB= 1,000,000,000Byte,从底层FLASH角度,1GB=1102410241024Byte。256GB FLASH 为256(2^30) Byte,而一般说的256GB SSD 容量为256*(10^9) Byte,这样,天然的有(256*(230)-256*(109))/(256*(10^9)) = 7.37%的OP。如果把256GB Flash容量的SSD配成240GB的,那么它的OP是多大呢? (256*(230)-240*(109))/(240*(10^9)) = 14.5%
除了满足基本的使用要求外,OP变大有什么坏处或者好处呢?坏处很显然,用户能使用的SSD容量变小。那么好处呢?
回到垃圾回收原理来。
再看一下这张图。回收Block x,上面有3个有效Page,需要读写3个Page完成整个Block的回收;而回收Block y时,则需要读写4个有效Page。两者相比,显然回收Block x比回收Block y快一些。说明一个简单的道理:一个Block上有效的数据越少(垃圾数据越多),则回收速度越快。
256GB FLASH配成256GB的SSD (OP = 7.37%), 意味着256*(10^9)的有效数据写到 256*(230)的空间,每个Block上面的平均有效数据率可以认为是256*(109)/256*(2^30) = 93.1%。
如果配成240GB的SSD,则意味着240*(109)的有效数据写到256*(230)的空间,每个Block的平均有效数据率为240*(109)/256*(230) = 87.3%。 OP越大,每个Block平均有效数据率越小,因此我们可以得出的结论:
OP越大,垃圾回收越快,写放大越小。这就是OP大的好处。
写放大越小,意味着写入同样多的HOST数据,写入到FLASH中的数据越少,也就意味着FLASH损耗越小。FLASH都是有一定寿命的,它是用P/E数 (Program/Erase Count)来衡量的。如果SSD集中对某几个Block进行擦写,那么这几个Block很快就寿命耗尽。比如在用户空间,有些数据是频繁需要更新的,那么这些数据所在Block就需要频繁的进行擦写,这些Block的寿命就可能很快的耗尽。相反,有些数据用户是很少更新的,比如一些只读文件,那么这些数据所在的Block擦写的次数就很少。随着用户对SSD的使用,就会形成一些Block有很高的PE数,而有些Block的PE数却很低的。这不是我们想看到的,我们希望所有Block的PE数都应该差不多,就是这些Block被均衡的使用。在SSD内部,有一种叫磨损平衡(Wear Leveling,WL)的机制来保证这点。
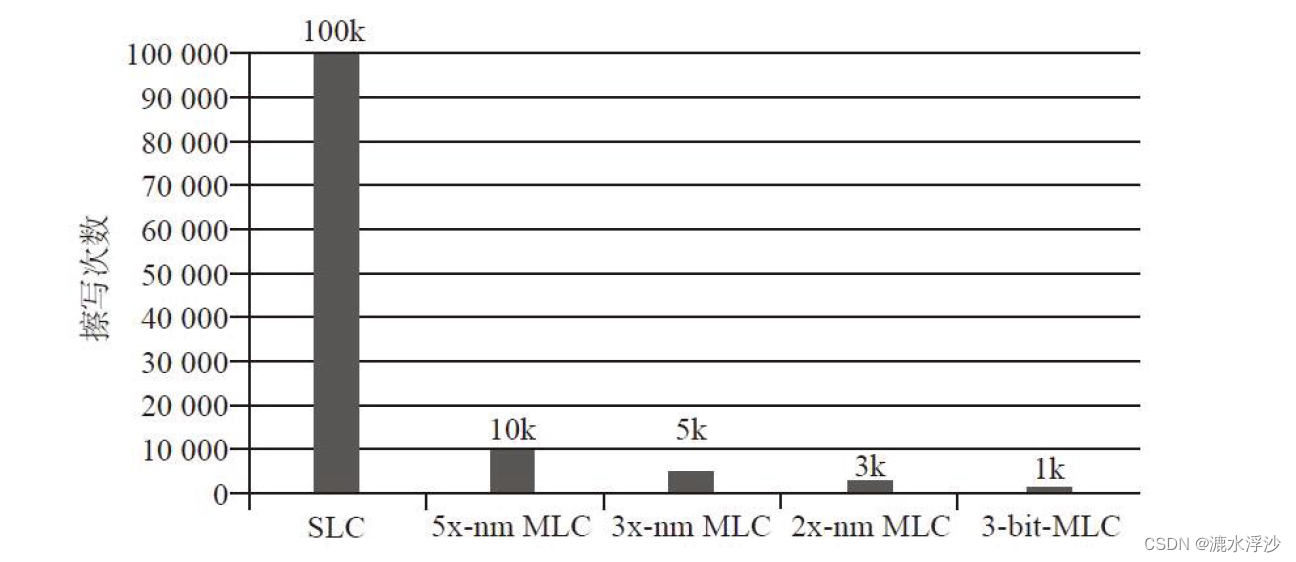
一个闪存块寿命有多长呢?从SLC十几万的擦写次数,到MLC几千的擦写次数,然后到TLC的一两千次甚至几百次擦写次数,随着闪存工艺不断向前推,闪存的寿命越来越短,SSD对磨损平衡的处理要求也越来越高,如下所示。
WL有两种算法:动态WL和静态WL。所谓动态WL,就是在使用Block进行擦写操作的时候,优先挑选PE 数低的;所谓静态WL,就是把长期没有修改的老数据(如前面提到的只读文件数据)从PE数低的Block当中搬出来,然后找个PE 数高的Block进行存放,这样,之前低PE数的Block就能拿出来使用
假设有一个SSD里有4096个闪存块,擦写次数为10000次,其中2.5%为备用区。现在我写入三个文件,每个文件占据了50个块的容量,每10分钟更新其中一个文件,如果没有WL的话,那就是全盘只有前200(3个数据块3*50,+ 一个搬运数据块50)个块在做擦写操作了。那么可以计算它的寿命大概是

如果做了WL呢
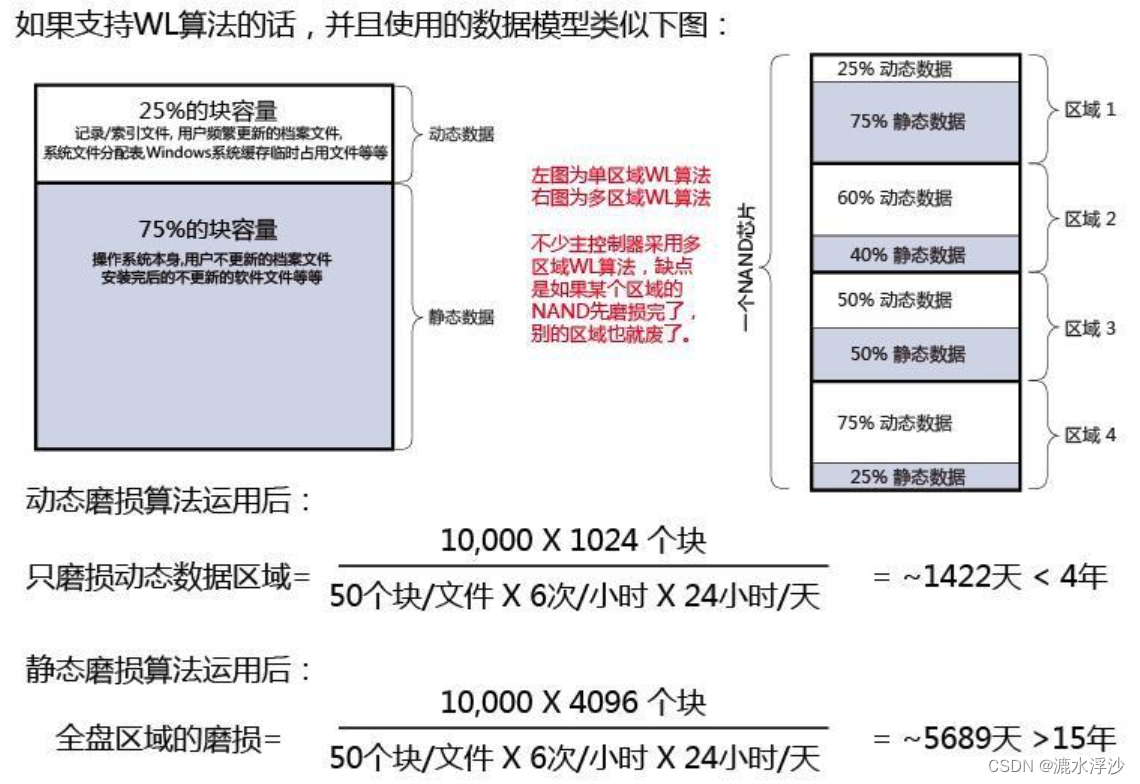
可以看到 做磨损平衡之后。SSD的寿命能延长很多
智能推荐
十六进制与字节数组转换_bytearraytohexstring-程序员宅基地
文章浏览阅读7.2k次。前段时间开发手持机上的软件,因为A8手持机的射频卡可存储的内容太小,并且需要存储16进制数据,因此就写了一个工具类。上代码:package cn.com.szh;import java.io.UnsupportedEncodingException;public class Main { public static void main(String[] args) { Stri..._bytearraytohexstring
对每个边缘求最小外接矩形,通过最小矩形提取每个边缘_边缘的最小外接矩形-程序员宅基地
文章浏览阅读4.9k次。#include #include using namespace std;using namespace cv;int main(){Mat src; //源图像Mat tmp; //临时图像Mat dst_bw; //去掉背景后的目标二值图像Mat dst_contours;//轮廓图像src=imread("E:\\单板图片\\求孔洞数_边缘的最小外接矩形
【设计模式】中介者-程序员宅基地
文章浏览阅读865次。中介者,说白了跟市面上黑中介类似。当然这个中介,开发者是可以控制其行为的。也是在一定的信任关系上建立的。该模式要解决的问题是,一堆对象之间交叉耦合问题。网上看过群聊的例子。如果没有任何一个平台,多人之间的会话会是什么样的呢?不举多人,就三个吧A想把一句话说给BC,那么他首先要知道B和C在哪儿,然后分别告诉对方,自己想说的事情。如果再加一个人呢?问题很明显,此时各种群聊工具应运而生。我写
Mysql列自增是怎么实现的_mysql 自增序列生成原理-程序员宅基地
文章浏览阅读1.8k次。AUTO_INCREMENT两种情况1、在载入语句执行前,已经不确定要插入多少条记录。在执行插入语句时在表级别加一个auto-inc锁,然后为每条待插入记录的auto-increment修饰的列分配递增的值,语句执行结束后,再把auto-inc锁释放掉。一个事务再持有auto-inc锁的过程中,其他事务的插入语句都要被阻塞,可以保证一个语句中分配的递增值是连续的。AUTO-INC锁的..._mysql 自增序列生成原理
半导体器件基础_掺杂半导体的带隙-程序员宅基地
文章浏览阅读3.5k次,点赞2次,收藏17次。半导体能带结构示意图:上方两条白色带为没有电子填充的带,下面三条灰色带为充满电子的带,其中最高一条灰色带为价带,它与最低一条白色带之间的空隙为能隙空穴又称电洞(Electron hole),在固体物理学中指共价键上流失一个电子,最后在共价键上留下空位的现象导带(英语:conduction band),又名传导带,是指半导体或是绝缘体材料中,一种电子所具有能量的范围。这个能量的范围高..._掺杂半导体的带隙
基于C++和OpenCV的中心线提取算法_图像中心线提取c++-程序员宅基地
文章浏览阅读3.5k次,点赞2次,收藏26次。基于C++和OpenCV的中心线提取算法加权平方灰度重心法介绍算法演示加权平方灰度重心法介绍详情见 https://blog.csdn.net/u010518385/article/details/101015604算法演示下面展示 函数-输入图像和阈值,输出点。void get_median_line(Mat& src, int thresh, vector<Point2d>& points){ if (src.empty()) return; // 一、_图像中心线提取c++
随便推点
QT 出现“找不到libgcc_s_dw2-1.dll”的解决方式_qt打包缺少libgcc_s_dw2-1.dll-程序员宅基地
文章浏览阅读5k次。在使用QT时,运行程序时,可能出现QT找不到DLL的问题,这种情况大多数情况是因为没有将QT添加到环境变量的原因。解决方式:我的电脑-高级设置-环境变量将QT的两个bin文件目录路径添加到环境变量中,即可解决这个问题!..._qt打包缺少libgcc_s_dw2-1.dll
Socket网络编程-程序员宅基地
文章浏览阅读1.5w次,点赞15次,收藏74次。Socket1 环境查看通过cmd窗口的命令:ipconfig查看本机IP地址查看网络情况是否正常:ping百度官网用来进行本地测试的地址 127.0.0.1,回环测试地址,默认代表的就是本机的IP2 Socket概述socket编程也叫套接字编程,应用程序可以通过它发送或者接受数据,可对其像打开文件一样打开/关闭/读写等操作.套接字允许应用程序将I/O插入到网络中,并与网络中的其他应用程序进行通信.网络套接字是IP地址与端口号TCP协议的组合Socket就是为网络编程提供的一_socket网络编程
java mp3格式转wav,在Java中将mp3转换为WAV-程序员宅基地
文章浏览阅读574次。I installed the mp3spi to support reading mp3 files in my Java 8 project usng the javax.sound* libraries. My goal now is to write mp3 to a wav file. However, the result is incorrect. Here's the code i..._java mp3转wav
Unity设置物体的自转和公转_unity2d 公转-程序员宅基地
文章浏览阅读2.7w次,点赞4次,收藏18次。正好要做一个天空的场景,想添加上行星和恒星的自转和公转,代码如下1.自转。public float _RotationSpeed; //定义自转的速度transform.Rotate(Vector3.down*_RotationSpeed,Space.World); //物体自转2.公转 public GameObject Axis; //物体需要公转的参_unity2d 公转
C++ string的trim, split方法_c++ string trim-程序员宅基地
文章浏览阅读7.6k次。 很多其他语言的libary都会有去除string类的首尾空格的库函数,但是标准C++的库却不提供这个功能。但是C++string也提供很强大的功能,实现trim这种功能也不难。下面是几种方法: 1.使用string的find_first_not_of,和find_last_not_of方法 /* Filename : StringTrim1...._c++ string trim
JAVA开发(保姆级微服务搭建过程)_java 微服务-程序员宅基地
文章浏览阅读4.4k次,点赞4次,收藏26次。现在的java后端基本都是通过微服务的方式进行搭建。当我们对需求进行分割时,可以通过横向或者纵向对服务进行划分。或者当某一块的业务我们希望通过一个单独的服务进行开发时,就需要新增新的服务,本文通过springtool suite工具介绍,微服务搭建过程。_java 微服务