Spark 基本知识介绍-程序员宅基地
文章目录
1. Spark是什么
Spark是用于大规模数据处理的统一分析引擎。
Spark 最早源于一篇论文 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing,该论文是由加州大学柏克莱分校的 Matei Zaharia 等人发表的。论文中提出了一种弹性分布式数据集(即 RDD)的概念。
RDD是一种分布式内存抽象,其使得程序员能够在大规模集群中做内存运算,并且有一定的容错方式。而这也是整个Spark的核心数据结构,Spark整个平台都围绕着RDD进行。
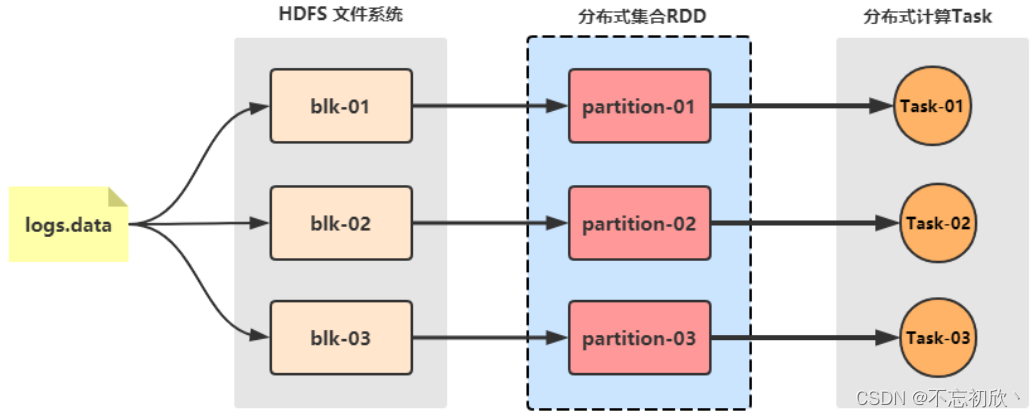
Spark借鉴了MapReduce思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度,并提供丰富的操作数据的API提高了开发速度。
2. Spark与Hadoop区别
| hadoop | spark | |
|---|---|---|
| 类型 | 基础平台,包含计算,存储,调度 | 纯计算工具(分布式) |
| 场景 | 海量数据批处理(磁盘迭代计算) | 海量数据的批处理(内存迭代计算,交互式计算),海量数据流计算,机器学习,图计算 |
| 价格 | 对机器要求低,便宜 | 对内存有要求,相对较贵 |
| 编程范式 | Map+Reduce,API较为底层,算法适应性差 | RDD组成DAG有向无环图,API较为顶层,方便使用 |
| 数据存储结构 | MapReduce中间计算结果在HDFS磁盘上,延迟大 | RDD中间运算结果在内存中,延迟小 |
| 运行方式 | Task以进程方式维护,任务启动慢 | Task以线程方式维护,任务启动快,可批量创建提高并行能力 |
虽然Spark相对Hadoop而言有较大的优势,但Spark并不能完全代替Hadoop,Spark仅能做计算,而Hadoop生态圈不仅有计算(MapReduce),还有存储(HDFS)和资源管理调度(YARN)。
Hadoop中的MR中每个map/reduce task都是一个java进程方式运行,好处在于进程之间是互相独立的,每个task独享进程资源,没有互相干扰,监控方便,但是问题在于task之间不方便共享数据,执行效率比较低。比如多个map task读取不同数据源文件需要将数据源加载到每个map task中,造成重复加载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark采用了线程的最小的执行单位,但缺点是线程之间会有资源竞争。
3. Spark四大特点
3.1 速度快
由于Apache Spark支持内存计算,并且通过DAG(有向无环图)执行引擎支持无环数据流,所以官方宣称其在内存中的运算速度要比Hadoop的MapReduce快100倍,在硬盘中要快10倍。
Spark处理数据与MapReduce处理数据相比,有如下两个不同点:
- Spark处理数据时,可以将中间处理结果数据存储到内存中;
- Spark 提供了非常丰富的算子(API), 可以做到复杂任务在一个Spark 程序中完成
3.2 易于使用
Spark支持了包括 Java、Scala、Python 、R和SQL语言在内的多种语言。
3.3 通用性强

在 Spark 的基础上,Spark 还提供了包括Spark SQL、Spark Streaming、MLib 及GraphX在内的多个工具库,我们可以在一个应用中无缝地使用这些工具库。
3.4 运行方式

Spark 支持多种运行方式,包括在 Hadoop 和 Mesos 上,也支持 Standalone的独立运行模式,同时也可以运行在云Kubernetes(Spark 2.3开始支持)上。
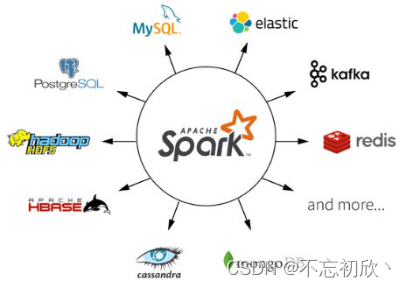
对于数据源,Spark 支持从HDFS、HBase、Cassandra 及 Kafka 等多种途径获取数据。
4. Spark整体框架
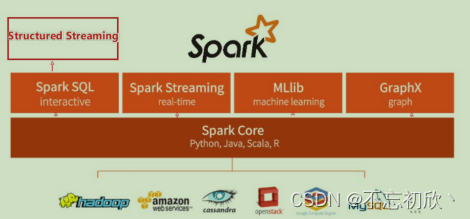
整个Spark 框架模块包含:Spark Core、 Spark SQL、 Spark Streaming、 Spark GraphX、 Spark MLlib,而后四项的能力都是建立在Spark Core之上。
- Spark Core:Spark的核心,Spark核心功能均由Spark Core模块提供,是Spark运行的基础。Spark Core以RDD为数据抽象,提供Python、Java、Scala、R语言的API,可以编程进行海量离线数据批处理计算。
- SparkSQL:基于SparkCore之上,提供结构化数据的处理模块。SparkSQL支持以SQL语言对数据进行处理,SparkSQL本身针对离线计算场景。同时基于SparkSQL,Spark提供了StructuredStreaming模块,可以以SparkSQL为基础,进行数据的流式计算。
- SparkStreaming:以SparkCore为基础,提供数据的流式计算功能。
- MLlib:以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习计算。
- GraphX:以SparkCore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算。
5. Spark运行模式
Spark提供多种运行模式,主要包括以下四种:
- 本地模式(单机):本地模式就是以一个独立的进程,通过其内部的多个线程来模拟整个Spark运行时环境
- Standalone模式(集群):Spark中的各个角色以独立进程的形式存在,并组成Spark集群环境
- Hadoop YARN模式(集群):Spark中的各个角色运行在YARN的容器内部,并组成Spark集群环境
- Kubernetes模式(容器集群):Spark中的各个角色运行在Kubernetes的容器内部,并组成Spark集群环境
6. Spark架构角色
6.1 YARN角色
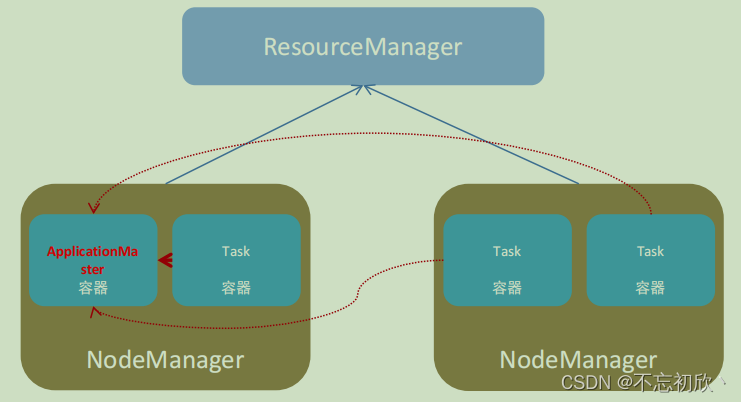
资源管理层面:
- 集群资源管理者(Master):ResourceManager
- 单机资源管理者(Worker):NodeManager
任务计算层面:
- 单任务管理者(Master):ApplicationMaster
- 单任务执行者(Worker):Task(容器内计算框架的工作角色)
6.2 Spark 角色
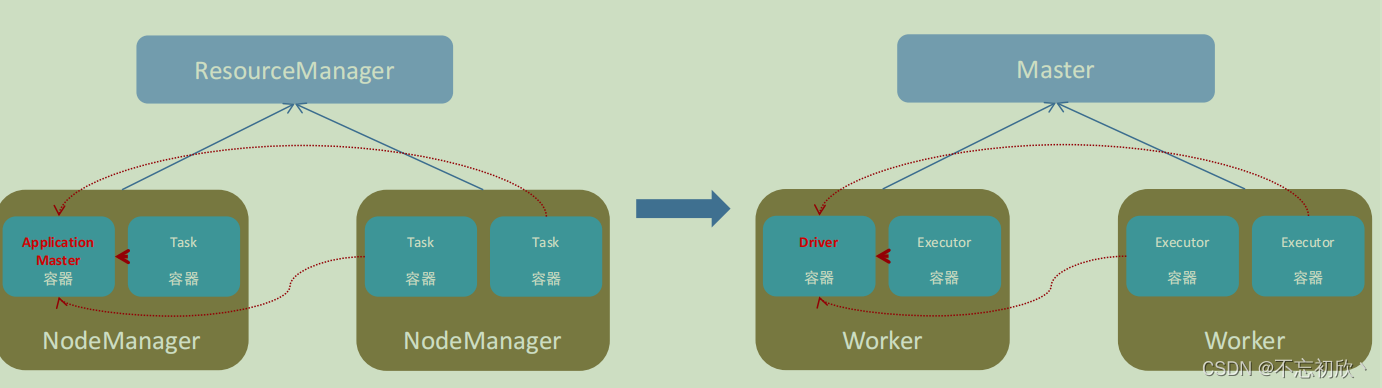
Spark中由4类角色组成整个Spark的运行时环境
- Master角色,管理整个集群的资源 类比于YARN的ResourceManager
- Worker角色,管理单个服务器的资源 类比于YARN的NodeManager
- Driver角色,管理单个Spark任务在运行的时候的工作 类比于YARN的ApplicationMaster
- Executor角色,单个任务运行的时候的一堆工作者,专门干活的,类比于YARN的容器内运行的task
从资源管理层面划分:
- 管理者:Spark是Master角色,YARN是ResourceManager
- 工作者:Spark是Worker角色,YARN是NodeManager
从任务执行层面:
- 任务管理者:Spark是Driver角色,YARN是ApplicationMaster角色
- 任务执行者:Spark是Executor角色,YARN是容器中运行的具体工作进程
正常情况下Executor是干活的角色,但是在Local模式下,Driver既可以干活又要管理
智能推荐
mysql5.7默认生成随机密码,不知道登录时需要强改_mysql 5.7 默认生成一个随机密码-程序员宅基地
文章浏览阅读5.8k次,点赞3次,收藏2次。其实想要重置 5.7 的密码很简单,就一层窗户纸:1、修改 /etc/my.cnf,在 [mysqld] 小节下添加一行:skip-grant-tables=1这一行配置让 mysqld 启动时不对密码进行验证2、重启 mysqld 服务:systemctl restart mysqld3、使用 root 用户登录到 mysql:mysql -u root _mysql 5.7 默认生成一个随机密码
PHP反序列化:-程序员宅基地
文章浏览阅读100次。序列化。
初探计算机视觉的三个源头、兼谈人工智能|正本清源_计算机视觉的三个核心问题-程序员宅基地
文章浏览阅读3.4k次,点赞4次,收藏6次。2016-11-24 视觉求索谈话人:杨志宏 视觉求索公众号编辑朱松纯 加州大学洛杉矶分校UCLA统计学和计算机科学教授 Song-Chun Zhu www.stat.ucla.edu/~sczhu时间: 2016年10月 杨: 朱教授,你在计算机视觉领域耕耘20余年,获得很多奖项, 是很资深的研究人员_计算机视觉的三个核心问题
程序员必学!Gradle源码全解析,看看这篇文章吧!_gradle 6.7.1源码分析-程序员宅基地
文章浏览阅读154次。背景惯例,先简单陈述一下自己的,91年生人,164年三本毕业后在深圳工作,末流小公司,工资13k,无房,无车,无户口。那时候感觉生活也还行,父母有退休金,我基本上不用太操心,女朋友在一起很久了,很体贴,没有怎么要求我。本来生活就这样一帆风顺下去我就满足了,但是去年初,女朋友家里出了一些事情,一点积蓄全给她了,后面疫情来了,家里开始催婚了,我感觉到了压力。目前的工资无法满足生活,虽然这些年来有一点点的提升,但是,房价物价涨的更快,于是我决定跳槽。从去年年底开始瞎投简历,回顾了一下,一共投了33份简历_gradle 6.7.1源码分析
关于Loadrunner并发组函数web_concurrent的注意事项_web_concurrent_start-程序员宅基地
文章浏览阅读5k次。web_concurrent_start函数是并发组开始的标记。组中所有的函数是并发执行的,并发组的结束符为web_concurrent_end 函数。在并发组中,可以包含的函数有:web_url、web_submit_data、web_custom_request、web_create_html_param、web_create_html_param_ex、web_reg_save_param、..._web_concurrent_start
Delphi dbgrideh序号_dbgrideh增加序号和箭头-程序员宅基地
文章浏览阅读267次。数据库里面的数据没有序号的数据,在dbgrideh上新增一列自定义其字段,例如:id。在dbgrideh控件上的‘OnDrawColumnCell’事件下写下代码。在unidatesource的‘OnDataChange’事件下写下。if DataCol = 0 then //设置在第一列。在编码的开头定义i,为integer。_dbgrideh增加序号和箭头
随便推点
Oracle Ora 错误解决方案合集-程序员宅基地
文章浏览阅读1.3k次。注:本文来源于 《Oracle学习笔记 --- Oracle ORA错误解决方案 》 ORA-00001: 违反唯一约束条件 (.)错误说明:当在唯一索引所对应的列上键入重复值时,会触发此异常。ORA-00017: 请求会话以设置跟踪事件ORA-00018: 超出最大会话数ORA-00019: 超出最大会话许可数ORA-00020: 超出最大进程数 ()ORA-00021: 会话附属于其它某些进..._ora01662
阿里巴巴研究院开源的代码库有哪些_alinn 深度学习库-程序员宅基地
文章浏览阅读397次。以上是阿里巴巴研究院开源的另外几个代码库,涵盖了分布式计算、深度学习模型库、图神经网络、日志聚合等多个领域,为开发者提供了涵盖了深度学习、自然语言处理、智慧城市、搜索引擎、物联网等多个领域,为开发者提供了丰富的工具和资源。_alinn 深度学习库
拼图游戏代码html5,翻译的HTML5拼图游戏(附源码)-程序员宅基地
文章浏览阅读1.2k次。demo.jpg (80.15 KB, 下载次数: 41)2013-12-10 11:05 上传HTML5技术之图像处理:一个滑动的拼图游戏HTML5有许多功能特性可以把多媒体整合到网页中。使用canvas元素可以在这个空白的画板上填充线条,载入图片文件,甚至动画效果。在这篇文章中,我将做一个滑动拼图的游戏用来展示HTML5 canvas的图片处理能力。在网页中使用canvas标签用来创建画板复制..._input做一个拖动滑块拼图游戏代码
什么是网络安全工程师?待遇好吗?-程序员宅基地
文章浏览阅读436次。什么是网络安全工程师?待遇好吗?_网络安全工程师
使用花生棒(内网版)远程控制电脑_花生棒 远程唤醒-程序员宅基地
文章浏览阅读4.5k次。首先将花生棒正确连接:网口端和路由器(或者交换机)相连接,电源端最好是使用独立的电源,如果你将电源端的那一头接到电脑主机上面的话,你关了主机,花生棒的电也就断了,所以最好使用独立的电源供电。输入网址www.oray.cn进入花生棒登陆界面:输入你的sn码和初始密码登陆,登陆之后的界面如下:然后点击内网映射,点右上角的位置添加映射,可以看到购买花生棒的时候官方已经送了一个免费域名给我们啦。为被远程控制_花生棒 远程唤醒
unity 动画Animator 状态机 关节动画 蒙皮动画 顶点动画思路整理_顶点动画 蒙皮动画-程序员宅基地
文章浏览阅读344次。动画思路的简单整理 做个归纳关节动画关节动画是组合而成的父子关系 不是一个整体 物体组合的物体之间有间隙蒙皮动画是一个整体 有mesh包围了整个骨骼物体组合的物体之间没有间隙顶点动画改变物体mesh的形状一 获得mesh 顶点数组还有法线数组二 对这些顶点数组的位置进行修改1, legacy:Unity 3.5以前老旧的选项2, generi..._顶点动画 蒙皮动画