DGL官方教程--随机稳态嵌入 (SSE)-程序员宅基地
技术标签: 算法 python 深度学习 图神经网络及其变体 神经网络
Note:
Click here to download the full example code
Stochastic steady-state embedding (SSE)
Author: Gai Yu, Da Zheng, Quan Gan, Jinjing Zhou, Zheng Zhang
在本教程中,您将学习如何通过MXNet使用深度图库(DGL)来实现以下功能:
- 具有随机稳态嵌入 (SSE)的简单稳态算法
- 子图抽样训练
子图采样是一种将学习扩展到巨大图(例如,数十亿个节点和边)的技术。子图采样可以应用于其他算法,例如图卷积网络 和关系图卷积网络。
Steady-state algorithms
许多用于图形分析的算法都是迭代过程,直到达到稳定状态时才结束。示例包括对Markov随机字段的PageRank或均值字段推断。
Flood-fill algorithm
A Flood-fill algorithm(或infection algorithm)也可以看作是一个过程。具体来说,问题在于给定一个图 G = ( ϑ , ε ) G=(\vartheta ,\varepsilon ) G=(ϑ,ε)和一个源节点 s ∈ ϑ s \in \vartheta s∈ϑ,您需要标记可以从中访问的所有节点 s。让 ϑ = { 1 , . . . , n } \vartheta = \{1, ..., n\} ϑ={
1,...,n}然后让 y v y_v yv指示是否一个节点 v v v被标记。填充算法进行如下。
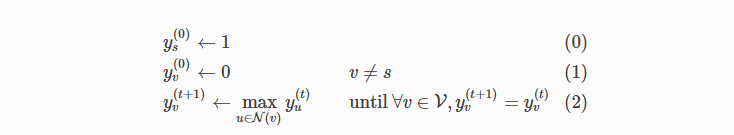
此处 N ( v ) \mathbb{N} (v) N(v) 表示的邻域 v v v, 包含 v v v本身。
填充算法首先标记源节点 s s s,然后重复标记带有一个或多个标记邻居的节点,直到不需要标记任何节点,即达到稳态为止。
Flood-fill algorithm and steady-state operator
更抽象地讲,
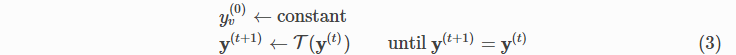
此处 y ( t ) = ( y 1 ( t ) , . . . , y n ( t ) ) y^{(t)} = (y_1^{(t)}, ..., y_n^{(t)}) y(t)=(y1(t),...,yn(t)) 和 [ τ ( y ( t ) ) ] v [\tau (y^{(t)})]_v [τ(y(t))]v= τ ~ ( y υ ( t ) ) : υ ∈ N ( ϑ ) ) \widetilde{\tau }({y_{\upsilon }^{(t))}:\upsilon \in N(\vartheta )}) τ
(yυ(t)):υ∈N(ϑ)) 。对于泛洪算法, τ ~ \widetilde{\tau } τ
=max。条件 ”until y ( t + 1 ) = y ( t ) y^{(t + 1)} = y^{(t)} y(t+1)=y(t)”中 ( 3 ) (3) (3) 暗示 y ∗ y^* y∗是解决问题的方法,当且仅当 y ∗ = τ ( y ∗ ) y^∗=\tau (y^∗) y∗=τ(y∗), 那是$ y^∗$ 在下稳定 τ \tau τ。因此我们称 τ \tau τ在稳态操作。
Implementing a flood-fill algorithm
您可以使用以下代码在DGL中实现Flood-fill algorithm。
import mxnet as mx
import os
import dgl
def T(g):
def message_func(edges):
return {
'm': edges.src['y']}
def reduce_func(nodes):
# First compute the maximum of all neighbors...
m = mx.nd.max(nodes.mailbox['m'], axis=1)
# Then compare the maximum with the node itself.
# One can also add a self-loop to each node to avoid this
# additional max computation.
m = mx.nd.maximum(m, nodes.data['y'])
return {
'y': m.reshape(m.shape[0], 1)}
g.update_all(message_func, reduce_func)
return g.ndata['y']
要运行该算法,请DGLGraph在此处的示例代码中创建一个由两个不相交的链组成的链,每个链有十个节点,然后按照等式中的指定对其进行初始化Eq. (0) 和Eq. (1)。
import networkx as nx
def disjoint_chains(n_chains, length):
path_graph = nx.path_graph(n_chains * length).to_directed()
for i in range(n_chains - 1): # break the path graph into N chains
path_graph.remove_edge((i + 1) * length - 1, (i + 1) * length)
path_graph.remove_edge((i + 1) * length, (i + 1) * length - 1)
for n in path_graph.nodes:
path_graph.add_edge(n, n) # add self connections
return path_graph
N = 2 # the number of chains
L = 500 # the length of a chain
s = 0 # the source node
# The sampler (see the subgraph sampling section) only supports
# readonly graphs.
g = dgl.DGLGraph(disjoint_chains(N, L), readonly=True)
y = mx.nd.zeros([g.number_of_nodes(), 1])
y[s] = 1
g.ndata['y'] = y
现在适用T于g直至收敛。您会看到从到达的节点s逐渐受到感染(标记)。
while True:
prev_y = g.ndata['y']
next_y = T(g)
if all(prev_y == next_y):
break
更新过程如下所示:
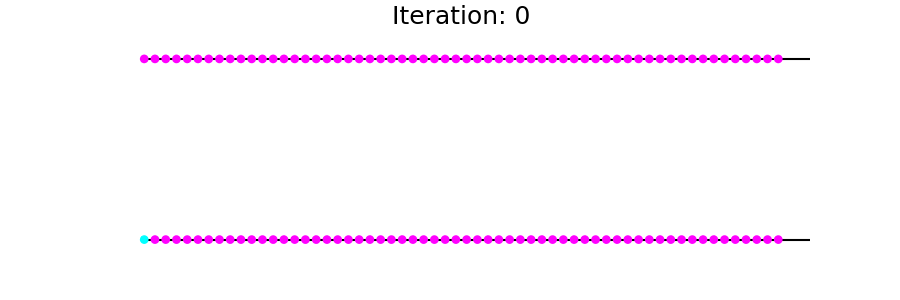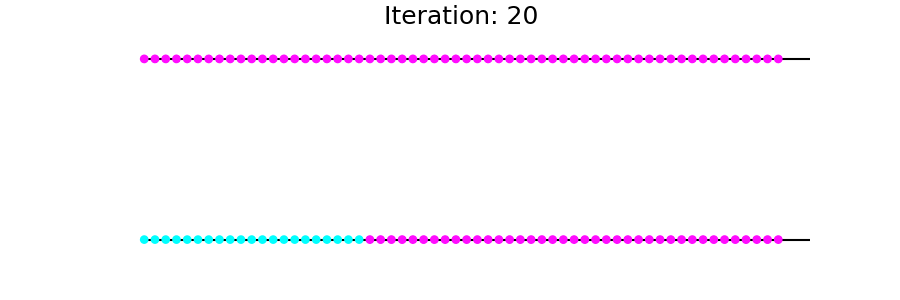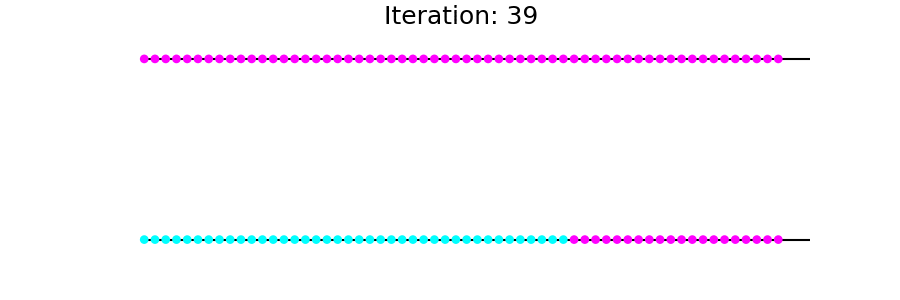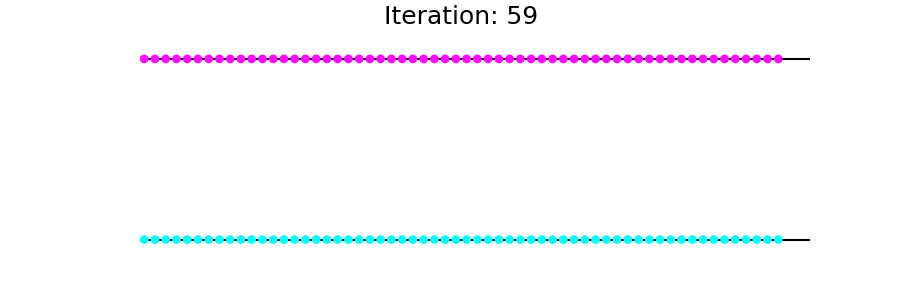
Steady-state embedding
Neural flood-fill algorithm
接下来,您可以设计一个模拟洪水填充算法的神经网络。
而不是使用 τ \tau τ更新节点的状态,使用
τ Θ \tau_\Theta τΘ ,图神经网络(和 τ ^ Θ \hat\tau_\Theta τ^Θ代替 τ ^ \hat\tau τ^)。
节点状态 v v v不再是布尔值
y v y_v yv,但嵌入 h v h_v hv(例如,某种合理尺寸的向量, H H H)。
您还可以关联特征向量 x v x_v xv与 v v v。对于
flood-fill algorithm,只需使用节点ID的一键编码作为其特征向量,以便我们的算法可以区分不同的节点。
只迭代 τ \tau τ次而不是重复直到
满足稳态条件。
迭代后,通过传递节点嵌入来标记节点
h v h_v hv 进入另一个神经网络以产生概率 p v p_v pv 节点是否可达的信息。
数学上,
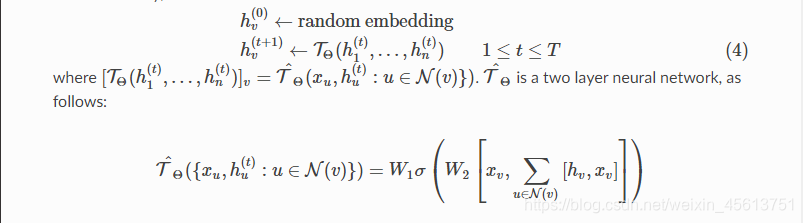
此处 [⋅,⋅] 表示向量的串联,并且 σ σ σ是非线性,例如ReLU。本质上,对于每个节点, τ Θ \tau_Θ τΘ 反复收集其邻居的特征向量和嵌入,对其求和,然后将结果连同节点自身的特征向量一起馈入两层神经网络。
Implementation of neural flood-fill
像简单的算法一样,神经泛洪填充算法可以分为message_func(邻居信息收集)和reduce_func( τ ^ Θ \hat\tau_\Theta τ^Θ)。我们定义 τ ^ Θ \hat\tau_\Theta τ^Θ如gluon.Block本示例代码中所示为可调用对象。
import mxnet.gluon as gluon
class FullGraphSteadyStateOperator(gluon.Block):
def __init__(self, n_hidden, activation, **kwargs):
super(FullGraphSteadyStateOperator, self).__init__(**kwargs)
with self.name_scope():
self.dense1 = gluon.nn.Dense(n_hidden, activation=activation)
self.dense2 = gluon.nn.Dense(n_hidden)
def forward(self, g):
def message_func(edges):
x = edges.src['x']
h = edges.src['h']
return {
'm' : mx.nd.concat(x, h, dim=1)}
def reduce_func(nodes):
m = mx.nd.sum(nodes.mailbox['m'], axis=1)
z = mx.nd.concat(nodes.data['x'], m, dim=1)
return {
'h' : self.dense2(self.dense1(z))}
g.update_all(message_func, reduce_func)
return g.ndata['h']
实际上,等式 ( 4 ) (4) (4)可能会导致数值不稳定。一种解决方案是更新 h v h_v hv 移动平均值如下:
h v ( t + 1 ) ← ( 1 − α ) h v ( t ) + α [ τ Θ ( h 0 ( t ) , . . . . , h n ( t ) ) ] v h_v^(t+1)\leftarrow (1-\alpha)h_v^(t)+\alpha[\tau_\Theta(h_0^(t),....,h_n^(t))]_v hv(t+1)←(1−α)hv(t)+α[τΘ(h0(t),....,hn(t))]v
其中 0 < α < 1 0<\alpha <1 0<α<1
将这些放在一起,您将拥有:
def update_embeddings(g, steady_state_operator):
prev_h = g.ndata['h']
next_h = steady_state_operator(g)
g.ndata['h'] = (1 - alpha) * prev_h + alpha * next_h
最后一步涉及实现预测器。
class Predictor(gluon.Block):
def __init__(self, n_hidden, activation, **kwargs):
super(Predictor, self).__init__(**kwargs)
with self.name_scope():
self.dense1 = gluon.nn.Dense(n_hidden, activation=activation)
self.dense2 = gluon.nn.Dense(2) ## binary classifier
def forward(self, h):
return self.dense2(self.dense1(h))
预测变量的决策规则只是二进制分类的决策规则。
y ^ v = argmax i ∈ { 0 , 1 } [ g Φ ( h v ( T ) ) ] i (5) \hat{y}_v = \text{argmax}_{i \in \{0, 1\}} \left[g_\Phi (h_v^{(T)})\right]_i \tag{5} y^v=argmaxi∈{
0,1}[gΦ(hv(T))]i(5)
其中预测变量由表示 g Φ g_\Phi gΦ 和 y ^ v \hat{y}_v y^v 指示节点是否 v v v 是否标记。
使用DGL可以进一步加速我们的实现,该DGL 将计算映射到后端框架(例如MXNet / Gluon,PyTorch)中更高效的稀疏运算符。请参阅图卷积网络教程以获取更多详细信息。built-in functions
Efficient semi-supervised learning on graph
在此设置下,您可以观察一个固定图的整个结构以及每个节点的特征向量。但是,您可能只能访问某些(很少)节点的标签。在此设置中也训练神经泛洪填充算法。
首先初始化特征向量’x’和节点嵌入’h’ 。
import numpy as np
import numpy.random as npr
n = g.number_of_nodes()
n_hidden = 16
g.ndata['x'] = mx.nd.eye(n, n)
g.ndata['y'] = mx.nd.concat(*[i * mx.nd.ones([L, 1], dtype='float32')
for i in range(N)], dim=0)
g.ndata['h'] = mx.nd.zeros([n, n_hidden])
r_train = 0.2 # the ratio of test nodes
n_train = int(r_train * n)
nodes_train = npr.choice(range(n), n_train, replace=True)
test_bitmap = np.ones(shape=(n))
test_bitmap[nodes_train] = 0
nodes_test = np.where(test_bitmap)[0]
在等式中展开迭代Eq. (4),对于更新的节点嵌入,我们具有以下表达式:
h v ( T ) = τ Θ T ( h 1 ( 0 ) , . . . , h n ( 0 ) ) v ∈ ν (6) h_v^{(T)} = \tau_\Theta^T (h_1^{(0)}, ..., h_n^{(0)}) \qquad v \in \nu \tag{6} hv(T)=τΘT(h1(0),...,hn(0))v∈ν(6)
此处 τ Θ T \tau_\Theta^T τΘT意味着申请 τ Θ \tau_\Theta τΘ对于 T T T次。这些更新的节点嵌入被馈送到 g Φ g_\Phi gΦ如式 (5)。这些步骤是完全可区分的,因此可以以端到端的方式训练神经泛洪算法。用来表示二元互熵损失 l l l,您具有以下形式的损失函数:
L ( Θ , Φ ) = 1 ∣ ν y ∣ ∑ v ∈ ν y l ( g Φ ( [ ν Θ T ( h 1 ( 0 ) , . . . , h n ( 0 ) ) ] v ) , y v ) (7) L(\Theta, \Phi) = \frac1{\left|\nu_y\right|} \sum_{v \in \nu_y} l \left(g_\Phi \left(\left[\nu_\Theta^T (h_1^{(0)}, ..., h_n^{(0)})\right]_v \right), y_v\right) \tag{7} L(Θ,Φ)=∣νy∣1v∈νy∑l(gΦ([νΘT(h1(0),...,hn(0))]v),yv)(7)
经过计算 L ( Θ , Φ ) (Θ,Φ) (Θ,Φ),您可以更新 Θ Θ Θ 和 Φ Φ Φ 使用渐变 ▽ Θ L ( Θ , Φ ) \bigtriangledown _\Theta L (\Theta, \Phi) ▽ΘL(Θ,Φ)和 ▽ Φ L ( Θ , Φ ) \bigtriangledown _Φ L (\Theta, \Phi) ▽ΦL(Θ,Φ)。情商的一个问题。 (7) 那是计算吗 ▽ Θ L ( Θ , Φ ) \bigtriangledown _\Theta L (\Theta, \Phi) ▽ΘL(Θ,Φ)和 ▽ Φ L ( Θ , Φ ) \bigtriangledown _Φ L (\Theta, \Phi) ▽ΦL(Θ,Φ) 需要反向传播 T T T 时光流逝 τ Θ \tau_Θ τΘ,这在实践中可能很慢。因此,采用以下稳态损失函数,该函数仅在反向传播中合并最后一个节点嵌入更新:
L SteadyState ( Θ , Φ ) = 1 ∣ ν y ∣ ∑ v ∈ ν y l ( g Φ ( [ υ Θ ( h 1 ( T − 1 ) , . . . , h n ( T − 1 ) ) ] v , y v ) ) (8) L_\text{SteadyState} (\Theta, \Phi) = \frac1{\left|\nu_y\right|} \sum_{v \in \nu_y} l \left(g_\Phi \left(\left[\upsilon _\Theta (h_1^{(T - 1)}, ..., h_n^{(T - 1)})\right]_v, y_v\right)\right) \tag{8} LSteadyState(Θ,Φ)=∣νy∣1v∈νy∑l(gΦ([υΘ(h1(T−1),...,hn(T−1))]v,yv))(8)
以下实现了培训的第一步 L SteadyState L_\text{SteadyState} LSteadyState。请注意, g g g以下是 G y G_y Gy 代替 G G G。
def fullgraph_update_parameters(g, label_nodes, steady_state_operator, predictor, trainer):
n = g.number_of_nodes()
with mx.autograd.record():
steady_state_operator(g)
z = predictor(g.ndata['h'][label_nodes])
y = g.ndata['y'].reshape(n)[label_nodes] # label
loss = mx.nd.softmax_cross_entropy(z, y)
loss.backward()
trainer.step(n) # divide gradients by the number of labelled nodes
return loss.asnumpy()[0]
现在您可以实施培训过程了,该过程分为两个阶段。
- 第一阶段使用多次更新节点嵌入 T Θ T_Θ TΘ 达到大致稳定的状态
- 第二阶段训练 T Θ T_Θ TΘ 和 g Φ g_Φ gΦ 使用这种稳定状态。
您更新以下节点的嵌入 G G G 代替 G y G_y Gy只要。原因在于半监督学习环境。做推断 G G G,您需要在上嵌入节点 G G G 而不是 G y G_y Gy 只要。
def train(g, label_nodes, steady_state_operator, predictor, trainer):
# first phase
for i in range(n_embedding_updates):
update_embeddings(g, steady_state_operator)
# second phase
for i in range(n_parameter_updates):
loss = fullgraph_update_parameters(g, label_nodes, steady_state_operator,
predictor, trainer)
return loss
Scaling up with stochastic subgraph training
每次更新的计算时间与图形中的边数成线性关系。如果我们有一个具有数十亿个节点和边的巨型图,则更新功能将效率低下。
可能的改进从对大型数据集的小批量训练中得出一个类比。代替计算整个图的梯度,仅考虑从标记节点随机采样的一些子图。在数学上,您具有以下损失函数:
L StochasticSteadyState ( Θ , Φ ) = 1 ∣ ν y ( k ) ∣ ∑ v ∈ ν y ( k ) l ( g Φ ( [ υ Θ ( h 1 , . . . , h n ) ] v ) , y v ) L_\text{StochasticSteadyState} (\Theta, \Phi) = \frac1{\left|\nu_y^{(k)}\right|} \sum_{v \in \nu_y^{(k)}} l \left(g_\Phi \left(\left[\upsilon _\Theta (h_1, ..., h_n)\right]_v\right), y_v\right) LStochasticSteadyState(Θ,Φ)=∣∣∣νy(k)∣∣∣1v∈νy(k)∑l(gΦ([υΘ(h1,...,hn)]v),yv)
此处 ν y ( k ) \nu_y^{(k)} νy(k) 是为迭代采样的子集 k k k。
在此训练过程中,您还只更新了采样子图上的节点嵌入,如果您知道随机的定点迭代,这也许就不足为奇了。
Neighbor sampling
您可以将Neighbor sampling用作子图采样策略。邻居采样以广度优先搜索遍历种子节点中的小邻居。对于每个新采样的节点,将对一小部分相邻节点进行采样,并将其与连接边一起添加到子图中,除非该节点达到最大值k 种子节点的跃点。
下图显示了一次具有两个种子节点,最多两个跃点和最多三个相邻节点的Neighbor sampling。
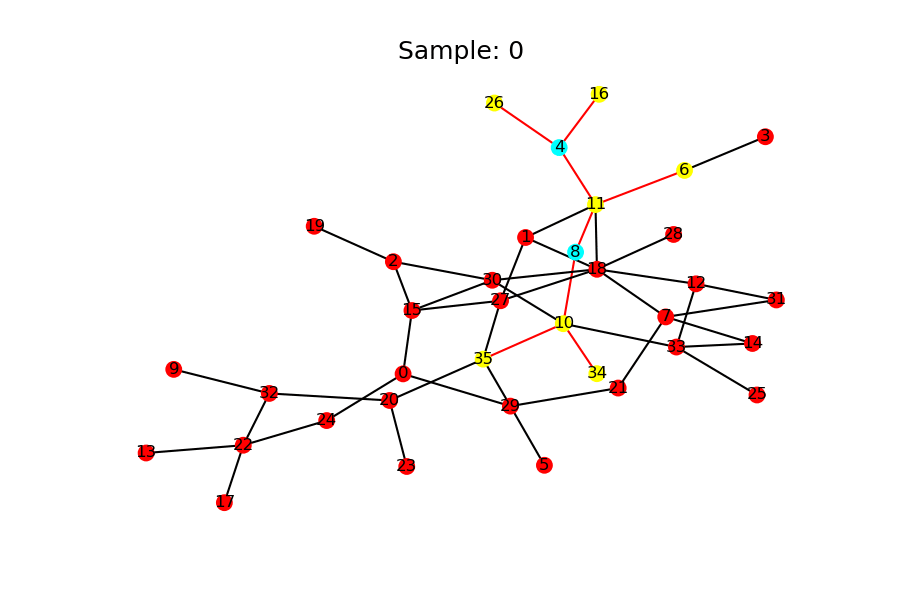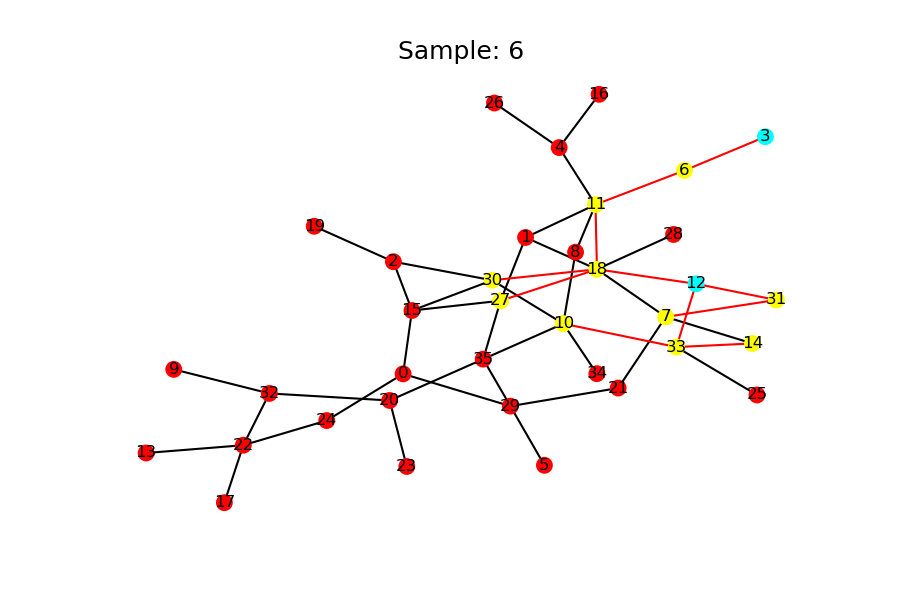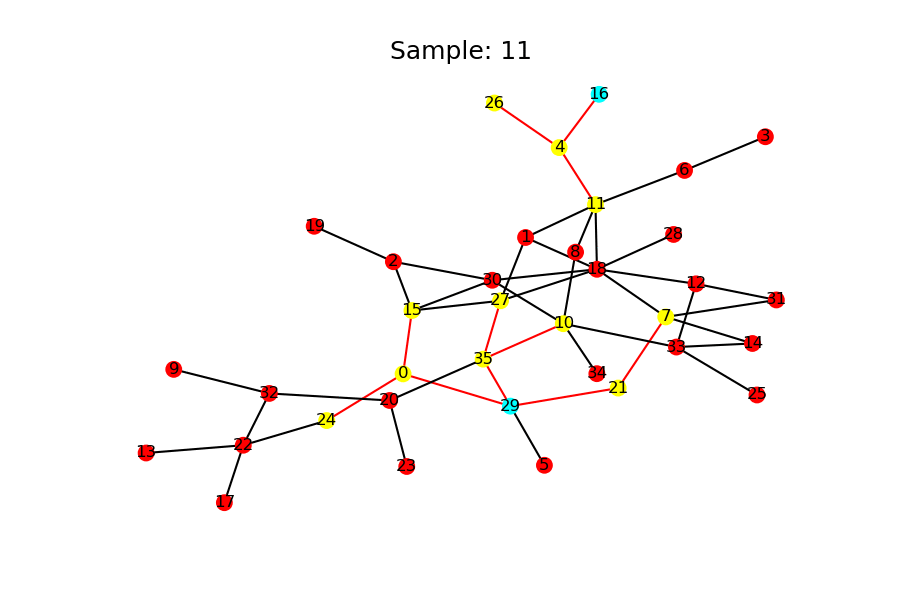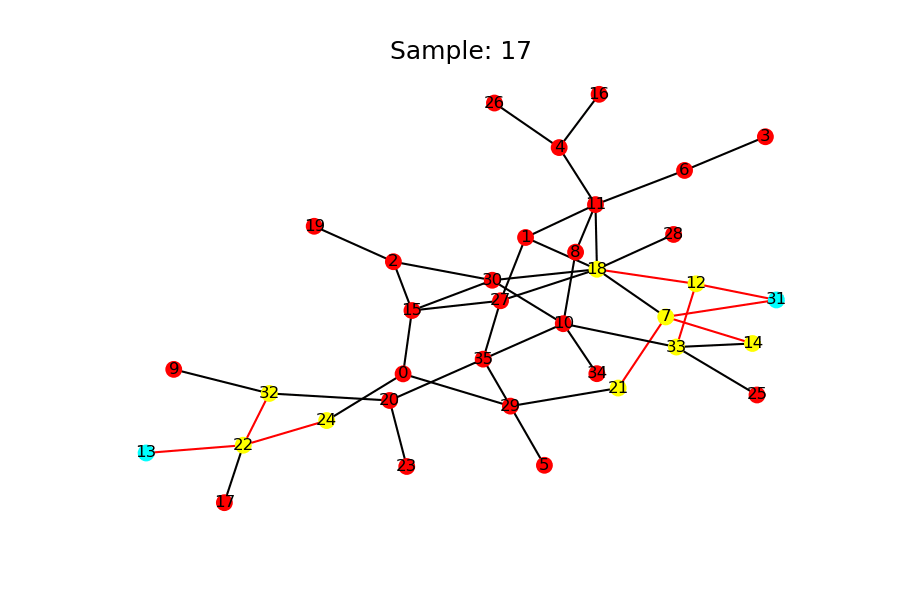
DGL本机支持非常有效的子图采样。这可以帮助用户将算法缩放到大图。当前,DGL提供了 NeighborSampler() API,该API返回一个子图迭代器,该子图迭代器通过邻居采样一次对多个子图进行采样。
以下代码演示了如何使用NeighborSampler来对子图进行采样,并在每次迭代中存储子图的种子节点:
nx_G = nx.erdos_renyi_graph(36, 0.06)
G = dgl.DGLGraph(nx_G.to_directed(), readonly=True)
sampler = dgl.contrib.sampling.NeighborSampler(
G, 2, 3, num_hops=2, shuffle=True)
seeds = []
for subg in sampler:
seeds.append(subg.layer_parent_nid(-1))
Sample training with DGL
该代码以小批量说明了训练过程。
class SubgraphSteadyStateOperator(gluon.Block):
def __init__(self, n_hidden, activation, **kwargs):
super(SubgraphSteadyStateOperator, self).__init__(**kwargs)
with self.name_scope():
self.dense1 = gluon.nn.Dense(n_hidden, activation=activation)
self.dense2 = gluon.nn.Dense(n_hidden)
def forward(self, subg):
def message_func(edges):
x = edges.src['x']
h = edges.src['h']
return {
'm' : mx.nd.concat(x, h, dim=1)}
def reduce_func(nodes):
m = mx.nd.sum(nodes.mailbox['m'], axis=1)
z = mx.nd.concat(nodes.data['x'], m, dim=1)
return {
'h' : self.dense2(self.dense1(z))}
subg.block_compute(0, message_func, reduce_func)
return subg.layers[-1].data['h']
def update_parameters_subgraph(subg, steady_state_operator, predictor, trainer):
n = subg.layer_size(-1)
with mx.autograd.record():
steady_state_operator(subg)
z = predictor(subg.layers[-1].data['h'])
y = subg.layers[-1].data['y'].reshape(n) # label
loss = mx.nd.softmax_cross_entropy(z, y)
loss.backward()
trainer.step(n) # divide gradients by the number of labelled nodes
return loss.asnumpy()[0]
def update_embeddings_subgraph(g, steady_state_operator):
# Note that we are only updating the embeddings of seed nodes here.
# The reason is that only the seed nodes have ample information
# from neighbors, especially if the subgraph is small (e.g. 1-hops)
prev_h = g.layers[-1].data['h']
next_h = steady_state_operator(g)
g.layers[-1].data['h'] = (1 - alpha) * prev_h + alpha * next_h
def train_on_subgraphs(g, label_nodes, batch_size,
steady_state_operator, predictor, trainer):
# To train SSE, we create two subgraph samplers with the
# `NeighborSampler` API for each phase.
# The first phase samples from all vertices in the graph.
sampler = dgl.contrib.sampling.NeighborSampler(
g, batch_size, g.number_of_nodes(), num_hops=1)
sampler_iter = iter(sampler)
# The second phase only samples from labeled vertices.
sampler_train = dgl.contrib.sampling.NeighborSampler(
g, batch_size, g.number_of_nodes(), seed_nodes=label_nodes, num_hops=1)
sampler_train_iter = iter(sampler_train)
for i in range(n_embedding_updates):
subg = next(sampler_iter)
# Currently, subgraphing does not copy or share features
# automatically. Therefore, we need to copy the node
# embeddings of the subgraph from the parent graph with
# `copy_from_parent()` before computing...
subg.copy_from_parent()
update_embeddings_subgraph(subg, steady_state_operator)
# ... and copy them back to the parent graph.
g.ndata['h'][subg.layer_parent_nid(-1)] = subg.layers[-1].data['h']
for i in range(n_parameter_updates):
try:
subg = next(sampler_train_iter)
except:
break
# Again we need to copy features from parent graph
subg.copy_from_parent()
loss = update_parameters_subgraph(subg, steady_state_operator, predictor, trainer)
# We don't need to copy the features back to parent graph.
return loss
您还可以定义报告预测准确性的辅助函数。
def test(g, test_nodes, predictor):
z = predictor(g.ndata['h'][test_nodes])
y_bar = mx.nd.argmax(z, axis=1)
y = g.ndata['y'].reshape(n)[test_nodes]
accuracy = mx.nd.sum(y_bar == y) / len(test_nodes)
return accuracy.asnumpy()[0], z
一些常规的训练准备。
lr = 1e-3
activation = 'relu'
subgraph_steady_state_operator = SubgraphSteadyStateOperator(n_hidden, activation)
predictor = Predictor(n_hidden, activation)
subgraph_steady_state_operator.initialize()
predictor.initialize()
params = subgraph_steady_state_operator.collect_params()
params.update(predictor.collect_params())
trainer = gluon.Trainer(params, 'adam', {
'learning_rate' : lr})
现在训练它。和以前一样,从 s s s 逐渐被感染,除了在后台是神经网络。
n_epochs = 35
n_embedding_updates = 8
n_parameter_updates = 5
alpha = 0.1
batch_size = 64
y_bars = []
for i in range(n_epochs):
loss = train_on_subgraphs(g, nodes_train, batch_size, subgraph_steady_state_operator,
predictor, trainer)
accuracy_train, _ = test(g, nodes_train, predictor)
accuracy_test, z = test(g, nodes_test, predictor)
print("Iter {:05d} | Train acc {:.4} | Test acc {:.4f}".format(i, accuracy_train, accuracy_test))
y_bar = mx.nd.argmax(z, axis=1)
y_bars.append(y_bar)
out:
Iter 00000 | Train acc 0.56 | Test acc 0.4895
Iter 00001 | Train acc 0.56 | Test acc 0.4895
Iter 00002 | Train acc 0.56 | Test acc 0.4895
Iter 00003 | Train acc 0.56 | Test acc 0.4895
Iter 00004 | Train acc 0.56 | Test acc 0.4895
Iter 00005 | Train acc 0.56 | Test acc 0.4895
Iter 00006 | Train acc 0.56 | Test acc 0.4895
Iter 00007 | Train acc 0.56 | Test acc 0.4895
Iter 00008 | Train acc 0.56 | Test acc 0.4895
Iter 00009 | Train acc 0.56 | Test acc 0.4895
Iter 00010 | Train acc 0.56 | Test acc 0.4895
Iter 00011 | Train acc 0.56 | Test acc 0.4895
Iter 00012 | Train acc 0.56 | Test acc 0.4895
Iter 00013 | Train acc 0.56 | Test acc 0.4895
Iter 00014 | Train acc 0.56 | Test acc 0.4895
Iter 00015 | Train acc 0.56 | Test acc 0.4895
Iter 00016 | Train acc 0.56 | Test acc 0.4895
Iter 00017 | Train acc 0.56 | Test acc 0.4895
Iter 00018 | Train acc 0.56 | Test acc 0.4895
Iter 00019 | Train acc 0.56 | Test acc 0.4895
Iter 00020 | Train acc 0.56 | Test acc 0.4895
Iter 00021 | Train acc 0.99 | Test acc 0.9877
Iter 00022 | Train acc 0.99 | Test acc 0.9877
Iter 00023 | Train acc 0.99 | Test acc 0.9877
Iter 00024 | Train acc 0.99 | Test acc 0.9877
Iter 00025 | Train acc 0.99 | Test acc 0.9877
Iter 00026 | Train acc 0.99 | Test acc 0.9877
Iter 00027 | Train acc 0.99 | Test acc 0.9877
Iter 00028 | Train acc 0.99 | Test acc 0.9877
Iter 00029 | Train acc 0.99 | Test acc 0.9877
Iter 00030 | Train acc 0.99 | Test acc 0.9877
Iter 00031 | Train acc 0.99 | Test acc 0.9877
Iter 00032 | Train acc 0.99 | Test acc 0.9877
Iter 00033 | Train acc 0.99 | Test acc 0.9877
Iter 00034 | Train acc 0.99 | Test acc 0.9877
图片链接:https://s3.us-east-2.amazonaws.com/dgl.ai/tutorial/img/sse.gif
在本教程中,您使用了一个非常小的示例图来演示子图训练,以便于进行可视化。子图训练实际上可以帮助您缩放到巨大的图。例如,在单个P3.8x大型实例中,将SSE缩放到具有5000万个节点和1.5亿条边的图形,一个历元仅需约160秒。
有关完整示例,请参阅Github 上基于多GPU的Benchmark SSE。
脚本的总运行时间:(0分钟8.770秒)
脚本下载:8_sse_mx.py
脚本下载:8_sse_mx.ipynb
智能推荐
EBS R12基本概念与应用基础-程序员宅基地
文章浏览阅读1.8k次。摘自: [ORACLE EBS 入门及供应链核心系统详解教程] (书籍)EBS基础功能架构(13个核心模块,业财一体化)业务运营管理,价值增值财务会计管理,价值实现应用架构Finance财务,资金流Accounting财务管理Bisuness业务,实物流核心业务,与财务高度集成;PUR、INV、制造、订单履行等间接业务,or专业业务,为核心业务提供支持;HR..._ebs r12
Java中Date和Timestamp的区别_java date timestamp区别-程序员宅基地
文章浏览阅读838次。转载:https://blog.csdn.net/ccecwg/article/details/39546307_java date timestamp区别
如何用原生js封装一个类似jq的选择器_原声js实现jq元素选择器-程序员宅基地
文章浏览阅读1.4k次。1、我们先了解一下原生js中的选择器ID选择器(在整个文档中获取id为xxx的元素)document.getElementId([ID]);类名选择器(在整个文档中或者在指定上下文中获取类名为xxx的元素)document.getElementsByClassName(' ');[context].getElementsByClassName(' ');标签名选择器(在整个文档中或者..._原声js实现jq元素选择器
Hive中partition by和distribute by区别_partition by distribute by-程序员宅基地
文章浏览阅读1.2k次,点赞3次,收藏4次。通常查询时会对整个数据库查询,而这带来了大量的开销,因此引入了partition的概念,在建表的时候通过设置partition的字段, 会根据该字段对数据分区存放,更具体的说是存放在不同的文件夹,这样通过指定设置Partition的字段条件查询时可以减少大量的开销。1)partition by [key..] order by [key..]只能在窗口函数中使用,而distribute by [key...] sort by [key...]在窗口函数和select中都可以使用。_partition by distribute by
游标(cursor )是什么?_c# cursor-程序员宅基地
文章浏览阅读7.3k次。Private SQL Area A private SQL area holds information about a parsed SQLstatement and other session-specific information for processing. When a serverprocess executes SQL or PL/SQL code, the process_c# cursor
listview使用的一些心得_listview的使用——购物商城实验心得-程序员宅基地
文章浏览阅读616次。近日在用ListView中的一些注意点,和公用代码,整理如下1.ListView.Items.Clear而不是ListView.Clear一般如果ListView是动态填充的,我们在填充之前都会先进行清理。但需要注意一下,我们是清理Items,如果去直接Clear整个ListView,就连原先定义好的列都没有了2.给ListView绑定数据ListView并不能直接_listview的使用——购物商城实验心得
随便推点
java 注解处理器的作用_深入理解Java:注解(Annotation)--注解处理器-程序员宅基地
文章浏览阅读110次。如果没有用来读取注解的方法和工作,那么注解也就不会比注释更有用处了。使用注解的过程中,很重要的一部分就是创建于使用注解处理器。Java SE5扩展了反射机制的API,以帮助程序员快速的构造自定义注解处理器。注解处理器类库(java.lang.reflect.AnnotatedElement):Java使用Annotation接口来代表程序元素前面的注解,该接口是所有Annotation类型的父接口..._java注解处理器作用
全国职业技能大赛高职组(最新职业院校技能大赛_大数据应用开发2023国赛样题解析-模块C:实时数据处理-任务二:实时指标计算)_大数据 国赛 样题-程序员宅基地
文章浏览阅读1.8k次,点赞27次,收藏28次。全国职业技能大赛高职组(最新职业院校技能大赛_大数据应用开发样题解析-模块B:数据采集-任务一:离线数据采集-程序员宅基地。_大数据 国赛 样题
ssm+mysql+微信小程序疫情防控小程序-计算机毕业设计源码73691_ssm+微信小程序-程序员宅基地
文章浏览阅读926次。本系统分为管理员和注册用户两个角色,主要有疫情新闻、疫情案例介绍、健康信息申报、行程信息申报、就医流程介绍、举报、在线留言、用户管理、信息统计等模块。用户需要先注册成为会员,成功登录后,可以查看网站发布的疫情新闻,可以查看疫情相关病例介绍,有助于疫情防范,还可以查看网站发布的重大疫情案例,了解疫情的发展状况,出行时候好做好防护,同时通过网站可以上报健康信息,以及上报行程信息,方便社区了解自己的出行情况;网站还发布了疫情状态下的就医流程,方便大家就医时候做好准备;同时网站还提供了举报功能,如果发现外来人员或_ssm+微信小程序
Linux 操作系统 022-串口/U盘/共享文件夹-程序员宅基地
文章浏览阅读296次,点赞3次,收藏9次。本节关键字:Linux、centos、串口、U盘、共享文件夹本节相关指令:echo、cat、mkdir、mount
解密C++新特性:内联函数、auto和基于范围的for循环-程序员宅基地
文章浏览阅读1.3k次,点赞45次,收藏29次。本篇主题为: 解密C++新特性:内联函数、auto关键字和基于范围的for循环。
上岸整理:2023前端面试题-vue,小程序,js,css_今年的前端面试难不难-程序员宅基地
文章浏览阅读774次,点赞4次,收藏11次。1、浏览器常见的报错信息与含义2、304与204的区别,http缓存,强缓存,协商缓存3、浏览器从输入地址到渲染,经历了什么状态?4、vue的界面渲染,经过哪些过程(生命周期)5、三次握手,四次挥手6、重排与重绘7、用css实现一个三角形8、常见的flex布局,有哪些功能9、用css实现一个水平垂直居中10、null与undefined的区别11、虚拟dom12、深拷贝与浅拷贝13、es6新增的功能15、async await 与promise。_今年的前端面试难不难