Python爬虫之入门保姆级教程,学不会我去你家刷厕所_python爬虫教程-程序员宅基地
技术标签: 爬虫 # 爬虫笔记 python Python专区
- 注重版权,转载请注明原作者和原文链接
- 作者:Bald programmer
今天这个教程采用最简单的爬虫方法,适合小白新手入门,代码不复杂
文章目录
爬虫的介绍以及原理等等七七八八的东西我就不多bb了,咋们直接上教程
本案例我就以 彼岸图网 这个网站做教程,原网址下方链接
首先打开咋们的网站
可以看到有很多好看的图片,一页总共21张图片

我们右键选择检查或者直接按F12来到控制台
点击左上角的箭头或者快捷键ctrl+shift+c,然后随便点在一张图片上面

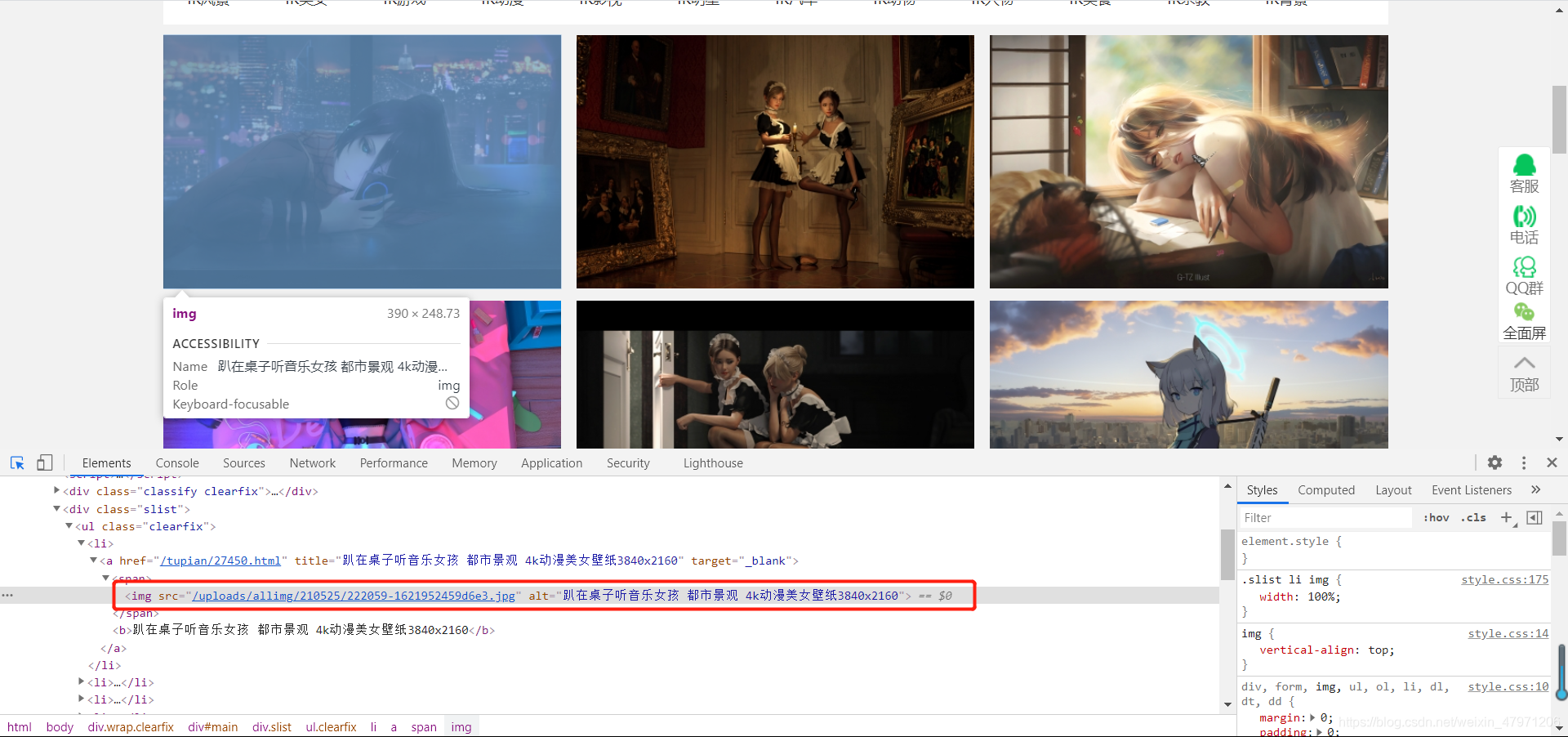
这时候我们就能看到这张图片的详细信息,src后面的链接就是图片的链接,将鼠标放到链接上就能看到图片,这就是我们这次要爬的
一、导入相关库(requests库)
import requests
requests翻译过来就是请求的意思,用来向某一网站发送请求
二、相关的参数(url,headers)
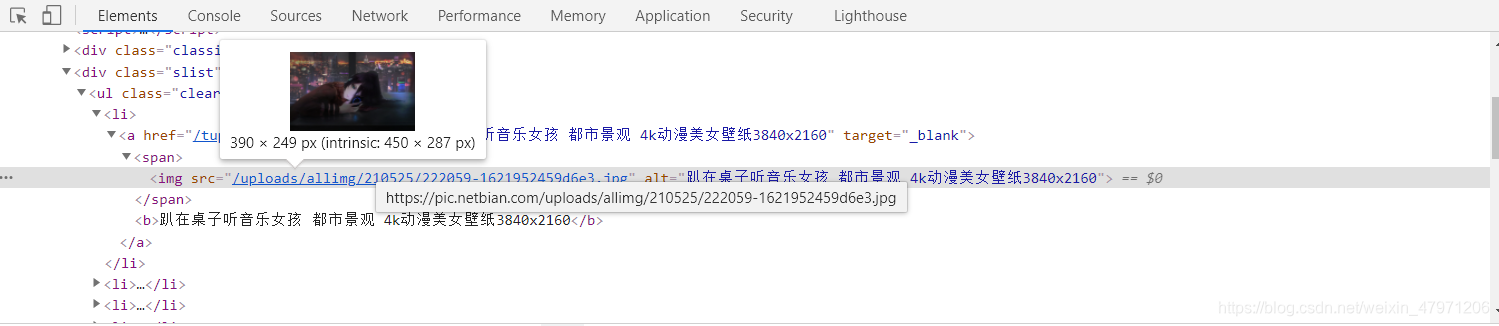
我们回到刚刚的控制台,点击上方的Network,按下ctrl+r刷新,随便点开一张图片

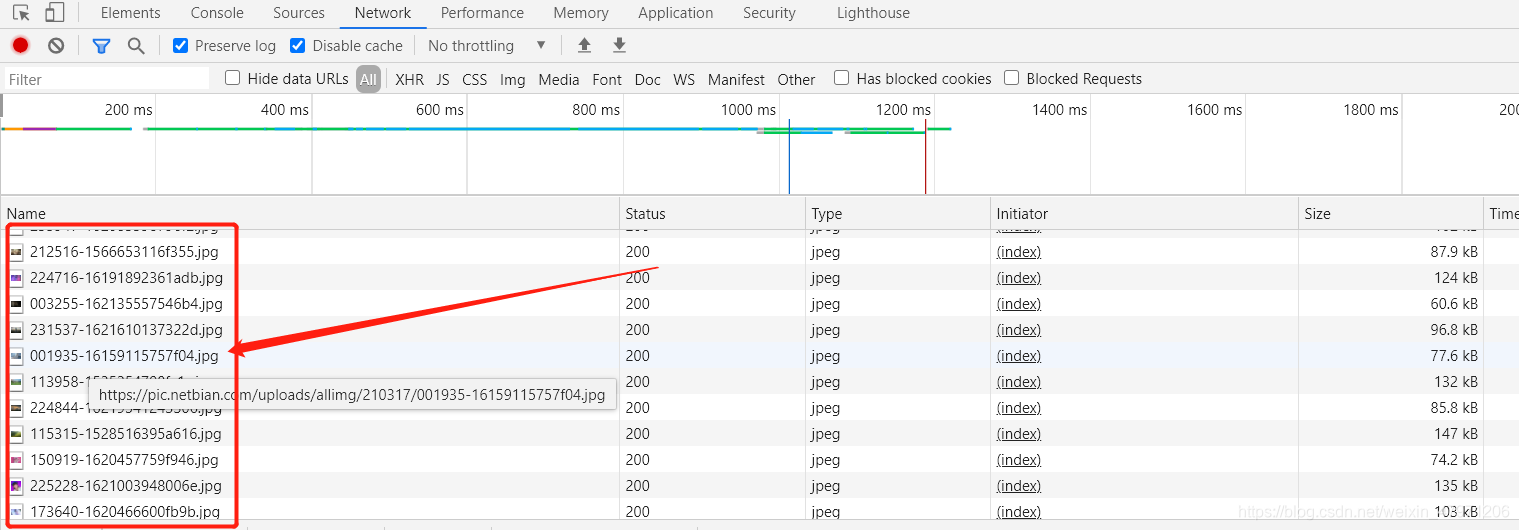
这里我们只需要到两个简单的参数,本次案例只是做一个简单的爬虫教程,其他参数暂时不考虑
| 参数 | 作用 |
|---|---|
| Request URL | 发送请求的网站地址,也就是图片所在的网址 |
| user-agent | 用来模拟浏览器对网站进行访问,避免被网站监测出非法访问 |


参数代码的准备
url = "https://pic.netbian.com/uploads/allimg/210317/001935-16159115757f04.jpg"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
三、向网站发出请求
response = requests.get(url=url,headers=headers)
print(response.text) # 打印请求成功的网页源码,和在网页右键查看源代码的内容一样的
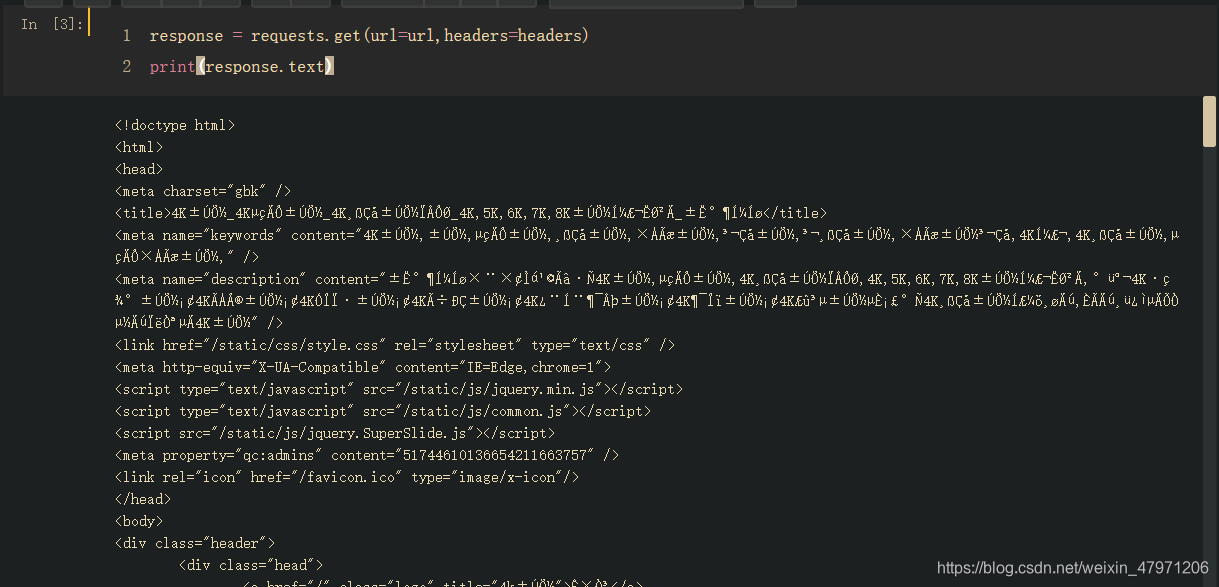
这时候我们会发现乱码?!!!!这其实也是很多初学者头疼的事情,乱码解决不难
# 通过发送请求成功response,通过(apparent_encoding)获取该网页的编码格式,并对response解码
response.encoding = response.apparent_encoding
print(response.text)
看着这些密密麻麻的一大片是不是感觉脑子要炸了,其实我们只需要找到我们所需要的就可以了
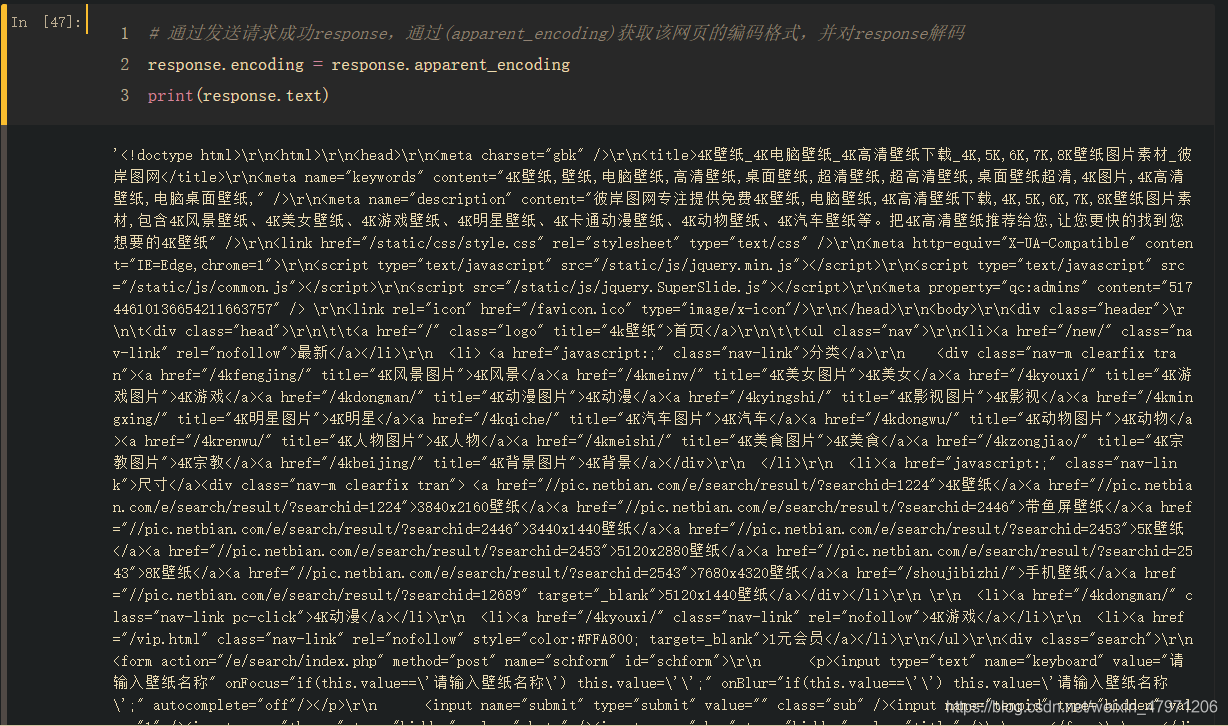
四、匹配(re库,正则表达式)
什么是正则表达式?简单点说就是由用户制定一个规则,然后代码根据我们指定的所规则去指定内容里匹配出正确的内容
我们在前面的时候有看到图片信息是什么样子的,根据信息我们可以快速找到我们要的
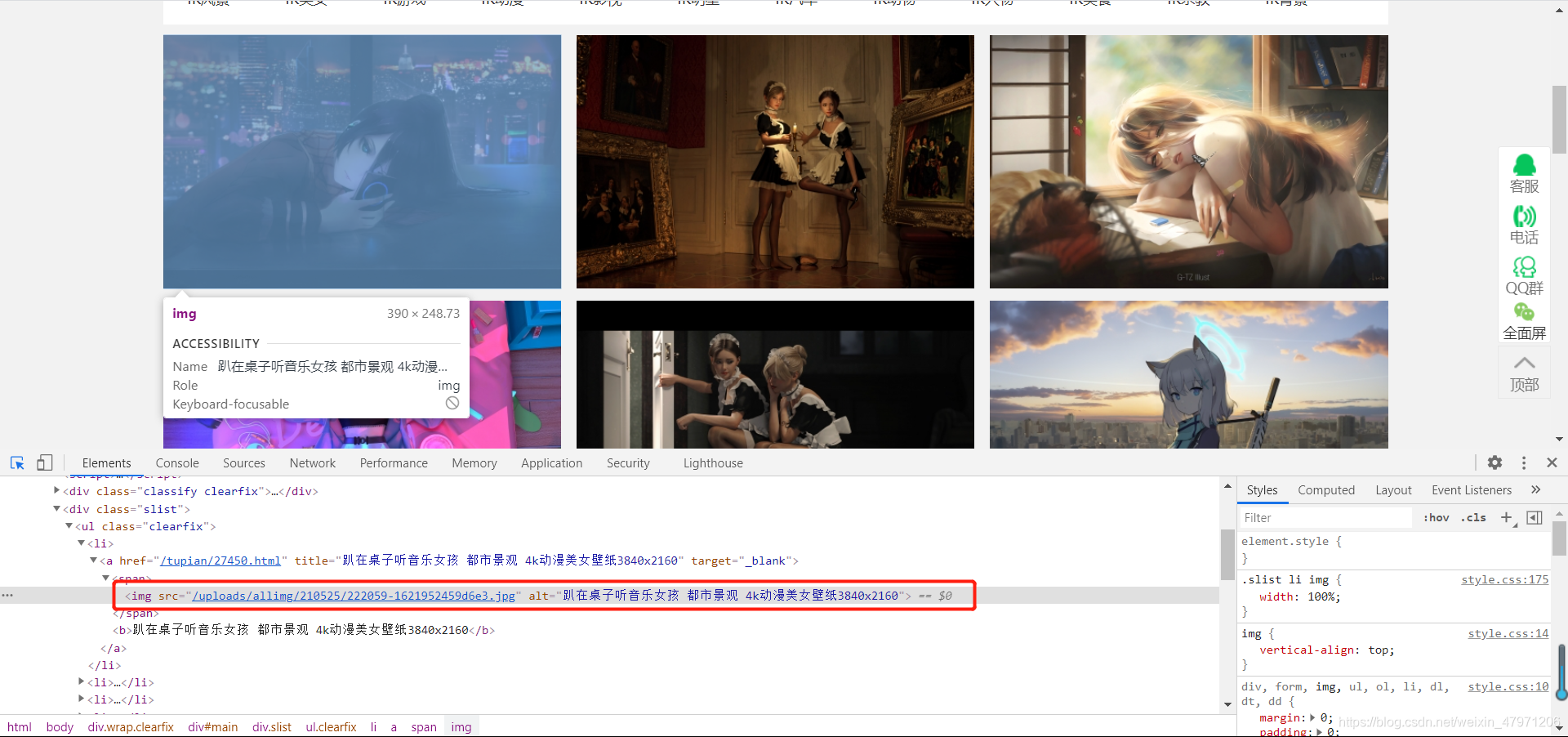

接下来就是通过正则表达式把一个个图片的链接和名字给匹配出来,存放到一个列表中
import re
"""
. 表示除空格外任意字符(除\n外)
* 表示匹配字符零次或多次
? 表示匹配字符零次或一次
.*? 非贪婪匹配
"""
# src后面存放的是链接,alt后面是图片的名字
# 直接(.*?)也是可以可以直接获取到链接,但是会匹配到其他不是我们想要的图片
# 我们可以在前面图片信息看到链接都是/u····开头的,所以我们就设定限定条件(/u.*?)这样就能匹配到我们想要的
parr = re.compile('src="(/u.*?)".alt="(.*?)"')
image = re.findall(parr,response.text)
for content in image:
print(content)
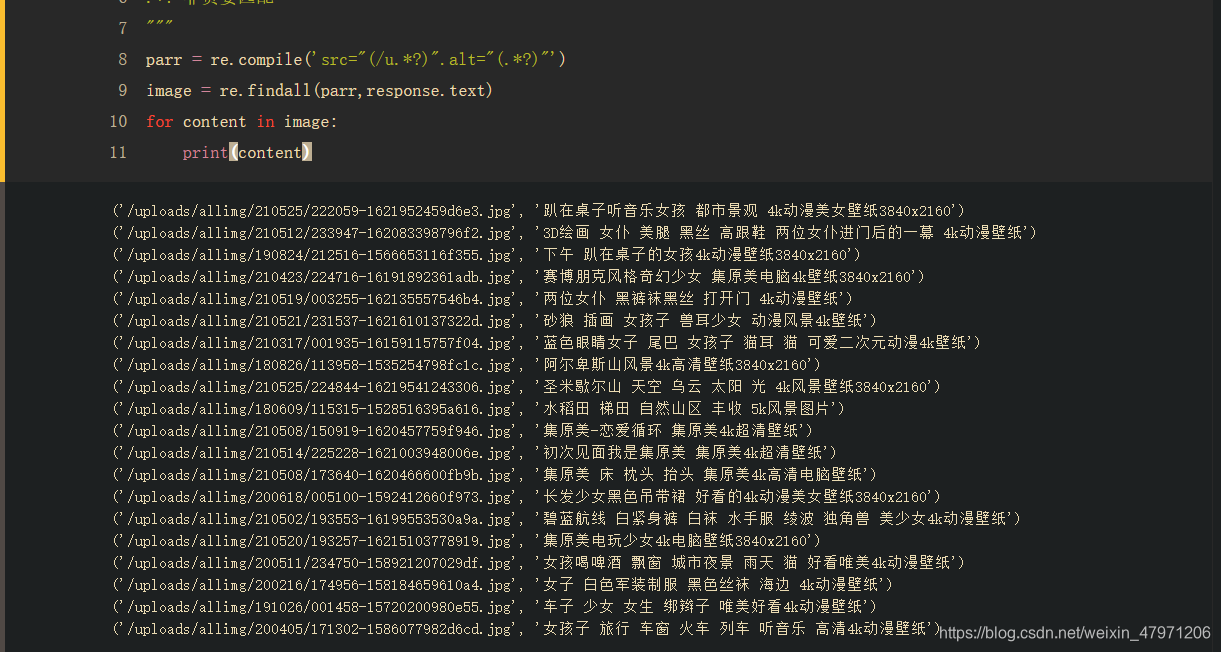
这样我们的链接和名字就存放到了image列表中了,通过打印我们可以看到以下内容
image[0]:列表第一个元素,也就是链接和图片
image[0][0]:列表第一个元素中的第一个值,也就是链接
image[0][1]:列表第一个元素中的第二个值,也就是名字

五、获取图片,保存到文件夹中(os库)
首先通过os库创建一个文件夹(当前你也可以手动在脚本目录创建一个文件夹)
import os
path = "彼岸图网图片获取"
if not os.path.isdir(path):
ok.mkdir(path)
然后对列表进行遍历,获取图片
# 对列表进行遍历
for i in image:
link = i[0] # 获取链接
name = i[1] # 获取名字
"""
在文件夹下创建一个空jpg文件,打开方式以 'wb' 二进制读写方式
@param res:图片请求的结果
"""
with open(path+"/{}.jpg".format(name),"wb") as img:
res = requests.get(link)
img.write(res.content) # 将图片请求的结果内容写到jpg文件中
img.close() # 关闭操作
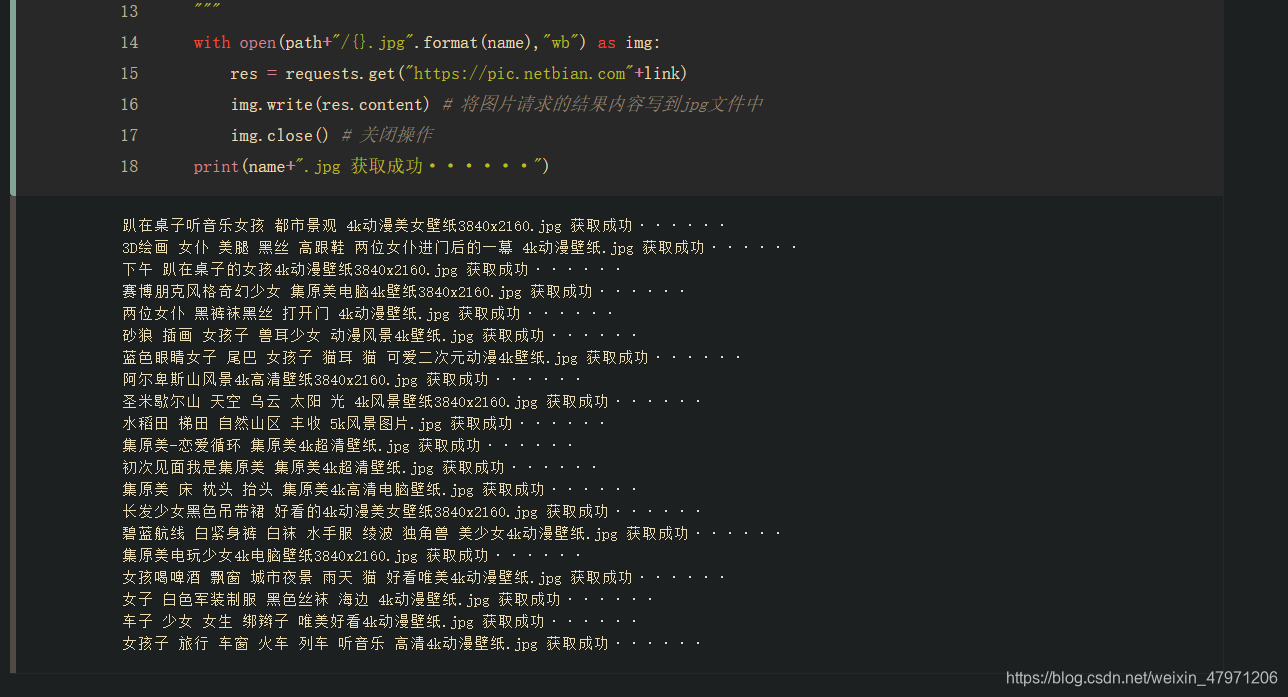
print(name+".jpg 获取成功······")
运行我们就会发现报错了,这是因为我们的图片链接不完整所导致的

我们回到图片首页网站,点开一张图片,我们可以在地址栏看到我们的图片链接缺少前面部分,我们复制下来 https://pic.netbian.com
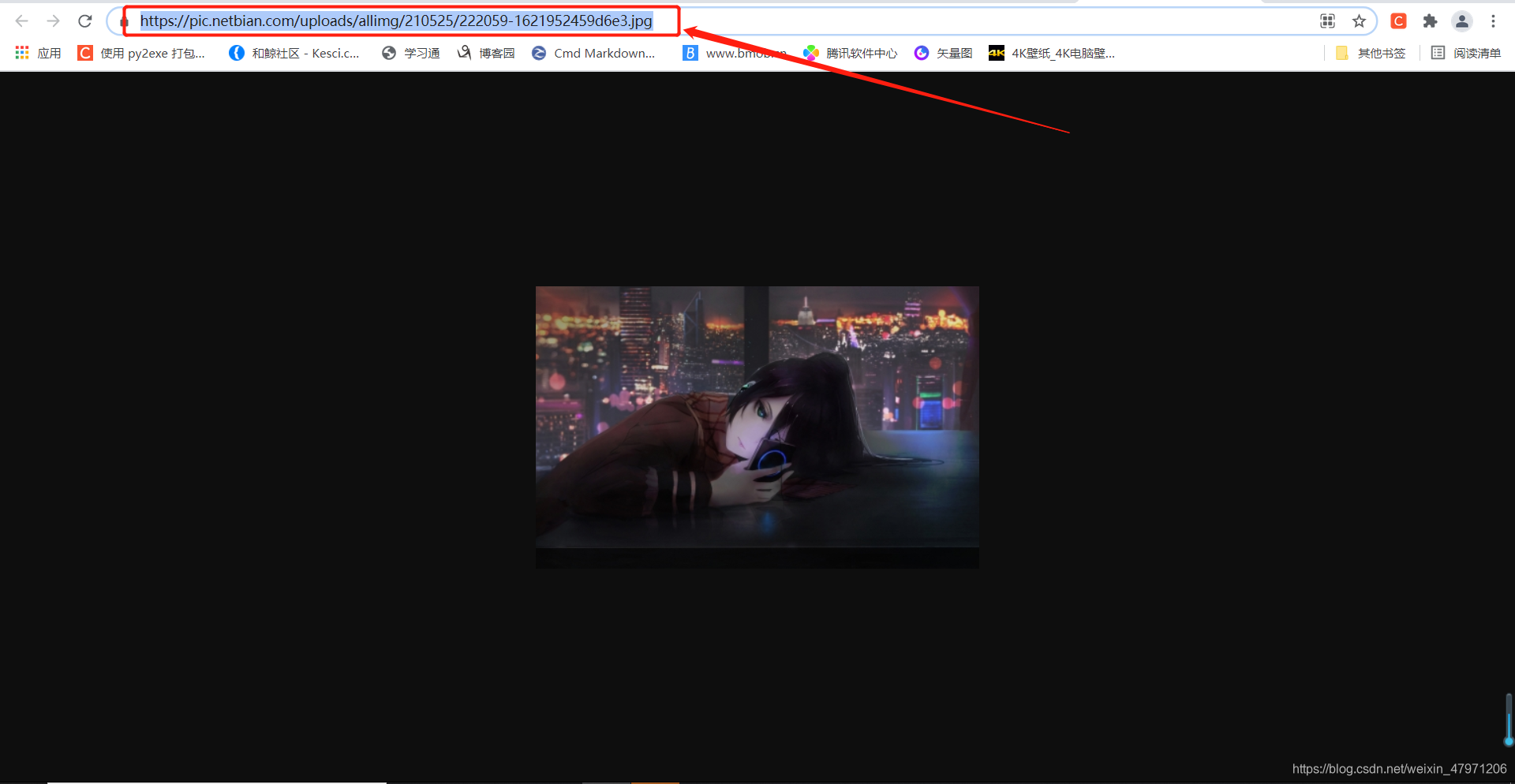
在获取图片的发送请求地址前加上刚刚复制的https://pic.netbian.com
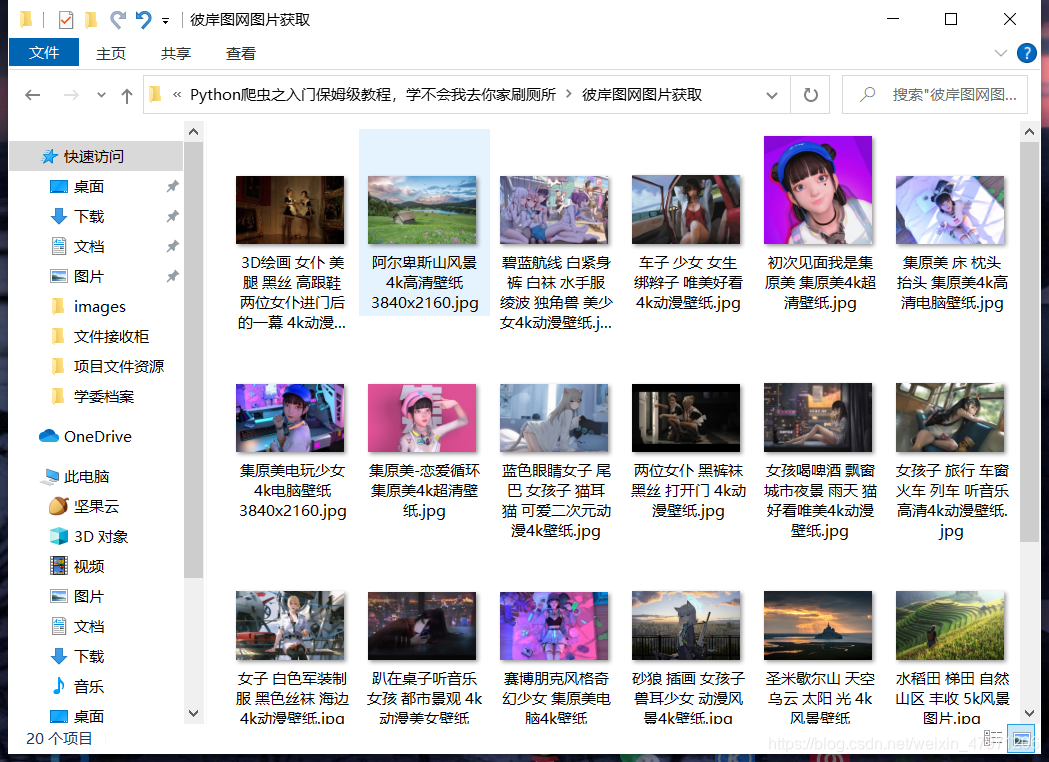
运行,OK,获取完毕
完整代码
import requests
import re
import os
url = "https://pic.netbian.com/"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
response = requests.get(url=url,headers=headers)
response.encoding = response.apparent_encoding
"""
. 表示除空格外任意字符(除\n外)
* 表示匹配字符零次或多次
? 表示匹配字符零次或一次
.*? 非贪婪匹配
"""
parr = re.compile('src="(/u.*?)".alt="(.*?)"') # 匹配图片链接和图片名字
image = re.findall(parr,response.text)
path = "彼岸图网图片获取"
if not os.path.isdir(path): # 判断是否存在该文件夹,若不存在则创建
os.mkdir(path) # 创建
# 对列表进行遍历
for i in image:
link = i[0] # 获取链接
name = i[1] # 获取名字
"""
在文件夹下创建一个空jpg文件,打开方式以 'wb' 二进制读写方式
@param res:图片请求的结果
"""
with open(path+"/{}.jpg".format(name),"wb") as img:
res = requests.get("https://pic.netbian.com"+link)
img.write(res.content) # 将图片请求的结果内容写到jpg文件中
img.close() # 关闭操作
print(name+".jpg 获取成功······")
本次教程到这里就结束了,是不是只爬了一页这么一点图片觉得不过瘾?
别急,下期我教大家如何获取十几页或者几十页甚至几百页的图片
- 本次文章分享就到这,有什么疑问或有更好的建议可在评论区留言,也可以私信我
- 感谢阅读~
智能推荐
jupyter notebook中matplotlib绘图包的中文乱码问题 —— 转载-程序员宅基地
文章浏览阅读965次。感谢原作,实测简洁、可用的教程查找matplotlib路径,输出大致如下:import matplotlibmatplotlib.matplotlib_fname()安装SimHei字体字体链接:百度网盘链接 密码:5vn4下载好的字体放到xxx/matplotlib/mpl-data/ttf下即可修改配置文件,配置文件在第一步的matplotlib路径下,添加内容如下...
Linux查询进程指令_linux查看进程命令-程序员宅基地
文章浏览阅读9.2k次,点赞3次,收藏7次。Linux 查询杀死进程_linux查看进程命令
Oracle EBS Forms查看trace file_ebs form trace-程序员宅基地
文章浏览阅读7.5k次。Introduction:Some times we need to diagnose the issue or error coming in forms. For such situation we need to get more information about the issue we are facing in forms. One of the best way to get su_ebs form trace
SpringBoot集成Spring Security(3)——异常处理_disabledexception-程序员宅基地
文章浏览阅读2.5w次,点赞25次,收藏92次。Step1 常见异常Step2 源码分析Step3 处理异常不知道你有没有注意到,当我们登陆失败时候,spring security帮我们跳转到了/login?error,奇怪的是不管是控制台还是网页上都没有打印错误信息。这是因为首先/login?error是spring security默认的失败url,其次如果你不手动处理这个异常,这个异常是不会被处理..._disabledexception
webview 加载h5页面,播放视频+全屏,实现简单封装_webview 加载的时候 可以直接播放视频吗-程序员宅基地
文章浏览阅读1.8w次,点赞4次,收藏7次。前段时间项目中用到了h5。从目前的市场来看,原生和h5的结合受到很多公司的欢迎,刚好最近微信也推出了它自己的“小程序”,这在Android程序员之间也掀起了波澜,引起大家讨论。个人觉得Google提供的webview有很多的坑,我这次就踩了不少,比如在某些版本的系统上某个方法不会执行,或者执行的顺序不一样,有的方法会多执行一次,说白了就是兼容性做的很差,究其主要原因,是Android4_webview 加载的时候 可以直接播放视频吗
ComfyUI 一键整合包- AIStarter启动器专属_comfyui-aki-v1.1.7z-程序员宅基地
文章浏览阅读532次,点赞9次,收藏7次。AIStarter使用教程及注意事项 -AIStarter tutorials and notes on how to use it。_comfyui-aki-v1.1.7z
随便推点
快速了解自动化测试工具Parasoft vs Fortify功能对比_pbvsj-程序员宅基地
文章浏览阅读411次。你知道测试金字塔吗?为了用开发实践来扩大测试规模,如何以正确的数量设计合适类型的自动化测试?测试金字塔是一个很好的指南!测试金字塔是一个很好的视觉隐喻,它描述了不同的测试层,以及每一层要做多少测试。Parasoft测试金字塔 虽然测试自动化金字塔为高效的测试自动化策略提供了一个蓝图,但你不能把测试质量融入到应用程序中。金字塔需要建立在坚实的基础上,进行深度的代码分析,专注于识别和预防可靠性和安全性问题。Parasoft测试金字塔,如下图所示,展示了Parasoft如何帮助每个级别的测试解决方_pbvsj
Go-MySQL(二)Go实现MySQL连接池_go语言mysql连接池-程序员宅基地
文章浏览阅读1.4k次。文章目录Go-MySQL(二)Go实现MySQL连接池连接池数据结构获取连接释放连接关闭连接池测试完整代码Go-MySQL(二)Go实现MySQL连接池连接池数据结构利用channel来存储数据库连接,消费channel中的消息获取连接,连接池未满时则新建连接后将连接放入channel,采用的带缓冲区的channel,缓冲区大小就是连接池的最大容纳的连接数,如果缓冲区还有空间,那么获取和释放连接都不会阻塞,如果缓冲区为空,那么就是阻塞连接获取,从而走新建连接的逻辑;同理,缓冲区满了,就阻塞向chann_go语言mysql连接池
Mysql 日志分析工具介绍_mysql日志分析工具-程序员宅基地
文章浏览阅读1.1w次。1. 工具简介pt-query-digest是用于分析mysql慢查询的一个工具,它可以分析binlog、General log、slowlog,也可以通过SHOWPROCESSLIST或者通过tcpdump抓取的MySQL协议数据来进行分析。可以把分析结果输出到文件中,分析过程是先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,可以借助分_mysql日志分析工具
javaweb基于SSH开发校园社团管理系统源码 课程设计 大作业 毕业设计_tp6校园社团管理系统-程序员宅基地
文章浏览阅读106次。开发校园社团管理系统(大作业/毕业设计)+Jdk+Tomcat+MYSQL数据库。开发环境: Windows操作系统。_tp6校园社团管理系统
网络安全学习--用户和用户组_组或用户名-程序员宅基地
文章浏览阅读1.1k次。文章基于Windows2003服务器系统版本Windows:win200,win2003,win2008r2,win2012Linux:Redhat,CentOS用户每个用户登录系统后,拥有不同的操作权限每个账户有自己唯一的SID(安全标识符)用户SID:S-1-5-21-42342423434-1433343434-500系统SID:S-1-5-21-42342423434-1433343434用户ID:500windows系统管理员administrator的UID是500普_组或用户名
Java注解 编译_Java注解之编译时注解-程序员宅基地
文章浏览阅读427次。新建两个moduleannotation用来定义注解compiler用来编写处理注解的代码这两个module都要选择Java Library 那为什么要拆分两个module呢,因为编译期注解的处理代码是只在代码编译的时候使用的,所以这些代码要和主module分开拆成compiler,但是compiler又依赖于注解,主module也要使用注解。所以就将注解的定义也拆分出来。这样做的好处是可以..._bw.append