mycat_wrapper-linux-aarch64-64-程序员宅基地
1.分库分表
-
垂直分库:以表为依据,根据业务将不同的表拆分至不同库中。
-
特点:
1.每个库的表结构不一样
2.每个库的数据也不一样
3.所有库的并集是全量数据
-
-
垂直分表:以字段为依据,根据字段属于将不同字段拆分到不同表中
-
特点:
1.每个表的结构不一样
2.每个表的数据也不一样,一般通过一列(主键/外键)关联
3.所有表的并集是全量数据
-
-
水平分库:以字段为依据,按照一定策略,将一个库的数据拆分到多个库中
-
特点:
1.每个库的表结构一样
2.每个库的数据都不一样
3.所有库的并集是全量数据
-
-
水平分表:以字段为依据,按照一定策略,将一个表的数据拆分到多个表中
-
特点:
1.每个表的结构都一样
2.每个表的数据都不一样
3.所有表的并集是全量数据
-
2.核心概念
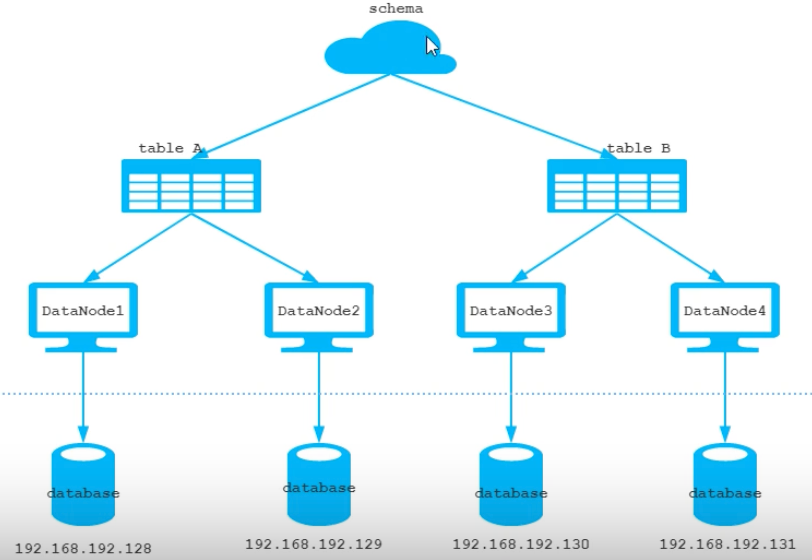
1.逻辑库、逻辑表
-
逻辑库:
-
逻辑表:分布式数据库中,对于应用来说,读取数据的表就说逻辑表。逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成。
- 分片表:指那些数据量很大的表,需要切分到多个数据库的表,这样每个分片都会有一部分数据,所以分片构成了完整的数据
- 非分片表:数据库中不是很大的表可以不用切分,非分片表是相对分片表来说的,就是那些不需要进行数据切分的表
- ER表:子表的记录与其关联的父表的记录存放在同一个数据分片中,通过表分组保证数据关联查询不会跨库操作
- 全局表:存储一些基础的数据,数量不大但在各个业务表中可能都存在关联,当业务表数据量大而分片后,业务表与附属的数据字典表之间的关联查询就变成了比较棘手的问题,在mycat中可以通过数据冗余来解决这类表的关联问题,即所有分片都复制这一份数据,因此可以把这些冗余数据的表定义为全局表。
2.分片测试
-
准备
-
三台服务器并且安装mysql
# 安装mysql docker run -p 3308:3306 \ -e MYSQL_ROOT_PASSWORD=root \ -v /mydata/mysql8/data:/var/lib/mysql-files:rw \ -v /mydata/mysql8/log:/var/log/mysql:rw \ -v /mydata/mysql8/config/my.cnf:/etc/my.cnf:rw \ --name mysql8 --restart=always -d mysql:8.0 # 安装mycat 解压jar包 # 修改mycat/lib/下 mysql-connector-java-8.0.22.jar (1.6.7mycat默认5.7)# 启动mycat报错 Unable to locate any of the following operational binaries: /etc/develop/mycat/bin/./wrapper-linux-aarch64-64 /etc/develop/mycat/bin/./wrapper-linux-aarch64-32 /etc/develop/mycat/bin/./wrapper # 解决 wget https://download.tanukisoftware.com/wrapper/3.5.40/wrapper-linux-armhf-64-3.5.40.tar.gz tar zxvf wrapper-linux-armhf-64-3.5.40.tar.gz 将 bin/wrapper 拷贝至 mycat/bin 目录下 将 lib/libwrapper.so 拷贝至 mycat/lib 目录下 -
配置mycat的schema.xml
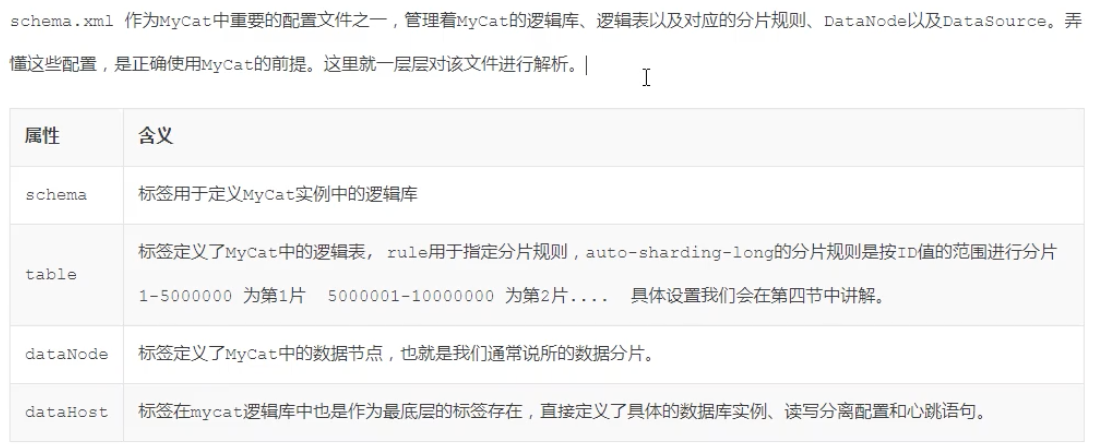
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="mycat" checkSQLschema="true" sqlMaxLimit="100"> <table name="test1" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" /> </schema> <dataNode name="dn1" dataHost="localhost1" database="db1" /> <dataNode name="dn2" dataHost="localhost2" database="db2" /> <dataNode name="dn3" dataHost="localhost3" database="db3" /> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc " switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="jdbc:mysql://10.211.55.3:3307?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="root"> </writeHost> </dataHost> <dataHost name="localhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="jdbc:mysql://10.211.55.4:3308?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="root"> </writeHost> </dataHost> <dataHost name="localhost3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="jdbc:mysql://10.211.55.5:3309?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="root"> </writeHost> </dataHost> </mycat:schema> -
配置mycat的server.xml

<property name="charset">utf8</property> <user name="root" defaultAccount="true"> <property name="password">root</property> <property name="schemas">mycat</property> //设置为逻辑库名 <!-- 表级 DML 权限设置 --> <!-- <privileges check="false"> <schema name="TESTDB" dml="0110" > <table name="tb01" dml="0000"></table> <table name="tb02" dml="1111"></table> </schema> </privileges> --> </user> <user name="user"> <property name="password">user</property> <property name="schemas">mycat</property> <property name="readOnly">true</property> </user> -
启动mycat bin/mycat start
查看logs下wrapper.log
MyCAT Server startup successfully. see logs in logs/mycat.log // 启动成功 -
连接mycat root root 端口8066
-
插入数据
INSERT INTO test1(id,title) VALUES(1,'a'); INSERT INTO test1(id,title) VALUES(2,'a');
-
3.分片
1.垂直拆分
- 将一个库的表拆分到多个库中,每个库的表结构不同,数据不同
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="mycat" checkSQLschema="true" sqlMaxLimit="100">
<table name="tb_areas_city" dataNode="dn1" primaryKey="id" />
<table name="tb_areas_provinces" dataNode="dn1" primaryKey="id" />
<table name="tb_areas_region" dataNode="dn1" primaryKey="id" />
<table name="tb_user" dataNode="dn1" primaryKey="id" />
<table name="tb_user_address" dataNode="dn1" primaryKey="id" />
<table name="tb_goods_base" dataNode="dn2" primaryKey="id" />
<table name="tb_goods_desc" dataNode="dn2" primaryKey="goods_id" />
<table name="tb_goods_item_cat" dataNode="dn2" primaryKey="id" />
<table name="tb_order_item" dataNode="dn3" primaryKey="id" />
<table name="tb_order_master" dataNode="dn3" primaryKey="order_id" />
<table name="tb_order_pay_log" dataNode="dn3" primaryKey="out_trade_no" />
</schema>
<dataNode name="dn1" dataHost="localhost1" database="user_db" />
<dataNode name="dn2" dataHost="localhost2" database="goods_db" />
<dataNode name="dn3" dataHost="localhost3" database="order_db" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="jdbc:mysql://10.211.55.3:3307?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root"
password="root">
</writeHost>
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="jdbc:mysql://10.211.55.4:3308?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root"
password="root">
</writeHost>
</dataHost>
<dataHost name="localhost3" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="jdbc:mysql://10.211.55.5:3309?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root"
password="root">
</writeHost>
</dataHost>
</mycat:schema>
SELECT order_id , payment ,receiver, province , city , area FROM tb_order_master o , tb_areas_provinces p , tb_areas_city c , tb_areas_region r
WHERE o.receiver_province = p.provinceid AND o.receiver_city = c.cityid AND o.receiver_region = r.areaid ;
# MyCat会报错, 原因是因为当前SQL语句涉及到跨域的join操作
-
全局表
<table name="tb_areas_city" dataNode="dn1,dn2,dn3" primaryKey="id" type="global"/> <table name="tb_areas_provinces" dataNode="dn1,dn2,dn3" primaryKey="id" type="global"/> <table name="tb_areas_region" dataNode="dn1,dn2,dn3" primaryKey="id" type="global"/>
2.水平拆分
-
将库的表拆分到不同的库中,每个数据库的表结构不一样,数据不一样
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="mycat" checkSQLschema="true" sqlMaxLimit="100"> # rule="mod-long":取余 <table name="tb_log" dataNode="dn1,dn2,dn3" primaryKey="id" rule="mod-long" /> </schema> <dataNode name="dn1" dataHost="localhost1" database="log_db" /> <dataNode name="dn2" dataHost="localhost2" database="log_db" /> <dataNode name="dn3" dataHost="localhost3" database="log_db" /> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="jdbc:mysql://10.211.55.3:3307?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="root"> </writeHost> </dataHost> <dataHost name="localhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="jdbc:mysql://10.211.55.4:3308?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="root"> </writeHost> </dataHost> <dataHost name="localhost3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="jdbc:mysql://10.211.55.5:3309?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="root"> </writeHost> </dataHost> </mycat:schema>
3.分片规则
1.取模分片
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">3</property>
</function>
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| count | 数据节点的数量 |
2.范围分片
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
<property name="defaultNode">0</property>
</function>
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| mapFile | 对应的外部配置文件 |
| type | 默认值为0 ; 0 表示Integer , 1 表示String |
| defaultNode | 默认节点的所用:枚举分片时,如果碰到不识别的枚举值, 就让它路由到默认节点 ; 如果没有默认值,碰到不识别的则报错 。 |
3.枚举分片
<tableRule name="sharding-by-intfile">
<rule>
<columns>status</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">0</property>
<property name="defaultNode">0</property>
</function>
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| mapFile | 对应的外部配置文件 |
| type | 默认值为0 ; 0 表示Integer , 1 表示String |
| defaultNode | 默认节点 ; 小于0 标识不设置默认节点 , 大于等于0代表设置默认节点 ; 默认节点的所用:枚举分片时,如果碰到不识别的枚举值, 就让它路由到默认节点 ; 如果没有默认值,碰到不识别的则报错 。 |
修改partition-hash-int.txt
1=0
2=1
3=2
4.范围求模算法
该算法为先进行范围分片, 计算出分片组 , 再进行组内求模。
优点: 综合了范围分片和求模分片的优点。 分片组内使用求模可以保证组内的数据分布比较均匀, 分片组之间采用范围分片可以兼顾范围分片的特点。
缺点: 在数据范围时固定值(非递增值)时,存在不方便扩展的情况,例如将 dataNode Group size 从 2 扩展为 4 时,需要进行数据迁移才能完成 。
<tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">autopartition-range-mod.txt</property>
<property name="defaultNode">0</property>
</function>
#autopartition-range-mod.txt
#range start-end , data node group size
0-500M=1
500M1-2000M=2 #2=分片数量
| columns | 标识将要分片的表字段名 |
|---|---|
| 属性 | 描述 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| mapFile | 对应的外部配置文件 |
| defaultNode | 默认节点 ; 未包含以上规则的数据存储在defaultNode节点中, 节点从0开始 |
5.固定分片hash算法
该算法类似于十进制的求模运算,但是为二进制的操作,例如,取 id 的二进制低 10 位 与 1111111111 进行位 & 运算

优点: 这种策略比较灵活,可以均匀分配也可以非均匀分配,各节点的分配比例和容量大小由partitionCount和partitionLength两个参数决定
缺点:和取模分片类似
<tableRule name="sharding-by-long-hash">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<function name="func1" class="org.opencloudb.route.function.PartitionByLong">
<property name="partitionCount">2,1</property>
<property name="partitionLength">256,512</property>
</function>
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段名 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| partitionCount | 分片个数列表 |
| partitionLength | 分片范围列表 |
约束 :
1). 分片长度 : 默认最大2^10 , 为 1024 ;
2). count, length的数组长度必须是一致的 ;
3). 两组数据的对应情况: (partitionCount[0]partitionLength[0])=(partitionCount[1]partitionLength[1])
以上分为三个分区:0-255,256-511,512-1023
6.取模范围算法
该算法先进行取模,然后根据取模值所属范围进行分片。
优点:可以自主决定取模后数据的节点分布
缺点:dataNode 划分节点是事先建好的,需要扩展时比较麻烦。
<tableRule name="sharding-by-pattern">
<rule>
<columns>id</columns>
<algorithm>sharding-by-pattern</algorithm>
</rule>
</tableRule>
<function name="sharding-by-pattern" class="io.mycat.route.function.PartitionByPattern">
<property name="mapFile">partition-pattern.txt</property>
<property name="defaultNode">0</property>
<property name="patternValue">96</property>
</function>
partition-pattern.txt 配置如下:
0-32=0
33-64=1
65-96=2
在mapFile配置文件中, 1-32即代表id%96后的分布情况。如果在1-32, 则在分片0上 ; 如果在33-64, 则在分片1上 ; 如果在65-96, 则在分片2上。
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| mapFile | 对应的外部配置文件 |
| defaultNode | 默认节点 ; 如果id不是数字, 无法求模, 将分配在defaultNode上 |
| patternValue | 求模基数 |
7.字符串hash求模范围算法
与取模范围算法类似, 该算法支持数值、符号、字母取模,首先截取长度为 prefixLength 的子串,在对子串中每一个字符的 ASCII 码求和,然后对求和值进行取模运算(sum%patternValue),就可以计算出子串的分片数。
优点:可以自主决定取模后数据的节点分布
缺点:dataNode 划分节点是事先建好的,需要扩展时比较麻烦。
<tableRule name="sharding-by-prefixpattern">
<rule>
<columns>id</columns>
<algorithm>sharding-by-prefixpattern</algorithm>
</rule>
</tableRule>
<function name="sharding-by-prefixpattern" class="io.mycat.route.function.PartitionByPrefixPattern">
<property name="mapFile">partition-prefixpattern.txt</property>
<property name="prefixLength">5</property>
<property name="patternValue">96</property>
</function>
partition-prefixpattern.txt 配置如下:
# range start-end ,data node index
# ASCII
# 48-57=0-9
# 64、65-90=@、A-Z
# 97-122=a-z
###### first host configuration
0-32=0
33-64=1
65-96=2
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| mapFile | 对应的外部配置文件 |
| prefixLength | 截取的位数; 将该字段获取前prefixLength位所有ASCII码的和, 进行求模sum%patternValue ,获取的值,在通配范围内的即分片数 ; |
| patternValue | 求模基数 |
8.应用指定算法
由运行阶段由应用自主决定路由到那个分片 , 直接根据字符子串(必须是数字)计算分片号 , 配置如下 :
<tableRule name="sharding-by-substring">
<rule>
<columns>id</columns>
<algorithm>sharding-by-substring</algorithm>
</rule>
</tableRule>
<function name="sharding-by-substring" class="io.mycat.route.function.PartitionDirectBySubString">
<property name="startIndex">0</property> <!-- zero-based -->
<property name="size">2</property>
<property name="partitionCount">3</property>
<property name="defaultPartition">0</property>
</function>
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| startIndex | 字符子串起始索引 |
| size | 字符长度 |
| partitionCount | 分区(分片)数量 |
| defaultPartition | 默认分片(在分片数量定义时, 字符标示的分片编号不在分片数量内时,使用默认分片) |
示例说明 :
id=05-100000002 , 在此配置中代表根据id中从 startIndex=0,开始,截取siz=2位数字即05,05就是获取的分区,如果没传默认分配到defaultPartition
9.字符串hash解析算法
截取字符串中的指定位置的子字符串, 进行hash算法, 算出分片 , 配置如下:
<tableRule name="sharding-by-stringhash">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-stringhash</algorithm>
</rule>
</tableRule>
<function name="sharding-by-stringhash" class="io.mycat.route.function.PartitionByString">
<property name="partitionLength">512</property> <!-- zero-based -->
<property name="partitionCount">2</property>
<property name="hashSlice">0:2</property>
</function>
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| partitionLength | hash求模基数 ; length*count=1024 (出于性能考虑) |
| partitionCount | 分区数 |
| hashSlice | hash运算位 , 根据子字符串的hash运算 ; 0 代表 str.length() , -1 代表 str.length()-1 , 大于0只代表数字自身 ; 可以理解为substring(start,end),start为0则只表示0 |
10.一致性hash算法
一致性Hash算法有效的解决了分布式数据的拓容问题 , 配置如下:
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<function name="murmur" class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property>
<property name="count">3</property><!-- -->
<property name="virtualBucketTimes">160</property>
<!-- <property name="weightMapFile">weightMapFile</property> -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property> -->
</function>
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| seed | 创建murmur_hash对象的种子,默认0 |
| count | 要分片的数据库节点数量,必须指定,否则没法分片 |
| virtualBucketTimes | 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍;virtualBucketTimes*count就是虚拟结点数量 ; |
| weightMapFile | 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 |
| bucketMapPath | 用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 |
11.日期分片算法
按照日期来分片
<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>
<function name="sharding-by-date" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2020-01-01</property>
<property name="sEndDate">2020-12-31</property>
<property name="sPartionDay">10</property>
</function>
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| dateFormat | 日期格式 |
| sBeginDate | 开始日期 |
| sEndDate | 结束日期,如果配置了结束日期,则代码数据到达了这个日期的分片后,会重复从开始分片插入 |
| sPartionDay | 分区天数,默认值 10 ,从开始日期算起,每个10天一个分区 |
注意:配置规则的表的 dataNode 的分片,必须和分片规则数量一致,例如 2020-01-01 到 2020-12-31 ,每10天一个分片,一共需要37个分片
12.单月小时算法
单月内按照小时拆分, 最小粒度是小时 , 一天最多可以有24个分片, 最小1个分片, 下个月从头开始循环, 每个月末需要手动清理数据。
<tableRule name="sharding-by-hour">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-hour</algorithm>
</rule>
</tableRule>
<function name="sharding-by-hour" class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 ; 字符串类型(yyyymmddHH), 需要符合JAVA标准 |
| algorithm | 指定分片函数与function的对应关系 |
| splitOneDay | 一天切分的分片数 |
13.自然月分片算法
使用场景为按照月份列分区, 每个自然月为一个分片, 配置如下:
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-month</algorithm>
</rule>
</tableRule>
<function name="sharding-by-month" class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2020-01-01</property>
<property name="sEndDate">2020-12-31</property>
</function>
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| dateFormat | 日期格式 |
| sBeginDate | 开始日期 |
| sEndDate | 结束日期,如果配置了结束日期,则代码数据到达了这个日期的分片后,会重复从开始分片插入 |
14.日期范围hash算法
其思想和范围取模分片一样,先根据日期进行范围分片求出分片组,再根据时间hash使得短期内数据分布的更均匀 ;
优点 : 可以避免扩容时的数据迁移,又可以一定程度上避免范围分片的热点问题
注意 : 要求日期格式尽量精确些,不然达不到局部均匀的目的
<tableRule name="range-date-hash">
<rule>
<columns>create_time</columns>
<algorithm>range-date-hash</algorithm>
</rule>
</tableRule>
<function name="range-date-hash" class="io.mycat.route.function.PartitionByRangeDateHash">
<property name="dateFormat">yyyy-MM-dd HH:mm:ss</property>
<property name="sBeginDate">2020-01-01 00:00:00</property>
<property name="groupPartionSize">6</property>
<property name="sPartionDay">10</property>
</function>
| 属性 | 描述 |
|---|---|
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与function的对应关系 |
| class | 指定该分片算法对应的类 |
| dateFormat | 日期格式 , 符合Java标准 |
| sBeginDate | 开始日期 , 与 dateFormat指定的格式一致 |
| groupPartionSize | 每组的分片数量 |
| sPartionDay | 代表多少天为一组 |
4.mycat性能监控
-
mycatweb简介
Mycat-web 是 Mycat 可视化运维的管理和监控平台,弥补了 Mycat 在监控上的空白。帮 Mycat 分担统计任务和配置管理任务。Mycat-web 引入了 ZooKeeper 作为配置中心,可以管理多个节点。Mycat-web 主要管理和监控 Mycat 的流量、连接、活动线程和内存等,具备 IP 白名单、邮件告警等模块,还可以统计 SQL 并分析慢 SQL 和高频 SQL 等。为优化 SQL 提供依据
-
mycatweb安装
-
安装zookeeper (安装jdk)
A. 上传安装包 alt + p -----> put D:\tmp\zookeeper-3.4.11.tar.gz B. 解压 tar -zxvf zookeeper-3.4.11.tar.gz -C /usr/local/ C. 创建数据存放目录 mkdir data D. 修改配置文件名称并配置 mv zoo_sample.cfg zoo.cfg E. 配置数据存放目录 dataDir=/usr/local/zookeeper-3.4.11/data F. 启动Zookeeper bin/zkServer.sh start -
安装mycatweb
A. 上传安装包 alt + p --------> put D:\tmp\Mycat-web-1.0-SNAPSHOT-20170102153329-linux.tar.gz B. 解压 tar -zxvf Mycat-web-1.0-SNAPSHOT-20170102153329-linux.tar.gz -C /usr/local/ C. 目录介绍 drwxr-xr-x. 2 root root 4096 Oct 19 2015 etc ----> jetty配置文件 drwxr-xr-x. 3 root root 4096 Oct 19 2015 lib ----> 依赖jar包 drwxr-xr-x. 7 root root 4096 Jan 1 2017 mycat-web ----> mycat-web项目 -rwxr-xr-x. 1 root root 116 Oct 19 2015 readme.txt -rwxr-xr-x. 1 root root 17125 Oct 19 2015 start.jar ----> 启动jar -rwxr-xr-x. 1 root root 381 Oct 19 2015 start.sh ----> linux启动脚本 D. 启动 sh start.sh E. 访问 http://192.168.192.147:8082/mycat如果Zookeeper与Mycat-web不在同一台服务器上 , 需要设置Zookeeper的地址 ; 在/usr/local/mycat-web/mycat-web/WEB-INF/classes/mycat.properties文件中配置
-
5.mycat读写分离
1.搭建主从复制(一主一从)
-
master配置文件(/etc/my.cnf)中配置
## 同一局域网内注意要唯一 server-id=100 ## 开启二进制日志功能,可以随便取(关键) log-bin=master-bin binlog-format=ROW // 二级制日志格式,有三种 row,statement,mixed binlog-do-db=数据库名 //同步的数据库名称,如果不配置,表示同步所有的库 -
slave配置文件 (/etc/my.cnf)
[mysqld] ## 设置server_id,注意要唯一 server-id=101 ## 开启二进制日志功能,以备Slave作为其它Slave的Master时使用 log-bin=mysql-slave-bin ## relay_log配置中继日志 relay_log=mysql-relay-bin read_only=1 ## 设置为只读,该项如果不设置,表示slave可读可写 -
开启主从复制
# master # 创建用户并授权 CREATE USER '用户名'@'%' IDENTIFIED WITH 'mysql_native_password' BY '密码'; GRANT REPLICATION SLAVE ON *.* TO '用户名'@'%'; flush privileges; # show master status查看Master状态 记住file和position SELECT DISTINCT CONCAT('User: ''',user,'''@''',host,''';') AS query FROM mysql.user; #slave change master to master_host='服务器地址', master_user='用户名', master_password='密码', master_port=3306, master_log_file='master-bin.000001', master_log_pos=2344, master_connect_retry=30; start slave; stop slave; show slave status \G;[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nwFdRiPN-1658027949266)(images/image-20220712091151471.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TOFrwNKg-1658027949266)(images/image-20220712091335699.png)]
2.一主一从读写分离
-
修改schem.xml配置文件
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="test1" checkSQLschema="true" sqlMaxLimit="100"> <table name="user" dataNode="dn1" primaryKey="id" /> </schema> <dataNode name="dn1" dataHost="localhost1" database="db1" /> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="jdbc:mysql://10.211.55.3:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="root"> <readHost host="hostS1" url="jdbc:mysql://10.211.55.4:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="root" /> </writeHost> </dataHost> </mycat:schema>checkSQLschema 当该值设置为true时, 如果我们执行语句"select * from test01.user ;" 语句时, MyCat则会把schema字符去掉 , 可以避免后端数据库执行时报错 ; balance 负载均衡类型, 目前取值有4种: balance="0" : 不开启读写分离机制 , 所有读操作都发送到当前可用的writeHost上. balance="1" : 全部的readHost 与 stand by writeHost (备用的writeHost) 都参与select 语句的负载均衡,简而言之,就是采用双主双从模式(M1 --> S1 , M2 --> S2, 正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。); balance="2" : 所有的读写操作都随机在writeHost , readHost上分发 balance="3" : 所有的读请求随机分发到writeHost对应的readHost上执行, writeHost不负担读压力 ;balance=3 只在MyCat1.4 之后生效 . -
修改server.xml配置文件
<user name="root" defaultAccount="true"> <property name="password">root</property> <property name="schemas">test1</property> </user> <user name="user"> <property name="password">root</property> <property name="schemas">test1</property> <property name="readOnly">true</property> </user> -
修改log4j日志级别info–>debug
<Loggers> <!--<AsyncLogger name="io.mycat" level="info" includeLocation="true" additivity="false">--> <!--<AppenderRef ref="Console"/>--> <!--<AppenderRef ref="RollingFile"/>--> <!--</AsyncLogger>--> <asyncRoot level="debug" includeLocation="true"> <!--<AppenderRef ref="Console" />--> <AppenderRef ref="RollingFile"/> </asyncRoot> </Loggers>
3.主从复制(双主双从)
# 重新配置主从关系
stop slave;
reset master;
-
master1配置
#主服务器唯一ID server-id=1 #启用二进制日志 log-bin=master-bin binlog-format=ROW # 设置不要复制的数据库(可设置多个) # binlog-ignore-db=mysql # binlog-ignore-db=information_schema #设置需要复制的数据库 binlog-do-db=db02 binlog-do-db=db03 binlog-do-db=db04 # 在作为从数据库的时候,有写入操作也要更新二进制日志文件 log-slave-updates -
master2配置
#主服务器唯一ID server-id=2 #启用二进制日志 log-bin=master-bin binlog-format=ROW # 设置不要复制的数据库(可设置多个) # binlog-ignore-db=mysql # binlog-ignore-db=information_schema #设置需要复制的数据库 binlog-do-db=db02 binlog-do-db=db03 binlog-do-db=db04 # 在作为从数据库的时候,有写入操作也要更新二进制日志文件 log-slave-updates -
双从机配置
[mysqld] # slave1 ## 设置server_id,注意要唯一 server-id=3 ## 开启二进制日志功能,以备Slave作为其它Slave的Master时使用 log-bin=mysql-slave-bin ## relay_log配置中继日志 relay_log=mysql-relay-bin read_only=1 ## 设置为只读,该项如果不设置,表示slave可读可写 #slave2 ## 设置server_id,注意要唯一 server-id=4 ## 开启二进制日志功能,以备Slave作为其它Slave的Master时使用 log-bin=mysql-slave-bin ## relay_log配置中继日志 relay_log=mysql-relay-bin read_only=1 ## 设置为只读,该项如果不设置,表示slave可读可写# master上操作 # 创建用户并授权 CREATE USER '用户名'@'%' IDENTIFIED WITH 'mysql_native_password' BY '密码'; GRANT REPLICATION SLAVE ON *.* TO '用户名'@'%'; flush privileges; # show master status查看Master状态 记住file和position #slave1->mast1 slave2 ->master2 change master to master_host='服务器地址', master_user='用户名', master_password='密码', master_port=3306, master_log_file='master-bin.000001', master_log_pos=2344, master_connect_retry=30; start slave; stop slave; show slave status \G; -
双主机配置
# master1操作 CHANGE MASTER TO MASTER_HOST='master2', MASTER_USER='用户', MASTER_PASSWORD='密码', MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=409; #master2操作 CHANGE MASTER TO MASTER_HOST='master1', MASTER_USER='用户', MASTER_PASSWORD='密码', MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=409;
4.双主双从读写分离
- schem.xml配置
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="test" checkSQLschema="true" sqlMaxLimit="100">
<table name="user" dataNode="dn1" primaryKey="id"/>
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db03" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql"
dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.192.147:3306" user="root" password="root">
<readHost host="hostS1" url="192.168.192.149:3306" user="root" password="root" />
</writeHost>
<writeHost host="hostM2" url="192.168.192.150:3306" user="root" password="root">
<readHost host="hostS2" url="192.168.192.151:3306" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
智能推荐
874计算机科学基础综合,2018年四川大学874计算机科学专业基础综合之计算机操作系统考研仿真模拟五套题...-程序员宅基地
文章浏览阅读1.1k次。一、选择题1. 串行接口是指( )。A. 接口与系统总线之间串行传送,接口与I/0设备之间串行传送B. 接口与系统总线之间串行传送,接口与1/0设备之间并行传送C. 接口与系统总线之间并行传送,接口与I/0设备之间串行传送D. 接口与系统总线之间并行传送,接口与I/0设备之间并行传送【答案】C2. 最容易造成很多小碎片的可变分区分配算法是( )。A. 首次适应算法B. 最佳适应算法..._874 计算机科学专业基础综合题型
XShell连接失败:Could not connect to '192.168.191.128' (port 22): Connection failed._could not connect to '192.168.17.128' (port 22): c-程序员宅基地
文章浏览阅读9.7k次,点赞5次,收藏15次。连接xshell失败,报错如下图,怎么解决呢。1、通过ps -e|grep ssh命令判断是否安装ssh服务2、如果只有客户端安装了,服务器没有安装,则需要安装ssh服务器,命令:apt-get install openssh-server3、安装成功之后,启动ssh服务,命令:/etc/init.d/ssh start4、通过ps -e|grep ssh命令再次判断是否正确启动..._could not connect to '192.168.17.128' (port 22): connection failed.
杰理之KeyPage【篇】_杰理 空白芯片 烧入key文件-程序员宅基地
文章浏览阅读209次。00000000_杰理 空白芯片 烧入key文件
一文读懂ChatGPT,满足你对chatGPT的好奇心_引发对chatgpt兴趣的表述-程序员宅基地
文章浏览阅读475次。2023年初,“ChatGPT”一词在社交媒体上引起了热议,人们纷纷探讨它的本质和对社会的影响。就连央视新闻也对此进行了报道。作为新传专业的前沿人士,我们当然不能忽视这一热点。本文将全面解析ChatGPT,打开“技术黑箱”,探讨它对新闻与传播领域的影响。_引发对chatgpt兴趣的表述
中文字符频率统计python_用Python数据分析方法进行汉字声调频率统计分析-程序员宅基地
文章浏览阅读259次。用Python数据分析方法进行汉字声调频率统计分析木合塔尔·沙地克;布合力齐姑丽·瓦斯力【期刊名称】《电脑知识与技术》【年(卷),期】2017(013)035【摘要】该文首先用Python程序,自动获取基本汉字字符集中的所有汉字,然后用汉字拼音转换工具pypinyin把所有汉字转换成拼音,最后根据所有汉字的拼音声调,统计并可视化拼音声调的占比.【总页数】2页(13-14)【关键词】数据分析;数据可..._汉字声调频率统计
linux输出信息调试信息重定向-程序员宅基地
文章浏览阅读64次。最近在做一个android系统移植的项目,所使用的开发板com1是调试串口,就是说会有uboot和kernel的调试信息打印在com1上(ttySAC0)。因为后期要使用ttySAC0作为上层应用通信串口,所以要把所有的调试信息都给去掉。参考网上的几篇文章,自己做了如下修改,终于把调试信息重定向到ttySAC1上了,在这做下记录。参考文章有:http://blog.csdn.net/longt..._嵌入式rootfs 输出重定向到/dev/console
随便推点
uniapp 引入iconfont图标库彩色symbol教程_uniapp symbol图标-程序员宅基地
文章浏览阅读1.2k次,点赞4次,收藏12次。1,先去iconfont登录,然后选择图标加入购物车 2,点击又上角车车添加进入项目我的项目中就会出现选择的图标 3,点击下载至本地,然后解压文件夹,然后切换到uniapp打开终端运行注:要保证自己电脑有安装node(没有安装node可以去官网下载Node.js 中文网)npm i -g iconfont-tools(mac用户失败的话在前面加个sudo,password就是自己的开机密码吧)4,终端切换到上面解压的文件夹里面,运行iconfont-tools 这些可以默认也可以自己命名(我是自己命名的_uniapp symbol图标
C、C++ 对于char*和char[]的理解_c++ char*-程序员宅基地
文章浏览阅读1.2w次,点赞25次,收藏192次。char*和char[]都是指针,指向第一个字符所在的地址,但char*是常量的指针,char[]是指针的常量_c++ char*
Sublime Text2 使用教程-程序员宅基地
文章浏览阅读930次。代码编辑器或者文本编辑器,对于程序员来说,就像剑与战士一样,谁都想拥有一把可以随心驾驭且锋利无比的宝剑,而每一位程序员,同样会去追求最适合自己的强大、灵活的编辑器,相信你和我一样,都不会例外。我用过的编辑器不少,真不少~ 但却没有哪款让我特别心仪的,直到我遇到了 Sublime Text 2 !如果说“神器”是我能给予一款软件最高的评价,那么我很乐意为它封上这么一个称号。它小巧绿色且速度非
对10个整数进行按照从小到大的顺序排序用选择法和冒泡排序_对十个数进行大小排序java-程序员宅基地
文章浏览阅读4.1k次。一、选择法这是每一个数出来跟后面所有的进行比较。2.冒泡排序法,是两个相邻的进行对比。_对十个数进行大小排序java
物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)_网络调试助手连接阿里云连不上-程序员宅基地
文章浏览阅读2.9k次。物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)其实作者本意是使用4G模块来实现与阿里云物联网平台的连接过程,但是由于自己用的4G模块自身的限制,使得阿里云连接总是无法建立,已经联系客服返厂检修了,于是我在此使用网络调试助手来演示如何与阿里云物联网平台建立连接。一.准备工作1.MQTT协议说明文档(3.1.1版本)2.网络调试助手(可使用域名与服务器建立连接)PS:与阿里云建立连解释,最好使用域名来完成连接过程,而不是使用IP号。这里我跟阿里云的售后工程师咨询过,表示对应_网络调试助手连接阿里云连不上
<<<零基础C++速成>>>_无c语言基础c++期末速成-程序员宅基地
文章浏览阅读544次,点赞5次,收藏6次。运算符与表达式任何高级程序设计语言中,表达式都是最基本的组成部分,可以说C++中的大部分语句都是由表达式构成的。_无c语言基础c++期末速成