基于分层强化学习的自动驾驶轨迹规划-程序员宅基地
作者 | Jone出品 | 焉知汽车
在不确定和动态条件下规划安全轨迹将使得自动驾驶问题变得非常复杂。由于计算成本较高,当前基于采样的方法(例如快速探索随机树(RRT))对于此问题并不理想。模仿学习等监督学习方法缺乏泛化性和安全性保障。为了解决这些问题并确保框架的稳健性,本文介绍了一种分层强化学习(HRL)结构与比例积分微分(PID)控制器相结合的轨迹规划。分层强化学习HRL将有助于将自动驾驶汽车的任务划分为子目标,并支持网络学习高级选项和低级轨迹规划器选择的策略。子目标的引入减少了收敛时间,并使学到的策略能够在其他场景中重用。此外,通过保证平滑的轨迹和处理自车的噪声感知系统,所提出的规划器变得鲁棒。PID控制器用于跟踪航路点,确保轨迹平滑并减少剧烈变化。对于目标阶段性观测可能出现不完整的问题则是通过在网络中使用长短期记忆(LSTM)层来解决的。
规划自动驾驶车辆的安全轨迹是一个具有挑战性的问题。实际上,由于机动规划的复杂性、环境的随机性以及来自汽车的噪声感知系统的不完整观察,这个问题特别困难。在执行轨迹规划时,自动驾驶车辆必须规划不同的操作,其中可能包括车道跟随、等待、变道和穿越十字路口。
现有的轨迹规划方法要么依赖于传统的经典规划器,要么依赖于机器学习方法。一些最先进的传统规划器包括基于采样的规划器,例如快速探索随机树(RRT)和格子规划器。其中,RRT 随机构建空间填充树,非常适合有障碍物和差分约束的环境。然而,它们的计算复杂度随着环境复杂度的增加而增大。此外,生成的轨迹对于自车来说通常并不平滑。
另一方面,格子规划器擅长生成可行路径并合并约束。然而,这种方式可能会创建不完整的图,从而导致曲率不连续。
规划轨迹的另一种方法是通过机器学习方法,这种方法又称为模仿学习的自监督学习方法,并且这种方法已经显示出一些卓有成效的效果。然而,这种方法可能不能很好地推广到复杂的条件,因为无法穷尽所有极端场景,也就不能对这些场景进行提前学习。因此,也就不能保证稳定性和最优解。
经典规划器和监督学习方法的另一种方法是强化学习(RL)。强化学习框架的工作原理是在给定状态下最大化特定操作的奖励。现有的强化学习工作已经显示出自车学习多种场景策略的良好结果。然而,传统的自动驾驶强化学习方法样本效率较低且稳定性较差,特别是对于具有多个子目标的任务。
与传统的强化学习相比,分层强化学习(HRL)允许模型学习多个子目标的策略,这使得学习到的策略可以在任何其他场景中重用。此外,HRL 显示出更快的收敛速度,这减少了模型学习最优策略的训练时间。
在本文中,介绍了一种用于轨迹规划的 HRL 结构。通过选择城市变道场景,并为本文算法结构提供两个高级选项:车道跟随/等待和变道选项。
相关工作
A. 分层强化学习
通过扩展RL框架,提出了分层深度 Q 网络(DQN)的思想,其中集成了动作价值函数,以在两个抽象级别上运行,并学习了元目标和低目标的策略级别的行动。提出了称为 MAXQ 的分层 Q-Learning 概念,并表明它比单独的 Q-Learning 能产生更好的结果。为了使分层Q-Learning的框架更加鲁棒,后来又有将R-MAX算法与MAXQ结合起来。
这种合并将基于模型的方法的安全探索维度添加到 MAXQ 中。在自动驾驶汽车领域,通常使用三层 HRL 结构来处理选项、低级动作,并使用 Q 网络来解决穿越路口的决策问题。与非分层方法相比,它们表现出更快的收敛速度和改进的结果。
为了进一步提高样本效率和奖励结构,又提出了状态注意力模型、混合奖励机制和分层优先经验回放。所有这些扩展都提高了样本效率,并产生了更好的结果。
B. 轨迹规划和预测工作
现有的轨迹规划工作包括经典的传统规划器和使用机器学习原理的规划器。自动驾驶规划中使用最先进的规划器是基于采样的 RRT。这种RRT 是通过在空间中构建树状结构来生成轨迹的。事实证明,RRT 适用于有障碍的环境,但可能无法收敛到最佳解决方案。
通过引入 RRT* 解决了这个问题,它显示了最佳收敛和更短的路线。引入的另一种方法是格子规划器,这些规划器能够纳入约束并产生可行的路径。经典规划器的另一种方法包括监督学习,它可以分为模仿学习和轨迹预测。使用深度模仿学习框架通过离线学习来学习城市场景的驾驶策略,同时还添加了一个安全控制器模块,提高了测试时的安全性。
对于轨迹预测而言,提出了一个名为 UrbanFlow 的系统,它包含从收集原始数据到最终处理轨迹的完整管道。使用 UrbanFlow 管道的初衷是根据人类驾驶员的驾驶行为进行轨迹预测,这使得自动汽车能够做出更好的决策。另一种在轨迹预测方面产生重大成果的方法是逆强化学习(IRL)。IRL 的工作原理是通过观察专家代理的最佳轨迹来提取奖励结构。通过建立在IRL方法的基础上,提出了一个通过整合运动学和环境来预测越野车辆轨迹的框架,以恢复奖励结构。
C. 变道工作
先前关于变道的工作包括使用经典控制方法和学习算法。在没有道路基础设施支持的情况下提出了变道问题的解决方案。主要通过自行车模型使用虚拟道路曲率将自车道连接到目标车道,从而引导自车执行车道变换。同时,还将转向角输入自行车模型,以估计目标车道的横向位置。另外,有算法针对变道情况提出了一种基于强化学习的方法。他们将通过 DQN 进行何时执行变道决策与用于轨迹生成和跟踪的 Pure Pursuit Tracking 算法相结合。这种提出的结构将机器学习技术与经典控制方法结合起来。另一项是使用学习来引入一种基于深度强化学习的方法,从而处理自车的速度和车道变换决策。这其中使用了 DQN 来训练速度和车道变换决策的策略。
算法详解
1、双重深度 Q 学习
Double Q-Learning 是最先进的深度 Q-Learning 算法的扩展。RL 中的 Q-Learning 算法用于使用 Q 函数π找到最佳动作选择策略,该函数用于最大化动作值函数 Q∗(s; a)。
深度 Q-Learning 使用神经网络,通过最小化预测动作值 Q 和目标动作值 Y Q 之间的损失函数来更新网络参数 θ。深度 Q-Learning 使用相同的值来选择和评估操作,这会导致评估结果偏高。
Double Deep Q-Learning 通过修改来自另一个具有不同权重的目标 Q0 网络的目标动作更新来解决高估问题,如下公式 1 所示。
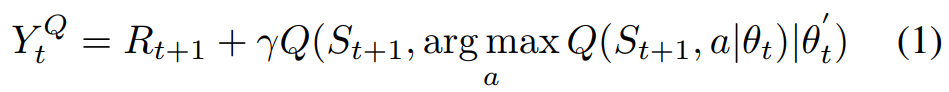
2、分层强化学习
分层强化学习HRL 在多层中进行模仿学习,从而生成对应的学习策略,如下公式中 Q1 为元控制器,主要是为后续步骤来生成子目标 g。控制器 Q2 则根据所选的子目标输出操作 a,直到元控制器生成下一个子目标。
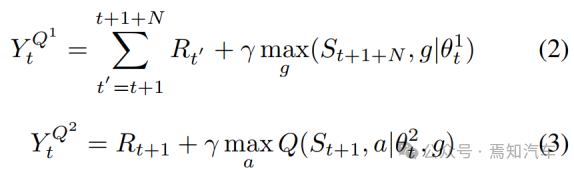
在本文中,我们选择了复杂性增加的城市变道场景。该方案的高级概述如图 1 所示,自车(绿色汽车)从自车道开始,需要进行变道,因为前面有一个障碍物(蓝色汽车)。但是目标车道具有动态的交通流。在这个例子中,使用两辆黄色的汽车来代表周围的交通。
这个场景可以很容易地分解为具有多个子目标的任务,这也解释了选择这个场景的原因。在这个问题中,为汽车提供了两个高级操作选项。第一种选择是车道跟随/等待,第二种选择是变道机动。所提出的HRL轨迹规划器的高级结构如图1所示。
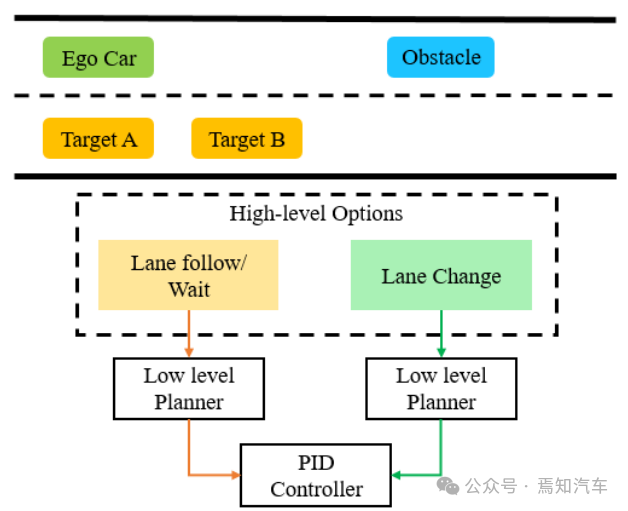
图 1. 分层结构有两个高级选项和每个高级选项的低级轨迹规划器
如上图表示了典型的比例积分微分 (PID) 控制器用于遵循规划的轨迹。考虑城市场景,自动驾驶汽车必须遵循车道或等待目标车道畅通才能执行车道变换操作。
对于每个高级选项,都有一个单独的低级轨迹规划器,且每个高级选项的低级规划器的详细描述可以在方法部分找到。
所提出的基于 HRL 的轨迹规划器主要包括两个特性:
1)规划安全平滑的轨迹:使用PID控制器来跟踪轨迹,而不是直接使用低级动作:油门、转向和制动。
2)处理噪声观测:在两个网络(高级选项网络和低级规划器网络)中使用长短期记忆LSTM 层,以帮助模型从一系列观测中学习,从而补偿缺失或错误的观测,并帮助自车可以在更加动态的环境中学习。
3、基于 HRL 的轨迹规划器
通过HRL分为两个高级选项(车道跟随/等待和变道),有助于自我汽车学习高级选项和低级轨迹规划者的策略。分层网络结构的细节如图 2 所示。
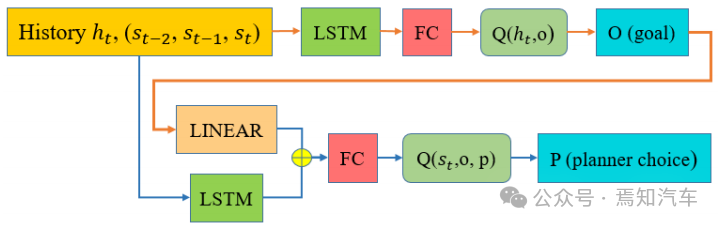
图2分层强化学习RL网络包括高层先择网络和低层规划网络
在图2中,两层网络中,长时记忆层a Long Short Term Memory (LSTM) 使用了之前固定的3步向量作为输入,同时,LSTM中使用了Tanh激活函数,选择网络的输出目标是基于历史向量输入到规划网络层来指定的。一个完整的功能连接层FC被每个网络用来做为最后一个层级。在功能连接层中,除了最后一层外,一个ReLU激活函数将被用于生成每个网络层的输出值。
选择高级选项后,低级轨迹规划器将通过网络策略选择最终轨迹预测点。选择基于自车的状态信息,通过epsilon-greedy策略。一旦选择了最终轨迹预测点,就会使用它可以具有的最大加速或减速来计算自车的目标速度,以确保子轨迹平稳。
然后,将目标速度和最终航点值提供给 PID 控制器,PID 控制器进而产生纵向和横向控制。这些子轨迹共同形成了一个完整的轨迹,其中包括车道跟随和变道操作。算法 1 显示了基于 HRL 的轨迹规划器的详细工作,包括训练细节。
分层轨迹规划器算法如下:
Step1:设置权重值θ0,θp用于初始化选择与权重网络Q0,Qp;
Step2:设置权重值θ0’,θp’用于初始化选择与权重网络Q0,Qp;
Step3:构建Buffer B,用于存储如下最长时记忆经验值lb;
Step4:运行100个基于规则的视频集存储经验值到Buffer B中;
Step5:对于第101至E训练集执行如下操作:
Step6:获得初始状态s;
Step7:初始化包含3个时间步骤的历史向量ht;
Step8:如果s不在最终状态,则设置Ot=argmax0,Q(ht)是基于ε-greedy,Ot是选项;
Step9:设置Pt=argmaxpQ(ht,Ot),Q(ht,Ot)是基于ε-greedy,Pt是规划器的路径点选择;
Step10:基于目标点Ot和规划器选择点Pt来获得路径选点Wt。
Step11:基于Wt计算目标速度值V;
Step12:纵向控制Throttle = PIDlongitudinal(u, v),其中u是当前速度,v是最终速度;
Step13:转向控制Steer = P IDlateral(wc, wt),wc为当前路径选点,wt为目标路径选点;
Step14:在仿真环境中,对子路径运行同样的步骤,获得,其中ro为选择奖励,rp为规划奖励;
Step15:最终通过将st+1列队到ht中,从而获得ht+1;
Step16:存储期间变化的要素T到缓存Buffer B中,其中T表示为;
Step17:重新运行缓存Buffer B,得到最终的训练值。
1)车道跟随/等待:一旦自我汽车选择了车道跟随/等待选项,就会使用低级轨迹规划器来规划路径。低级规划器有三种轨迹选择,如图 3 中的彩色线所示。绿线代表自车可以沿着车道行驶更长距离的选择。当自车在其自车道中当前位置的一定半径内没有观察到任何障碍物时,这种选择会得到相应的奖励。
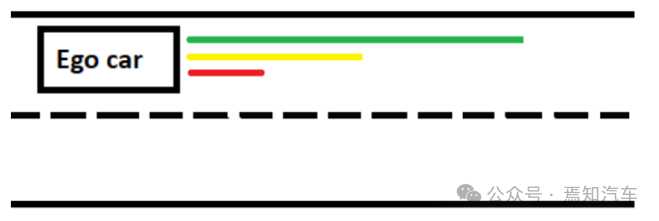
图 3.车道跟随/等待选项概述
黄线代表一种轨迹选择,在该轨迹下,自车可以沿着车道行驶更短的距离。当自车在一定距离内观察到自车道上的障碍车并希望避免靠近它时,这种选择是有益的。另一方面,如果自车选择红线轨迹,它将减速到等待选项或较慢的速度。选择轨迹后,将使用 PID 控制器完成规划的路径。
2)变道:一旦决定进行变道,就会通过epsilongreedy策略使用自车的状态信息选择目标车道上的航点。图 4 中所示,每个不同的最终航点代表自车可能选择进行变道的不同速度曲线。这确保了在规划变道操作时的平稳性和稳定性。
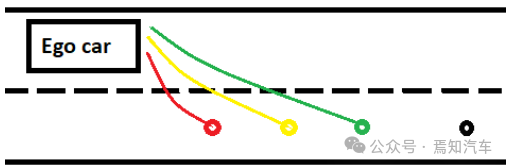
图4 自动变道选择轨迹线描述
如果由于车道速度较高,因此需要自动驾驶汽车进行更快的变道,则选择绿点。黄点表示正常速度剖面轨迹。红点选择有助于自车进行更急转弯,当自车的速度较小或处于等待选项时,可能需要这样做。RL通过变道高级选项下的低级规划网络在三点之间选择一个点。一旦策略选择了该点,就会在目标通道中的某个距离处生成一个黑点。这个黑点是一个安全跟随点,它有助于自车在再次激活车道跟随/等待选项之前重新定位自己。黑点的生成基于自车在执行变道后与前车的距离。
4、处理嘈杂状态下的观测值
为了让本算法的模型考虑嘈杂的观测值,需要在两个网络中都添加了一个长时网络记忆 层LSTM :其中包括高级选项和低级规划器网络。分层网络结构的详细信息如图 2 所示,其中,使用了三个时间步长作为 LSTM 层的输入。为了从重放视频记忆中提取对应的经验,并使用了提出的自举随机更新方法。该策略从经验回放中提取的一批剧集,并从中随机采样 n 步序列,然后训练神经网络。
5、状态空间
为了为我们的层次结构制定状态空间,需要在给定场景中使用来自自车(e)、障碍车 (o)、目标汽车 A(a)和目标汽车B(b)的信息,这可以从下面给出的元组中看出。对于停止或障碍车辆,自车的安全范围为 x >= 16,对于移动车辆,x >= 9,其中 x 是自车与其他车辆的距离,以米为单位。状态空间由 14 个参数组成,元组包含各类状态信息。
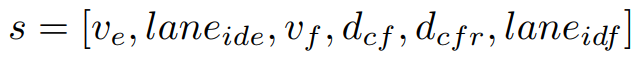
ve = 自车速度
laneide = 自车道 ID
vf = 障碍车和目标车的速度
dcf = 自车道中与障碍车的追逐距离和目标车道中移动车辆的追逐距离
dcfr = 追逐距离与安全阈值之比
laneidf = 障碍车和目标车辆的车道 ID
6、奖励结构
奖励结构由单独的高级期权奖励和低级轨迹选择奖励组成。在每个时间步中,考虑到自车(e)、障碍车(o)、移动汽车A(a)和移动汽车B(b),则可以给出以下惩罚和奖励:
常规时间步长惩罚:−σ1
向最终目的地前进的常规时间步长奖励:σ2
碰撞惩罚:−σ3
不安全惩罚:exp −(dcfr),其中 f 2 fo;一个;BG公司
进球不需要的点球:−σ4
不平滑度惩罚 −σ5
成功奖励 σ6
自车会因为选择错误的高级选项或选择错误的低级轨迹选择而受到单独惩罚。如果选择的轨迹导致子目标无法成功完成,则低级选择会受到惩罚,在我们的例子中,这意味着与目标汽车或障碍车之一发生碰撞。此外,为了规划更安全、更平稳的轨迹,如果不需要低级选择,就会受到惩罚。例如,在选项 1 下,如果选择低级等待选项显得没有必要性,则该选项也会受到惩罚。
随着自车与其他车辆的安全距离逐渐减少,自车受到的惩罚将不断增大。安全距离是自车必须与障碍车或移动车辆保持的最小距离。如果自车在一定距离内没有看到自车道上的任何障碍物,则预计它会规划更长的轨迹。对于变道动机,自车会根据其过去的速度曲线选择最安全的点来获得奖励。例如,如果自车在目标车道上有更高的速度,那么它就会得到更高的奖励来更快地变道。否则,如果自车就会在自车道上进行等待,且会进行较慢的转弯估计。以上这些形式策略就很好的总结了不平滑度惩罚的原理,即这些不同的低级点选择可以防止旁边车辆的车道入侵和或者自车行驶可能带来的行驶混乱。
总结
本文介绍的方法的使用对于轨迹规划这类强化学习框架更加稳健。拟议的轨迹规划 HRL 框架为自动驾驶汽车提供了两个高级选项,并为每个高级选项提供了三个低级规划器选择。每个低级规划器需要根据所选的高级选项和自车的状态信息(主要是其速度曲线和与其他车辆的距离)来选择路点。HRL 模块化结构确保了所学策略的可重用性,并表现出更快的收敛速度。
通过有效的模型构建,使用 PID 控制器来跟踪低级规划器选择的航路点,从而通过对PID 进行轨迹跟踪,实现稳定的操纵,从而减少了紧急制动和紧急转向的概率。此外,该算法在分层网络结构中添加了长时记忆层 LSTM ,可以有效的缓解观测不完整或不准确以及动态环境的问题。
欢迎扫下面二维码加入智能交通技术群!

扫描加入免费的「智慧城市之智慧交通」知识星球可了解更多行业资讯和资料。
欢迎加入智能交通技术群!
联系方式:微信号18515441838
智能推荐
图解unicode、utf8和utf8mb4_utf-8 unicode (utf8mb4)-程序员宅基地
文章浏览阅读10w+次,点赞6次,收藏6次。字符集和字符编码字符集(CCS: Coded Character Set):就是一个表格,表示每个字符对应数字(通常用16进制表示),比如unicode字符集中,数字1对应的就是U+00031,字母a对应的就是U+00061。字符编码(CEF:Character Encoding Form):因为计算机只认识0和1,所以计算机在存储字母a(U+00031)的时候,不能直接存储。所以就需要编码将字母a转换成01表示形式。对于unicode字符,utf8就是它的编码方案(如何utf8转换成01表示下._utf-8 unicode (utf8mb4)
sy-index和sy-tabix的区别_sap sy-tabix-程序员宅基地
文章浏览阅读2.4k次。通过这个程序,让我清楚的知道了sy-index和sy-tabix的区别。sy-index 是系统变量,在sap系统里的描述是:Loop Index-->这里我理解loop仅仅是循环的意思,并不是sap abap中loop。也就是说sy-index只是记录程序当前循环的次数,但是,对于sap abap中的loop循环sy-index是无效的,值是0.sy-tabix 在sap系统里的_sap sy-tabix
python如何舍去个位上的数字,输出呢?_去diao个位数python-程序员宅基地
文章浏览阅读1.2k次。任意输入一个三位数,在最后舍去个位上的数字输出_去diao个位数python
logback标签说明_logback中logger标签对应的name-程序员宅基地
文章浏览阅读460次,点赞6次,收藏5次。logback的配置,需要配置输出源appender,打日志的logger(子节点)和root(根节点),实际上,它输出日志是从子节点开始,子节点如果有输出源直接输入,如果无,判断配置的additivity,是否向上级传递,即是否向root传递,传递则采用root的输出源,否则不输出日志。鉴别器,常用的鉴别器是JaninoEventEvaluato,也是默认的鉴别器,它以任意的java布尔值表达式作为求值条件,求值条件在配置文件解释过成功被动态编译,布尔值表达式返回true就表示符合过滤条件。_logback中logger标签对应的name
asp.net 基本控件_asp.net控件-程序员宅基地
文章浏览阅读1k次,点赞16次,收藏17次。最经典的图标按钮就是Windows的最小化、最大化、关闭、前进后退、刷新按钮。属性:纯图标按钮的形状本身就具有很形象的解释力,光标悬浮在按钮上时经常会弹出更详细的说明信息框,用来具体解释此按钮实现的功能。点击命令按钮产生的响应有弹出新窗口、弹出框体、弹出新页面、切换或弹出菜单(结合菜单栏)、弹出列表框(结合下拉列表)、刷新、放大/缩小/收起/关闭窗口等等。属性:纯图片按钮就是一张图片可以点击产生响应,不同于图标按钮,图片更有预览意义,图片内容不代表功能,同一功能可能因为场景、对象不同而图片内容不同。_asp.net控件
Python图像处理库PIL的滤波_ImageFilter_简述pil对图像进行滤波处理有哪些滤波器?-程序员宅基地
文章浏览阅读4.4k次,点赞10次,收藏36次。 Python图像处理库PIL的滤波_ImageFilterImageFilter模块提供了滤波器相关定义;这些滤波器主要用于Image类的filter()方法。一、ImageFilter模块所支持的滤波器当前的PIL版本中ImageFilter模块支持十种滤波器:1、 BLURImageFilter.BLUR为模糊滤波,处理之后的图像会整体变得模糊。..._简述pil对图像进行滤波处理有哪些滤波器?
随便推点
OpenCV图像全景拼接-黑边处理(C++)_c++中opencv去除图片黑边-程序员宅基地
文章浏览阅读929次。1、直接使用3通道的原图查找边界点,不再转换成灰度图及二值化图像,提高效率。应用范围也是和之前类似,夜景图片效果会不好。这个修改可以提高部分性能。2、第一次找到对角非全黑点后,会尝试往回找,尽量增大可用面积。具体说明参照上述资料。_c++中opencv去除图片黑边
理解IO流的使用C/C++_std::istream 输入流-程序员宅基地
文章浏览阅读166次。IO标准库学习,文件流ofstream与ifstream的使用详细。_std::istream 输入流
系统架构:Kubernetes Operator 的架构设计解析_operator-sdk的架构-程序员宅基地
文章浏览阅读534次,点赞29次,收藏17次。CRD 允许在 Kubernetes 中定义新的资源类型。Operator 通过这些自定义资源来管理应用特有的配置和状态。自定义控制器是 Operator 的核心,用于观察、调节和维护 Kubernetes 集群中的自定义资源。
Error during filtering com.netflix.zuul.exception.ZuulException: Filter threw Exceptions错误解决-程序员宅基地
文章浏览阅读1.4w次。启动项目的微服务组件的时候,总是在微服务的网关那出现这个错误Error during filtering com.netflix.zuul.exception.ZuulException: Filter threw Exception查阅了网上资料:原因可能是有一些请求的请求时间太长,触发了熔断器导致。解决方案:在yml配置文件上加上即可,如果还是不行,把熔断时间、连接超时时间、通信超时时间都改大即可。ribbon: ConnectTimeot: 10000 # 连接超时时间(ms) Rea
浅谈Canvas与SVG_canvas svg 缩放 性能-程序员宅基地
文章浏览阅读3.5k次,点赞2次,收藏5次。1、SVGSVG 可缩放矢量图形(Scalable Vector Graphics),是一种使用可扩展标记语言(XML)描述2D图形的语言。SVG严格遵从XML语法,并用文本格式的描述性语言来描述图像内容,因此是一种和图像分辨率无关的矢量图形格式。SVG基于XML,意味着SVG DOM中的每个元素都是可用的,可以为某个元素附加 JavaScript 事件处理器。在SVG中,每个被绘制的_canvas svg 缩放 性能
STM32 MFRC522 IC读卡 程序及原理图_rc522电路原理图-程序员宅基地
文章浏览阅读6.9k次,点赞3次,收藏41次。https://blog.csdn.net/cxw312864660/article/details/89384584【RC522芯片简介】 MF RC522是应用于13.56MHz非接触式通信中高集成度的读写卡芯片,是NXP公司针对“三表”应用推出的一款低电压、低成本、体积小的非接触式读写卡芯片,是智能仪表和便携式手持设备研发的较好选择。 MF RC522利用了先进的调制和解调概念,完..._rc522电路原理图