【计算机视觉 | 语义分割】综述 | 语义分割经典网络及轻量化模型盘点_语义分割模型-程序员宅基地
基于图像的语义分割又被理解为密集的像素预测,即将每个像素进行分类,这不仅仅对于算法是一个考验,而且对于硬件的计算性能也有很高的要求。
因此,本文从两方面着手考虑,一方面是基于语义分割经典网络的介绍,向大家展示语义分割方向上的,经典的网络模型。另一方面,从计算的性能入手,向大家介绍一下语义分割方向的轻量化模型。
文章目录
一、经典语义分割模型
1.1 全卷积神经网络(FCN)
论文地址:
https://arxiv.org/abs/1411.4038
代码实现地址:
https://github.com/MarvinTeichmann/tensorflow-fcn[Tensorflow]
FCN神经网络作为深度学习中,语义分割网络的经典之作,是必须要理解和掌握的一个网络结构,它借鉴了传统的分类网络结构,而又区别于传统的分类网络,将传统分类网络的全连接层转化为卷积层。然后通过反卷积(deconvolution)进行上采样,逐步恢复图像的细节信息并扩大特征图的尺寸。
在恢复图像的细节信息过程中,FCN一方面通过可以学习的反卷积来实现,另一方面,采用了跳跃连接(skip-connection)的方式,将下采样过程中得到的特征信息与上采样过程中对应的特征图相融合。
虽然从目前的研究来看,FCN存在着诸如语义信息丢失,缺乏对于像素之间关联性的研究,但是FCN引入了编码-解码的结构,为深度学习在语义分割方向上的应用打开了一扇大门,也为后续的研究做出了许多借鉴之处。
FCN-8s在VOC-2012上的准确率如下图所示:

1.2 SegNet
论文地址:
https://arxiv.org/abs/1511.00561
代码实现地址:
https://github.com/tkuanlun350/Tensorflow-SegNet[Tensorflow]
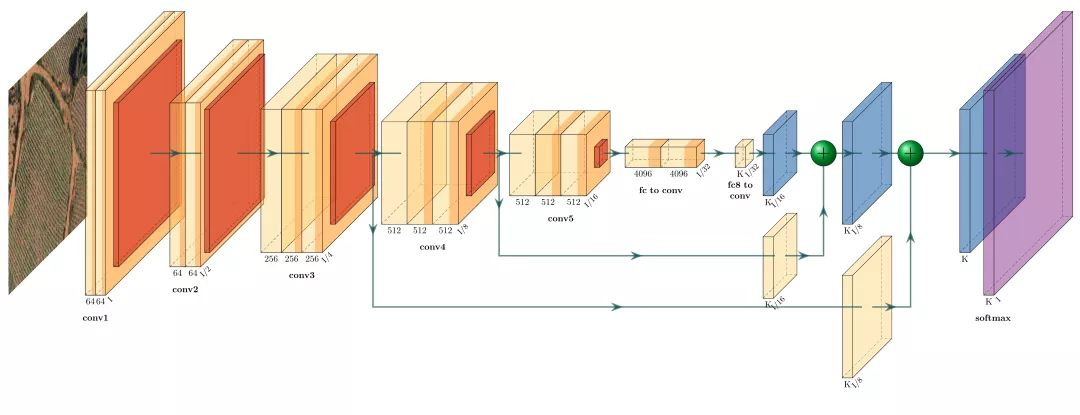
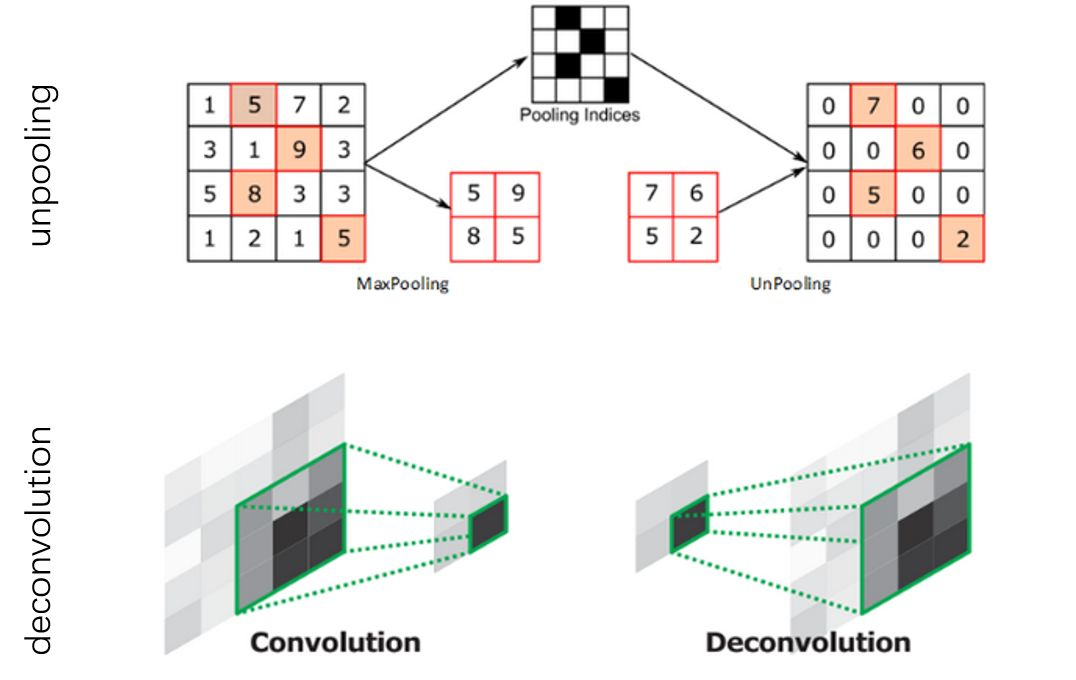
SegNet采用了FCN的编码-解码的架构,但是与FCN不同的是,SegNet没有使用跳跃连接结构,并且在上采样的过程中,不是使用反卷积,而是使用了unpooling的操作。
SegNet相较于FCN有了两点的改进。第一,由于unpooling不需要进行学习,所以相比于FCN,SegNet的参数数量明显下降,从而降低了计算量。第二,由于SegNet在解码器中使用那些存储的索引来对相应特征图进行去池化操作。从而保证了高频信息的完整性,但是对于较低分辨率的特征图进行unpooling时,同样会忽略像素近邻之间的信息。
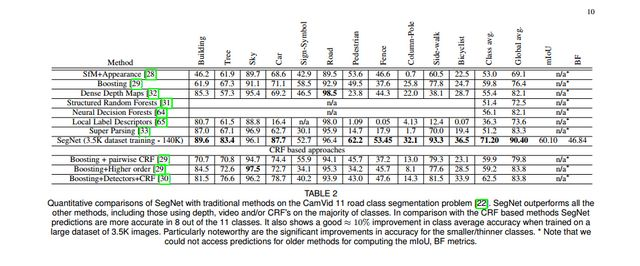
SegNet在CamVid数据集上的测试结果如下图所示:
1.3 Deeplab系列
deeplab系列是由Google团队设计的一系列的语义分割网络模型。是一个不断进化改进的过程,通过阅读deeplab系列的论文,理解作者一步步的改进思路,无论对于文章的理解,还是设计我们自己的网络结构,都有很大的帮助。
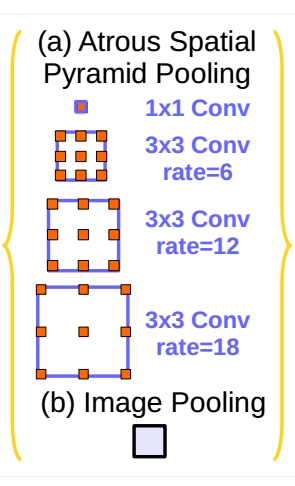
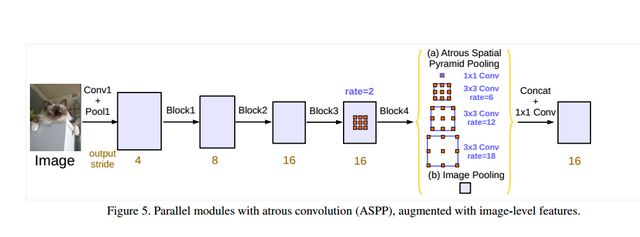
deeplabv1的设计亮点在于,采用了空洞卷积和CRF的处理。利用空洞卷积在不增加参数的情况下扩大了感受野的范围。而CRF的后期处理可以更好的提升语义分割的准确率。deeplabv2在v1的基础之上增加了ASPP(空洞空间金字塔池化)模块。如下图所示:

通过不同尺度的空洞率来提取不同尺寸的特征,更好的融合不同的特征,达到更好的分割效果。
deeplabv3的创新点有两个,一个是改进了ASPP模块,第二个是参考了HDC的设计思想,也就是横纵两种结构。对于改进的ASPP模块,如下图所示。
对比于v2的ASPP模块,可以发现V3的ASPP模块增加了一个1x1的卷积和全局池化层。对于ASPP模块的构建,作者采用了“纵向”的设计方式,如下图所示:
与”纵向“向对应的是”横向“的设计,如下图所示:

作者将conv4的结构连续复制了3次,后面的每一个block块都有一个基础的空洞率,而在每一个block块里面,作者又参考了HDC的思想,将卷积层的空洞率设计为[1,2,1]的形式。这里的[1,2,1]设计模式是作者经过试验得到的最好设计结构。deeplabv3+的设计相较于v3有两点改进,第一点是解码的方式,第二点是采用改进后的xception网络作为backbone。下图是deeplabv3+原文中对于v3和v3+以及编码-解码结构的模型对比。
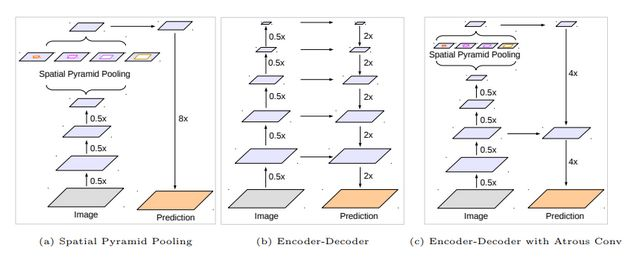
deeplabv3+文章中使用了两种backbone,分别是Resnet101和改进后的xception网络。通过文章中的实验对比,以改进后的xception作为backbone效果要优于Resnet101。
deeplab的官方也发布过一个ppt,讲述的是deeplab v1,v2和v3的主要区别,大家可以从ppt中获取到更多的信息。下载链接:
http://web.eng.tau.ac.il/deep_learn/wp-content/uploads/2017/12/Rethinking-Atrous-Convolution-for-Semantic-Image-Segmentation-1.pdf。
deeplabv1论文地址:
https://arxiv.org/abs/1412.7062
deeplabv2论文地址:
https://arxiv.org/abs/1606.00915
deeplabv3论文地址:
https://arxiv.org/abs/1706.05587
deeplabv3+论文地址:
https://arxiv.org/abs/1802.02611
deeplabv3 代码实现地址:
https://github.com/rishizek/tensorflow-deeplab-v3[Tensorflow]
deeplabv3+ 代码实现地址:
https://github.com/rishizek/tensorflow-deeplab-v3-plus[Tensorflow]
1.4 RefineNet
论文地址:
https://arxiv.org/abs/1611.06612
代码实现地址:
https://github.com/eragonruan/refinenet-image-segmentation[Tensorflow]
RefineNet提出了一种多路径的提炼网络,通过使用远距离的残差连接,尽可能多的利用下采样过程中的信息。从而得到高分辨率的预测图。文章通过细心的设计RefineNet模块,通过链式残差池化(CRP)来融合上下文信息,将粗糙的深层特征和细节特征进行融合。实现了端到端的训练。文章针对于目前语义分割存在的问题进行改进。
目前的分割算法采用降采样使得很多的细节信息丢失,这样得到的结果较为粗糙。而针对于这种情况,文章的Introduction部分介绍了目前的主要改进方式。
- 利用反卷积来进行上采样,产生高分辨率的特征图。但是反卷积不能恢复低层的特征,因为这部分信息在下采样的过程中已经丢失,已经不可能找回(这里我想添加一点自己的理解,例如32倍的下采样,那么理论上小于32x32像素的目标将会丢失,而丢失的目标无论怎样反卷积都不会被找回,因为下采样的特征图中没有包含该目标的任何信息)。
- 利用空洞卷积。利用空洞卷积来产生较高分辨率的特征图,这样的操作不会带来额外的参数,但是由于特征图的分辨率增加,会造成巨大的计算和存储资源的消耗,因此deeplab输出的尺寸只能是输入尺寸的1/8甚至更小。而且,由于空洞卷积只是对于特征图的粗略采样,还是会存在潜在的重要细节信息的丢失。
- 利用中间层的信息。例如FCN网络的跳跃连接。但是还是缺少较强的空间信息。文章作者认为各层的信息对于分割都是有用的。高层特征有助于类别识别,低层特征有助于生成精细的边界。如何有效的利用各个层的信息非常的重要。
作者围绕如何有效的利用各个层的信息,设计了RefineNet网络结构,如下图所示:
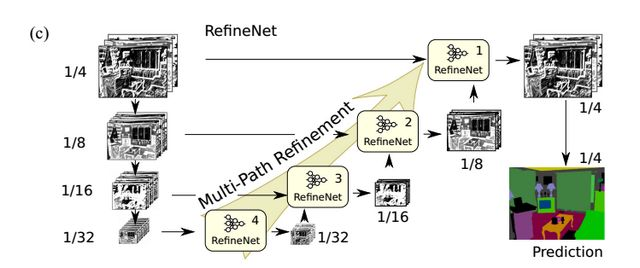
该网络将不同分辨率的特征图进行融合,通过上图左侧的ResNet101预训练模型,产生四个分辨率的特征图,然后将四个特征图分别通过对应的RefineNet block模块进行进行融合。由上图也可以看出,除了RefineNet-4模块外,其余的RefineNet block都是有两个输入,用于不同尺寸特征图的提炼融合。RefineNet block的细节图如下所示。
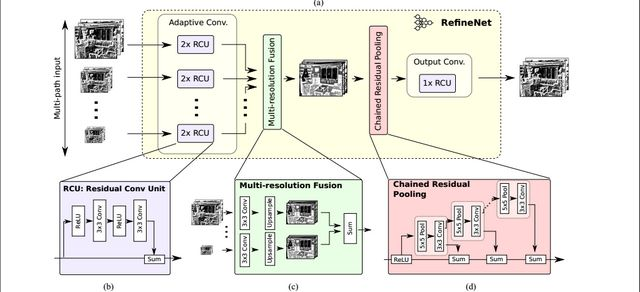
主要的组成部分包括Residual convolution unit(RCU,残差卷积单元), Multi-resolution fusion(MRF,多分辨率融合),Chained residual pooling(CRP,链式残差池化)和最后的Output convolutions(输出卷积 )。其中各个部分的作用为:
- RCU:该部分用来作为一个自适应卷积集,主要是微调ResNet的权重。
- MRF:从名字可以看出,该部分是将所有的输入特征图的分辨率调整为最大特征图的分辨率尺寸。
- CRP:通过链式残差池化部分,可以有效的捕捉上下文信息。
- 输出卷积:在最终的输出之前,再加一个RCU。
RefineNet再VOC2012数据集上的测试结果如下图所示:
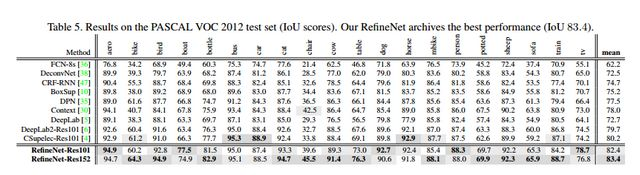
1.5 PSPNet
论文地址:
https://arxiv.org/abs/1612.01105
代码实现地址:
https://github.com/hellochick/PSPNet-tensorflow[Tensorflow]
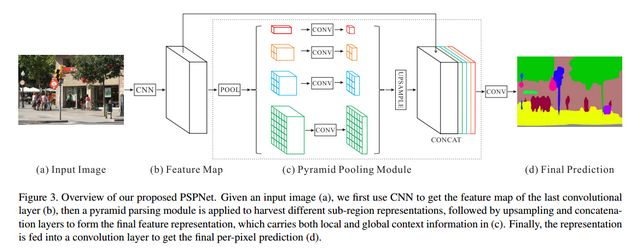
PSPnet全称为Pyramid Scene Parsing Network ,它采用的金字塔池化模块,来融合图像的上下文信息,注重像素之间的关联性。如何理解像素之间的关联性和图像中的上下文信息呢?比如我们看到了一个物体,由于拍摄角度,光线等问题,很难从物体本身来分别它究竟是条船还是一辆小汽车。但是我们知道船在水里,而车在路上,因此,结合物体所处的周围环境信息,就能很好的分辨这个物体是什么了。PSPnet利用预训练模型提取特征后,将采用金字塔池化模块提取图像的上下文信息,并将上下文信息与提取的特征进行堆叠后,经过上采样得到最终的输出。而特征堆叠的过程其实就是讲目标的细节特征和全局特征融合的过程,这里的细节特征指的是浅层特征,也就是浅层网络所提取到的特征,而全局特征指的是深层的特征,也就是常常说的上下文特征。对应的就是深层网络提取的特征。
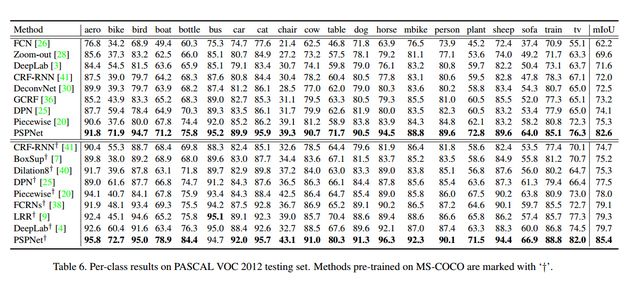
PSPNet在VOC2012上的测试结果如下图所示:
二、轻量化模型
以上介绍的是近些年来的深度学习领域中语义分割方向比较经典的文章,上述的文章注重的是分割准确率的提升,但是在计算速度上并不是很出色。下面为大家介绍的是语义分割领域的轻量化模型。轻量化模型在注重计算的速度的同时,也保证了分割的准确率。
2.1 ENet
论文地址:
https://arxiv.org/abs/1606.02147
代码地址:
https://github.com/kwotsin/TensorFlow-ENet[Tensorflow]
ENet是基于SegNet改进的实时分割的轻量化模型,相比于SegNet,ENet的计算速度提升了18倍,计算量减少了75倍,参数量减少了79倍。并且在CityScapes和CamVid的数据集上,ENet的效果都要好于SegNet。ENet作为轻量化模型,设计的初衷就是如何最大限度的减少计算量,提升计算速度。ENet的网络架构如下图所示。
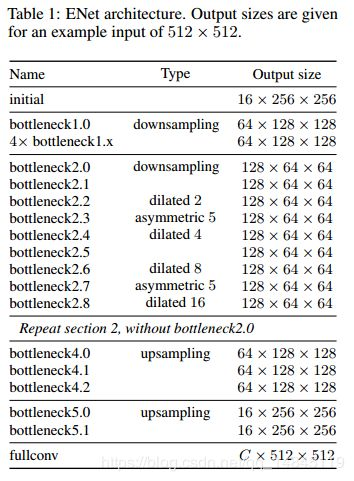
其中initial block 和bottleneck分别如下所示。
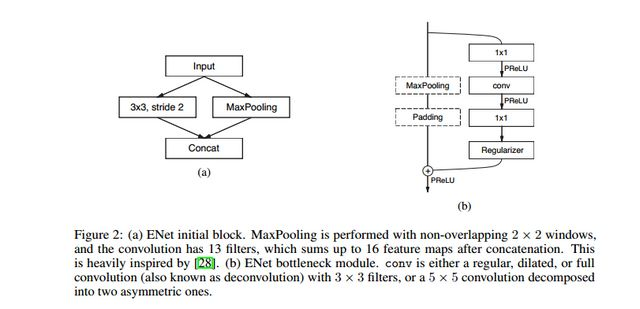
从提升网络的计算速度来看,文章主要有以下几点改进。
- 在Initial Block中,文章将pooling操作和卷积操作并行,然后堆叠到一起,这将Initial Block的inference时间加速了10倍。
- ENet的前两个block大大的降低了输入图像的尺寸,而且只用了很少的特征图。而作者这样做的原因是考虑到视觉信息在空间上是高度冗余的,可以压缩成更有效的表示方式。
- ENet网络将nxn的卷积核拆分为nx1和1xn的卷积核,从而有效的减少了参数量和计算量。
从提升网络的准确率来看,文章主要有以下的几点改进。
- ENet去除了初始几层的大部分的Relu激活函数,实验发现可以提高网络的准确性。
- 在下采样的过程中,ResNet的block会采用stride为2的1x1卷积,这会造成75%的输入信息丢失,ENet采用处理方法是将卷积核改为2x2大小,使得卷积核能覆盖整个输入,从而有效的改善了信息的流动和准确率。
- 文章使用了空洞卷积,实验证明在Cityscapes数据集上Iou有了4%左右的提升。
- ENet在卷积层后面使用Spatial Dropout,可以获得比stochastic depth和L2 weight decay更好的效果。
2.2 ICNet
论文地址:
https://arxiv.org/abs/1704.08545
代码实现地址:
https://github.com/hellochick/ICNet-tensorflow[Tensorflow]
ICNet是针对于高分辨率图片的实时分割模型,网络设计的目标是能够快速分割,同时保证一个合适的准确率。ICNet采用了多尺度的图像输入,首先让低分辨率的图像经过一个Heavy CNN,得到较为粗糙的预测特征图,然后提出了级联特征融合单元和级联标签指导的策略,来引入中、高分辨率的特征图,逐步提高精度。整个网络的结构如下图所示。
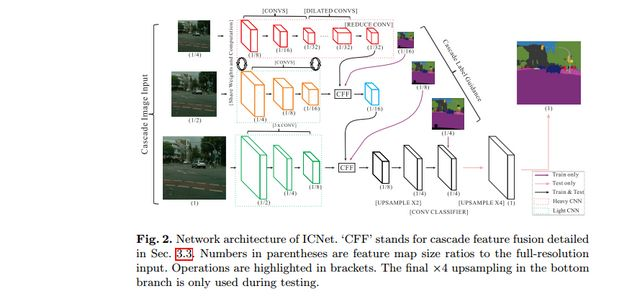
该网络结构十分有趣,值得学习,对于较低分辨率的输入图像,ICNet采用Heavy CNN来提取网络的特征,这里的Heavy CNN可以看作是计算量较大的编码器。而针对于中、高分辨率的输入图像而言,ICNet采用的网络层数以此减少,这样,虽然较低分辨率的输入图像经过了最深层的网络结构,但是由于其分辨率较小,因此计算量也受到了限制。而较高分辨率的输入图像,则是采用较浅的网络结构,计算量同样得到降低。这样,就利用了低分辨率图片的高效处理和高分辨率图片的高推断质量。而这也恰恰是ICNet和其他cascade structures网络结构不同的地方,虽然也有其他的网络从单一尺度或者多尺度的输入融合不同层的特征,但是其他的网络都是采取的是所有的输入经过相同的网络,这就会造成计算量的加大,从而使得计算的速度大大降低。
上图中的CFF(cascade feature fusion unit) 就是级联特征融合单元。如下图所示。
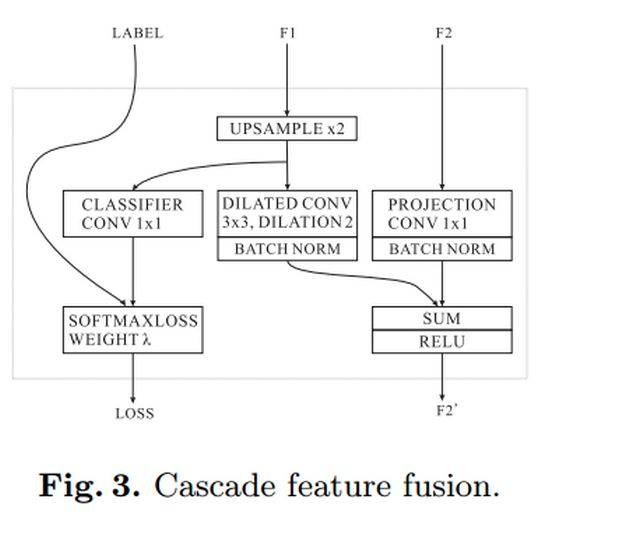
CFF模块用来融合不同分辨率的输入,与反卷积相比,CFF使用二线性插值上采样+空洞卷积的组合只需要更小的卷积核来获取相同大小的感受野,而且空洞卷积可以整合相邻像素的特征信息,而直接上采样使得每个元素变得相对孤立,缺少了像素与周围像素之间的关联。
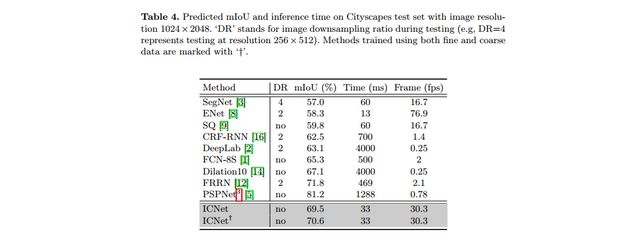
ICNet在Cityscapes数据集上的表现如下图所示。
2.3 CGNet
CGNet网络的核心架构是文章提出的CG模块,也就是上下文指导模块。CG模块能够学习局部特征和周围环境上下文的联合特征,并通过引入全局上下文特征进一步改善联合特征。文中指出CG模块的四个优势,分别是:
- CG模块能够学习局部特征和周围环境上下文的联合特征。
- CG模块利用全局上下文来提高联合特征。其中,全局上下文用来逐通道的对于特征图的权重进行调整,以此来突出有用的部分,而压制没有用的部分(这里可以通过阅读SENet的文章,来进一步的理解)。
- CG模块被用在了CGnet的所有阶段,因此CGNet可以从语义层(深层网络)或者空间层(浅层网络)来获取上下文信息,区别于PSPNet、DFN等网络,这些网络这是在编码之后获取上下文特征。
- CGNet只应用了三个下采样,因此能够更好的保留空间信息。
CGNet的网络结构如下图所示。
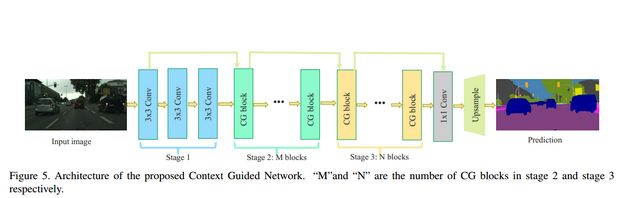
CGNet的网络架构遵循了“深而浅”的原则,整个网络只有51层。并且CG模块采用的是逐通道卷积(channel-wise convolutions)的方式。从而降低了计算的成本。
CG模块的结构如下图所示。
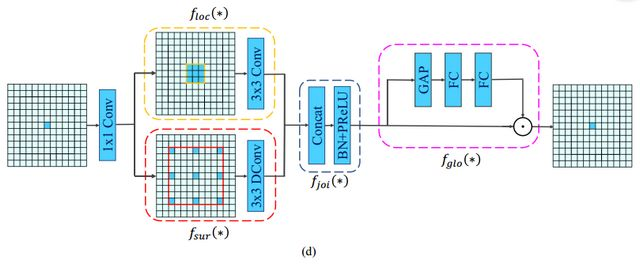
CG模块还采用了残差学习来学习高复杂度的特征并在训练期间改善梯度反向传播。文中提出了两种方式,分别为局部残差学习(LRL)和全局残差学习(GRL)。LRL将输入和联合特征提取器进行连接,GRL则是将输入和全局特征提取器进行连接。从直观上来说,GRL比LRL更能促进网络中的信息传递,而文章后面的实验也证明,GRL更能提升分割精度。
三、总结
以上总结是基于深度学习中语义分割领域的经典算法和轻量化模型。随着技术的发展和硬件条件的不断进步,基于像素级别的分割才是图像分类的主流方向。从FCN至今的短短几年,语义分割技术已经取得了很大的发展,越来越多的新颖的技术不断的被提出。小编总结了最近几年的文章,总结了一下未来的语义分割发展方向,仅供大家参考。
- 引入自注意模型。自注意力模型最早的应用是在自然语言处理方面。后来慢慢引入到计算机视觉领域,例如在图像识别领域,注意力模型可以让深度学习模型更加关注某一些局部的关键信息。在CGNet中,同样也引入了注意力模型,来调整特征图的权重,从而更加有效的区分和利用各个特征。
- 无监督/弱监督的语义分割。由于语义分割是基于像素级别的分类,而传统的有监督的语义分割需要大量的训练数据集,这就需要花费大量的人力物力去制作标签数据集,而且由于针对的场景不同,采集到的数据集也不一样,这就会造成大量的繁重的数据集标签制作。因此,基于弱监督的语义分割也自然成为了研究的热门趋势。近年来,基于弱监督的语义分割文章也越来越多。
- 轻量化网络。在现有的计算条件下,虽然准确率已经能够达到很好的表现,但是在计算速度上却不尽如人意,语义分割技术的落地实现,需要提高分割模型的计算速度。一方面,可以采用模型压缩、模型加速的方式来解决。另一方面,也可以从模型本身入手,设计轻量化模型,在尽可能不损失准确率的情况下,提高模型的计算速度。
智能推荐
如何配置filezilla服务端和客户端_filezilla server for windows (32bit x86)-程序员宅基地
文章浏览阅读7.8k次,点赞3次,收藏9次。如何配置filezilla服务端和客户端百度‘filezilla server’下载最新版。注意点:下载的版本如果是32位的适用xp和win2003,百度首页的是适用于win7或更高的win系统。32和64内容无异。安装过程也是一样的。一、这里的filezilla包括服务端和客户端。我们先来用filezilla server 架设ftp服务端。看步骤。1选择标准版的就可以了。 _filezilla server for windows (32bit x86)
深度学习图像处理01:图像的本质-程序员宅基地
文章浏览阅读724次,点赞18次,收藏8次。深度学习作为一种强大的机器学习技术,已经成为图像处理领域的核心技术之一。通过模拟人脑处理信息的方式,深度学习能够从图像数据中学习到复杂的模式和特征,从而实现从简单的图像分类到复杂的场景理解等多种功能。要充分发挥深度学习在图像处理中的潜力,我们首先需要理解图像的本质。本文旨在深入探讨深度学习图像处理的基础概念,为初学者铺平通往高级理解的道路。我们将从最基础的问题开始:图像是什么?我们如何通过计算机来理解和处理图像?
数据探索阶段——对样本数据集的结构和规律进行分析_数据分析 规律集-程序员宅基地
文章浏览阅读62次。在收集到初步的样本数据之后,接下来该考虑的问题有:(1)样本数据集的数量和质量是否满足模型构建的要求。(2)是否出现从未设想过的数据状态。(3)是否有明显的规律和趋势。(4)各因素之间有什么样的关联性。解决方案:检验数据集的数据质量、绘制图表、计算某些特征量等,对样本数据集的结构和规律进行分析。从数据质量分析和数据特征分析两个角度出发。_数据分析 规律集
上传计算机桌面文件图标不见,关于桌面上图标都不见了这类问题的解决方法-程序员宅基地
文章浏览阅读8.9k次。关于桌面上图标都不见了这类问题的解决方法1、在桌面空白处右击鼠标-->排列图标-->勾选显示桌面图标。2、如果问题还没解决,那么打开任务管理器(同时按“Ctrl+Alt+Del”即可打开),点击“文件”→“新建任务”,在打开的“创建新任务”对话框中输入“explorer”,单击“确定”按钮后,稍等一下就可以见到桌面图标了。3、问题还没解决,按Windows键+R(或者点开始-->..._上传文件时候怎么找不到桌面图标
LINUX 虚拟网卡tun例子——修改_怎么设置tun的接收缓冲-程序员宅基地
文章浏览阅读1.5k次。参考:http://blog.csdn.net/zahuopuboss/article/details/9259283 #include #include #include #include #include #include #include #include #include #include #include #include _怎么设置tun的接收缓冲
UITextView 评论输入框 高度自适应-程序员宅基地
文章浏览阅读741次。创建一个inputView继承于UIView- (instancetype)initWithFrame:(CGRect)frame{ self = [superinitWithFrame:frame]; if (self) { self.backgroundColor = [UIColorcolorWithRed:0.13gre
随便推点
字符串基础面试题_java字符串相关面试题-程序员宅基地
文章浏览阅读594次。字符串面试题(2022)_java字符串相关面试题
VSCODE 实现远程GUI,显示plt.plot, 设置x11端口转发_vscode远程ssh连接服务器 python 显示plt-程序员宅基地
文章浏览阅读1.4w次,点赞12次,收藏21次。VSCODE 实现远程GUI,显示plt.plot, 设置x11端口转发问题服务器 linux ubuntu16.04本地 windows 10很多小伙伴发现VSCode不能显示figure,只有用自带的jupyter才能勉强个截图、或者转战远程桌面,这对数据分析极为不方便。在命令行键入xeyes(一个显示图像的命令)会failed,而桌面下会出现:但是Xshell能实现X11转发图像,有交互功能,但只能用Xshell输入命令plot,实在不方便。其实VScode有X11转发插件!!方法_vscode远程ssh连接服务器 python 显示plt
Java SE | 网络编程 TCP、UDP协议 Socket套接字的使用_javase套接字socket-程序员宅基地
文章浏览阅读529次。网络编程_javase套接字socket
element-ui switch开关打开和关闭时的文字设置样式-程序员宅基地
文章浏览阅读3.3k次,点赞2次,收藏2次。element switch开关文字显示element中switch开关把on-text 和 off-text 属性改为 active-text 和 inactive-text 属性.怎么把文字描述显示在开关上?下面就是实现方法: 1 <el-table-column label="状态"> 2 <template slot-scope="scope">..._el-switch 不同状态显示不同字
HttpRequestUtil方法get、post、JsonToPost_httprequestutil.httpget-程序员宅基地
文章浏览阅读785次。java后台发起请求使用的工具类package com.cennavi.utils;import org.apache.http.Header;import org.apache.http.HttpResponse;import org.apache.http.HttpStatus;import org.apache.http.client.HttpClient;import org.apache.http.client.methods.HttpPost;import org.apach_httprequestutil.httpget
App-V轻量级应用程序虚拟化之三客户端测试-程序员宅基地
文章浏览阅读137次。在前两节我们部署了App-V Server并且序列化了相应的软件,现在可谓是万事俱备,只欠东风。在这篇博客里面主要介绍一下如何部署客户端并实现应用程序的虚拟化。在这里先简要的说一下应用虚拟化的工作原理吧!App-V Streaming 就是利用templateServer序列化出一个软件运行的虚拟环境,然后上传到app-v Server上,最后客户..._app-v 客户端