Pandas 合并(merge)_pandas中merge相同列按第一个为准-程序员宅基地
技术标签: pandas pandas merge pandas合并
Pandas 合并(merge),对于合并操作,熟悉SQL的同学可以将其理解为JOIN操作,它使用一个或多个键把多行数据结合在一起。
原文参考 https://coolcou.com/pandas/pandas-data-process/pandas-merger-merge.html
跟关系数据库打交道的同学通常使用SQL的JOIN查询,用几个表共用的引用值(键)从不同的表获取数据。以这些键为基础,我们能够获取列表形式的新数据,这些数据是对几个表中的数据进行组合得到的。Pandas库中这类操作叫做合并,执行合并操作的函数为merge()。
阅读本章内容前,可以先学习Pandas基础教程及Pandas数据读写。
使用merge()函数进行合并
如下所示,首先定义两个DataFrame对象,然后对两个DataFrame对象应用merge()函数进行合并操作。
import pandas as pd
frame1 = pd.DataFrame({
'id':['ball', 'pencil', 'pen', 'mug', 'ashtray'],
'price':['12.33', '11.44', '33.21', '12.23', '33.62']})
frame2 = pd.DataFrame({
'id':['pencil', 'pencil', 'ball', 'pen'],
'color':['white', 'red', 'red', 'black']})
print(frame1)
print('------------')
print(frame2)
print('-----------')
print(pd.merge(frame1, frame2))
输出结果如下:

如上所示,返回的DataFrame对象由原来两个DataFrame对象中ID相同的行组成,出了id这一列,新DataFrame包含了属于两个DataFrame的其他列。
on 选项指定基准列
在上面例子中,没有为merge()指定基于哪一列进行合并,实际应用中,常常需要指定基于哪一列进行合并。具体做法是增加on选项,把列的名称作为用于合并的键赋值给它。如下所示:
import pandas as pd
frame1 = pd.DataFrame({
'id':['ball', 'pencil', 'pen', 'mug', 'ashtray'],
'color':['white', 'red', 'red', 'black','green'],
'brand':['OMG', 'ABC', 'ABC', 'POD', 'POD']})
frame2 = pd.DataFrame({
'id':['pencil', 'pencil', 'ball', 'pen'],
'brand':['OMG', 'POD', 'ABC', 'POD']})
print(frame1)
print('------------')
print(frame2)
print('-----------')
print(pd.merge(frame1, frame2))
输出结果如下:

如上所示,由于我们定义的两个DataFrame对象,一个对象的列名称在另一个对象中也存在,所以对它们执行合并操作将得到一个空DataFrame对象。
因此我们需要明确定义pandas合并操作需要遵循的标准,我们用on选项指定合并操作所依据的基准列,合并标准不同,合并结果也会不同,如下所示:
import pandas as pd
frame1 = pd.DataFrame({
'id':['ball', 'pencil', 'pen', 'mug', 'ashtray'],
'color':['white', 'red', 'red', 'black','green'],
'brand':['OMG', 'ABC', 'ABC', 'POD', 'POD']})
frame2 = pd.DataFrame({
'id':['pencil', 'pencil', 'ball', 'pen'],
'brand':['OMG', 'POD', 'ABC', 'POD']})
print(pd.merge(frame1, frame2,on='id'))
print("------------")
print(pd.merge(frame1, frame2,on='brand'))
输出结果如下:

问题如影随形,假如两个DataFrame基准列的名称不一致,又该如何进行合并呢?为此,我们可以使用left_on和right_on选项指定第一个和第二个DataFrame的基准列,如下所示:
import pandas as pd
frame1 = pd.DataFrame({
'id':['ball', 'pencil', 'pen', 'mug', 'ashtray'],
'color':['white', 'red', 'red', 'black','green'],
'brand':['OMG', 'ABC', 'ABC', 'POD', 'POD']})
frame2 = pd.DataFrame({
'id':['pencil', 'pencil', 'ball', 'pen'],
'brand':['OMG', 'POD', 'ABC', 'POD']})
frame2.columns = ['brand', 'sid']
print(frame1)
print('------------')
print(frame2)
print('------------')
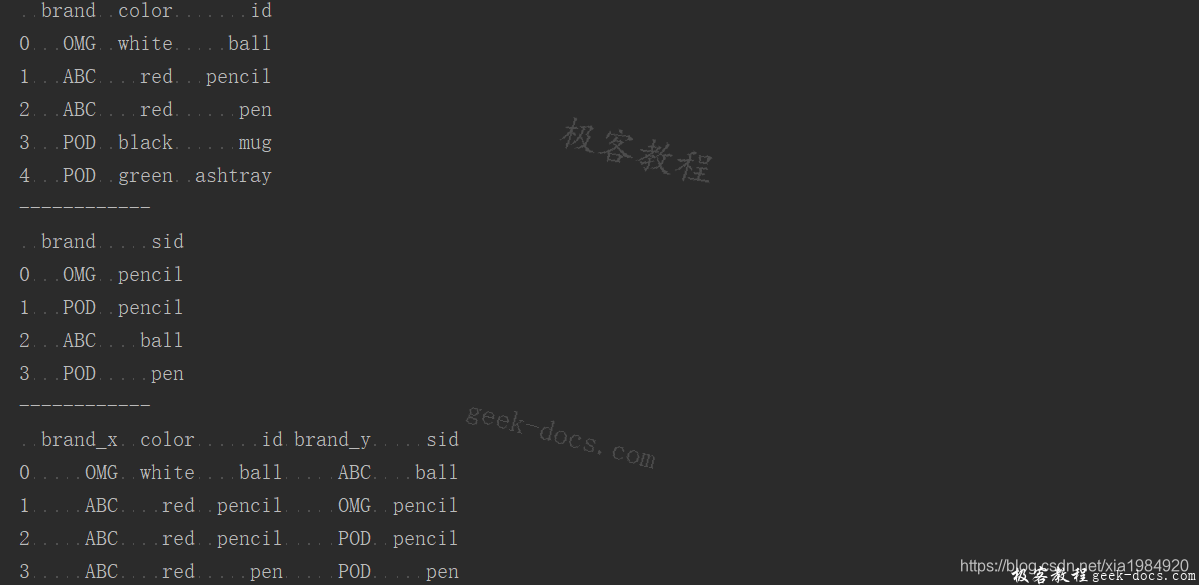
print(pd.merge(frame1,frame2,left_on='id',right_on='sid'))
输出结果如下:
左连接,右连接,外连接
如上所示,merge()函数默认执行的是内连接操作,上述结果执行的是交叉操作,其他还支持左连接,右连接和外连接,外连接把所有的键整合在一起,其效果相当于左连接和右连接的效果之和,连接类型用how选项指定。如下所示:
import pandas as pd
frame1 = pd.DataFrame({
'id':['ball', 'pencil', 'pen', 'mug', 'ashtray'],
'color':['white', 'red', 'red', 'black','green'],
'brand':['OMG', 'ABC', 'ABC', 'POD', 'POD']})
frame2 = pd.DataFrame({
'id':['pencil', 'pencil', 'ball', 'pen'],
'brand':['OMG', 'POD', 'ABC', 'POD']})
frame2.columns = ['brand', 'id']
print(frame1)
print('------------')
print(frame2)
print('------------')
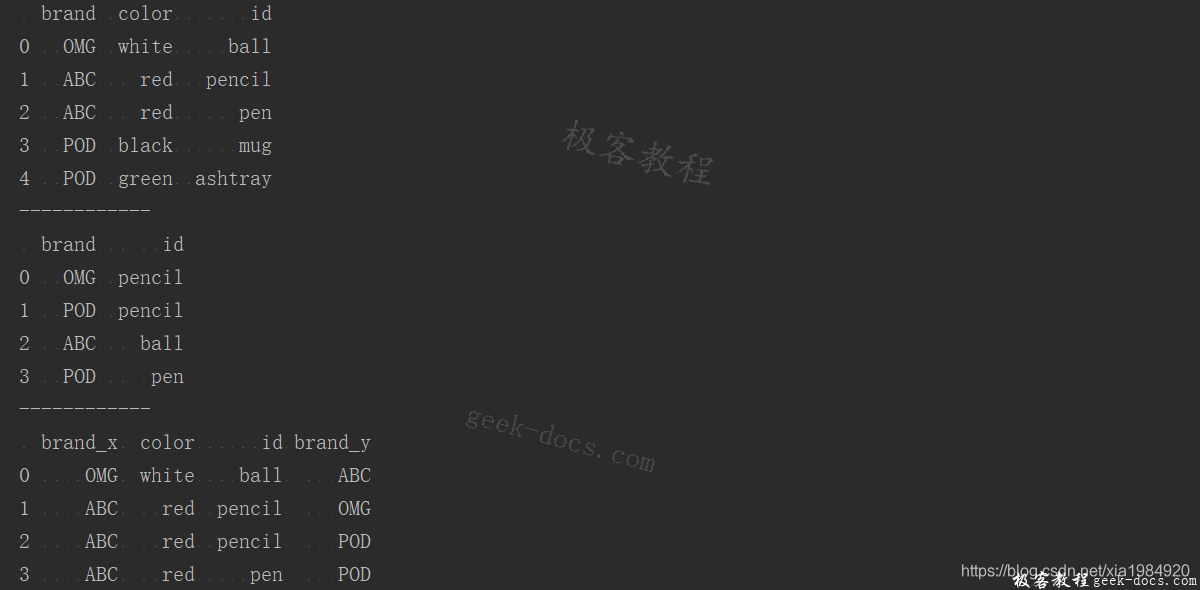
print(pd.merge(frame1,frame2,on='id'))
执行结果如下:
分别执行外连接,左连接,右连接,如下所示:
import pandas as pd
frame1 = pd.DataFrame({
'id':['ball', 'pencil', 'pen', 'mug', 'ashtray'],
'color':['white', 'red', 'red', 'black','green'],
'brand':['OMG', 'ABC', 'ABC', 'POD', 'POD']})
frame2 = pd.DataFrame({
'id':['pencil', 'pencil', 'ball', 'pen'],
'brand':['OMG', 'POD', 'ABC', 'POD']})
frame2.columns = ['brand', 'id']
print(pd.merge(frame1,frame2,how='outer'))
print('------------')
print(pd.merge(frame1,frame2,how='left'))
print('------------')
print(pd.merge(frame1,frame2,how='right'))
输出结果如下:
brand color id
0 OMG white ball
1 ABC red pencil
2 ABC red pen
3 POD black mug
4 POD green ashtray
5 OMG NaN pencil
6 POD NaN pencil
7 ABC NaN ball
8 POD NaN pen
------------
brand color id
0 OMG white ball
1 ABC red pencil
2 ABC red pen
3 POD black mug
4 POD green ashtray
------------
brand color id
0 OMG NaN pencil
1 POD NaN pencil
2 ABC NaN ball
3 POD NaN pen
要合并多个键,则把多个键赋值为on选项,如下示:
import pandas as pd
frame1 = pd.DataFrame({
'id':['ball', 'pencil', 'pen', 'mug', 'ashtray'],
'color':['white', 'red', 'red', 'black','green'],
'brand':['OMG', 'ABC', 'ABC', 'POD', 'POD']})
frame2 = pd.DataFrame({
'id':['pencil', 'pencil', 'ball', 'pen'],
'brand':['OMG', 'POD', 'ABC', 'POD']})
frame2.columns = ['brand', 'id']
print(pd.merge(frame1,frame2,on=['id','brand'],how='outer'))
输出结果如下:

根据索引进行合并
有的时候,合并操作不是用DataFrame的列,而是用索引作为键。把left_index和right_index选项的值置为True,就可将其作为合并DataFrame的基准。如下所示:
import pandas as pd
frame1 = pd.DataFrame({
'id':['ball', 'pencil', 'pen', 'mug', 'ashtray'],
'color':['white', 'red', 'red', 'black','green'],
'brand':['OMG', 'ABC', 'ABC', 'POD', 'POD']})
frame2 = pd.DataFrame({
'id':['pencil', 'pencil', 'ball', 'pen'],
'brand':['OMG', 'POD', 'ABC', 'POD']})
frame2.columns = ['brand', 'id']
print(pd.merge(frame1,frame2,right_index=True,left_index=True))
输出结果如下:

DataFrame对象的join()函数更适合于根据索引进行合并,我们可以用它合并多个索引相同列不同的DataFrame对象。如上所示,因为frame1的列名称和frame2的列名称有重合,直接调用frame1.join(frame2)会给出错误信息,这里要重命名frame2的列。如下所示:
import pandas as pd
frame1 = pd.DataFrame({
'id':['ball', 'pencil', 'pen', 'mug', 'ashtray'],
'color':['white', 'red', 'red', 'black','green'],
'brand':['OMG', 'ABC', 'ABC', 'POD', 'POD']})
frame2 = pd.DataFrame({
'id':['pencil', 'pencil', 'ball', 'pen'],
'brand':['OMG', 'POD', 'ABC', 'POD']})
frame2.columns = ['brand2', 'id2']
print(frame1.join(frame2))
输出结果如下:

如上所示,合并操作是以索引而不是列为基准,合并后得到的DataFrame对象包含了只存在于frame1的索引4,整合了frame2,索引为4的各元素使用NaN填充。
相关文章参考
Pandas 旋转数据
Pandas 删除数据
Pandas 拼接(concat)
Pandas GroupBy 用法
智能推荐
【数据结构】查找1——线性表的查找(顺序查找、折半查找、分块查找)_图顺序查找-程序员宅基地
文章浏览阅读2.8k次。【数据结构】查找1——线性表的查找(顺序查找、折半查找、分块查找)_图顺序查找
zip包解压时报malformed input off : 0, length : 1-程序员宅基地
文章浏览阅读843次。使用ZipArchiveInputStream而非ZipInputStream的原因主要有以下两点:支持更多的压缩格式:ZipArchiveInputStream是Apache Commons Compress库中提供的类,能够支持多种压缩格式,包括Zip、Gzip、Tar、Jar等。而ZipInputStream是Java标准库中的类,只能读取普通的Zip文件。因此,如果需要处理多种压缩格式的文件,使用ZipArchiveInputStream会更加方便。更多的选项和功能:ZipArchiveInp_malformed input off : 0, length : 1
switch case结合枚举值使用,借助枚举的值来做case分支判断_switch case 枚举-程序员宅基地
文章浏览阅读8.3k次,点赞9次,收藏22次。https://blog.csdn.net/m0_37754981/article/details/80022169参考资料_switch case 枚举
rpc简介及原理-程序员宅基地
文章浏览阅读5.1k次,点赞2次,收藏30次。1.RPC简介及原理介绍RPC技术内部原理是通过两种技术的组合来实现的:本地方法调用 和 网络通信技术。1.1 RPC简介在上述本地过程调用的例子中,我们是在一台计算机上执行了计算机上的程序,完成调用。随着计算机技术的发展和需求场景的变化,有时就需要从一台计算机上执行另外一台计算机上的程序的需求,因此后来又发展出来了RPC技术。特别是目前随着互联网技术的快速迭代和发展,用户和需求几乎都是以指数式的方式在高速增长,这个时候绝大多数情况下程序都是部署在多台机器上,就需要在调用其他物理机器上的程序的情况。_rpc
AI大视觉(十七) | PANet(路径聚合网络)-程序员宅基地
文章浏览阅读7k次,点赞6次,收藏70次。本文来自公众号“AI大道理目标检测或者实例分割不仅要关心语义信息,还要关注图像的精确到像素点的浅层信息。所以需要对骨干网络中的网络层进行融合,使其同时具有深层的语义信息和浅层的纹理信息。PANet整体结构PANet(Path Aggregation Network)最大的贡献是提出了一个自顶向下和自底向上的双向融合骨干网络,同时在最底层和最高层之间添加了一条“short-cut”,用于缩短层之间的路径。PANet还提出了自适应特征池化和全连接融合两个模块。其中自适应特征_panet
OperationalError: (sqlite3.OperationalError) unable to open database file解决方案_sqlite3.operationalerror: unable to open database -程序员宅基地
文章浏览阅读1.3w次,点赞13次,收藏14次。本文主要介绍了OperationalError: (sqlite3.OperationalError) unable to open database file解决方案,希望能对使用langchain读取sqlite文件的同学们有所帮助。文章目录1. 问题描述2. 解决方案_sqlite3.operationalerror: unable to open database file
随便推点
PID控制详解-程序员宅基地
文章浏览阅读10w+次,点赞551次,收藏3.2k次。PID控制详解一、PID控制简介 PID( Proportional Integral Derivative)控制是最早发展起来的控制策略之一,由于其算法简单、鲁棒性好和可靠性高,被广泛应用于工业过程控制,尤其适用于可建立精确数学模型的确定性控制系统。 在工程实际中,应用最为广泛的调节器控制规律为比例、积分、微分控制,简称PID控制,又称PID调节,它实际上是一种算法。PID控制器问..._pid控制
搭建静态网站-程序员宅基地
文章浏览阅读329次。搭建Http静态服务器环境任务时间:15min ~ 30min搭建静态网站,首先需要部署环境。下面的步骤,将告诉大家如何在服务器上通过 Nginx 部署 HTTP 静态服务。00、安装 Nginx在 CentOS 上,可直接使用yum来安装 Nginxyum install nginx -y安装完成后,使用nginx命令启动 Nginx:n..._在一个目录下创建静态站点
HTML5网页设计 (一)_html5网页制作-程序员宅基地
文章浏览阅读7k次,点赞2次,收藏23次。初始HTML5记事本简单实现HTML5页面_html5网页制作
CentOS 固定IP配置_centos配置ip地址-程序员宅基地
文章浏览阅读6.8k次。1、打开 VMware Workstation,点击 “编辑” -> "虚拟网络编辑器"2、选择 “更改设置”(若界面内没有,则不用理会)3、选择 “VMnet8”,更改为192.168.88.0(按需填写)、为255.255.255.0,点击 “NAT设置”4、更改为192.168.88.2(按需填写),当前界面点击确定,“虚拟网络编辑器”界面再点击确定。_centos配置ip地址
MATLAB 调用 p文件,Matlab中使用.p文件的方法-程序员宅基地
文章浏览阅读2.9k次。首先,P文件为了保护知识产权设计的一种加密文件,是不能查看的。运行比较简单,和调用m文件方法一样。下面是一些解释。P文件是对应M文件的一种预解析版本(preparsedversion)。因为当你第一次执行M文件时,Matlab需要将其解析(parse)一次(第一次执行后的已解析内容会放入内存作第二次执行时使用,即第二次执行时无需再解析),这无形中增加了执行时间。所以我们就预先作解释,那么以后再使用..._matlab怎么调用p文件
[CSS] 内联元素内的文字居中显示(按钮、链接等)_a-button居中-程序员宅基地
文章浏览阅读2.1k次。最近在做一个移动端的响应式页面,对自定义样式要求较高,很多地方需要细微的调整,比如按钮、链接等内联元素,不能只是让它看起来居中,而要做到“响应式”居中……水平居中很简单,但是垂直居中的问题困扰了我很久,直到我研究过bootstrap的_variables.scss文档后,才仔细地了解到一些组件的构造。如果修改了inline/inline-block元素的默认样式后,里面的文字不居中了,试试这个方法,只需要5步~_a-button居中