2D: 传统目标检测算法综述_2d目标检测sota方法-程序员宅基地
技术标签: 自动驾驶 tensorflow # 二维目标检测 机器学习 深度学习 pytorch
一. 目标检测的发展历程
1. 2001年,V-J检测器诞生,主要用于人脸的检测;
2. 2006年,HOG + SVM的方法出现,主要用于行人的检测;
3. 2008年,rgb大神(记住这个人,后面的R-CNN系列检测算法也是出自他之手)研究出了著名的DPM算法,在深度学习方法成熟之前的很长一段时间里,就是这个算法一直在目标检测中发挥作用;
以上算法是属于传统目标检测的算法,都是基于图像处理和计算机视觉的!
------------------------------------------------------------------分割线------------------------------------------------
到了2012年CNN的崛起,开始了深度学习和计算机视觉结合的旅程!
4. 2013年,出现了Overfeat;
5. 2014年,rgb大神提出了大名鼎鼎的R-CNN检测算法,开始了two-stage的旅程;
6. 2014年,SPPNet诞生;
7. 2015年,R-CNN的快速版Fast RCNN 和 Faster RCNN,以及yolo,yolo的到来标志着one-stage检测算法的开启;
8. 2016年,大家都爱的SSD到来;
9. 2017-2018年,Pyramid Networks,还有Retina-Net。
二. 什么是目标检测?
-
目标检测就是找出图像中所有感兴趣的目标,识别他们的类别和位置。
(1)什么是类别?
类别就是一个分类的标签,即感兴趣的目标属于什么种类,猫,狗,羊等。
(2)什么是位置?
位置用矩形框表示,目标检测的位置信息一般有两种格式(以图片左上角为原点(0, 0)):极坐标表示:(xmin, ymin, xmax, ymax) xmin,ymin: 矩形框的左上角坐标 xmax,ymax: 矩形框的右下角坐标 中心点坐标:(x_center, y_center, w, h) x_center, y_center: 目标检测框的中心点坐标 w, h: 目标检测框的宽、高 -
目标检测的输出是一个列表,其中的每一项都会给出检出目标的类别和位置。类别就是一个分类的标签,而位置用矩形框表示。
(1)比较:
分类的输出是一个类别标签。对单分类来说,它就是一个整数,表示属于某一个类别;对多分类而言,它就是一个向量。
三. 什么是传统目标检测?
-
传统目标检测和深度学习目标检测的区别:
传统目标检测:很多任务不是一次性就可以解决,需要多个步骤;
深度学习目标检测:很多任务都采用end-to-end方案,即输入一张图,输出最终想要的结果。算法细节和学习过程全部交给了神经网络。 -
完成一个目标检测任务一般分为三个步骤:
第一步选择检测窗口;
第二步提取图像特征;
第三部设计分类器。
如下图所示:

四. V-J人脸检测算法
-
候选框选取:
V-J框架使用的就是最简单的滑动窗口法(穷举窗口扫描),它的训练尺度是24*24的滑动窗口。 -
Haar特征提取:
关于Haar特征,通俗点讲就是白色像素点于黑色像素点的差分,即value = 白 - 黑,是一种纹理特征。
(1)V-J算法特征提取矩形框图:
包括三种特征,分为两矩形特征、三矩形特征、对角特征。如下图所示:

(2)使用积分图加速计算特征:
积分图的特点就是,该图像中的任何一点,等于位于该点左上角的所有像素之和,这可以被看成是一种积分,因此称之为积分图。(3)计算方块内的像素和:
为了理解如何计算任意矩形内的像素值,我们画出四个区域A、B、C、D,并且图中有四个位置分别为1、2、3、4。如下图所示: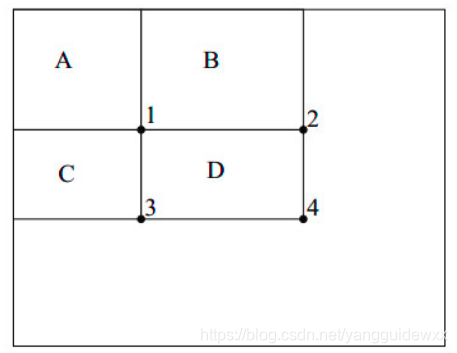
我们要计算D区域内部的像素和该怎么计算?记位置4的左上的所有像素为rectsum(4),那么D位置的像素之和就是rectsum(1)+rectsum(4)−rectsum(2)−rectsum(3)。 我们前面提到有三种类型的Haar特征。其中二矩形特征需要6次查找积分图中的值,而三矩形特征需要8次查找积分图中的值,而对角的特征需要9次。 -
训练人脸分类器:
V-J采用的是Adaboost算法,原理如下:
a. 初始化样本的权重w, 权重之和为1;
b. 训练弱分类器;
c. 更新样本权重;
d. 重复步骤b
e. 最后结合多个弱分类器的结果进行投票。
将多个弱分类器组合成一个强分类器,这就是AdaBoost方法的核心理念。
五. HOG + SVM行人检测算法
1. HOG算法
HOG是一种在计算机视觉和图像处理中用来进行物体检测的描述子。通过计算和统计局部区域的梯度方向直方图来构成特征。Hog特征结合SVM分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。
主要思想:在一幅图像中,局部目标的表象和形状能够利用梯度或边缘的方向密度分布来进行描述。其本质是梯度的统计信息,而梯度主要存在于边缘所在的地方。
算法优点:与其他的特征描述方法相比,HOG具有较多优点。由于HOG是在图像的局部方格单元上进行操作的,所以它对图像的几何和光学形变都能保持很好的不变性,这两种形变只会出现在更大的空间领域上。其次,在粗的空域抽样、精细的方向抽样以及较强的局部光学归一化等条件下,只要行人大体上能够保持直立的姿势,可以容许行人有一些细微的肢体动作,这些细微的动作可以被忽略而不影响检测效果。因此HOG特征特别适合于做图像中的人体检测。
实现步骤及流程图如下:
步骤1. 读取待检测的图片;
步骤2. 将输入图像灰度化(将输入的彩色图像的r,g,b值通过特定公式转换为灰度值);
步骤3. 采用Gamma校正法对输入图像进行颜色空间的标准化(归一化);
步骤4. 计算图像中每个像素的梯度值(包括大小和方向),捕获轮廓信息;
步骤5. 统计每个cell内的梯度直方图(不同梯度的个数),形成每个cell的特征描述子;
步骤6. 将每几个cell组成一个block(以3*3为例),一个block内所有cell的特征串联起来得到该block的HOG特征描述子;
步骤7. 将图像image内所有block块的HOG特征描述子串联起来得到该image(检测目标)的HOG特征描述子,这就是最终分类的特征向量。

2. SVM算法
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。
SVM的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
具体的算法实现原理参考:https://zhuanlan.zhihu.com/p/31886934
3. 基于HOG+SVM的目标检测算法训练流程
步骤1. 从训练数据集中获取P个正样本块,并计算这P个正样本块的HOG特征描述子;
步骤2. 从训练数据集中获取N个负样本块,并计算这N个负样本块的HOG特征描述子,其中N>>P;
步骤3. 在这些正样本和负样本块上面训练一个SVM分类器模型;
步骤4. 应用hard-negative-mining。对于负面训练集中的每个图像和每个可能的图像比例,在图像上面应用滑动窗口。在每个窗口中计算相应的HOG特征描述符并应用分类器。如果您的分类器(错误地)将给定窗口分类为一个对象(它将绝对存在误报),记录与误报补丁相关的特征向量以及分类的概率。这种方法被称为hard-negative-mining。具体效果如下图所示:

步骤5. 首先获取使用hard-negative-mining技术获取到的错误的正样本块,然后按照概率值对它们进行排序;接着使用这些样本块重新训练分类器模型;
步骤6. 将训练好的模型应用到测试图片中;
步骤7. 对预测的结果使用NMS去除冗余的bbox。
4. 知识点hard negative mining的含义
假设给你一堆包含一个或多个人物的图片,并且每一个人都给你一个bounding box做标记,如果要训练一个分类器去做分类的话,你的分类器需要既包含正训练样本(人)和负训练样本(背景)。
你通过观察bounding box去创建一个有用的正训练样本,那么怎么做才能创建一个有用的负训练样本呢?
一个很好的方式就是去在开始时随机创建一堆的bounding box候选框,并且不能与你的正样本有任何的重叠,把这些未与正样本重叠的新的bounding box作为你的负样本。
好了,这样你的正负样本都有了,可以训练可以用的分类器了,你用滑动窗口在你的训练图片上进行运行,但是你会发现你的分类器并不是很好用,分类的效果并不是很好,因为它会抛出一堆的错误的正样本(当检测到人时实际上却并不是实际的人),这就问题来了,你训练了一个用于分类的分类器,然而这个分类器却并不能达到你想要的效果,那么应该怎么办呢?
这个时候就要用的hard negative了,hard negative就是当你得到错误的检测patch时,会明确的从这个patch中创建一个负样本,并把这个负样本添加到你的训练集中去。当你重新训练你的分类器后,分类器会表现的更好,并且不会像之前那样产生多的错误的正样本。
参考网页:
https://blog.csdn.net/WZZ18191171661/article/details/91305466
https://zhuanlan.zhihu.com/p/94934407
六. DPM检测算法
1. 什么是DPM算法
DPM(Deformable Parts Models)翻译成中文是可变型部件模型,是一种用于目标探测的方法。DPM方法在2012年之前在目标探测领域都是应用非常广泛的一种方法,但是在12年之后,这种方法逐渐走下没落。
2. DPM算法思想
输入一幅图像,对图像提取图像特征,针对某个物件制作出相应的激励模板,在原始的图像中计算,得到该激励效果图,根据激励的分布,确定目标位置。
制作激励模板就相当于人为地设计一个卷积核,一个比较复杂的卷积核,拿这个卷积核与原图像进行卷积运算得到一幅特征图。比如拿一个静止站立的人的HOG特征形成的卷积核,与原图像的梯度图像进行一个卷积运算,那么目标区域就会被加密。如下图所示:

那么说到这里就会出现一个问题,人在图像中可能有各种的姿态,比如躺着,趴着,坐着等等,我们只用一个静止站立状态的人的激励模板去做探测就会失败。也就是说图像中的物件可能会发生形变,那么我们用固定的激励模板去探测目标物件的时候就不再适用,那么该如何解决这一问题呢,这就引出了局部模板,也就是说,我们不做一个整体的人的激励模板,转而去做人的部分组件的模板,比如头、胳膊、腿等,其实这就是DPM算法。
3. DPM算法的步骤
(1)产生多个模板,整体模板以及不同的局部模板;
(2)拿这些不同的模板同输入图像“卷积”产生特征图;
(3)将这些特征图组合形成融合特征;
(4)对融合特征进行传统分类,回归得到目标位置。
4. DPM算法优点
(1)方法直观简单;
(2)运算速度块;
(3)适应动物变形。
5. DPM算法缺点
(1)性能一般
(2)激励特征人为设计,工作量大;
这种方法不具有普适性,因为用来检测人的激励模板不能拿去检测小猫或者小狗,所以在每做一种物件的探测的时候,都需要人工来设计激励模板,为了获得比较好的探测效果,需要花大量时间去做一些设计,工作量很大。
(3)无法适应大幅度的旋转,稳定性很差。
七. NMS算法
全名叫非极大值抑制算法,该算法的主要目的是为了消除检测得到的多余框,找到目标物体的最佳位置。
该算法具体的步骤如下:
- 假定有6个带置信率的region proposals,并预设一个IOU的阈值如0.7。
- 按置信率大小对6个框排序: 0.95, 0.9, 0.9, 0.8, 0.7, 0.7。
- 设定置信率为0.95的region proposals为一个物体框;
- 在剩下5个region proposals中,去掉与0.95物体框IOU大于0.7的。
- 重复2~4的步骤,直到没有region proposals为止。
- 每次获取到的最大置信率的region proposals就是我们筛选出来的目标。
参考文献:https://blog.csdn.net/leeyisong/article/details/96422963
智能推荐
ROS1快速入门学习笔记 - 10服务数据的定义和使用
三个横线作为一个区分,上面是request,下面是response;创建完之后如下所示。
017、Python+fastapi,第一个Python项目走向第17步:ubuntu24.04 无界面服务器版下安装nvidia显卡驱动
新的ubuntu24.04正式版发布了,前段时间玩了下桌面版,感觉还行,先安装一个服务器无界面版本吧安装时有一个openssh选择安装,要不然就不能ssh远程,我就是没选,后来重新安装ssh。另外一个就是安装过程中静态ip设置下在etc/netplan 文件夹下,有一个yaml文件,我的是50-cloud-init.yaml,先用ip a看看network:ethernets:enp3s0:routes:version: 2。
不是阿里P8级大佬,岂能错过这篇MySQL运维内参?啃透涨薪so easy-程序员宅基地
文章浏览阅读176次。写在前面MySQL被设计为一个可移植的数据库,几乎在当前所有系统上都能运行,如Linux、Solaris、 FreeBSD、 Mac和Windows。尽管各平台在底层(如线程)实现方面都各有不同,但是MySQL基本上能保证在各平台上的物理体系结构的一致性。因此,用户应该能很好地理解MySQL数据库在所有这些平台上是如何运作的。由于工作的缘故,笔者的大部分时间需要与开发人员进行数据库方面的沟通,并对他们进行培训。不论他们是DBA,还是开发人员,似乎都对MySQL的体系结构了解得不够透彻。很多人喜欢把M_mysql运维内参
百度正用谷歌AlphaGo,解决一个比围棋更难的问题 | 300块GPU在燃烧-程序员宅基地
文章浏览阅读382次。晓查 发自 凹非寺量子位 报道 | 公众号 QbitAI9102年,人类依然不断回想起围棋技艺被AlphaGo所碾压的恐怖。却也有不以为然的声音:只会下棋的AI,再厉害..._alpha go训练用了多少个gpu
docker 容器 设置网络代理_docker export http_proxy-程序员宅基地
文章浏览阅读3.3k次。docker 容器 设置网络代理以/bin/bash 形式进入容器:【设置http 及https代理】,如下:export http_proxy=http://172.16.0.20:3128export https_proxy=https://172.16.0.20:3128要取消该设置:unsethttp_proxyunset https_proxy..._docker export http_proxy
linux之笔记_linux 0775十六進制-程序员宅基地
文章浏览阅读263次。授课环境: 结束程序运行: ctrl + c 共享目录(工作目录): /kyo /Videos 访问共享目录流程: 是否能连通服务器 ping 3.3.3.9 是否服务器开启共享 showmount -e 3.3.3.9 挂载共享目录到本地: _linux 0775十六進制
随便推点
K210与STM32之间的通信_k210与stm32通信-程序员宅基地
文章浏览阅读5.1k次,点赞2次,收藏70次。K210与STM32之间使用串口进行通信_k210与stm32通信
OpenHarmony语言基础类库【@ohos.util.List (线性容器List)】
而网上有关鸿蒙的开发资料非常的少,假如你想学好鸿蒙的应用开发与系统底层开发。你可以参考这份资料,少走很多弯路,节省没必要的麻烦。由两位前阿里高级研发工程师联合打造的《鸿蒙NEXT星河版OpenHarmony开发文档》里面内容包含了(ArkTS、ArkUI开发组件、Stage模型、多端部署、分布式应用开发、音频、视频、WebGL、OpenHarmony多媒体技术、Napi组件、OpenHarmony内核、Harmony南向开发、鸿蒙项目实战等等)鸿蒙(Harmony NEXT)技术知识点。
[自学笔记] ESP32-C3 Micropython初次配置
2、本次测试了两款IDE,分别是"thonny-4.1.4.exe"和"uPyCraft-v1.0.exe"。Thonny支持中文及多语言。而uPyCraft-v1.0只支持英文语言。因此入门时选用了Thonny作为IDE。(注:1、测试过程中IDE正常连接ESP32C3简约版的虚拟串口。不受简约版无串口芯片的影响。
初识Electron,创建桌面应用
古有匈奴犯汉,晋室不纲,铁木夺宋,虏清入关,神舟陆沉二百年有余,中国之见灭于满清初非满人能灭之,能有之也因有汉奸以作虎怅,残同胞媚异种,始有吴三桂洪承畴,继有曾国藩袁世凯以为厉。今率堂堂之师,征讨汉贼袁氏筑共和之体,或免于我子子孙孙被异族奴役。---- 《讨汉贼袁世凯檄文》- DOMContentLoaded事件:此时浏览器已经完全加载了HTML文件,并且DOM树已经生成好了。- Load事件:此时浏览器已经将所有的资源都加载完毕,可以正确读取页面中的资源。补充知识:Electron 生命周期。
Xcode 15构建问题
将ENABLE_USER_SCRIPT_SANDBOXING设为“no”即可!
OpenVINO应用案例:部署YOLO模型到边缘计算摄像头_openvino yolo-程序员宅基地
文章浏览阅读2.8k次,点赞3次,收藏23次。一、实现路径通过OpenVINO部署YOLO模型到边缘计算摄像头,其实现路径为:训练(YOLO)->转换(OpenVINO)->部署运行(OpenNCC)。二、具体步骤1、训练YOLO模型1.1 安装环境依赖有关安装详情请参阅 https://github.com/AlexeyAB/darknet#requirements-for-windows-linux-and-macos 。1.2 编译训练工具git clone https://github.com/AlexeyAB/da_openvino yolo