网络相关面试题_can 进阶面试题-程序员宅基地
文章目录
- 1.简述OSI七层协议
- 2.什么是C/S和B/S架构?
- 3.三次握手、四次挥手
- 4.TCP与UDP的区别
- 5.为何基于TCP协议的通信比基于UDP协议的通信更可靠?
- 6.什么是socket?简述基于TCP协议的套接字通信流程
- 7.什么是粘包?socket 中造成粘包的原因是什什么?哪些情况会发生粘包现象?
- 8.IO多路复用的作用
- 9.select、poll、epoll 模型的区别?(属于多路复用IO的模型)
- 10.什么是防火墙以及作用?
- 11.简述 进程、线程、协程的区别 以及应用场景
- 12.GIL锁是什么?
- 13.Python中如何使用线程池和进程池?
- 14.threading.local()的作用
- 15.进程之间如何进行通信?
- 16.什么是并发和并行?
- 17.进程锁和线程锁的作用
- 18.同步和异步,阻塞和非阻塞的区别?
- 19.路由器和交换机的区别
- 20.什么是域名解析?
- 21.如何修改本地hosts件?
- 22.生产者消费者模型应用场景及优势
- 23.什么是cdn?
- 24.LVS是什么及作用?
- 25.Nginx是什么及作用
- 26.什么是负载均衡?
- 27.twisted框架的应用
- 28.大规模连接上来,并发模型怎么设计?
1.简述OSI七层协议
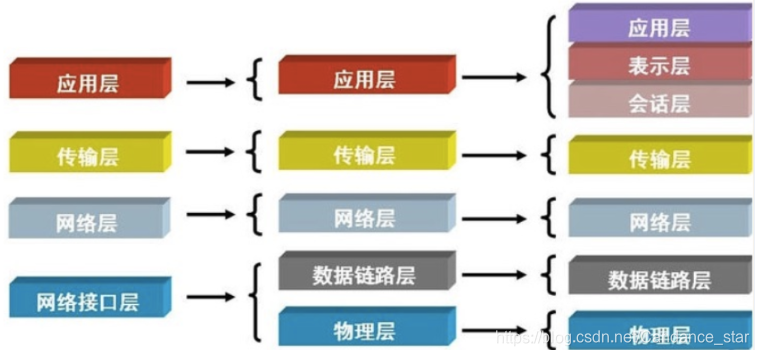
物理层:定义物理设备标准,如网线的接口类型、光纤的接口类型、各种传输介质
数据链路层:定义如何传输格式化数据,以及如何访问物理介质
网络层:定义逻辑网络地址
传输层:定义传输协议和端口
会话层:定义客户端与服务端的连接
表示层:定义数据格式转换,对来自应用层的数据进行解释
应用层:定义应用程序
2.什么是C/S和B/S架构?
C/S架构:client(客户端)与server(服务端),即客户端与服务端的架构
B/S架构:brosver(浏览器端)与server(服务端),即浏览器端与服务端架构
3.三次握手、四次挥手
三次握手 ——> 请求连接
第一次握手
客户端先向服务端发送一次询问建立连接的请求,并随机生成一个值作为标识
第二次握手
服务端向客户端先回应第一个标识,再重新发一个确认标识
第三次握手
客户端确认标识,建立连接,开始传输数据
四次挥手 ——> 断开连接
第一次挥手
客户端向服务端发送请求断开连接的请求
第二次挥手
服务端向客户端确认请求,表示知道了
第三次挥手
服务端向客户端发起断开连接请求
第四次挥手
客户端向服务端确认断开请求,表示已断开
4.TCP与UDP的区别
TCP协议:面向连接,高可用性的传输层协议
UDP协议:不面向连接,数据会丢失,不可靠的传输层协议 (短信和QQ基于UDP协议)
5.为何基于TCP协议的通信比基于UDP协议的通信更可靠?
TCP:可靠,因为只要对方回了确认收到信息,才发下一个,如果没收到确认信息就重发
UDP:不可靠,它是一直发数据,不需要对方回应
流式协议:TCP协议,可靠传输
数据报协议:UDP协议,不可传输
6.什么是socket?简述基于TCP协议的套接字通信流程
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。
在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部。
流程:
服务端:创建socket对象;绑定IP和端口bind(); 创建双工通信,等待连接; send(), recv(), 收发数据;close()
客户端:创建socket对象;与服务端创建双工通信,请求连接; send(),recv(), 收发数据;close()
7.什么是粘包?socket 中造成粘包的原因是什什么?哪些情况会发生粘包现象?
只有TCP有粘包现象,UDP永远不会粘包!
粘包:在接收数据时,一次性多接收了其它请求发送来的数据(即多包接收)。如,对方第一次发送hello,第二次发送world,在接收时,应该收两次,一次是hello,一次是world,但事实上是一次收到helloworld,一次收到空,这种现象叫粘包。
原因:粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
什么情况会发生:
1、发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据很小,会合到一起,产生粘包)
2、接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
8.IO多路复用的作用
socketserver,多个客户端连接,单线程下实现并发效果,就叫多路复用。
与多进程和多线程技术相比,I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。
9.select、poll、epoll 模型的区别?(属于多路复用IO的模型)
都是i/o多路复用的机制,监视多个socket是否发生变化,本质上都是同步i/o,select,poll实现需要自己不断轮询所有监测对象,直到对象发生变化,在这个阶段中,可能要睡眠和唤醒多次交替,而epoll也需要调用epoll_wait不断轮询就绪链表,但是当对象发生变化时,会调用回调函数,将变化的对象放入就绪链接表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都会睡眠和唤醒,但是select和poll在被唤醒的时候要遍历整个监测对象集合,而epoll只要判断就绪链表是否为空即可,节省了大量cpu的时间。
select、poll、epoll都是IO多路复用的机制,但select,poll,epoll本质上都是同步I/O,
因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的.
FD(文件描述符)
select模型
优点:
1:可移植性好,在某些Unix系统不支持poll()
2:对于超时值提供了更好的精度:微妙,而poll是毫秒
缺点:
1:最大并发数限制,因为一个进程所打开的 FD (文件描述符)是有限制的,由 FD_SETSIZE 设置,默认值是 1024/2048 ,因此 Select 模型的最大并发数就被相应限制了。
2:效率问题,select每次调用都会线性扫描全部的FD集合,所以将FD_SETSIZE 改大,会越慢
3:需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大。
poll本质上和select 没有区别,它将用户传入的数组拷贝到内核空间,它没有最大连接数的限制,原因是它基于链表来存储的但是同样有一个缺点:大量的fd的数组被整体复制于用户态和内核地址空间,而不管这样的复制是不是有意义。
10.什么是防火墙以及作用?
防火墙是一个分离器、一个限制器,也是一个分析器,有效地监控了内部网和Internet之间的任何活动,保证了内部网络的安全。
作用:
- 网络安全的屏障
- 对网络存取和访问进行监控审计
- 防止内部信息的外泄
- 除了安全作用,防火墙还支持具有Internet服务特性的企业内部网络技术体系VPN(虚拟专用网)
11.简述 进程、线程、协程的区别 以及应用场景
线程是指进程内的一个执行单元,
**进程:**进程拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度。
**线程:**线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程亦由操作系统调度。
**协程:**协程是运行在单线程中的"并发",协程相比多线程的一大优势就是省去了多线程之间的切换开销,获得了更高的运行效率。所以可以用协程取代多线程。协程避免了无意义的调度,由此可以提高性能;但同时协程也失去了线程使用多核CPU的能力。
进程与线程的区别
如果把进程比喻成项目组办公室,那么线程就是办公室里的员工,一个办公室可以有多个员工,每个员工的任务不同,但他们共享办公司资源。
(1)地址空间:线程是进程内的一个执行单位,进程内至少有一个线程,他们共享进程的地址空间,而进程有自己独立的地址空间
(2)资源拥有:进程是资源分配和拥有的单位,同一个进程内多线程共享进程的资源
(3)线程是处理器调度的基本单位,但进程不是
(4)二者均可并发执行
(5)每个独立的线程有一个程序运行的入口
协程与线程
(1)一个线程可以有多个协程,一个进程也可以有多个协程,这样Python则能使用多核CPU
(2)线程、进程都是同步机制,而协程是异步
(3)协程能保留上一次调用时的状态
12.GIL锁是什么?
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
GIL保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处理。
应用(总结):
多线程用于IO密集型,如socket,爬虫,web
多进程用于计算密集型,如金融分析
- 每个cpython进程内都有一个GIL
- GIL导致同一进程内多个进程同一时间只能有一个运行
- 之所以有GIL,是因为cpython的内存管理不是线程安全的
13.Python中如何使用线程池和进程池?
因为在切换线程/进程的时候,需要切换上下文环境,线程很多的时候,依然会造成CPU的大量开销。为解决这个问题,线程池的概念被提出来了。
预先创建好一个数量较为优化的线程/进程组,在需要的时候立刻能够使用,就形成了线程/进程池。
如果池还没有满,那么就会创建一个新的线程/进程用来执行该请求;但如果池中的线程/进程数已经达到规定最大值,那么该请求就会等待。
from multiprocessing import Pool
p = Pool(processes=4) # 允许最多同时放入4个进程,自由调配子程序。默认是本机的CPU核数。
for i in range(20): # 开启20个进程
res = p.apply_async(func=task, args=(x,), callback='回调函数') # 异步运行进程池,func传入函数,arg是元组,有返回结果
p.close() # 调用join()之前必须先调用close()
p.join() # 等待目前子进程结束后,继续运行下一个子进程。如果没有则进入主进程
14.threading.local()的作用
实现线程的不同函数之间局部变量的传递。
threading.local()最常用的地方:
为每个线程绑定一个资源(数据库连接,HTTP请求,用户身份信息等),这样一个线程的所有调用到的处理函数都可以非常方便地访问这些资源。
15.进程之间如何进行通信?
线程/进程彼此之间互相隔离,要实现线程/进程间通信,Python提供了队列Queue(线程通信)、管道Pipe(进程通信)等多种方式来交换数据。
Queue主要方法:put(),get()
Pipe主要方法:send(),recv()
16.什么是并发和并行?
并发:同一时刻只能处理一个任务,但可以交替处理多个任务。(一个处理器同时处理多个任务)
并行:同一时刻可以处理多个任务。(多个处理器或者是多核的处理器同时处理多个不同的任务)
类比:并发是一个人同时吃三个馒头,而并行是三个人同时吃三个馒头。
17.进程锁和线程锁的作用
为了保证数据安全,Python设计了锁,即同一时刻只允许一个线程或进程操作数据。
18.同步和异步,阻塞和非阻塞的区别?
同步:执行一个操作之后,需要主动等待返回结果;
异步:执行一个操作之后,不需要主动等待返回结果,若接收到结果通知,再回来执行刚才没执行完的操作。
同步和异步关心的问题是:要不要主动等待结果。
阻塞:在执行一个操作时,不能做其他操作;
非阻塞:在执行一个操作时,能做其他操作。
阻塞和非阻塞关心的问题是:能不能做其他操作。
19.路由器和交换机的区别
- 交换机:是负责内网里面的数据传递(arp协议)根据MAC地址寻址。
路由器:在网络层,路由器根据路由表,寻找该ip的网段。 - 路由器可以把一个IP分配给很多个主机使用,这些主机对外只表现出一个IP。
交换机可以把很多主机连起来,这些主机对外各有各的IP。 - 交换机是做端口扩展的,也就是让局域网可以连进来更多的电脑。
路由器是用来做网络连接,也就是连接不同的网络。
20.什么是域名解析?
在互联网上,所有的地址都是ip地址,现阶段主要是IPv4(比如:110.110.110.110)。
但是这些ip地址太难记了,所以就出现了域名(比如http://baidu.com)。
域名解析就是将域名,转换为ip地址的这样一种行为。
21.如何修改本地hosts件?
Hosts是一个没有扩展名的系统文件,可以用记事本等工具打开,其作用就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库”,
当用户在浏览器中输入一个需要登录的网址时,系统会首先自动从Hosts文件中寻找对应的IP地址,
一旦找到,系统会立即打开对应网页,如果没有找到,则系统会再将网址提交给DNS域名解析服务器进行IP地址的解析。
文件路径:C:\WINDOWS\system32\drivers\etc。
将127.0.0.1 www.163.com 添加在最下面
修改后用浏览器访问“www.163.com”会被解析到127.0.0.1,导致无法显示该网页。
22.生产者消费者模型应用场景及优势
生产者与消费者模式是通过一个容器来解决生产者与消费者的强耦合关系,生产者与消费者之间不直接进行通讯,而是利用阻塞队列来进行通讯,生产者生成数据后直接丢给阻塞队列,消费者需要数据则从阻塞队列获取,实际应用中,生产者与消费者模式则主要解决生产者与消费者的生产与消费的速率不一致的问题,达到平衡生产者与消费者的处理能力,而阻塞队列则相当于缓冲区。
应用场景:用户提交订单,订单进入引擎的阻塞队列中,由专门的线程从阻塞队列中获取数据并处理。
优势:
- 解耦
假设生产者和消费者分别是两个类。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。将来如果消费者的代码发生变化,可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。 - 支持并发
生产者直接调用消费者的某个方法,还有另一个弊端。由于函数调用是同步的(或者叫阻塞的),在消费者的方法没有返回之前,生产者只能一直等着;而使用这个模型,生产者把制造出来的数据只需要放在缓冲区即可,不需要等待消费者来取。 - 支持忙闲不均
缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。等生产者的制造速度慢下来,消费者再慢慢处理掉。
23.什么是cdn?
目的是使用户可以就近到服务器取得所需内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度。
cdn 即内容分发网络
24.LVS是什么及作用?
LVS :Linux虚拟服务器
作用:LVS主要用于多服务器的负载均衡。
它工作在网络层,可以实现高性能,高可用的服务器集群技术。
它廉价,可把许多低性能的服务器组合在一起形成一个超级服务器。
它易用,配置非常简单,且有多种负载均衡的方法。
它稳定可靠,即使在集群的服务器中某台服务器无法正常工作,也不影响整体效果。另外可扩展性也非常好。
25.Nginx是什么及作用
Nginx是一款自由的、开源的、高性能的HTTP服务器和反向代理服务器,同时也是一个IMAP、POP3、SMTP代理服务器。
可以用作HTTP服务器、方向代理服务器、负载均衡。
26.什么是负载均衡?
将服务器接收到的请求按照规则分发的过程,称为负载均衡。
27.twisted框架的应用
twisted是异步非阻塞框架。爬虫框架Scrapy依赖twisted。
28.大规模连接上来,并发模型怎么设计?
**多进程:**开启多个进程为客户端服务,同一时刻可为多个客户端提供服务,但是任务量大会因为创建进程的开销影响服务器性能。
**多线程:**一个进程内开启多个线程,同一时刻只能为一个客户端服务,I/O等待的时间可以进行别的任务,不会浪费时间,不影响服务器性能,推荐使用。
**协程:**协程的优势在于函数入口可以是上次停止的地方,显然对大规模连接没什么帮助。
所以这种情况推荐使用多线程来设计并发模式。
智能推荐
mysql语句_mysql服务启动语句-程序员宅基地
文章浏览阅读218次。mysql语句启动mysql services.msc登录mysql -uroot -proot退出exitmysql 数据库操作数据库表格操作修改表删除表表-数据-增删改查条件查询 (复杂)连接查询(连表查询)子查询 (一个查询的结果作为另一个查询的一部分)启动mysql services.msc登录mysql -uroot -proot退出exitmysql 数据库操作登录mysql -uroot -prootquit/exit查看当前使用数据库: select database();_mysql服务启动语句
网址跳转重定向浏览器html,域名301重定向页面转跳的操作方法-巅云建站-程序员宅基地
文章浏览阅读1.3k次。当网站地址变更时,需要将旧域名301重定向到新的URL地址,实际上就是把旧地址的访问请求重新引导到新域名上。301永久重定向无论是对用户还是搜索引擎都是比较友好的,对SEO完全没有不好的一面。通过旧网站的关键词排名和PR等级都会传递给新网站,网站更换了域名,用域名301永久重定向的方式告诉搜索引擎本网页已经永久性转移到新的域名,避免搜索引擎无法找到页面,网站对于搜索引擎相对比较友好。域名重定向的好..._一个域名301重定向到另一个域名的url上
【软考-软件设计师精华知识点笔记】第八章 算法分析设计_软考决策树-程序员宅基地
文章浏览阅读1.4k次,点赞2次,收藏11次。【软考-软件设计师精华知识点笔记】第八章 算法分析设计_软考决策树
ubuntu怎么切换到root用户,切换到root账号方法_unbuntu切换到root用户-程序员宅基地
文章浏览阅读2.7w次,点赞28次,收藏169次。ubuntu怎么切换到root用户,使用su root命令,去切换到root权限,会提示输入密码,可是如何也输不对,提示“Authentication failure”或者是提示认证失败。该错误有两种情况一个是密码错了,另一种就是新安装好的Linux系统,暂时还没有给root设置密码。1、打开Ubuntu,输入命令:su root,回车提示输入密码,如何输入都不对。2、给root用户设置密码,命令“sudo passwd root ” 。 输入密码,并确认密码。3、重新输入命_unbuntu切换到root用户
精选2022年大厂高频Java面试真题集锦(含答案),面试一路开挂_java程序员大厂真题解析 作者图灵学院 周瑜-程序员宅基地
文章浏览阅读6.6k次。本文涵盖了阿里巴巴、腾讯、字节跳动、京东、华为等大厂的Java面试真题,不管你是要面试大厂还是普通的互联网公司,这些面试题对你肯定是有帮助的,毕竟大厂一定是行业的发展方向标杆,很多公司的面试官同样会研究大厂的面试题。与此同时,今年算法面试一定是会被问的,而算法不是光靠背面试题就有用的,它是需要数学逻辑思维的,因此,小编会在文末为大家准备一份非常优质的算法学习手册,重点在于学习思维方法,话不多说,直接开始上精选的大厂面试真题!1.JAVA 中的几种数据类型是什么,各自占用多少字节。2.String 类能被继承_java程序员大厂真题解析 作者图灵学院 周瑜
HTMLQQ跳转三方实现聊天功能_htmlqq聊天超链接-程序员宅基地
文章浏览阅读960次。众所周知,我们的网页右侧一般都有一个组件,那就联系QQ这个功能的实现就是一行代码解决QQ推广是不允许复制粘贴网页里的代码< a href="http://wpa.qq.com/msgrd?v=3&uin=1393882772&site=qq&menu=yes">联系客服</a>利用超链接实现跳转外部QQ链接在任何标签里边都可以实现此功能..._htmlqq聊天超链接
随便推点
【超分辨率(Super-Resolution)】关于【超分辨率重建】专栏的相关说明,包含专栏简介、专栏亮点、适配人群、相关说明、阅读顺序、超分理解、实现流程、研究方向、论文代码数据集汇总等-程序员宅基地
文章浏览阅读8.5k次,点赞54次,收藏23次。本专栏研究领域为【超分辨率重建】,涵盖图像超分、视频超分,实时超分,4K修复等方面。主要内容包括主流算法模型的论文精读、论文复现、毕业设计、涨点手段、调参技巧、论文写作、应用落地等方面。算法模型从SRCNN开始更新至今,一般是一篇论文精读对应一篇论文复现。论文精读详解理论,归化繁为简,归纳核心,积累词句,培养阅读论文和论文写作能力。论文复现依托Pytorch代码,实现完整的模型训练流程,总结调参方法,记录碰到的bug,论文插图可视化,培养读写代码能力、做实验的能力、以及应用落地能力。
python upload_module_转:使用 Nginx Upload Module 实现上传文件功能-程序员宅基地
文章浏览阅读327次。普通网站在实现文件上传功能的时候,一般是使用Python,Java等后端程序实现,比较麻烦。Nginx有一个Upload模块,可以非常简单的实现文件上传功能。此模块的原理是先把用户上传的文件保存到临时文件,然后在交由后台页面处理,并且把文件的原名,上传后的名称,文件类型,文件大小set到页面。下面和大家具体介绍一下。一、编译安装Nginx为了使用Nginx Upload Module,需要编译安装..._向nginx_upload_module服务器上传文件的python脚本
Python技能树丨Python简介-程序员宅基地
文章浏览阅读1k次,点赞15次,收藏30次。 作者主页:不吃西红柿****一、为什么要学Python短短 20 年间,**「计算机和互联网」**以一种前所未有的速度,改变了人类的生活 。我们使用微信 「交流」,使用淘宝 「购物」,使用搜索引擎 「获取信息」,随着 Uber、滴滴、美团的出现,甚至我们的出行、吃饭都越来越离不开互联网了。而这些改变,都来源于编程。如果说上个世纪是全球化的时代,掌握了英语,就能成为时代的宠儿;那么在 语义识别 和 人工智能 愈发成熟的今天,**「人和人的沟通」**不再是难题, 「人和计算机的沟通」 会显得越来越重要。我
[享学Ribbon] 三、Ribbon核心API源码解析:ribbon-core(二)IClientConfig配置详解_iclientconfig lai-程序员宅基地
文章浏览阅读2.5k次。配置对于一个程序到底有多重要自然不用多说,每个库均有它自己的配置管理方式,比如Spring有`Enviroment`抽象等。本文即将介绍的是Ribbon中一个使用频繁,且非常重要的接口:`IClientConfig`,它负责Ribbon的**配置管理**,包括所有默认值的维护,以及提供提供其读写能力。_iclientconfig lai
Matlab中dir函数使用小技巧_matlab dir函数用法-程序员宅基地
文章浏览阅读9.5k次,点赞11次,收藏66次。想必很多小伙伴在matlab中对文件进行批处理时经常会使用dir函数吧,dir函数用于列出文件夹中的内容。使用语法如下:% Matlabdir % 列出当前文件夹中的文件和文件夹,当然调用方式也可以是listing = dirdir name % 列出当前文件夹中与name同名的文件和文件夹,不支持调用方式listing = dir namelisting = dir(name) % 列出当前文件夹中与name同名的文件和文件夹当_matlab dir函数用法
zeromq java 教程,如何使用Java运行ZeroMQ?-程序员宅基地
文章浏览阅读228次。I'm having an issue running ZeroMQ with Java using Eclipse and Windows XP. I've successfully installed [I think] the 0MQ libraries as well as the Java bindings. The instructions I used to do that are ..._zeromq java