Elasticsearch介绍及如何使用_elasticsearch match_phrase_prefix-程序员宅基地
技术标签: elasticsearch
是什么
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
基本概念:
- 节点(Node):
一个节点是一个单一的服务器,是你的集群的一部分,存储数据,并且参与集群的索引和搜索功能。
一个节点可以通过配置特定的集群名称来加入特定的集群。默认情况下,每个节点被设定加入一个名称为 “elasticsearch” 的集群,这意味着如果你在你的网络中启动了一些节点,并且假设它们能相互发现,它们将会自动组织并加入一个名称是 “elasticsearch” 的集群。 - 索引(Index):
可以近似的理解SQL中的数据库,虽然官方文档上说这是不好的。可以包涵表和数据。 - 类型(Type):(警告!Type在6.0.0版本中已经不赞成使用):
可以近似的理解成是SQL中的表,里面会包涵许多数据 - 文档(Document):
可以近似的理解是SQL中的表里的每一条数据。
去哪下:
官网下载传送
官网下载window版(我的是6.6.1版本)。
双击运行bin目录下的 elasticsearch.bat
怎么玩:
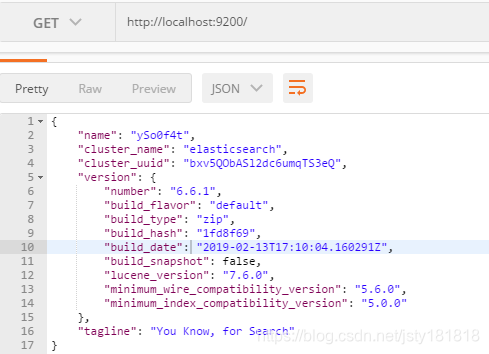
看到这个结果,说明安装,启动成功。
- 列出所有的索引:(GET)
http://localhost:9200/_cat/indices?v
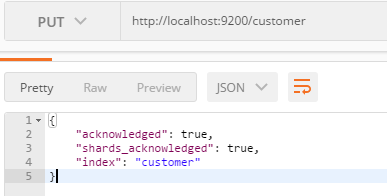
- 创建一个索引:(PUT)
http://localhost:9200/customer
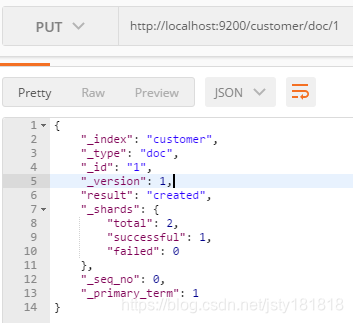
- 向索引中添加文档(PUT)
http://localhost:9200/customer/doc/1
//其中doc是类型。
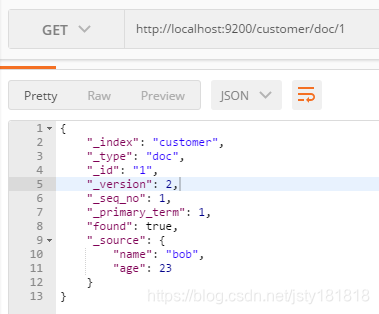
- 获取刚刚加入索引的文档:(GET)
http://localhost:9200/customer/doc/1
- 删除一个索引:(DELETE)
http://localhost:9200/customer
- 更新文档(POST)
除了能够新增和替换文档,我们也可以更新文档。注意虽然 Elasticsearch 在底层并没有真正更新文档,而是当我们更新文档时,Elasticsearch 首先去删除旧的文档,然后加入新的文档。
http://localhost:9200/customer/doc/1/_update?pretty
{
"doc": { "name": "Jane Doe" }
}
更新操作也可以使用简单的脚本来执行。如下的示例使用一个脚本将age增加了5:
http://localhost:9200/customer/doc/1/_update?pretty
{
"script" : "ctx._source.age += 5"
}
- 删除文档(DELETE):
http://localhost:9200/customer/doc/2?pretty
推荐使用Kibana进行数据查询
搜索:
- _mget(批量获取文档)
类似sql中的 id in(1,2,3)这样。
GET _mget
{
"docs":[
{
"_index": "bank",
"_type": "account",
"_id": "1",
"_source": ["balance", "city"]
},
{
"_index": "bank",
"_type": "account",
"_id": "5",
"_source": "firstname"
}
]
}
也可以简写:
GET /bank/account/_mget
{
"ids": ["1", "2", "4"]
}
-
_bulk(批量操作)
1.格式:
{action:{metadata}}
{requestbody}
其中action(行为)可以取值:
1.create:文档不存在时创建
2.update:更新文档
3.index:创建新文档或覆盖已有文档
4.delete:删除一个文档
create和index的区别:如果数据存在,使用create操作失败,会提示文档以存在,使用index可以成功执行。
如果使用create创建多个,其中有存在的,那么存在的返回失败,不存在的添加成功
其中metadata可以取值:
_index,_type,_id示例:
1.create:POST /bank/account/_bulk { "create":{ "_id":"999"}} { "account_number":999, "balance": 999} { "create":{ "_id":"1000"}} { "account_number":1000, "balance": 1000} { "create":{ "_id":"1001"}} { "account_number":1001, "balance": 1001}2.delete:
POST bank/account/_bulk { "delete":{ "_index":"bank", "_type":"account", "_id":"1000"}}3.update:
POST /bank/account/_bulk { "update":{ "_id":"1001"}} { "doc":{ "balance":"0"}} -
term:
用于查询指定字段包含某个词项的文档。这个查询不知道分词器的存在,所以搜索的值不会进行分词。只会拿搜索的值去倒排索引中找。
GET /bank/account/_search
{
"query":{
"term":{
"address":{
"value":"heath"
}
}
}
}
- match:
知道分词器的存在,所以搜索的值会被分词在去查询。
GET /bank/account/_search
{
"query":{
"match":{
"address":"511 Heath Place"
}
}
}
- multi_match:
可以指定多个字段,意思是:查找fields字段值的字段中包含query字段中对应的值
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
}
}
- match_phrase:
短语搜索,就是搜索含有指定的短语的数据。意思是搜索的值经过分词之后和es中分词保存的一致,顺序也一致,两头的可以少,中间的不可以少
GET /bank/account/_search
{
"query":{
"match_phrase":{
"address":"511 Heath Place"
}
}
}
- _source:
用来指定返回的字段:
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
},
"_source": ["firstname", "age"]
}
_可以写个数组来指定,也可以在 "source" 字段中加"includes"和"excludes"
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
},
"_source": {
"includes": ["age", "balance", "gen*"],
"excludes": ["gender"]
}
}
- sort:
用来排序,和关系型数据库的排序类似
GET /bank/account/_search
{
"query":{
"match_all":{
}
},
"sort":[
{
"balance":{
"order":"desc"
}
},
{
"age":{
"order":"asc"
}
}
]
}
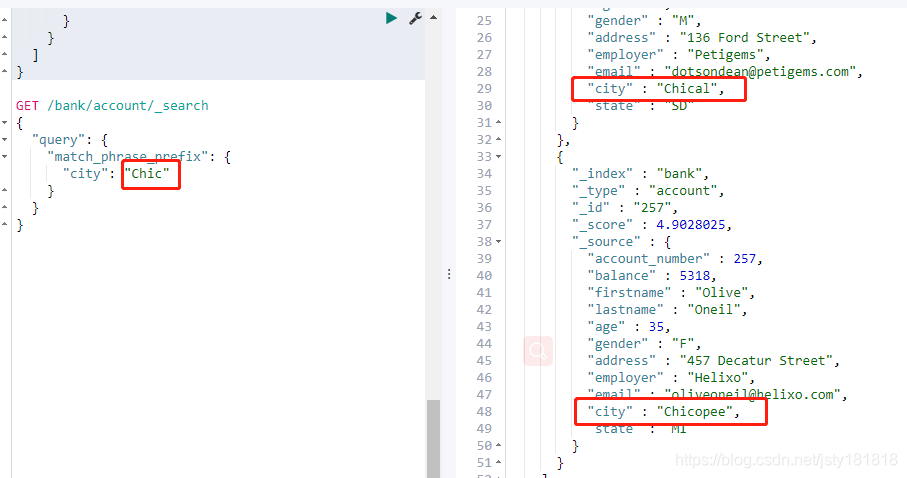
- match_phrase_prefix:
前缀匹配(查询的值不会分词,但是忽略大小写)
- range:
范围查询:
GET /bank/account/_search
{
"query":{
"range":{
"age":{
"gte": 20,
"lt": 30
}
}
}
}
- wildcard:
通配符匹配:
通配符:
* 代表任意多字符
? 代表一个字符
GET /bank/account/_search
{
"query":{
"wildcard":{
"city":{
"value": "nicho*n"
}
}
}
}
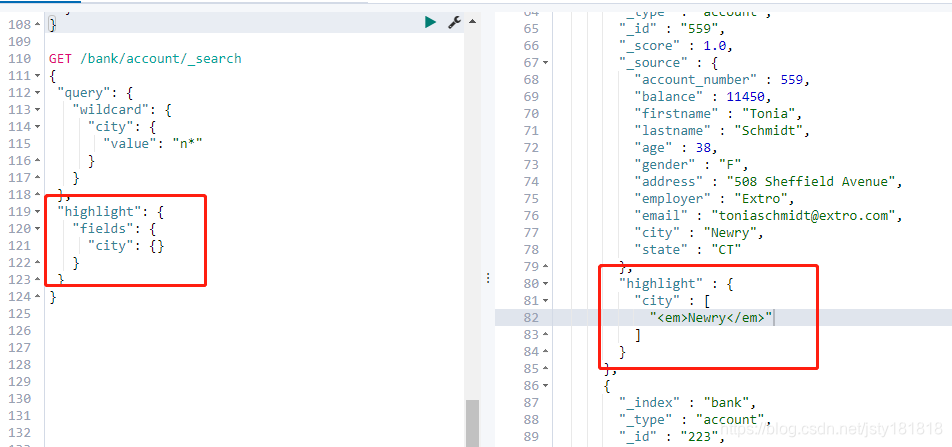
- highlight:
高亮显示:
GET /bank/account/_search
{
"query":{
"wildcard":{
"city":{
"value": "nicho*n"
}
}
},
"highlight":{
"fields":{
"city":{
}
}
}
}
- fuzzy:
模糊匹配,这个可不是mysql中的like,是可以错误的输入一些字 来进行匹配
GET /bank/account/_search
{
"query":{
"fuzzy":{
"city": "Nicho1so"
}
}
}
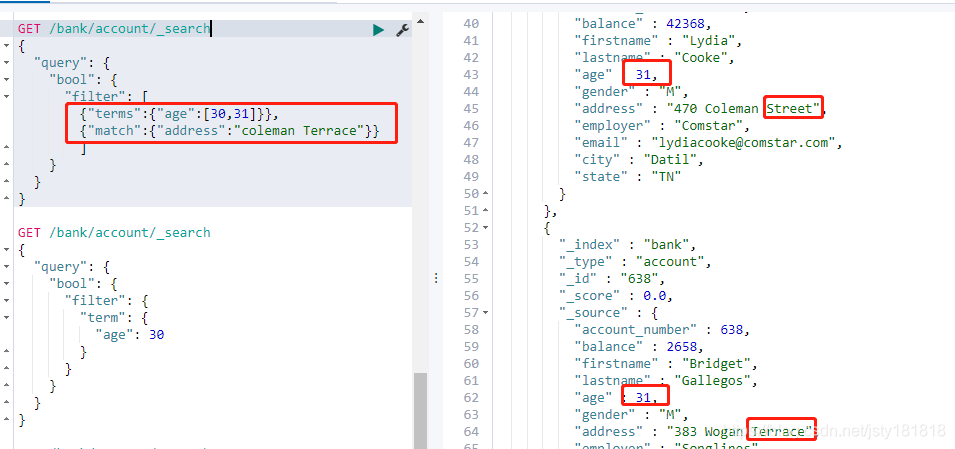
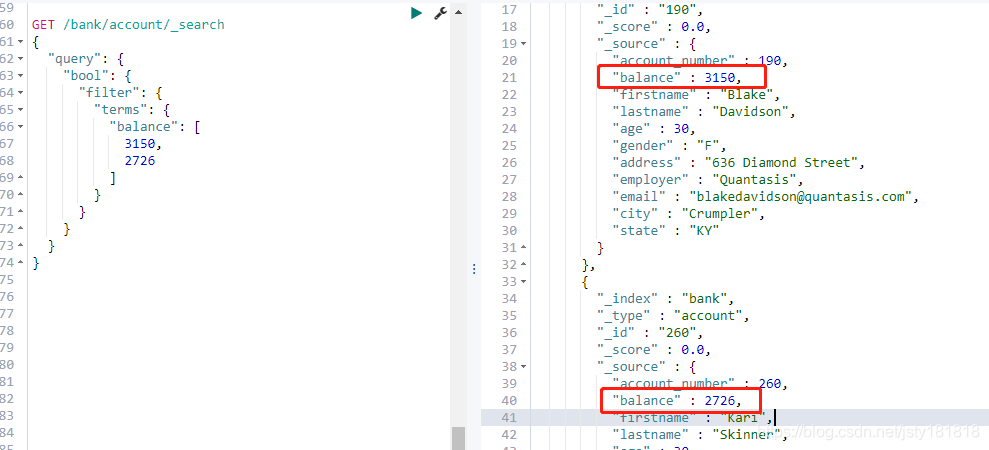
- filter查询:
过滤查询:
- must,should,must_not:
GET /bank/account/_search
{
"query":{
"bool":{
"must": [
{
"term":{
"age":{
"value" :20
}
}
}
]
}
}
}
- exists:
查询某个字段不为空
GET /bank/account/_search
{
"query":{
"bool":{
"filter": {
"exists":{
"field": "age"
}
}
}
}
}
- 聚合查询:
1.sum

智能推荐
linux里面ping www.baidu.com ping不通的问题_linux桥接ping不通baidu-程序员宅基地
文章浏览阅读3.2w次,点赞16次,收藏90次。对于这个问题我也是从网上找了很久,终于解决了这个问题。首先遇到这个问题,应该确认虚拟机能不能正常的上网,就需要ping 网关,如果能ping通说明能正常上网,不过首先要用命令route -n来查看自己的网关,如下图:第一行就是默认网关。现在用命令ping 192.168.1.1来看一下结果:然后可以看一下电脑上面百度的ip是多少可以在linux里面ping 这个IP,结果如下:..._linux桥接ping不通baidu
android 横幅弹出权限,有关 android studio notification 横幅弹出的功能没有反应-程序员宅基地
文章浏览阅读512次。小妹在这里已经卡了2-3天了,研究了很多人的文章,除了低版本api 17有成功外,其他的不是channel null 就是没反应 (channel null已解决)拜托各位大大,帮小妹一下,以下是我的程式跟 gradle, 我在这里卡好久又没有人可问(哭)public class MainActivity extends AppCompatActivit..._android 权限申请弹窗 横屏
CNN中padding参数分类_cnn “相同填充”(same padding)-程序员宅基地
文章浏览阅读1.4k次,点赞4次,收藏6次。valid padding(有效填充):完全不使用填充。half/same padding(半填充/相同填充):保证输入和输出的feature map尺寸相同。full padding(全填充):在卷积操作过程中,每个像素在每个方向上被访问的次数相同。arbitrary padding(任意填充):人为设定填充。..._cnn “相同填充”(same padding)
Maven的基础知识,java技术栈-程序员宅基地
文章浏览阅读790次,点赞29次,收藏28次。手绘了下图所示的kafka知识大纲流程图(xmind文件不能上传,导出图片展现),但都可提供源文件给每位爱学习的朋友一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长![外链图片转存中…(img-Qpoc4gOu-1712656009273)][外链图片转存中…(img-bSWbNeGN-1712656009274)]
getFullYear()和getYear()有什么区别_getyear和getfullyear-程序员宅基地
文章浏览阅读469次。Date对象取得年份有getYear和getFullYear两种方法经 测试var d=new Date;alert(d.getYear())在IE中返回 2009,在Firefox中会返回109。经查询手册,getYear在Firefox下返回的是距1900年1月1日的年份,这是一个过时而不被推荐的方法。而alert(d.getFullYear())在IE和FF中都会返回2009。因此,无论何时都应使用getFullYear来替代getYear方法。例如:2016年用 getFullYea_getyear和getfullyear
Unix传奇 (上篇)_unix传奇pdf-程序员宅基地
文章浏览阅读182次。Unix传奇(上篇) 陈皓 了解过去,我们才能知其然,更知所以然。总结过去,我们才会知道我们明天该如何去规划,该如何去走。在时间的滚轮中,许许多的东西就像流星一样一闪而逝,而有些东西却能经受着时间的考验散发着经久的魅力,让人津津乐道,流传至今。要知道明天怎么去选择,怎么去做,不是盲目地跟从今天各种各样琳琅满目前沿技术,而应该是去 —— 认认真真地了解和回顾历史。 Unix是目前还在存活的操作系_unix传奇pdf
随便推点
ACwing 哈希算法入门:_ac算法 哈希-程序员宅基地
文章浏览阅读308次。哈希算法:将字符串映射为数字形式,十分巧妙,一般运用为进制数,进制据前人经验,一般为131,1331时重复率很低,由于字符串的数字和会很大,所以一般为了方便,一般定义为unsigned long long,爆掉时,即为对 2^64 取模,可以对于任意子序列的值进行映射为数字进而进行判断入门题目链接:AC代码:#include<bits/stdc++.h>using na..._ac算法 哈希
VS配置Qt和MySQL_在vs中 如何装qt5sqlmysql模块-程序员宅基地
文章浏览阅读952次,点赞13次,收藏27次。由于觉得Qt的编辑界面比较丑,所以想用vs2022的编辑器写Qt加MySQL的项目。_在vs中 如何装qt5sqlmysql模块
【渝粤题库】广东开放大学 互联网营销 形成性考核_画中画广告之所以能有较高的点击率,主要由于它具有以下特点-程序员宅基地
文章浏览阅读1k次。选择题题目:下面的哪个调研内容属于经济环境调研?()题目:()的目的就是加强与客户的沟通,它是是网络媒体也是网络营销的最重要特性。题目:4Ps策略中4P是指产品、价格、顾客和促销。题目:网络市场调研是目前最为先进的市场调研手段,没有任何的缺点或不足之处。题目:市场定位的基本参数有题目:市场需求调研可以掌握()等信息。题目:在开展企业网站建设时应做好以下哪几个工作。()题目:对企业网站首页的优化中,一定要注意下面哪几个方面的优化。()题目:()的主要作用是增进顾客关系,提供顾客服务,提升企业_画中画广告之所以能有较高的点击率,主要由于它具有以下特点
爬虫学习(1):urlopen库使用_urlopen the read operation timed out-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏5次。以爬取CSDN为例子:第一步:导入请求库第二步:打开请求网址第三步:打印源码import urllib.requestresponse=urllib.request.urlopen("https://www.csdn.net/?spm=1011.2124.3001.5359")print(response.read().decode('utf-8'))结果大概就是这个样子:好的,继续,看看打印的是什么类型的:import urllib.requestresponse=urllib.r_urlopen the read operation timed out
分享读取各大主流邮箱通讯录(联系人)、MSN好友列表的的功能【升级版(3.0)】-程序员宅基地
文章浏览阅读304次。修正sina.com/sina.cn邮箱获取不到联系人,并精简修改了其他邮箱代码,以下就是升级版版本的介绍:完整版本,整合了包括读取邮箱通讯录、MSN好友列表的的功能,目前读取邮箱通讯录支持如下邮箱:gmail(Y)、hotmail(Y)、 live(Y)、tom(Y)、yahoo(Y)(有点慢)、 sina(Y)、163(Y)、126(Y)、yeah(Y)、sohu(Y) 读取后可以发送邮件(完..._通讯录 应用读取 邮件 的相关
云计算及虚拟化教程_云计算与虚拟化技术 教改-程序员宅基地
文章浏览阅读213次。云计算及虚拟化教程学习云计算、虚拟化和计算机网络的基本概念。此视频教程共2.0小时,中英双语字幕,画质清晰无水印,源码附件全课程英文名:Cloud Computing and Virtualization An Introduction百度网盘地址:https://pan.baidu.com/s/1lrak60XOGEqMOI6lXYf6TQ?pwd=ns0j课程介绍:https://www.aihorizon.cn/72云计算:概念、定义、云类型和服务部署模型。虚拟化的概念使用 Type-2 Hyperv_云计算与虚拟化技术 教改