Database_partition all share nothing-程序员宅基地
技术标签: DataBase
发展前沿 · NewSQL数据库概述
传统的关系型数据库有着悠久的历史,从上世纪60年代开始就已经在航空领域发挥作用。因为其严谨的强一致保证以及通用的关系型数据模型接口,获得了越来越多的应用,大有一统天下的气势。这期间,涌现出了一批佼佼者,其中有优秀的商业化数据库如Oracle,DB2,SQL Server等,也有我们耳熟能详的开源数据库MySQL及PostgreSQL。这里不严谨的将这类传统数据库统称为SQL数据库。
SQL to NoSQL
2000年以后,随着互联网应用的出现,很多场景下,并不需要传统关系型数据库提供的强一致性以及关系型数据模型。相反,由于快速膨胀和变化的业务场景,对可扩展性(Scalability)以及可靠性(Reliable)更加需要,而这个又正是传统关系型数据库的弱点。自然地,新的适合这种业务特点的数据库NoSQL开始出现,其中最句代表性的是Amazon的Dynamo以及Google的BigTable,以及他们对应的开源版本像Cassandra以及HBase。由于业务模型的千变万化,以及抛弃了强一致和关系型,大大降低了技术难度,各种NoSQL版本像雨后春笋一样涌现,基本成规模的互联网公司都会有自己的NoSQL实现。主要可以从两个维度来对各种NoSQL做区分:
- 按元信息管理方式划分:以Dynamo[1]为代表的对等节点的策略,由于没有中心节点的束缚有更高的可用性。而采用有中心节点的策略的,以BigTable[2]为代表的的数据库,则由于减少全网的信息交互而获得更好的可扩展性。
- 按数据模型划分:针对不同业务模型出现的不同数据模型的数据库,比较知名的有文档型数据库MongoDB,KV数据库Redis、Pika,列数据库Cassandra、HBase,图数据库Neo4J。
NoSQL to New SQL
NoSQL也有很明显的问题,由于缺乏强一致性及事务支持,很多业务场景被NoSQL拒之门外。同时,缺乏统一的高级数据模型、访问接口,又让业务代码承担了很多的负担。图灵奖得主Michael Stonebraker甚至专门发文声讨,”Why Enterprises Are Uninterested in NoSQL” [3] 一文中,列出了NoSQL的三大罪状:No ACID Equals No Interest, A Low-Level Query Language is Death,NoSQL Means No Standards。数据库的历史就这样经历了否定之否定,又螺旋上升的过程。而这一次,鱼和熊掌我们都要。
核心问题:分片(PARTITION)
如何能在获得SQL的强一致性、事务支持的同时,获得NoSQL的可扩展性及可靠性。答案显而易见,就是要在SQL的基础上像NoSQL一样做分片。通过分片将数据或计算打散到不同的节点,来摆脱单机硬件对容量和计算能力的限制,从而获得更高的可用性、性能以及弹性:
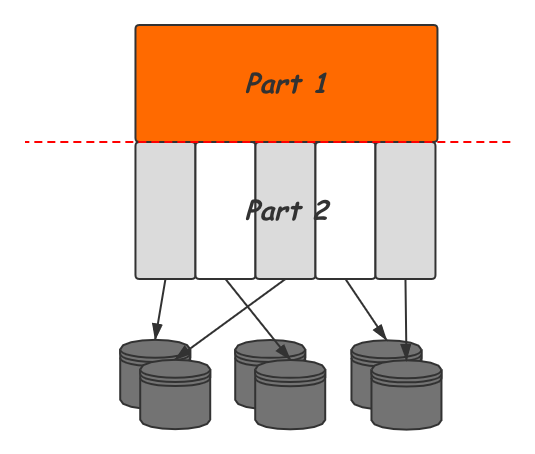
那么如何做分片呢,上图是一个高度抽象的数据库分片示意图,我们将数据库系统划分为上下两个部分,Part 1保持不动,将Part 2进行分片打散,由不同的节点负责,并在分片间通过副本方式保证高可用。同时,Part 2部分的功能由于被多个节点分担,也可以获得并行执行带来的性能提升。
所以现在实现NewSQL的核心问题变成了:确定一条分割线将数据库系统划分为上下两个部分,对Part 2做分片打散。而这条分割线的确定就成了主流NewSQL数据库的不同方向,不同的选择带来的不同的ACID实现方式,以及遇到的问题也大不相同。下图展示了更详细的数据库系统内部结构,以及主流的分界线选择及工业实现代表:
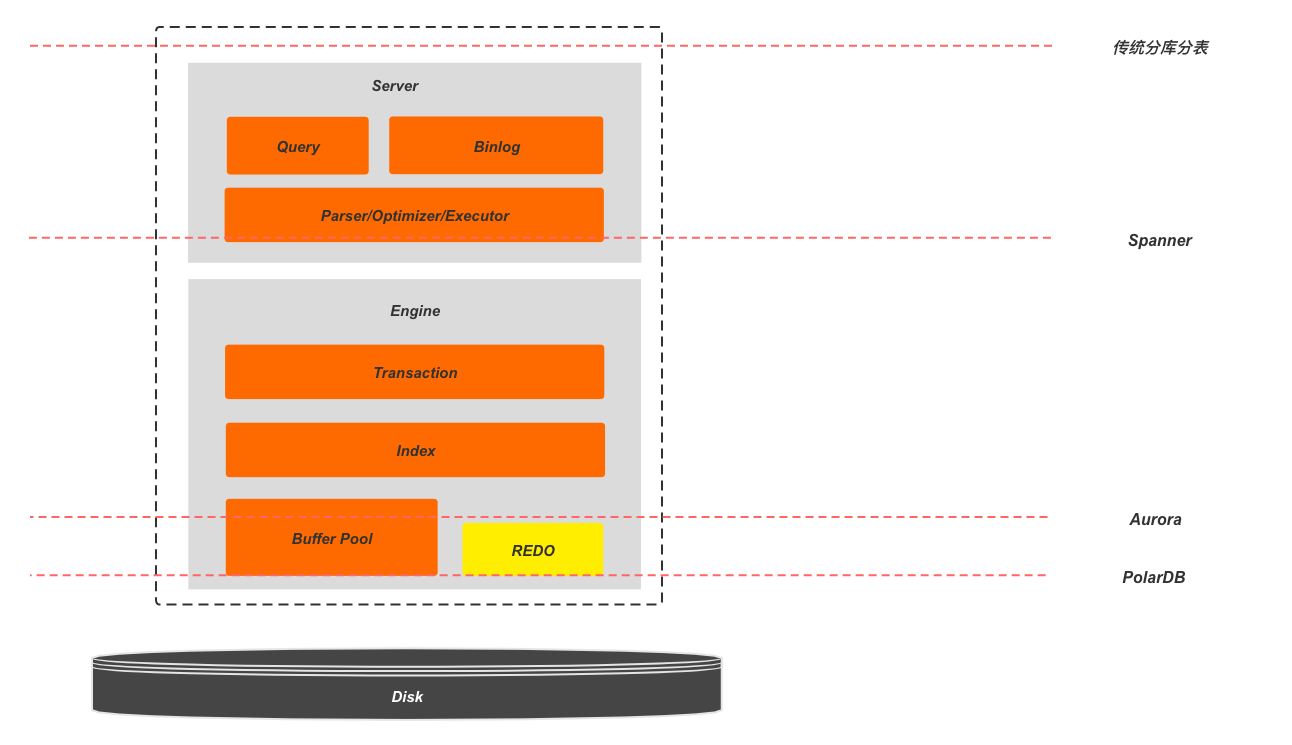
为了方便说明,本文中根据这个分片分割线的位置,将不同的方案命名为:Partition All、Partition Engine、Partiton Storage 以及 Partition Disk。这里先说结论:随着分片层次的下降,可扩展性会降低,但易用性和生态兼容性会增大。下面就分别介绍每种选择中需要解决的问题,优缺点,使用场景以及代表性工业实现的实现方式。
PARTITION ALL:分库分表
最直观的想法,就是直接用多个DB实例共同服务,从而缓解单机数据库的限制,这也是很多大公司内部在业务扩张期的第一选择。这种方式相当于是在数据库系统的最顶层就做了Partition,理想情况下,整个数据库的各个模块可以全部并发执行起来。

采用分库分表的首要问题就是如何对数据进行分片,常见的就是在表或者库的维度水平或垂直的进行分片。这里分片的选择是非常关键的,良好的,适应业务模式的分片可以让多DB实例尽量的并发起来获得最好的扩展性能。而不合适的分片则可能导致大量的跨节点访问,导致负载不均衡,或引入访问瓶颈。除分片策略之外,由于跨节点的访问需要,会有一些通用的问题需要解决,比如如何在分片之间支持分布式事务,处理分布式Query拆分和结果合并,以及全局自增ID的生成等。而且,最重要的,所有这些新增的负担全部要业务层来承担,极大的增加了业务的成本。
因此,分库分表的模式,在良好的业务侧设计下可以获得极佳的扩展性,取得高性能、大容量的数据库服务。但业务耦合大,通用性差,需要用户自己处理分片策略、分布式事务、分布式Query。这也是为什么在各大公司内部都有成熟稳定的分库分表的数据库实现的情况下,这些实现却很难对外通用的输出。
PARTITION ENGINE: SPANNER
我们将Part 1和Part2的分界线下移,到Server层之下,也就是只在引擎层做Partition。这种模式由于节点间相对独立,也被称作Share Nothing架构。相对于传统分库分表,Partition Engine的方式将之前复杂的分布式事务,分布式Query等处理放到了数据库内部来处理。
本文就以分布式事务为例,来尝试解释这种分片层次所面对的问题和解决思路。要支持事务就需要解决事务的ACID问题。而ACID的问题在分布式的环境下又变得复杂很多:

A(Atomicity),在传统数据库系统中,通过REDO加UNDO的方式容易解决这个问题[4],但当有多个不同的节点参与到同一个事务中的时候问题变的复杂起来,如何能把保证不同节点上的修改同时成功或同时回滚呢,这个问题有成熟的解决方案,就是2PC(Two-Phase Commit Protocol),引入Coordinator角色和prepare阶段来在节点间协商。
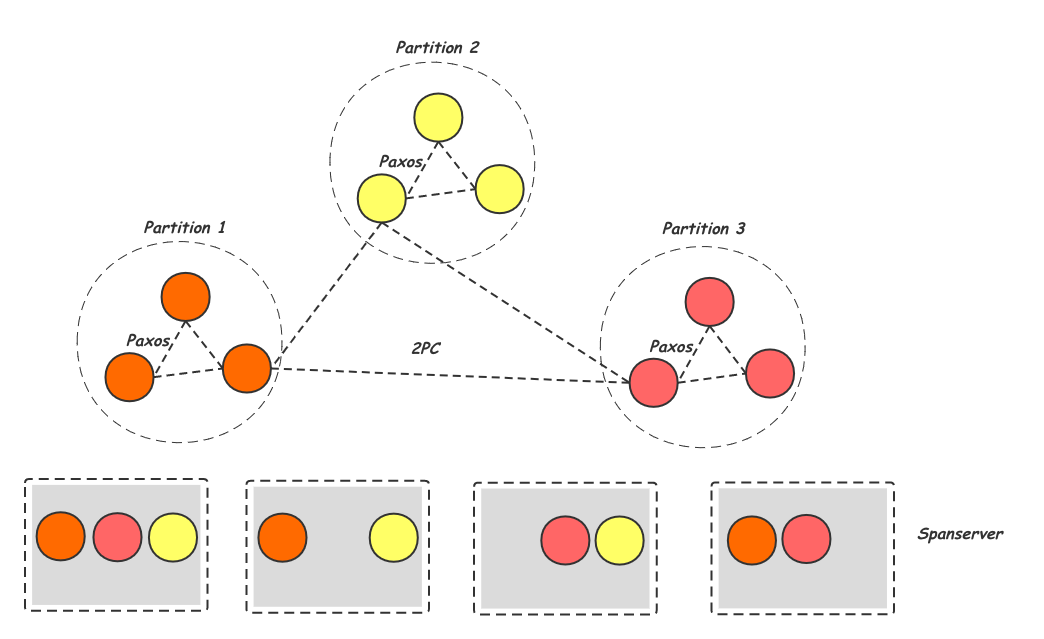
D (Durability),单机数据库中,我们通过REDO配合Buffer Pool的刷脏策略可以保证节点重启后可以看到已经提交的事务[4]。而在分布式环境中通常会需要更高的可用性,节点宕机后马上需要有新的节点顶上。这里的解决方案也比较成熟,就是给分片提供多个副本(通常是3个),每个副本由不同的节点负责,并且采用一致性算法Multi-Paxos[6]或其变种来保证副本间的一致性。下图是Spanner的实现方式,每个spanserver节点负责不同partition的多个分片,每个partition的副本之间用Paxos来保证其一致性,而跨Partition的事务则用2PC来保证原子。
I(Isolation),“数据库并发控控制”[5]一文中介绍过,是实现并发控制最直观的做法是2PL(两阶段锁),之后为了减少读写之间的加锁冲突,大多数数据库都采取了2PL + MVCC的实现方式,即通过维护多版本信息来让写请求和读请求可以并发执行。而MVCC的实现中有十分依赖一个全局递增的事务执行序列,用来判断事务开始的先后,从而寻找正确的可读历史版本。而这个全局递增的序列在分布式的数据库中变的十分复杂,原因是机器间的时钟存在误差,并且这种误差的范围不确定。常见的做法是通过节点间的信息交互来确定跨节点的时间先后,如Lamport时钟[7]。但更多的信息交互带来了瓶颈,从而限制了集群的扩展规模以及跨地域的复制。Spanner[8]提出了一种新的思路,通过引入GPS和原子钟的校准,在全球范围内,将不同节点的时钟误差限制到一个确定的范围内。这个确定的误差范围非常重要,因为他支持了一种可能:通过适度的等待保证事务的正确性。
具体的说,这里Spanner需要保证External Consistency,即如果事务T2开始在T1 commit之后, 那么T2拿到的Commit Timestamp一定要大于T1的Timestamp。Spanner实现这个保证的做法,是让事务等待其拿到的Commit Timestamp真正过去后才真正提交(Commit Wait):

如上图[9]所示,事务Commit时,首先通过TrueTime API获取一个当前时间now,这个时间是一个范围now = [t - ε, t + ε],那么这个t - ε就是作为这个事务的Commit Timestamp,之后要一直等待到TrueTime API返回的当前时间now.earliest > s时,才可以安全的开始做真正的comimt,这也就保证,这个事务commit以后,其他事务再也不会拿到更小的Timestamp。
总结下, 采用Partition Engine策略的NewSQL,向用户屏蔽了分布式事务等细节,提供统一的数据库服务,简化了用户使用。Spanner,CockroachDB,Oceanbase,TIDB都属于这种类型。这里有个值得探讨的问题:由于大多数分库分表的实现也会通过中间件的引入来屏蔽分布式事务等实现细节,同样采用类Multi Paxos这样的一致性协议来保证副本一致,同样对用户提供统一的数据库访问,那么相较而言,Partition Engine的策略优势又有多大呢?在大企业,银行等场景下, 这两种方案或许正在正面竞争,我们拭目以待[11]。
PARTITION STORAGE: AURORA、POLARDB
继续将分片的分界线下移,到事务及索引系统的下层。这个时候由于Part 1部分保留了完整的事务系统,已经不是无状态的,通常会保留单独的节点来处理服务。这样Part 1主要保留了计算相关逻辑,而Part 2负责了存储相关的像REDO,刷脏以及故障恢复。因此这种结构也就是我们常说的计算存储分离架构,也被称为Share Storage架构。
这种策略由于关键的事务系统并没有做分片处理,也避免了分布式事务的需要。而更多的精力放在了存储层的数据交互及高效的实现。这个方向最早的工业实现是Amazon的Aurora[12]。Aurora的计算节点层保留了锁,事务管理,死锁检测等影响请求能否执行成功的模块,对存储节点来说只需要执行持久化操作而不需要Vote。另外,计算节点还维护了全局递增的日志序列号LSN,通过跟存储节点的交互可以知道当前日志在所有分片上完成持久化的LSN位置,来进行实物提交或缓存淘汰的决策。因此,Aurora可以避免Partition Engine架构中面临的分布式事务的问题[18]。
Auraro认为计算节点与存储节点之间,存储节点的分片副本之间的网络交互会成为整个系统的瓶颈。而这些数据交互中的大量Page信息本身是可以通过REDO信息构建的,也就是说有大量的网络交互是冗余的,因此Aurora提出了“Log is Database”,也就是所有的节点间网络交互全部只传输REDO,每个节点本地自己在通过REDO的重放来构建需要的Page信息。
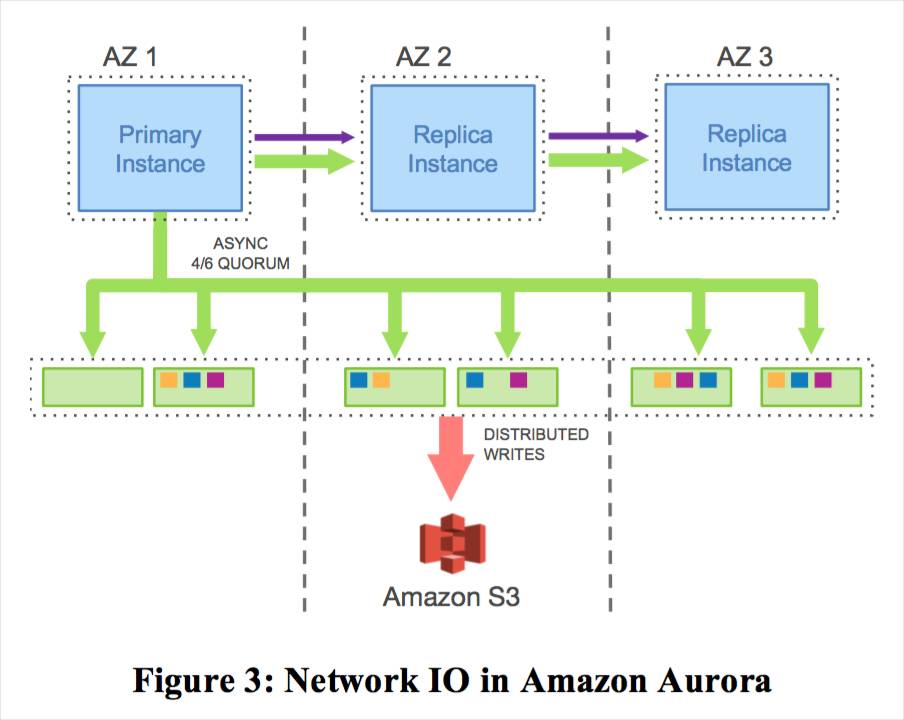
从上图可以看出,计算节点和存储节点之间传输的只有REDO,也就是是说,传统数据库中存储相关的部分从计算节点移到了存储节点中,这些功能包括:
- REDO日志的持久化
- 脏页的生成与持久化
- Recovery过程的REDO重放
- 快照及备份
这些功能对数据库整体的性能有非常大的影响:首先,根据ARIES[17]安全性要求,只有当REDO落盘后事务才能提交,这使得REDO的写速度很容易成为性能瓶颈;其次,当Buffer Pool接近满时,如果不能及时对Page做刷脏,后续的请求就会由于获取不到内存而变慢;最后,节点发生故障重启时,在完成REDO重放之前是无法对外提供服务的,因此这个时间会直接影响数据库的可用性。而在Aurora中,由于存储节点中对数据页做了分片打散,这些功能可以由不同的节点负责,得以并发执行,充分利用多节点的资源获得更大的容量,更好的性能。
PolarDB
2017年,由于RDMA的出现及普及,大大加快了网络间的网络传输速率,PolarDB[15]认为未来网络的速度会接近总线速度,也就是瓶颈不再是网络,而是软件栈。因此PolarDB采用新硬件结合Bypass Kernel的方式来实现高效的共享盘实现,进而支撑高效的数据库服务。由于PolarDB的分片层次更低,也就能做到更好的生态兼容,也就是为什么PolarDB能够很快的做到社区版本的全覆盖。副本间PoalrDB采用了ParalleRaft来允许一定范围内的乱序确认,乱序Commit以及乱序Apply。
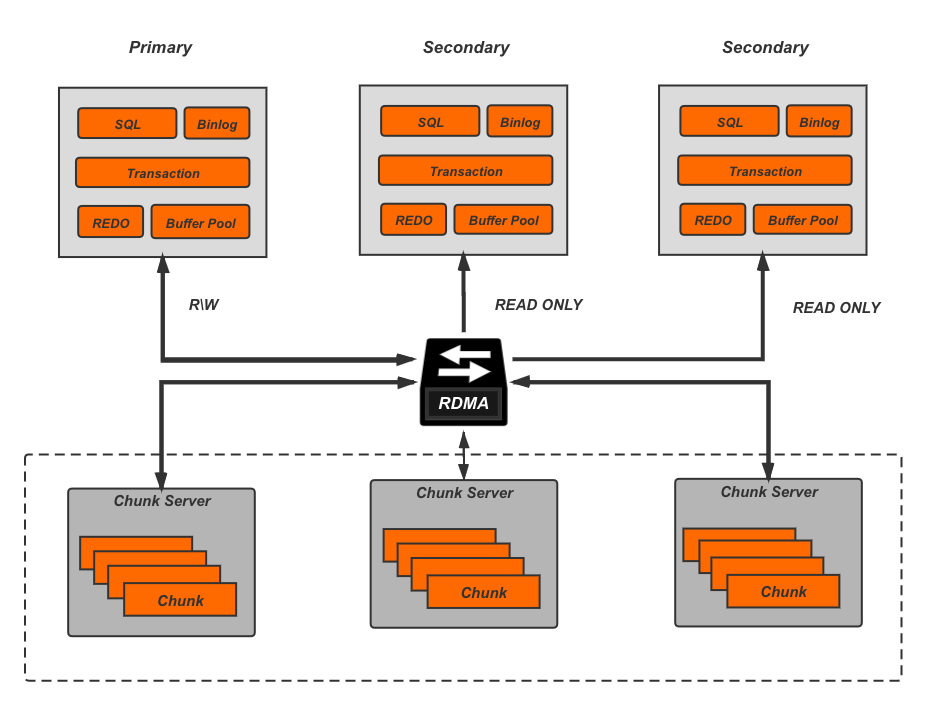
采用Partition Storage的策略的NewSQL,由于保持了完整的计算层,所以相对于传统数据库需要用户感知的变化非常少,能过做到更大程度的生态兼容。同时也因为只有存储层做了分片和打散,可扩展性不如上面提到的两种方案。在计算存储分离的基础上,Microsoft的Socrates[13]提出了进一步将Log模块拆分,实现Durability和Available的分离;Oracal的Cache Fusion[14]通过增加计算节点间共享的Memory来获得多点写及快速Recovery,总体来讲他们都属于Partition Storage这个范畴。
对比
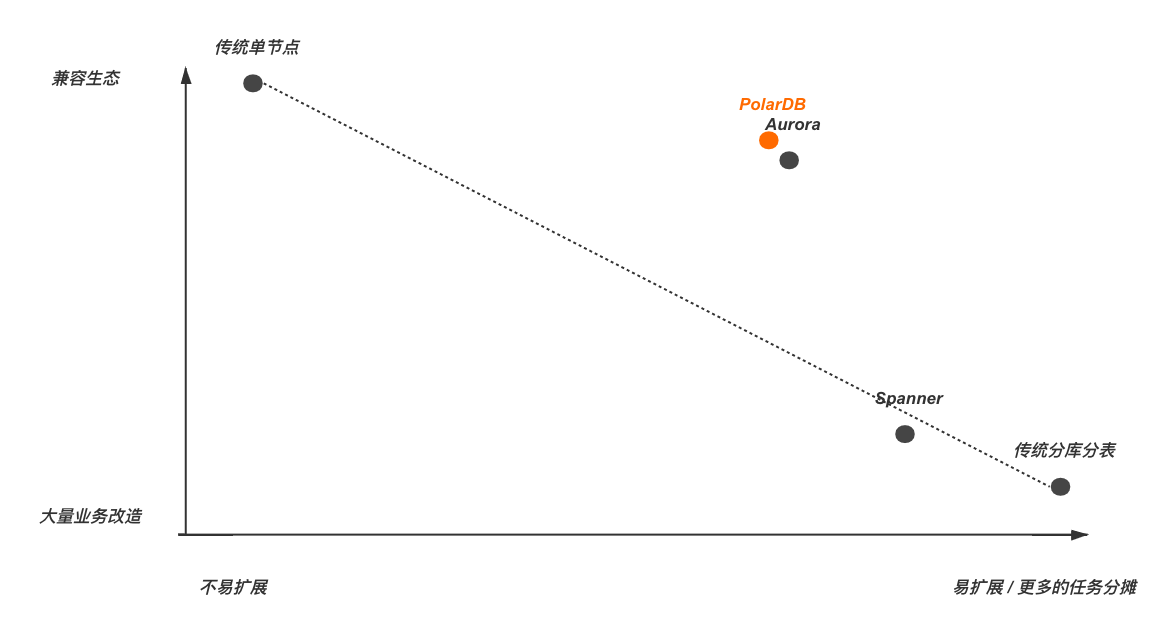
可以看出,如果我们以可扩展性为横坐标,易用及兼容生态作为纵坐标,可以得到如上图所示的坐标轴,越往右上角当然约理想,但现实是二者很难兼得,需要作出一定的取舍。首先来看传统的单节数据库其实就是不易扩展的极端,同时由于他自己就是生态所以兼容生态方面满分。另一个极端就是传统的分库分表实现,良好的分片设计下这种策略能一定程度下获得接近线性的扩展性。但需要做业务改造,并且需要外部处理分布式事务,分布式Query这种棘手的问题。之后以Spanner为代表的的Partition Engine类型的NewSQL由于较高的分片层次,可以获得接近传统分库分表的扩展性,因此容易在TPCC这样的场景下取得好成绩,但其需要做业务改造也是一个大的限制。以Aurora及PolarDB为代表的的Partition Storage的NewSQL则更倾向于良好的生态兼容,几乎为零的业务改造,来交换了一定程度的可扩展性。
使用场景上来看,大企业,银行等对用户对扩展性要求较高,可以接受业务改造的情况下,类Spanner的NewSQL及传统分库分表的实现正在正面竞争。而Aurora和PolarDB则在云数据库的场景下一统江湖。
参考
[3] Why Enterprises Are Uninterested in NoSQL
[18] Amazon Aurora: On Avoiding Distributed Consensus for I/Os, Commits, and Membership Changes
智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范