EDSR: Enhanced Deep Residual Networks for Single Image Super-Resolution-程序员宅基地
近年来,随着深度卷积神经网络(DCNN)的发展,超分辨率研究取得了进展。特别是,残余学习技术表现出改进的性能。在本文中,我们开发了一种增强型深度超分辨率网络(EDSR),其性能超过当前最先进的SR方法。我们的模型的显著性能改进是由于通过去除传统残余网络中不必要的模块进行了优化。在稳定训练过程的同时,通过扩大模型大小,进一步提高了性能。我们还提出了一种新的多尺度深度超分辨率系统(MDSR)和训练方法,该系统可以在单个模型中重建不同尺度因子的高分辨率图像。所提出的方法在基准数据集上表现出优于最先进方法的性能,并通过赢得NTIRE2017超级分辨率挑战证明了其卓越性[26]。
1. Introduction
几十年来,图像超分辨率(SR)问题,特别是单图像超分辨率问题(SISR),已经受到越来越多的研究关注。SISR旨在从单个低分辨率图像ILR重建高分辨率图像ISR。通常,ILR和原始高分辨率图像IHR之间的关系可以根据情况而变化。许多研究假设ILR是IHR的双三次下采样版本,但在实际应用中也可以考虑其他退化因素,如模糊、抽取或噪声。最近,深度神经网络[11,12,14]在SR问题中的峰值信号噪声比(PSNR)方面提供了显著改善的性能。然而,这样的网络在架构优化方面表现出局限性。此外,同一模型通过不同的初始化和训练技术实现了不同级别的性能。因此,请小心设计的模型架构和复杂的优化方法是训练神经网络的关键。
其次,大多数现有的SR算法将不同尺度因子的超分辨率视为独立问题,而没有考虑和利用SR中不同尺度之间的相互关系.VDSR[11]可以在单个网络中联合处理多个尺度的超分辨率。用多个尺度训练VDSR模型大大提高了性能,并优于特定尺度训练,这意味着特定尺度模型之间的冗余。尽管如此,VDSR风格的架构需要双三次插值图像作为输入,这导致与具有特定尺度上采样方法的架构相比,计算时间和内存更重[5,22,14]。
虽然SRResNet[14]以良好的性能成功地解决了这些时间和内存问题,但它只使用了He等人[9]的ResNet架构,没有进行太多修改。然而,最初的ResNet被提出用于解决更高级别的计算机视觉问题,例如图像分类和检测。因此,将ResNet架构直接应用于像超分辨率这样的低级别视觉问题可能是次优的。
为了解决这些问题,基于SRResNet架构,我们首先通过分析和删除不必要的模块来优化它,以简化网络架构。当模型复杂时,训练网络变得非常重要。因此,我们使用适当的损失函数来训练网络,并在训练后仔细修改模型。我们的实验表明,改进的方案产生了更好的结果。其次,我们研究了模型训练方法,该方法将知识从在其他尺度上训练的模型中转移。为了在训练期间利用尺度无关信息,我们从预训练的低尺度模型中训练高尺度模型。此外,我们提出了一种新的多尺度架构,该架构在不同尺度上共享大部分参数。与多个单尺度模型相比,所提出的多尺度模型使用的参数明显更少,但表现出可比的性能。
我们在标准基准数据集和新提供的DIV2K数据集上评估我们的模型。所提出的单尺度和多尺度超分辨率网络在PSNR和SSIM方面在所有数据集上显示出最先进的性能。我们的方法在NTIRE 2017超级分辨率挑战中分别排名第一和第二[26]。
2. Related Works
为了解决超分辨率问题,早期方法使用基于采样理论的插值技术[1,15,34]。然而,这些方法在预测详细、真实的纹理方面存在局限性。先前的研究[25,23]采用了自然图像统计来重建更好的高分辨率图像。高级工作旨在学习ILR和IHR图像对之间的映射函数。这些学习方法依赖于从邻居嵌入[3,2,7,21]到稀疏编码[31,32,27,33]的技术。Yang等人介绍了另一种聚类面片空间并学习相应函数的方法。一些方法利用图像自相似性来避免使用外部数据库[8,6,29],并通过面片的几何变换来增加有限内部字典的大小[10]。最近,深度神经网络的强大能力导致SR的显著改进。自从Dong等人[4],5]首次提出基于深度学习的SR方法以来,已经研究了SR的各种CNN架构。Kim等人[11,12]首次引入残差网络来训练更深层的网络架构,并取得了优异的性能。特别是,他们表明,skipconnection和递归卷积减轻了超分辨率网络中携带身份信息的负担。与[20]类似,Mao等人[16]利用编码器-解码器网络和对称跳过连接解决了一般的图像恢复问题。在[16]中,他们认为这些嵌套的跳跃连接提供了快速和改进的收敛性。
在许多基于深度学习的超分辨率算法中,输入图像在输入网络之前通过双三次插值进行上采样[4,11,12]。不使用插值图像作为输入,也可以在网络的最末端训练上采样模块,如[5,22,14]所示。通过这样做,可以在不损失模型容量的情况下减少大量计算,因为特征的大小减小了。然而,这些方法有一个缺点:它们不能像VDSR[11]那样在单个框架中处理多尺度问题。在这项工作中,我们解决了多尺度训练和计算效率的困境。我们不仅利用了每个尺度的学习特征的相互关系,还提出了一种新的多尺度模型,该模型可以有效地重建不同尺度的高分辨率图像。此外,我们开发了一种适当的训练方法,该方法对单尺度和多尺度模型都使用多尺度。
一些研究还集中于损失函数,以更好地训练网络模型。均方误差(MSE)或L2损失是一般图像恢复中使用最广泛的损失函数,也是这些问题的主要性能度量(PSNR)。然而,Zhao等人[35]报告,与PSNR和SSIM方面的其他损失函数相比,L2损失的训练不能保证更好的性能。在他们的实验中,与用L2训练的网络相比,用L1训练的网络获得了改进的性能。
3. Proposed Methods
在本节中,我们将描述所提出的模型架构。我们首先分析了最近发布的超分辨率网络,并提出了残差的增强版本具有更简单结构的网络架构。我们表明,我们的网络优于原始网络,同时显示出改进的计算效率。在以下章节中,我们建议使用单尺度架构(EDSR)处理特定的超分辨率尺度,使用多尺度架构(MDSR)在单个模型中重建各种尺度的高分辨率图像。
3.1. Residual blocks
最近,残差网络[11,9,14]在从低级到高级任务的计算机视觉问题中表现出优异的性能。尽管Ledig等人[14]成功地将ResNet架构应用于SRResNet的超分辨率问题,但我们通过采用更好的ResNet结构进一步提高了性能。
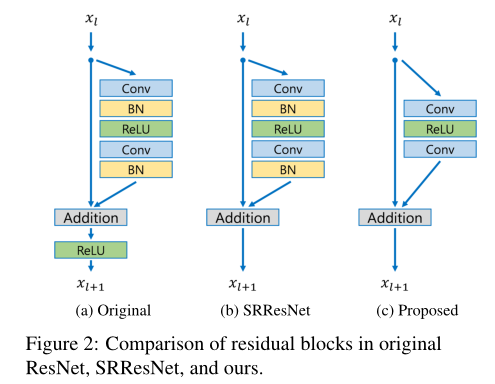
在图2中,我们比较了原始ResNet[9]、SRResNet[14]和我们提出的网络中每个网络模型的构建块。正如Nah等人[19]在图像去模糊工作中提出的那样,我们从网络中移除了批处理归一化层。由于批处理规范化层规范化了特征,它们通过规范化特征来消除网络的范围灵活性,因此最好将其移除。我们通过实验表明,这种简单的修改大大提高了性能,详见第4节。
此外,由于批处理规范化层消耗与先前卷积层相同的内存量,因此GPU内存使用也充分减少。与SRResNet相比,我们的基线模型没有批处理标准化层,在训练期间节省了大约40%的内存使用。因此,我们可以在有限的计算资源下建立比传统ResNet结构具有更好性能的更大模型。

3.2. Single-scale model
提高网络模型性能的最简单方法是增加参数数量。在卷积神经网络中,可以通过堆叠许多层或增加滤波器的数量来增强模型性能。具有深度(层的数量)B和宽度(特征信道的数量)F的一般CNN架构在具有O(BF 2)参数的情况下大致占据O(BF)存储器。因此,当考虑有限的计算资源时,增加F而不是B可以最大化模型容量。然而,我们发现,将特征图的数量增加到一定水平以上会使训练过程在数值上不稳定。Szegedy等人报道了类似的现象[24]。我们通过采用系数为0.1的残差缩放[24]来解决这个问题。在每个残差块中,在最后的卷积层之后放置恒定缩放层。当使用大量过滤器时,这些模块极大地稳定了训练过程。在测试阶段,可以将该层集成到先前的卷积层中,以提高计算效率。
我们用我们提出的残差块构建了我们的基线(单尺度)模型,如图2所示。结构类似于SRResNet[14],但我们的模型在残余块之外没有ReLU激活层。此外,我们的基线模型没有残余缩放层,因为我们对每个卷积层仅使用64个特征图。在我们的最终单尺度模型(EDSR)中,我们通过设置B=32,F=256以及比例因子0.1来扩展基线模型。模型架构如图3所示。

当为上采样因子×3和×4训练我们的模型时,我们使用预训练的×2网络初始化模型参数。如图4所示,这种预训练策略可以加速训练并提高最终成绩。对于放大×4,如果我们使用预先训练的尺度×2模型(蓝线),训练收敛速度比从随机初始化开始的训练快得多(绿线)。
3.3. Multi-scale model
从图4中的观察,我们得出结论,多尺度下的超分辨率是相互关联的任务。我们通过构建一个多尺度架构来进一步探索这一想法,该架构利用了VDSR[11]所做的尺度间相关性的优势。我们设计了基线(多尺度)模型,使其具有B=16个残差块的单个主分支,以便在不同尺度上共享大多数参数,如图5所示。
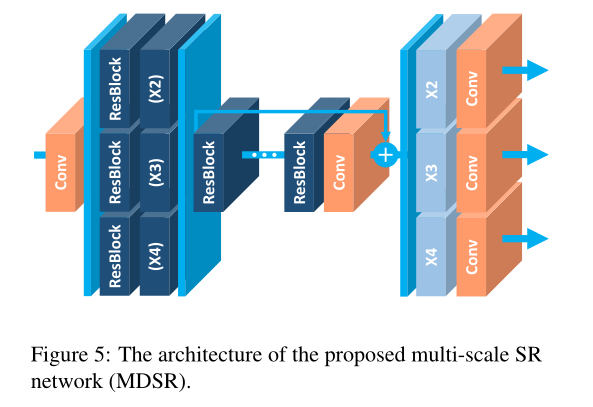
在我们的多尺度架构中,我们引入了特定于尺度的处理模块来处理多尺度的超分辨率。首先,预处理模块位于网络的前端,以减少来自不同尺度的输入图像的差异。每个预处理模块由两个5×5核的残差块组成。通过采用更大的内核作为预处理模块,我们可以在网络的早期阶段覆盖更大的感受野的同时保持尺度特定部分的浅。在多尺度模型的末尾,特定于尺度的上采样模块被并行放置以处理多尺度重建。上采样模块的架构与上一节中描述的单尺度模型的架构相似。我们构建了最终的多尺度模型(MDSR),B=80,F=64。虽然我们的3个不同尺度的单尺度基线模型各有约1.5M个参数,总计4.5M个,但我们的基线多尺度模型只有320万个参数。然而,多尺度模型表现出与单尺度模型相当的性能。此外,我们的多尺度模型在深度方面是可扩展的。尽管我们的最终MDSR与基线多尺度模型相比有5倍的深度,只需要2.5倍的参数,因为残余块比特定比例的部分更轻。注意,MDSR还显示了与特定规模的EDSR相当的性能。表2和表3给出了我们提出的模型的详细性能比较。
4. Experiments
4.1. Datasets
DIV2K数据集[26]是用于图像恢复任务的新提出的高质量(2K分辨率)图像数据集。DIV2K数据集由800个训练图像、100个验证图像和100个测试图像组成。由于未发布测试数据集的基本事实,我们报告并比较验证数据集的性能。我们还比较了四个标准基准数据集的性能:Set5[2]、Set14[33]、B100[17]和Urban100[10]
4.2. Training Details
对于训练,我们使用LR图像中大小为48×48的RGB输入块和相应的HR块。我们用随机水平翻转和90次旋转来增加训练数据。我们通过减去DIV2K数据集的平均RGB值来预处理所有图像。通过设置β1=0.9、β2=0.999和ǫ=10−8,我们的ADAM优化器模型[13]。我们将小批量设置为16。学习率初始化为10e-4,每2×10e5次小批量更新,学习率减半。对于单尺度模型(EDSR),我们按照第3.2节所述对网络进行训练。×2模型是从头开始训练的。在模型收敛后,我们将其用作其他尺度的预训练网络。在训练多尺度模型(MDSR)的每次更新时,我们构建具有在×2、×3和×4之间随机选择的尺度的小批量。仅启用和更新与所选比例对应的模块。因此,不启用或更新与所选比例以外的不同比例对应的比例特定残差块和上采样模块。我们使用L1损耗而不是L2来训练网络。最小化L2通常是优选的,因为它最大化了PSNR。然而,基于一系列实验,我们根据经验发现L1损失比L2提供更好的收敛性。第4节提供了该比较的评估。我们使用Torch7框架实现了拟议的网络,并使用NVIDIA Titan X GPU对其进行了培训。训练EDSR和MDSR分别需要8天和4天。源代码在网上公开。
4.3. Geometric Self-ensemble
......
4.4. Evaluation on DIV2K Dataset
我们在DIV2K数据集上测试了我们提出的网络。
从SRResNet开始,我们逐步更改各种设置以执行消融测试。我们自己训练SRResNet[14]。2 3首先,我们将损失函数从L2更改为L1,然后如前一节所述并在表1中总结的那样对网络架构进行改革。在这个实验中,我们用3×105个更新来训练所有这些模型。使用PSNR和SSIM标准对DIV2K验证集的10幅图像进行评估。对于评估,我们使用全RGB通道,忽略边界的(6+比例)像素。表2给出了定量结果。对于所有比例因子,用L1训练的SRResNet比用L2训练的原始SRResNet的结果稍好。网络的修改带来了更大的改进空间。表2的最后2列显示了我们最终的更大模型EDSR+和MDSR+的显著性能提高,采用几何自集成技术。注意,我们的模型需要更少的GPU内存,因为它们没有批处理标准化层。
 4.5. Benchmark Results
4.5. Benchmark Results
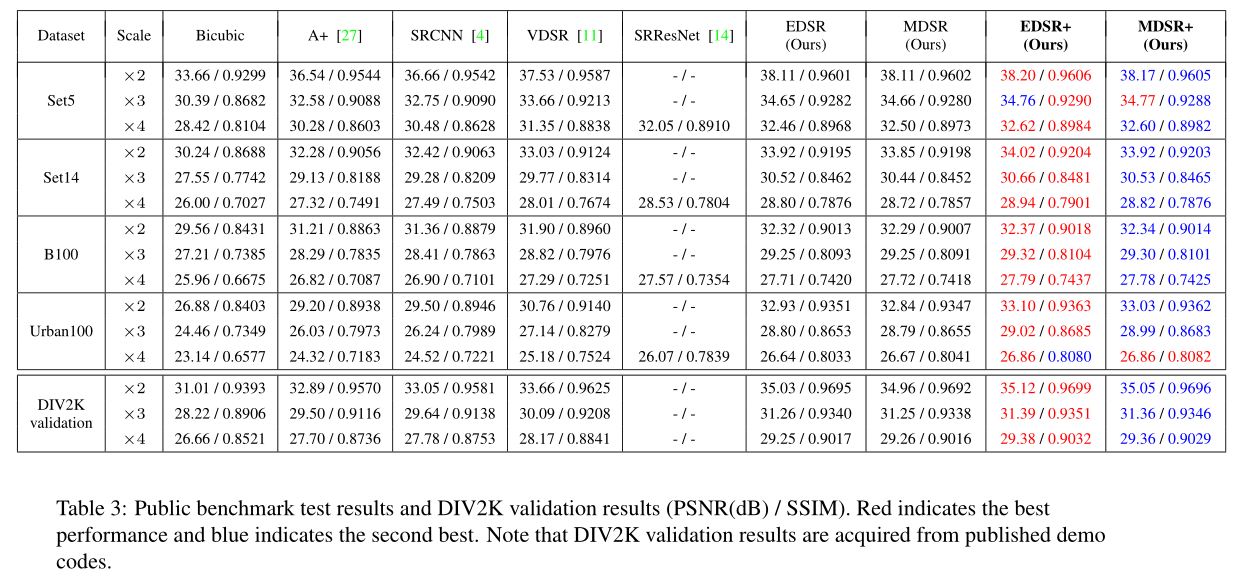
我们在表3中提供了对公共基准数据集的最终模型(EDSR+、MDSR+)的定量评估结果。最后两列还提供了对自集成的评估。我们使用106个批量大小为16的更新来训练我们的模型。我们保持其他设置与基线模型相同。我们将我们的模型与最先进的方法进行了比较,包括A+[27]、SRCNN[4]、VDSR[11]和SRResNet[14]。为了进行比较,我们在y通道上测量PSNR和SSIM,并忽略与边界比例相同的像素量。我们使用MA TLAB[18]函数进行评估。还提供了DVI2K数据集的比较结果。与其他方法相比,我们的模型显示出显著的改进。在执行自集成之后,间隙进一步增加。我们还在图6中展示了定性结果。所提出的模型成功地重建了HR图像中的详细纹理和边缘,并与之前的工作相比显示出更好的SR输出
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法