OpenMV(五)--STM32实现人脸识别_stm32人脸识别-程序员宅基地
技术标签: •OpenMV stm32 •嵌入式AI 嵌入式硬件 单片机
STM32实现人脸识别
引
OpenMV(一)–基础介绍与硬件架构
OpenMV(二)–IDE安装与固件下载
OpenMV(三)–实时获取摄像头图片
OpenMV(四)–STM32实现特征检测
前言
本专栏基于以STM32H743为MCU的OpenMV-H7基板,结合OV7725卷帘快门摄像头进行相关机器视觉应用的开发。人脸识别的前提是人脸检测,本篇博文基于OpenMV官方的Face-Detection例程,来解析一下怎么实现人脸识别。
1. 人脸检测
人脸检测就是通过摄像头实时获取的图片,来标记出人脸的位置。本节代码的目的就是将摄像头拍摄的画面中的人脸用矩形框表示出来。人脸检测的本质是特征识别,OpenMV中已经集成了非常多的特征库和算法库,比如image模块下的find_features()特征寻找函数。
1.1 构造函数
- image.find_features(cascade, threshold=0.5, scale=1.5, roi)
搜索和Haar Cascade匹配的所有区域的图像,并返回一个关于这些特征的边界框矩形元祖(x, ,y, w, h)的列表,若没有发现任何特征,则返回一个空白列表。基于Haar特征的cascade分类器一种有效的物品检测(object detect)方法。它是一种机器学习方法,通过许多正负样例中训练得到cascade方程,然后将其应用于其他图片。详细内容可以参考博客:使用Haar Cascade 进行人脸识别- cascade:Haar Cascade 对象
- threshold: 是浮点数(0.0-1.0),其中较小的值在提高检测速率同时增加误报率。相反,较高的值会降低检测速率,同时降低误报率。
- scale: 是一个必须大于1.0的浮点数。较高的比例因子运行更快,但是其图像匹配相应较差。理想值介于1.35到1.5之间。
- roi:指定识别区域的矩形元组(x, y, w, h)。如果没有指定,roi即整个图像的图像矩形。
1.2 源码分析
"""
人脸检测例程
利用Haar Cascade特征检测器来实现:一个Haar Cascade是一系列简单区域的对比检查,人脸识别有25个阶段,每个阶段有几百次检测。Haar Cascade运行很快是因为它是逐个阶段进行检测的。
OpenMV使用一种称为积分图像的数据结构来在恒定时间内快速执行每个区域的对比度检查
"""
# 导入相应的库
import sensor, image, time
# 初始化摄像头
sensor.reset()
# 设置相机图像的对比度为1
sensor.set_contrast(1)
# 设置相机的增益上限为16
sensor.set_gainceiling(16)
# 设置采集到照片的大小
sensor.set_framesize(sensor.HQVGA)
# 设置采集到照片的格式:灰色图像
sensor.set_pixformat(sensor.GRAYSCALE)
# 加载Haar Cascade 模型
# 默认使用25个步骤,减少步骤会加快速度但会影响识别成功率
face_cascade = image.HaarCascade("frontalface", stage = 25)
print(face_cascade)
# 创建一个时钟来计算摄像头每秒采集的帧数FPS
clock = time.clock()
while(True):
# 更新FPS时钟
clock.tick()
# 拍摄图片并返回img
img = sensor.snapshot()
# 寻找人脸对象
# threshold和scale_factor两个参数控制着识别的速度和准确性
objects = img.find_features(face_cascade, threshold=0.75, scale_factor=1.25)
# 用矩形将人脸画出来
for r in objects:
img.draw_rectangle(r)
# 串口打印FPS参数
print(clock.fps())
我们将板子连接到OpenMV IDE, 新建文件,并将上述代码copy进去,点击左下角的绿色按钮,我们就可以看到IDE右边的窗口在实时显示提取到的人脸特征图片:
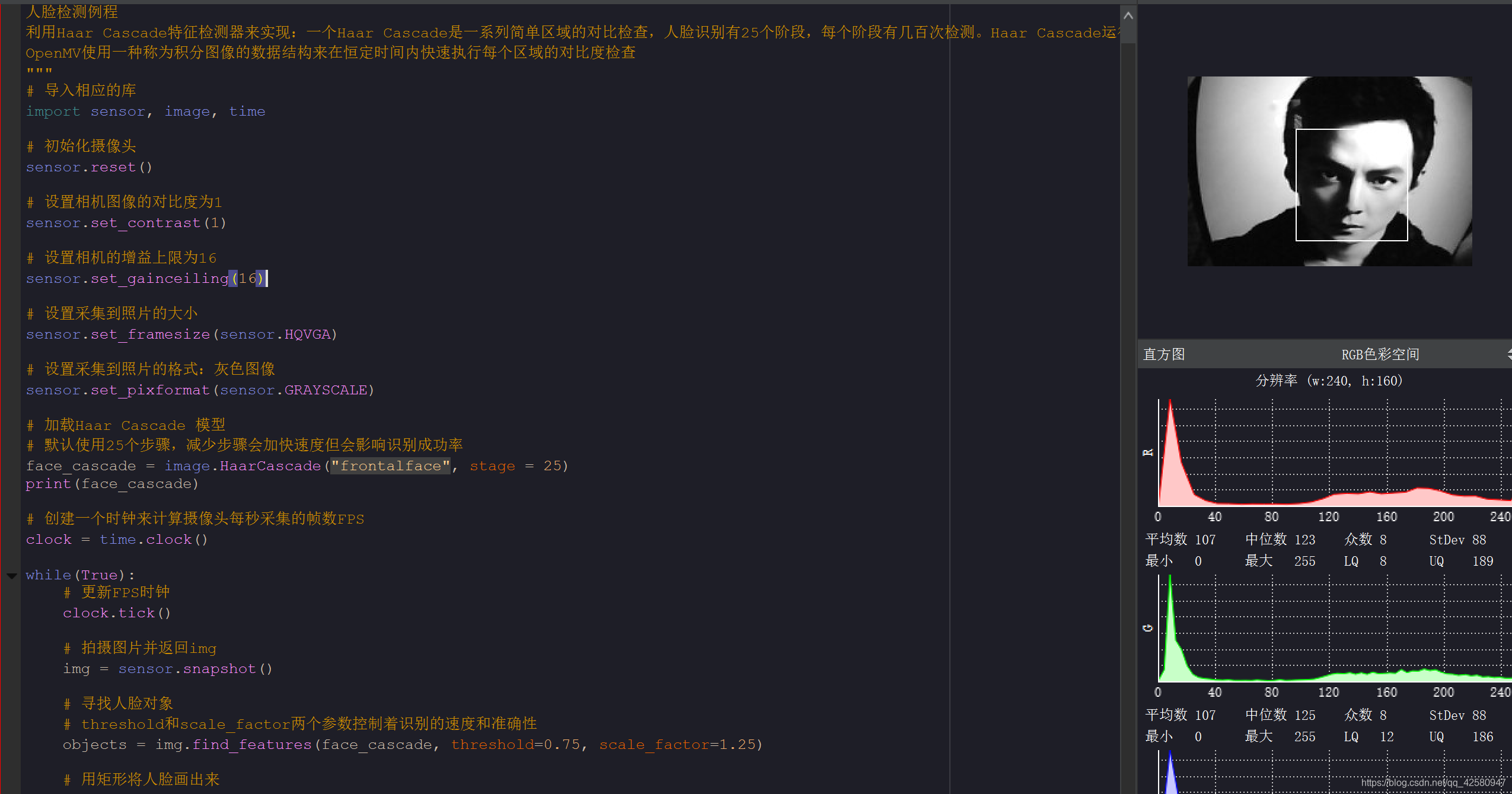
2. 人脸识别
人脸识别是通过短时间的人脸特征学习,再重新识别的过程,这节内容是基于第一小节的人脸检测的基础上完成的。
2.1 构造函数
本节是人脸检测和特征点识别的结合,实验用到的函数和对象在之前都有介绍过,分别是
- image.find_features(cascade, threshold=0.5, scale=1.5, roi)
收获和Haar Cascade 匹配的所有区域的对象,并返回关于这个特征的边界框矩形元组 - image.find_keypoints(roi, threshold=20, normalize=False, scale_factor=1.5, max_keypoints=100, corner_detector=image.CORNER_AGAST)
特征点识别函数,返回一个image.rect矩形对象列表 - image.match_descriptor(descriptor0, descriptor1, threshold=70, filter_outliers=False)
特征点对比函数。
2.2 源码分析
对于人脸识别,具体的实现步骤如下:
初始化和配置相应模块–>加载人脸检测Haar Cascade模型–>对当前的人脸学习并记录特征点K1–>在采集的图像中提取特征点K2–>对比K1和K2是否一致–>如果一致就在图中用矩形画出相应位置
"""
人脸识别例程
第一步先使用Haar Cascade找出人脸并记录该关键点
第二步就是不停的检测当前获取图片的关键点是否匹配
"""
# 导入相应的库
import sensor, image, time
# 初始化摄像头
sensor.reset()
# 设置相机图像的对比度为3
sensor.set_contrast(3)
# 设置相机的增益上限为16
sensor.set_gainceiling(16)
# 设置采集到照片的大小
sensor.set_framesize(sensor.VGA)
# 在VGA(640*480)下开个小窗口,相当于数码缩放
sensor.set_windowing((320, 240))
# 设置采集到照片的格式:灰色图像
sensor.set_pixformat(sensor.GRAYSCALE)
# 加载Haar Cascade 模型
# 默认使用25个步骤,减少步骤会加快速度但会影响识别成功率
face_cascade = image.HaarCascade("frontalface", stage = 25)
print(face_cascade)
# 初始化特征kpts1
kpts1 = None
# 找到人脸
while(kpts1 == None):
# 拍摄图片并返回img
img = sensor.snapshot()
img.draw_string(0, 0, "Looking for a face...")
# 寻找人脸对象
# threshold和scale_factor两个参数控制着识别的速度和准确性
objects = img.find_features(face_cascade, threshold=0.5, scale_factor=1.25)
if objects:
# 将 ROI(x, y, w, h)往各个方向扩展31像素
face = (objects[0][0]-31,
objects[0][1]-31,
objects[0][2]+31*2,
objects[0][3]+31*2)
# 使用扩展后的ROI区域(人脸)学习关键点
kpts1 = img.find_keypoints(threshold = 10,
scale_factor = 1.1,
max_keypoints = 100,
roi = face)
img.draw_keypoints(kpts1, size=24)
img = sensor.snapshot()
time.sleep(2000)
while(True):
img = sensor.snapshot()
# 从图像中提取关键点
kpts2 = img.find_keypoints(threshold = 10,
scale_factor = 1.1,
max_keypoints = 100,
normalized = True)
if(kpts2):
# 跟kpts1匹配
c = image.match_descriptor(kpts1, kpts2, threshold = 85)
# c[6]为match值,值越大表示匹配程度越高
match = c[6]
if(match > 5):
img.draw_rectangle(c[2:6])
img.draw_cross(c[0], c[1], size = 10)
我们将板子连接到OpenMV IDE, 新建文件,并将上述代码copy进去,点击左下角的绿色按钮,我们就可以看到IDE右边的窗口在首先学习了人脸特征:

然后我们换一张还是吴彦祖的人脸看看是否能够进行识别:

从图中可以发现,已经成功识别了这张人脸特征。
3.通过本地特征文件进行人脸识别
第2节的例程是在线学习特征然后进行人脸识别,但是绝大多数的应用场景需要我们对比本地的人脸特征库和目标图像。我们要做的步骤有两部,首先要将人脸特征保存到本地,其次是调用本地的特征来进行人脸识别,下面我们将通过实例来分析如果实现这两个步骤。
3.1 将人脸特征保存到本地
将人脸特征保存到本地只需要一句语句即可:
image.save_descriptor(kpts, "path")
其中kpts为要保存的特征点,path为保存路径。
源码如下:
"""
保存人脸特征例程
第一步先使用Haar Cascade识别出人脸,并获取人脸的特征
第二步就是将特征保存在本地文件中
"""
# 导入相应的库
import sensor, image, time
# 初始化摄像头
sensor.reset()
# 设置相机图像的对比度为3
sensor.set_contrast(3)
# 设置相机的增益上限为16
sensor.set_gainceiling(16)
# 设置采集到照片的大小
sensor.set_framesize(sensor.VGA)
# 在VGA(640*480)下开个小窗口,相当于数码缩放
sensor.set_windowing((320, 240))
# 设置采集到照片的格式:灰色图像
sensor.set_pixformat(sensor.GRAYSCALE)
sensor.skip_frames(time = 3000) # Wait for settings take effect.
# 加载Haar Cascade 模型
# 默认使用25个步骤,减少步骤会加快速度但会影响识别成功率
face_cascade = image.HaarCascade("frontalface", stage = 25)
# 初始化特征kpts1
kpts1 = None
# 文件名
FILE_NAME = "kpts1"
# 找到人脸
while(kpts1 == None):
# 拍摄图片并返回img
img = sensor.snapshot()
img.draw_string(0, 0, "Looking for a face...")
# 寻找人脸对象
# threshold和scale_factor两个参数控制着识别的速度和准确性
objects = img.find_features(face_cascade, threshold=0.5, scale_factor=1.25)
if objects:
# 将 ROI(x, y, w, h)往各个方向扩展31像素
face = (objects[0][0]-31,
objects[0][1]-31,
objects[0][2]+31*2,
objects[0][3]+31*2)
# 使用扩展后的ROI区域(人脸)学习关键点
kpts1 = img.find_keypoints(threshold = 10,
scale_factor = 1.1,
max_keypoints = 100,
roi = face)
img.draw_keypoints(kpts1, size=24)
img = sensor.snapshot()
#将人脸保存打本地文件
image.save_descriptor(kpts1, "/face_feature/%s.orb"%(FILE_NAME))
3.2 通过本地特征文件进行人脸识别
提取本地特征文件只需要一句语句即可:
kpts1 = image.load_descriptor("path")
其中kpts1为要本地文件中的特征,path为保存路径。
源码如下:
"""
加载本地特征文件进行人脸识别例程
第一步先从本地加载特征文件
第二步就是不停的检测当前获取图片的关键点判断是否和本地特征匹配
"""
# 导入相应的库
import sensor, image, time
# 初始化摄像头
sensor.reset()
# 设置相机图像的对比度为3
sensor.set_contrast(3)
# 设置相机的增益上限为16
sensor.set_gainceiling(16)
# 设置采集到照片的大小
sensor.set_framesize(sensor.VGA)
# 在VGA(640*480)下开个小窗口,相当于数码缩放
sensor.set_windowing((320, 240))
# 设置采集到照片的格式:灰色图像
sensor.set_pixformat(sensor.GRAYSCALE)
sensor.skip_frames(time = 10000) # Wait for settings take effect.
# 加载Haar Cascade 模型
# 默认使用25个步骤,减少步骤会加快速度但会影响识别成功率
face_cascade = image.HaarCascade("frontalface", stage = 25)
print(face_cascade)
# 从本地提取特征
kpts1 = image.load_descriptor("/face_feature/kpts1.orb")
while(True):
img = sensor.snapshot()
# 从图像中提取关键点
kpts2 = img.find_keypoints(threshold = 10,
scale_factor = 1.1,
max_keypoints = 100,
normalized = True)
if(kpts2):
# 跟kpts1匹配
c = image.match_descriptor(kpts1, kpts2, threshold = 85)
# c[6]为match值,值越大表示匹配程度越高
match = c[6]
if(match > 10):
img.draw_rectangle(c[2:6])
img.draw_cross(c[0], c[1], color = (255,0,0), size = 10)
智能推荐
R语言学习笔记9_多元统计分析介绍_r语言多元统计分析-程序员宅基地
文章浏览阅读3.6k次,点赞4次,收藏66次。目录九、多元统计分析介绍九、多元统计分析介绍_r语言多元统计分析
小米金融守护消费权益,共筑金融和谐新篇章
在出院结算时,商业医疗保险与医保同步完成结算,无需提供繁琐的纸质申请材料,保险公司直接赔付保险金,简化了理赔流程,赢得了黄奶奶及其家属的高度赞誉。该保险公司的理赔直付模式实现了医疗信息的线上流转和快速理赔支付,大大减轻了消费者的负担。将继续关注消费者权益保护问题,采取多项措施加强消费者权益保障工作,为金融消费者提供更加安全、便捷、高效的金融服务,与社会各方共同构建和谐稳定的金融环境。聚焦于金融消费者权益保护,通过梳理典型案例,旨在提升广大消费者的金融素养,增强风险防范能力,确保他们的合法权益得到切实维护。
Python数据分析大作业(ARIMA 自回归积分滑动平均模型) 4000+字 图文分析文档 销售价格&库存分析+完整python代码
同时销售量后1000的sku品类占比中(不畅销产品)如上,精品类产品占比第一,达到66.7%,其次是香化类产品,占比11.90%,远远小于精品类产品,酒水类产品占比7.3%,有税商品免税其他商品和电子类产品分别占比6.40%、6.40%、1.3%,将数据按照毛利进行排序,毛利前1000和后1000的sku品类占比如下,。
spring-boot 连接池 druid 的配置及监控_druid sql白名单-程序员宅基地
文章浏览阅读1.2w次,点赞3次,收藏12次。连接池 Druid简介Druid是Java中最好的数据库连接池,并且能够提供强大的监控和扩展功能。业界把Druid和HikariCP做对比后,虽说HikarCP的性能比Druid高,但是因为Druid包括很多维度的统计和分析功能,所以也是大家学则使用的主要原因。Druid是阿里巴巴开源平台上的一个项目,整个项目由数据库连接池、插件框架和SQL解析器组成。该项目主要是为了扩展JDBC的一_druid sql白名单
ssm基于JAVA的驾校信息管理系统设计论文_驾校管理系统的设计与实现论文近五年参考文献-程序员宅基地
文章浏览阅读787次,点赞26次,收藏26次。独立开发程序期间,才会发现有许多知识都是现学现用得来的,毕竟大学期间所学知识比较有限,专业知识掌握得比较浅显,这也给自己制造了许多麻烦,比如程序开发期间遇到的中文乱码问题,程序对应数据库的数据安全问题,程序开发中框架的使用问题等,这些问题都需要随时去翻阅书籍,或通过百度浏览器等方式寻找解决办法,这也耽误了许多程序开发的宝贵时间,后期我也通过对周边同学的请教,以及指导老师的悉心指导,让我找到了程序开发的相关技巧,也积累了一定的知识量,慢慢地纠正了许多不该犯的错误。也推动了我的程序开发进程。_驾校管理系统的设计与实现论文近五年参考文献
Kafka学习笔记(二、linux和docker安装及使用demo)
第一个总是Kafka Connect进程的配置,包含常见的配置,比如Kafka要连接的代理和数据的序列化格式。这些示例配置文件,包含在Kafka中,使用您之前启动的默认本地集群配置并创建两个连接器:第一个是源连接器,它从输入文件中读取行并将每个行生成到Kafka主题,第二个是接收器连接器,它从Kafka主题中读取消息并将每个消息作为输出文件中的一行生成。下面我们介绍如何使用简单的连接器来运行Kafka Connect,将数据从文件导入到Kafka主题,并将数据从Kafka主题导出到文件。
随便推点
termux安装metasploit()-程序员宅基地
文章浏览阅读8.9k次,点赞16次,收藏108次。因为呢,termux作者,不希望让termux变成脚本小子的黑客工具,于是把msf , sqlmap等包删了。至于如何安装metasploit呢。apt update -y && apt upgrade -y #更新升级更新升级之后要安装一个叫 git 的安装包apt install git -y然后我们就开始//这里的话建议把手机放到路由器旁边,保持网络的优良。或者科学上网。//git clone https://github.com/gushmazuko/metaspl_termux安装metasploit
armbian docker Chrome_一起学docker06-docker网络-程序员宅基地
文章浏览阅读141次。一、Docker支持4种网络模式Bridge(默认)--network默认网络,Docker启动后创建一个docker0网桥,默认创建的容器也是添加到这个网桥中;IP地址段是172.17.0.1/16 独立名称空间 docker0桥,虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。host容器不会获得一个独立的network namespace,而是与宿主..._armbian 172.17.0.1
Ansible-Tower安装破解
Ansible-Tower安装破解。
如何使用 Nginx 进行负载均衡
通过使用 Nginx 进行负载均衡,您可以提高应用的可靠性和性能。上述指南提供了设置负载均衡的基础步骤,您可以根据具体需求对其进行调整和扩展。确保定期检查和更新您的 Nginx 配置以保持最优性能。希望这篇博客能帮助您开始使用 Nginx 进行负载均衡!如果您有任何问题或需要进一步的帮助,请留言或联系我们。
ARFoundation系列讲解 - 39 AR看车六_arfoundation 关闭动画位移计算-程序员宅基地
文章浏览阅读1k次。十二、播放模型动画1.这里我们要做的是第一次点击中心按钮播放打开车门动画,第二次点击中心按钮关闭车门动画。2.新建一个脚本,命名为“AnimationManager.cs”。(代码如下)using System.Collections.Generic;using UnityEngine;/// <summary>动画管理</summary>public class AnimationManager : MonoBehaviour{ /// <s._arfoundation 关闭动画位移计算
Idea 运行spring项目 出现的bug_idea spring代理对象出bug-程序员宅基地
文章浏览阅读220次。Idea 运行spring项目 出现的bugbug 1错误信息:Cannot start compilation: the output path is not specified for module “02_primary”.Specify the output path in the Project Structure dialog.解决办法:..._idea spring代理对象出bug