hive server2源码地址在哪_0510Spark应用访问Hive报错异常分析-程序员宅基地
技术标签: hive查看表中列的信息命令 hive 修改cluster by算法 hive server2源码地址在哪
温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
Fayson的github:
https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1
故障描述
运行环境说明
1.RedHat7.2
2.CM和CDH版本为5.15.0
3.Spark1.6
问题现象
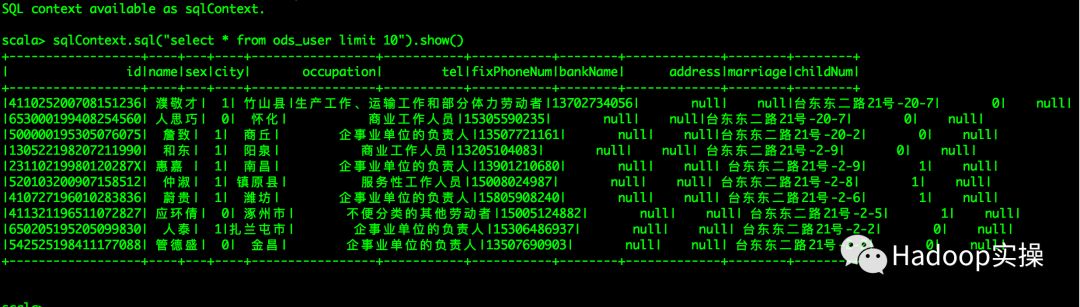
在代码中使用HiveContext对象访问Hive表ods_user(该表为Parquet格式)时发现作业报错,异常如下:
in thread 
2
问题诊断分析
报找不到cdh01.fayson.com主机,Fayson在之前对集群做过几次变更:
集群启用HA前,SparkStreaming作业使用saveAsTable在Hive中保存了ods_user表,可以正常查询及写入数据。
集群启用HA并更新NameNode URL后,Hive和Spark作业依然能够访问ods_user表。
修改集群的hostname,将cdh01.fayson.com主机名修改为cdh1.fayson.com后,Spark作业访问ods_user表失败。
1.检查Spark和Hive的配置文件,在配置文件中均为发现cdh01.fayson.com记录

经过检查集群中Spark和Hive的配置文件,未发现有cdh01.fayson.com的配置信息,排除配置文件导致的问题。
2.检查Spark作业的运行环境,也未发现相应的配置信息
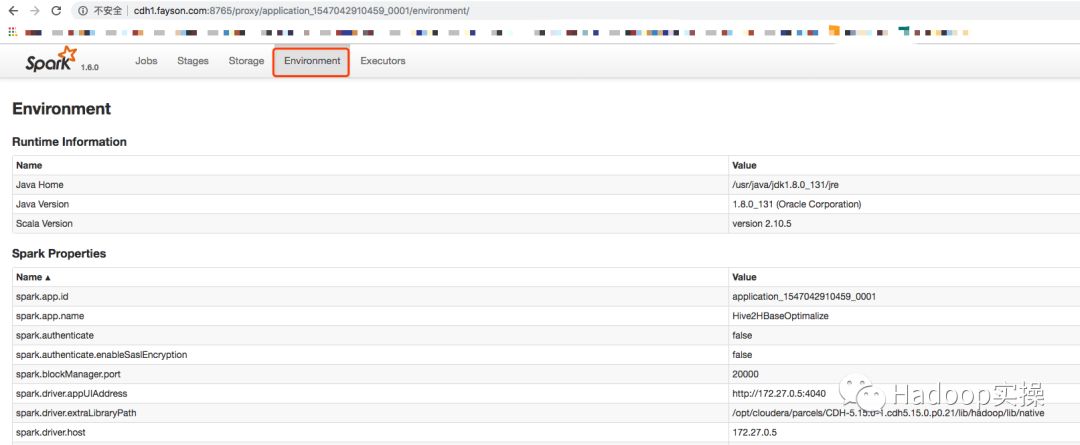
在Spark作业的运行环境中也未找到cdh01.fayson.com相关的配置信息,继续分析。
3.在作业日志中可以看到,Spark访问HiveMetastore服务是成功的

既然可以正常的访问HiveMetastore服务,那再次证明Hive和Spark配置是没有问题的。
4.既然能够正常的访问HiveMetastore服务,Spark服务直接通过访问HiveMetastore服务获取ods_user的元数据信息,推测可能是ods_user表元数据存在问题,查看ods_user表建表语句确认
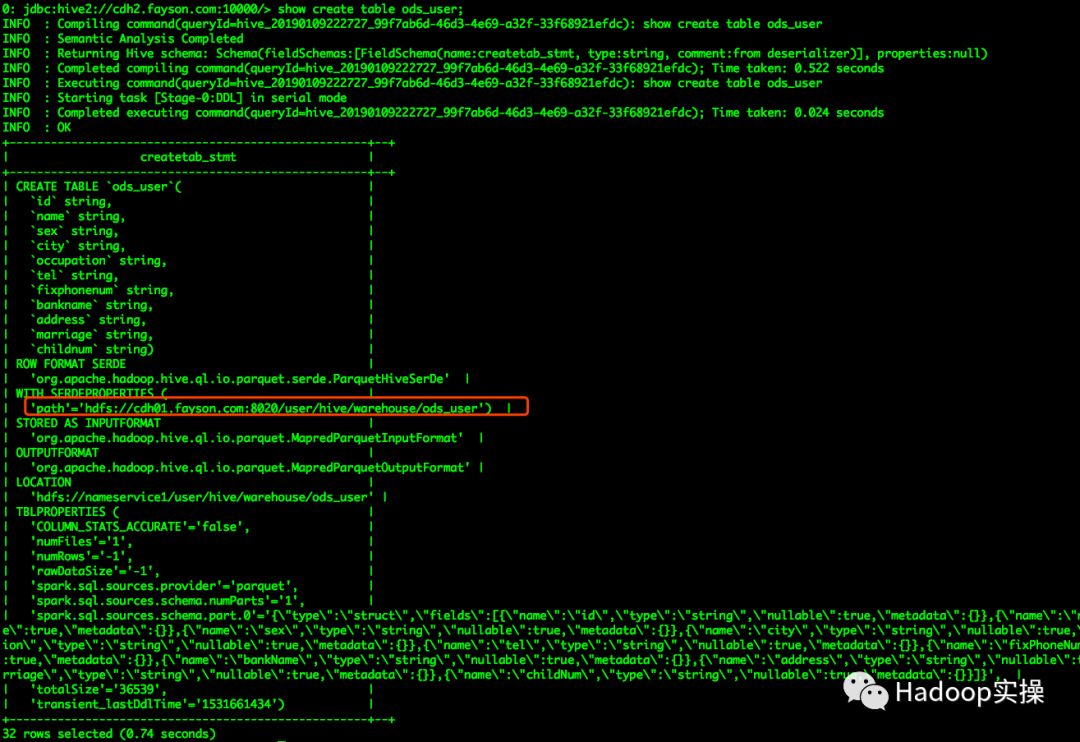
检查ods_user的建表语句发现,存在配置信息为cdh01.fayson.com的信息,由此推断可能是由于ods_user表中该属性导致。
3
问题解决
Fayson很清晰的记得在SparkStreaming作业中创建的ods_user表,,并未在建表语句中指定Spark SQL相关的配置参数。通过Spark官网资料找到相关信息(
http://spark.apache.org/docs/1.6.0/sql-programming-guide.html#hive-metastore-parquet-table-conversion
),Spark在读取和写入Hive Metastore Parquet表时,会尝试使用自己的Parquet支持而不是使用Hive SerDe,从而获取更好的性能。此行为由spark.sql.hive.convertMetastoreParquet参数控制(默认为true)。那如果修改了Hive表的属性或其它外部变更(如:修改NameNode节点hostname,NameNode节点迁移等)均会导致Spark缓存的配置失效,因此这时需要手动的刷新表,以确保元数据信息一致。
1.修改ods_user表中SERDEPROPERTIES中的path属性为NameNode启用HA后的地址,命令如下;
ALTER 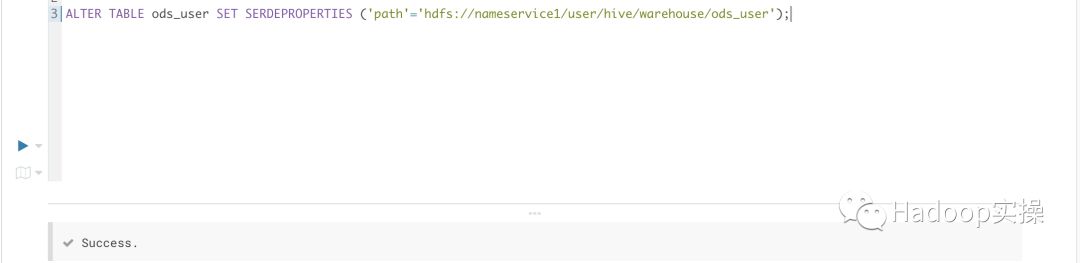
可以看到path已修改为最新的HDFS访问地址
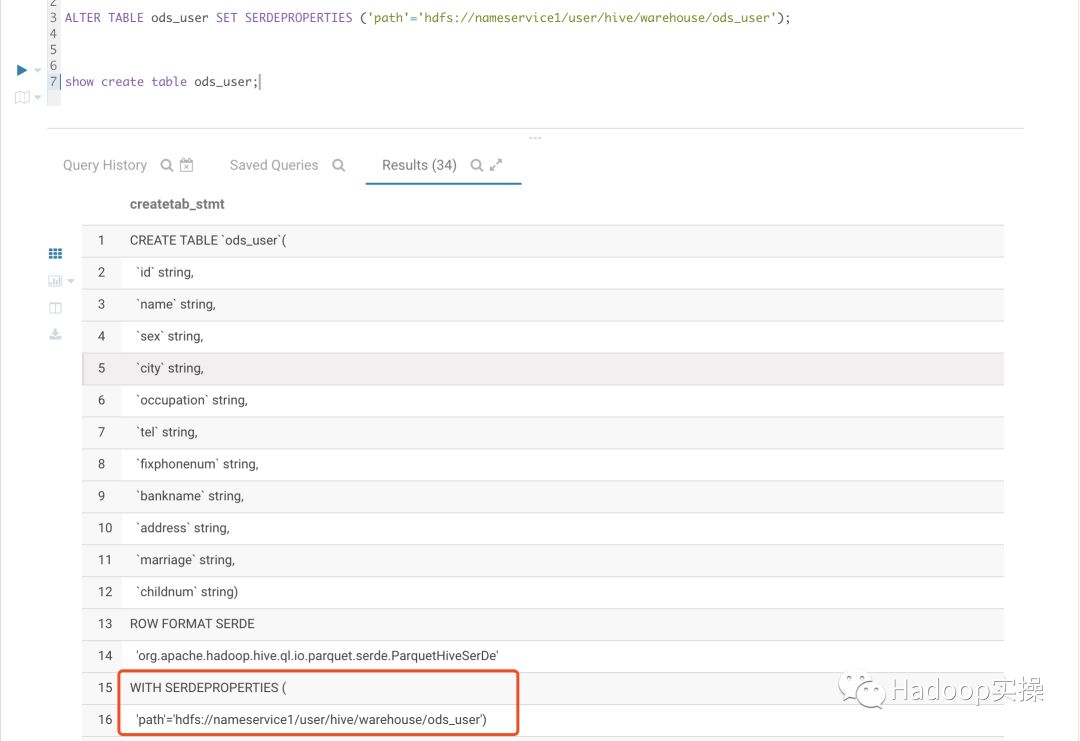
2.再次验证可以正常的访问ods_user表的数据
4
总结
1.Spark在读取和写入Hive Metastore Parquet表时,会尝试使用自己的Parquet支持而不是使用Hive SerDe,从而获取更好的性能。所以在将spark数据写入一个不存在的hive表时会在建表语句中增加spark的一些属性配置。
2.特别要注意集群在未启用HA时使用Spark生成的Hive表,在集群启用HA后可能会到Spark无法访问该表,需要修改SERDEPROPERTIES中path属性。
3.如果只是通过hive或者其他外部方式修改了Hive表的元数据信息,可以通过如下方式刷新Spark缓存的表元数据
new org.apache.spark.sql.hive.HiveContext(sc)提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。

原创文章,欢迎转载,转载请注明:转载自微信公众号Hadoop实操
智能推荐
python色卡识别_用Python帮小姐姐选口红,人人都是李佳琦-程序员宅基地
文章浏览阅读502次。原标题:用Python帮小姐姐选口红,人人都是李佳琦 对于李佳琦,想必知道他的女生要远远多于男生,李佳琦最早由于直播向广大的网友们推荐口红,逐渐走红网络,被大家称作“口红一哥”。不可否认的是,李佳琦的直播能力确实很强,他能够抓住绝大多数人的心理,让大家喜欢看他的直播,看他直播推荐的口红适不适合自己,色号适合什么样子的妆容。为了提升效率,让自己的家人或者女友能够快速的挑选出合适自己妆容的口红色号,今..._获取口红品牌 及色号,色值api
linux awk命令NR详解,linux awk命令详解-程序员宅基地
文章浏览阅读3.6k次。简介awk命令的名称是取自三位创始人Alfred Aho 、Peter Weinberger 和 Brian Kernighan姓名的首字母,awk有自己的程序设计语言,设计简短的程序,读入文件,数据排序,处理数据,生成报表等功能。awk 通常用于文本处理和报表生成,最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。awk 通常以文件的一行为处理单位..._linux awk nr
android 网络连接失败!failed to connect to /192.168.1.186(port 8080)_failed to connect to 192.168.88.218:80-程序员宅基地
文章浏览阅读1.3w次,点赞5次,收藏2次。在网上找了一个小时,一直没有头绪,因为上个星期还是好好的,最后看到一个大神的解答,只需要将防火墙关闭就好了.原本向测试功能的,却卡在了登录上.以此记录.另外好像还有种错误是电脑与手机连接的WiFi不同,也可以看看...._failed to connect to 192.168.88.218:80
matlab 多径衰落,利用MATLAB仿真多径衰落信道.doc-程序员宅基地
文章浏览阅读1.9k次。利用MATLAB仿真多种多径衰落信道摘要:移动信道的多径传播引起的瑞利衰落,时延扩展以及伴随接收过程的多普勒频移使接受信号受到严重的衰落,阴影效应会是接受的的信号过弱而造成通信的中断:在信道中存在噪声和干扰,也会是接收信号失真而造成误码,所以通过仿真找到衰落的原因并采取一些信号处理技术来改善信号接收质量显得很重要,这里利用MATLAB对多径衰落信道的波形做一比较。一,多径衰落信道的特点关于多径衰落..._matlab多径衰落工具箱
python对json的操作及实例解析_import json灰色-程序员宅基地
文章浏览阅读1w次,点赞2次,收藏17次。Json简介:Json,全名 JavaScript Object Notation,是一种轻量级的数据交换格式。它基于 ECMAScript (w3c制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。(来自百度百科)python关于json文_import json灰色
mysql实现MHA高可用详细步骤_mysql mha超详细教程-程序员宅基地
文章浏览阅读1.1k次,点赞6次,收藏3次。一、工作原理MHA工作原理总结为以下几条:(1) 从宕机崩溃的 master 保存二进制日志事件(binlog events);(2) 识别含有最新更新的 slave ;(3) 应用差异的中继日志(relay log) 到其他 slave ;(4) 应用从 master 保存的二进制日志事件(binlog events);(5) 通过Manager控制器提升一个 slave 为新 m..._mysql mha超详细教程
随便推点
Linux环境下主从搭建心得(高手勿喷)_linux的java主从策略是什么-程序员宅基地
文章浏览阅读194次。一 java环境安装:1 安装JDK 参考链接地址:https://blog.csdn.net/qq_42815754/article/details/82968464注:有网情况下直接 yum 一键安装:yum -y list java(1)首先执行以下命令查看可安装的jdk版本(2)选择自己需要的jdk版本进行安装,比如这里安装1.8,执行以下命令:yum install -y java-1.8.0-openjdk-devel.x86_64(3)安装完之后,查看安装的jdk 版本,输入以下指令_linux的java主从策略是什么
ACM第四题_acm竞赛题 i 'm from mars-程序员宅基地
文章浏览阅读104次。定义int 类型,由while实现A,B的连续输入,输出A+B的值按Ctrl Z结束循环。#include<iostream>using namespace std;int main(){ int A,B; while(cin>>A>>B) { cout<<A+B<&_acm竞赛题 i 'm from mars
TextView.SetLinkMovementMethod后拦截所有点击事件的原因以及解决方法-程序员宅基地
文章浏览阅读5.2k次。在需要给TextView的某句话添加点击事件的时候,我们一般会使用ClickableSpan来进行富文本编辑。与此同时我们还需要配合 textView.setMovementMethod(LinkMovementMethod.getInstance());方法才能使点击处理生效。但与此同时还会有一个问题:如果我们给父布局添加一个点击事件,需要在点击非链接的时候触发(例如RectclerV..._linkmovementmethod
JAVA实现压缩解压文件_java 解压zip-程序员宅基地
文章浏览阅读1.1w次,点赞6次,收藏31次。JAVA实现压缩解压文件_java 解压zip
JDK8 新特性-Map对key和value分别排序实现_java comparingbykey-程序员宅基地
文章浏览阅读1.3w次,点赞7次,收藏21次。在Java 8 中使用Stream 例子对一个 Map 进行按照keys或者values排序.1. 快速入门 在java 8中按照此步骤对map进行排序.将 Map 转换为 Stream 对其进行排序 Collect and return a new LinkedHashMap (保持顺序)Map result = map.entrySet().stream() .sort..._java comparingbykey
GDKOI2021普及Day1总结-程序员宅基地
文章浏览阅读497次。第一次参加GDKOI,考完感觉还可以,结果发现还是不行,有一些地方细节打错,有些失分严重,总结出以下几点:1.大模拟一定要注意,细节打挂就是没分,像T1就是一道大模拟题,马上切了,后面就没想着检查以下,导致有些地方挂掉了,用民间数据一测,才85分。2.十年OI一场空,不开longlonglong longlonglong见祖宗。今天的T2本来想用暴力水点分的,结果没想到longlong→intlong long\to intlonglong→int,40→040\to040→0。3.代码实现能力太差,_gdkoi