论文 Convolutional Networks for Images, Speech, and Time-Series-程序员宅基地
技术标签: 卷积 机器学习 神经网络 TensorFlow
论文 Convolutional Networks for Images, Speech, and Time-Series
1 Introduction
The ability of multilayer back-propagation networks to learn complex, heigh-dimensional,non-linear mapping from large collection of examples make them obvious candidates for image recognition or speech recognition tasks (see PATTERN RECOGNITION AND NEURAL NETWORKS).
large collection of examples: 应该指的是大量的训练集,这些训练集中的对应关系是非线性的、复杂的、高维的。
In the traditional model of pattern recognition, a hand designed feature extractor gathers relevant information from the input and eliminates irrelevant variabilities. A trainable classifier then categorizes the resulting feature vectors (or strings of symbols) into classes.
这不禁让我想起了我入手神经网络时做的第一个例子,鸢尾花数据集(iris_dataset)。这个数据集由 Fisher 于 1936 年收集整理,每个数据包含 4 个属性:花萼长度、花萼宽度、花瓣长度、花瓣宽度。输入的不是一张花的图片而是人为提取的 4 个花的特征,收集输入中的相关信息去除相关变量。
In this scheme, standard, full-connected multilayer networks can be used as classifiers.
此后再将这些输入全链接网络进行分类,全连接网络相当于一个分类器。
A potentially more interesting scheme is to eliminate the feature extractor, feeding the network with “raw” inputs(e.g. normalized images), and to rely on backpropagation to turn the first few layers into an appropriate feature extractor.
直接给网络输入原始数据,依靠反向传播来将前面几层变成一个合理的特征提取器。对于前面的鸢尾花数据集来说,我们希望网络能自动提取出花萼长度、花萼宽度、花瓣长度、花瓣宽度。
While this can be done with odinary fully connected feed-forward network with some success for tasks such as character recognition, there are problems.
虽然我们也可以直接给多层全连接网络输入原始数据,但是会存在一些问题。全连接网络有什么问题呢?为什么不能把全连接网络的前几层当成特征提取器呢?这些问题又是如何解决的呢?
Firstly, typical images, or spectral representations of spoken words, are large, often with several hundred variables.
输入变量太多,这会导致什么问题?如何思考解决?
A fully-connected first layer with, say a few 100 hidden units would already contain several 10,000 weights. Overfitting problems may occur if training data is scarce
对于 28x28 的 MNIST 大小的数据集来说,输入神经元个数为 784 个 第一层隐藏层为 100 个神经元。第一层权重个数为 78400。 权重太多需要大量的数据集来训练,权重过多会导致泛化能力下降。也就是说每一个权重都需要用数据集来良好定义。
In addition, the memory requirement for that many weights may rule out certain hardware implementations.
内存不够大,对于显卡来说内存很重要。
But the main deficiency of unstructured nets for image or speech applications is that they have no built-in invariance with respect to translations, or local distortions of the inputs
这里 unstructured nets 指的是多层全链接网络,没有内在不变性。局部扭曲和不同形式表现的输入都会被当成全新的输入。对于 MNIST 手写体数据集来说,稍微有一些平移或局部有一些扭曲并不会影响本质,即这个数字是 5。但是对于通过光谱得到结构这件事来说,它和图片识别有着本质区别。光谱的移动即对应不同的结构。虽然他们都是同样的 fano, 只不过是位置不同。
Before being sent to the fixed-size input layer of a neural net, character images, spoken word spectra, or other 2D or 1D signals, must be approximately size-normalized and centered in the input field.
在输入网络前会对数据集做归一化,这让我想起了 GAN 总是将输入图片归一化为 -1~1,generator 的最后一层输出层用 tanh 激活。但这里还会做一个操作,尽可能的将数字移动到中心,减少位移对于结果的影响。
Unfortunately,no such preprocessing can be perfect: handwriting is often normalized at the word level, which can cause size, slant, and position variations for the individual characters; words can be spoken at varying speed, pitch, and intonation
对于原始数据来说,这些预处理都没法做到完美,总会有位移,倾斜。因为这个 raw data 是人手写出来的。
This will cause variations in the position of distinctive features in the input objects.
所以有些关键的特征会产生位移,但是这些位移对于图片的识别来说是非相关的变量。文章的第一段:hand designed feature extractor 的目的是收集相关变量去除非相关变量。对于我们的光谱识别对应结构来说,薄膜干涉是非相关变量,能带是相关变量。所以我们的神经网络中不能像图片识别一样去掉位移。而应该像方法去掉薄膜干涉,保留能带及其位置。
In principle, a fully-connected network of sufficient size could learn to produce outputs that are invariant with respect to such variations.
我们需要避免这些 irrelevent variation 带来的过大的数据集,过大的网络,以及带来的过拟合。但是对于我们关系的 relevent variation 需要大量的数据集,那没办法呀。所以对于我们的任务,我们的训练集只能遍历我们关心的参数空间啦。
对于前面的依赖反向传播算法的特征提取器的结构需要我们针对不同问题仔细设计。设计目标:使得网络能够保留 relevent variation 而尽可能的去除 irelevent variation。因为 irelevent variation 将会给我们带来额外的数据集、过大的网络以及过拟合问题。
分析一下 MNIST 手写体数据集,对于这个数据集来说 relevent variation 应该是数字的类别 0-9,由此对应的一些特征,而 irrelevant variation 应该是数字局部的变形、数字的位移。
However, learning such a task would probably result in multiple units with identical weight patterns positioned at various locations in the input.
LeCunn 说对于这个问题,解决方法:权重共享。因为我们可以注意到在全链接层中会有许多相同的权重,这是由于输入 MNIST 手写体数字的位移以及局部变形造成的。
一种很好的减少权重的方法就是,给每个 batch 的神经元赋予相同的权重。这样就可以应对神经元相对于 feature 的位置有一个位移产生对应着新的权重的问题了。而这个 shift 是 irrelevent variation。
Learning these weight configurations requires a very large number of training instances to cover these space of possible variations
因为你使用了全链接网络,把位移一个本来 irrelevant variation 变成了 relevent variation,所以需要配套使用对位移 relevent 的数据集,即足够多数量的训练集来覆盖所有可能的空间位置。
On the other hand, in convolutional networks, shit invariance is automatically obtained by forcing the replication of weight configurations across space.
由此才设计出对位移不敏感的卷积神经网络。即卷积神经网络的提出思考了的问题,1、如何设计一个空间平移不变的网络;2、如何能将空间上有一个 shift 的未包含在训练集内的数字也包含进去;3、基于前面的观察,如何能有效减少权重数量。
Secondly a deficiency of fully-connected architectures is that the topology of the input is entirely ignored. The input variables can be presented in any (fixed) order without affecting the outcome of the training.
也就是说 一张 28x28 的手写体图片,flatten 后为 784 的一个向量。1,2,3,4,5…,783,784 的排列方式和 435,589,245,1…,243,142 的乱序排列方式都不会影响最后的结果。这个现象是由什么导致的,又为什么不好呢?
这是由于全链接造成的,全链接使得空间整体的性质被考虑,即使的拓扑结构被破坏。也对最后结果没有影响。
先不管为什么不好,LeCun 说前面特征提取器的设计应该充分考虑特征结构。
On the contrary, images, or spectral representations of speech have a strong 2D local structure, time-series have a strong 1D structure: variables(or pixels) that are spatially or temporally nearby are highly correlated.
空间上和时序上附近的点是高度相关的,这一点也可以被用来考虑如何设计我们的网络。
Local correlations are the reasons for the well-known advantages of extracting and combining local feature before recognizing spatial or temporal objects.
在分辨时序或空间中的物体前,提取局部特征并将局部特征组合起来为什么有优势的原因就是 局部关联。
那我们不做 image recognition 做光谱分析,在分析得到最终结构之前,提取出光谱的局部特征,并将这些局部特征组合起来为什么有优势的原因就是 局部关联。
图像识别的逻辑是:物体有这些特征所以它是这类物体。光谱分析的逻辑是光谱上这些特征在这个位置所以它是这个结构。就仅仅比图像识别多了一个位置。但我们还是要辨别光谱上的特征(如果一个网络不知道光谱上这些特征是什么那就没得玩了)
Convolutional networks force the extraction of local features by restricting the receptive field of hidden units to be local.
卷积网络通过限制隐藏层神经元的感受野从此前的全局变为局部(filter 的范围)来提取局部特征。通过空间上的平移解决特征位置 shift。
2 Convolutional Networks
Convolutional networks combine three architectural ideas to ensure some degree of shift and distortion invariance: local receptive fields, shared weights (or weight replication), and, sometimes spatial or temporal subsampling.
CNN 作为特征提取器有三个结构来保证位移和局部扭曲的不变性:局部感受野、共享权重、时空上降采样。前面两点保证了位移不变性,最后一点保证了局部扭曲不变性。
A typical convolutional network for recognizing characters is shown in figure 1 (from (LeCun et al. 1990)).
这个应该就是做 MNIST 手写体数据集分辨的 LeNet。
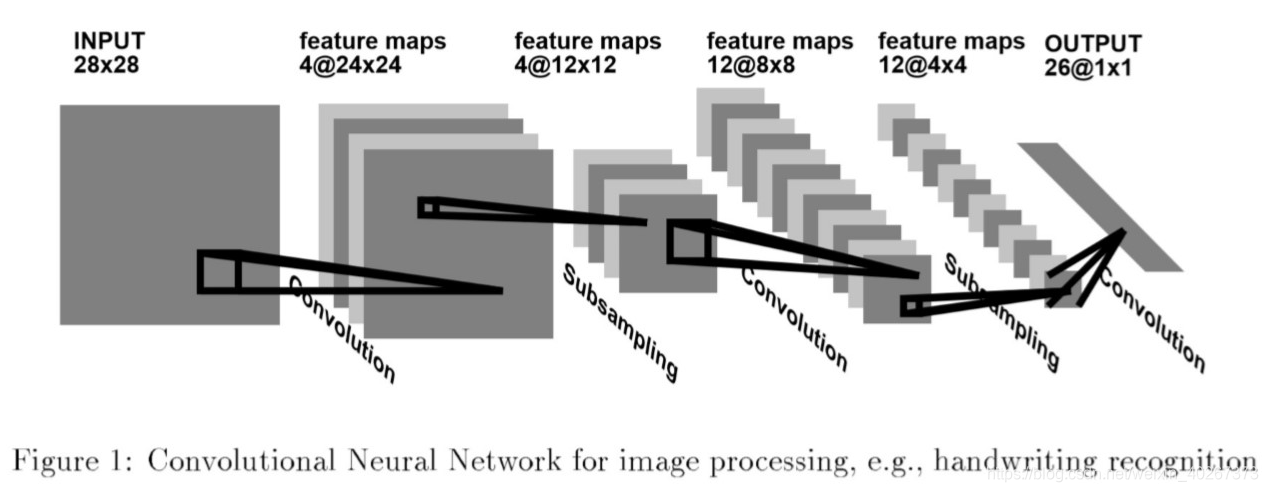
The input plane receives images of characters that are approximately size-normalized and centered.
我感觉是因为原来做神经网络的人硬件设备很差,所以他们对神经网络的理论研究很深入,而且预处理很多。
Each unit of a layer receives inputs from a set of units located in a small neighborhood in the previous layer. The ideal of connecting units to local receptive fields on the input goes back to the Perception in the early 60s, and was almost simultaneous with Hubel and Wiesel’s discovery of locally sensitive, orientation selective neurons in the cat’s visual system. Local connections have been reused many times in neural models of visual learning (see (Mozer, 1991; Le Cun, 1986) and NEOCOGNITRON in this handbook).
With local receptive fields, neurons can extract elementary visual features such as oriented edges, end-point, corners (or similar features in speech spectrograms).
可以识别有向边、终点、拐角
These features are then combined by the higher layers.
这些特征被更高的层组合在一起,这是通过卷积组合跨通道相邻区域的 features 实现的。
As stated earlier, distortions or shifts of the input can cause the position of salient features to vary.
注意 Le Cun 这里强调了局部扭曲和位移会导致 feature 的位置发生移动,但位置对于图像识别来说不重要。
In addition, elementary feature detectors that are useful on one part of the image are likely to be useful across the entire image.
这个虽然说的是 feature detectors 即卷积,但是其实是指 feature。意思是 feature 可以在全图的任何一个地方出现。
This knowledge can be applied by forcing a set of units, whose receptive fields are located at different places on the image, to have identical weight vetors (Rumelhart, Hinton and Willian, 1986).
其实就是 filter 的平移操作。使得 feature 在全图中任何一个地方都可以被识别到。
These outputs of such a set of neurons constitute a feature map.
输出被称为特征图 feature map。
At each position, different types of units in different feature maps compute different types of features
用目前我对理解来说,这句话说的是,不同的 channel 中的同一个地方存放着不同的 features。等等 different type of units 指 卷积核。在每一个位置,每一个 channel 的卷积核的类型都是不一样的。用于计算不同的特征。
A sequential implementation of this, for each feature map, would be to scan the input image with a single neuron that has a local receptive field, and to store the state of this neuron at corresponding locations in the feature map.
the feature map 的作用是存储神经元的状态。
This operation is equivalent to a convolution with a small size kernel, followed by a squashing function.
这里的 squashing function 指的是激活函数 sigmoid
The process can be performed in parallel by implementing in feature map as a plane of neurons that share a single weight vector
不同 channel 的图片可以并行计算。
Units in a feature map are constrained to perform the same operation on different parts of the image.
这是通过平移扫描来实现的,在图片的不同位置进行相同的操作。
A convolutional layer is usually composed of several feature maps (with different weight vectors), so that multiple features can be extracted at each location.
每个位置的多层特征都会被提取。
The first hidden layer in figure 1 has 4 feature maps with 5 by 5 receptive fields. Shifting the input of a convolutional layer will shift the output, but will leave it unchanged otherwise
这个描述很有趣,如果移动输入图片会移动输出,但是只是移动但是还是会识别到,这一点不会被改变。这意味着,the feature map 被激活的特征保持不变只不过发生了移动。这个用 VGG_Lite1 试试。
Once a feature has been detected, its exact location becomes less important, as long as its approximate position relative to other features is preserved. Therefore, each convolutional layer is followed by an additional layer which performs a local averaging and a subsampling, reducing the resolution of the feature map, and reducing the sensitivity of the output to shifts and distortions
个人觉得这里有点问题,只能 reduce the sensitivity of the output to distortions。shift 使用卷积核扫描来办到的。对于要将神经网络用于 OCD 中来说,精确位置非常重要,所以不能使用 pooling。不过对于 LeNet 来说,这里说的应该是对的。分辨手写体数字,问题不是这个特征是否存在,而是这个特征存在且与其他特征有一个大概的相对位置。也就是说对于 MNIST 数据集来说,特征是什么很重要、特征之间的相对位置很重要、特征的绝对位置不重要。对于 MNIST 数据集来说不能使用全局池化。
哦,我理解了。为什么在之后的文章中会用全局池化消除物体的绝对位置。因为卷积层数足够多,导致局部信息组合成了一个整体。到后面已经可以分辨出每一个数字了。一个 channel 中的 feature 不再是横或勾,而是一个数字。导致可以直接全局池化来判别这个 feature 是否存在。
The second hidden layer in figure 1 performs 2 by 2 averaging and subsampling, followed by a trainable coefficient, a trainable bias, and a sigmoid. The trainable coefficient and bias control the effect of the squashing non-linearity (for example, if the coefficient is small, then the neuron operates in a quasi-linear mode).
权重和偏置来控制非线性性导致第一次听说。那对于 relu 来说,即是正负决定了非线性开还是关。
Successive layers of convolutions and subsampling are typically alternated, resulting in a ''bi-pyramid": at each layer, the number of feature maps is increased as the spatial resolution is decreased. Each unit in the third hidden layer in figure 1 may have input connections from several feature maps in the previous layer.
也就是说空间分辨率下降了,但是我们希望它提取的特征越来越多,spatial 上面的减少用 channel 的增加来弥补形成一个双锥体。这也是将空间位置上的注意力转移为物体 feature 是什么的一个方法。
The convolution/subsampling combination, inspired by Hubel and Wiesel’s notions of “simple” and “complex” cells, was implemented in the Neocognitron model (see NEOCOGNITRON), though no globally supervised learning procedure such as back-propagation was available then.
感觉是一句废话。
Since all the weights are learned with back-propagation, convolutional networks can be seen as synthesizing their own feature extractor.
依靠反向传播算法,神经网络可以自己学习如何提取特征。(目前我感觉提取出的特征还和后面的分类器或者是做回归的部分有关)
The weight sharing technique has the interesting side effect of reducing the number of free parameters, thereby reducing the “capacity” of the machine and improving its generalization ability (see (LeCun 1989) on weight sharing, and LEARNING AND GENERALIZATION for an explanation of notion of capacity and generalization)
权重共享技术会降低网络的能力(因为减少了参数的个数),增加网络的泛化。这么说:网络的泛化和网络的能力是成反比的。Le Cun 1989 的这篇文章之后我必看,因为是我目前遇到的主要问题,权重参数过多导致泛化能力为零。
The network in figure 1 contains about 100,000 connections, but only about 2600 free parameters because of the weight sharing. Such networks compare favorably with other methods on handwritten character recognition tasks (Botton et al. 1994) (see also HAND WRITTEN DIGIT RECOGNITION), and they have been deployed in commercial applications.
链接数量很多但是权重很少,这是权重共享导致的。后面是说这个网络的能力和商用设备能力相当,一句废话。
Fixed-size convolution networks that share weights along a single temporal dimension are known as Time-Delay Neural Network(TDNNs). TDNNs have been used in phoneme recognition(without subsampling) (Lang and Hinton, 1988l Waibel et al., 1989), spoken word recognition (with subsampling) (Botton et al., 1990), and on-line handwriting recognition (Guyon et al., 1991).
这段和我们关系不大,但是中间有一个 without subsampling 这说明是否 pool 是根据具体问题进行分析的。肯定了我们在光谱分析上不使用 pool 的正确性。
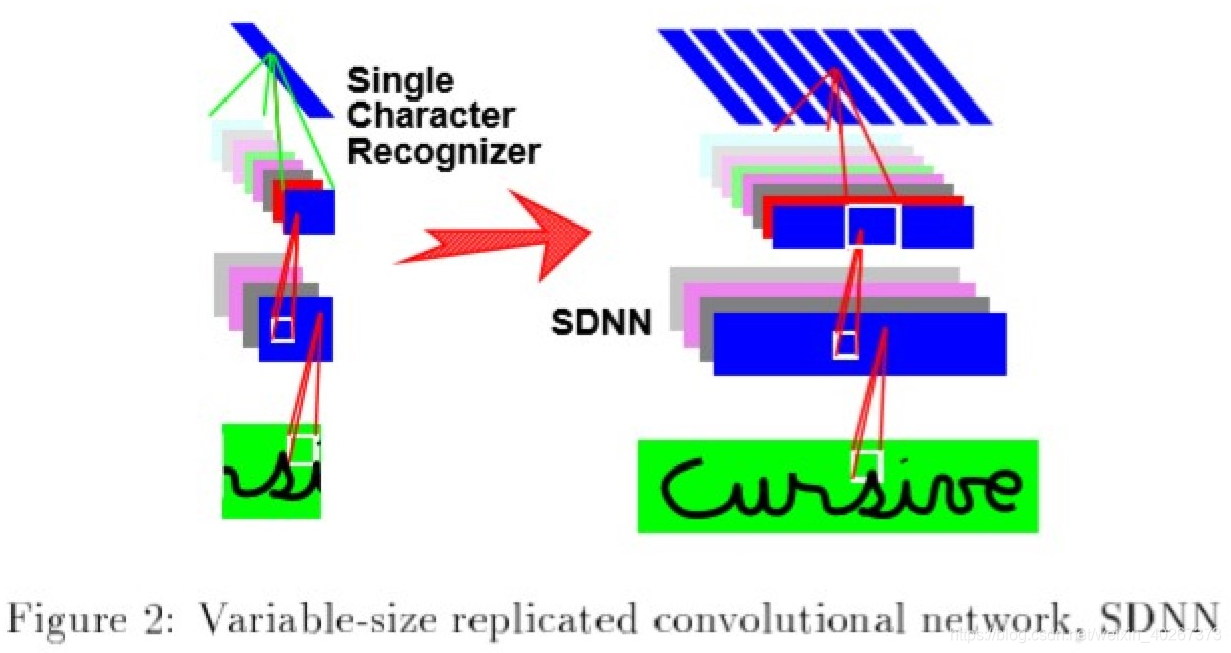
3 Variable-size convolutional networks, SDNN
While characters or short spoken words can be size-normalized and fed to a fixed-size network, more complex objects such as written or spoken words and sentences have inherently variable size.
可变大小的卷积是用于识别很多个字母的情况。这个部分和我们的工作不太相关,所以不看了。大概思想能用权重共享的思路来理解。附张可变卷积的图在这里吧。
智能推荐
什么是内部类?成员内部类、静态内部类、局部内部类和匿名内部类的区别及作用?_成员内部类和局部内部类的区别-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏42次。一、什么是内部类?or 内部类的概念内部类是定义在另一个类中的类;下面类TestB是类TestA的内部类。即内部类对象引用了实例化该内部对象的外围类对象。public class TestA{ class TestB {}}二、 为什么需要内部类?or 内部类有什么作用?1、 内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。2、内部类可以对同一个包中的其他类隐藏起来。3、 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。三、 内部类的分类成员内部_成员内部类和局部内部类的区别
分布式系统_分布式系统运维工具-程序员宅基地
文章浏览阅读118次。分布式系统要求拆分分布式思想的实质搭配要求分布式系统要求按照某些特定的规则将项目进行拆分。如果将一个项目的所有模板功能都写到一起,当某个模块出现问题时将直接导致整个服务器出现问题。拆分按照业务拆分为不同的服务器,有效的降低系统架构的耦合性在业务拆分的基础上可按照代码层级进行拆分(view、controller、service、pojo)分布式思想的实质分布式思想的实质是为了系统的..._分布式系统运维工具
用Exce分析l数据极简入门_exce l趋势分析数据量-程序员宅基地
文章浏览阅读174次。1.数据源准备2.数据处理step1:数据表处理应用函数:①VLOOKUP函数; ② CONCATENATE函数终表:step2:数据透视表统计分析(1) 透视表汇总不同渠道用户数, 金额(2)透视表汇总不同日期购买用户数,金额(3)透视表汇总不同用户购买订单数,金额step3:讲第二步结果可视化, 比如, 柱形图(1)不同渠道用户数, 金额(2)不同日期..._exce l趋势分析数据量
宁盾堡垒机双因素认证方案_horizon宁盾双因素配置-程序员宅基地
文章浏览阅读3.3k次。堡垒机可以为企业实现服务器、网络设备、数据库、安全设备等的集中管控和安全可靠运行,帮助IT运维人员提高工作效率。通俗来说,就是用来控制哪些人可以登录哪些资产(事先防范和事中控制),以及录像记录登录资产后做了什么事情(事后溯源)。由于堡垒机内部保存着企业所有的设备资产和权限关系,是企业内部信息安全的重要一环。但目前出现的以下问题产生了很大安全隐患:密码设置过于简单,容易被暴力破解;为方便记忆,设置统一的密码,一旦单点被破,极易引发全面危机。在单一的静态密码验证机制下,登录密码是堡垒机安全的唯一_horizon宁盾双因素配置
谷歌浏览器安装(Win、Linux、离线安装)_chrome linux debian离线安装依赖-程序员宅基地
文章浏览阅读7.7k次,点赞4次,收藏16次。Chrome作为一款挺不错的浏览器,其有着诸多的优良特性,并且支持跨平台。其支持(Windows、Linux、Mac OS X、BSD、Android),在绝大多数情况下,其的安装都很简单,但有时会由于网络原因,无法安装,所以在这里总结下Chrome的安装。Windows下的安装:在线安装:离线安装:Linux下的安装:在线安装:离线安装:..._chrome linux debian离线安装依赖
烤仔TVの尚书房 | 逃离北上广?不如押宝越南“北上广”-程序员宅基地
文章浏览阅读153次。中国发达城市榜单每天都在刷新,但无非是北上广轮流坐庄。北京拥有最顶尖的文化资源,上海是“摩登”的国际化大都市,广州是活力四射的千年商都。GDP和发展潜力是衡量城市的数字指...
随便推点
java spark的使用和配置_使用java调用spark注册进去的程序-程序员宅基地
文章浏览阅读3.3k次。前言spark在java使用比较少,多是scala的用法,我这里介绍一下我在项目中使用的代码配置详细算法的使用请点击我主页列表查看版本jar版本说明spark3.0.1scala2.12这个版本注意和spark版本对应,只是为了引jar包springboot版本2.3.2.RELEASEmaven<!-- spark --> <dependency> <gro_使用java调用spark注册进去的程序
汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用_uds协议栈 源代码-程序员宅基地
文章浏览阅读4.8k次。汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用,代码精简高效,大厂出品有量产保证。:139800617636213023darcy169_uds协议栈 源代码
AUTOSAR基础篇之OS(下)_autosar 定义了 5 种多核支持类型-程序员宅基地
文章浏览阅读4.6k次,点赞20次,收藏148次。AUTOSAR基础篇之OS(下)前言首先,请问大家几个小小的问题,你清楚:你知道多核OS在什么场景下使用吗?多核系统OS又是如何协同启动或者关闭的呢?AUTOSAR OS存在哪些功能安全等方面的要求呢?多核OS之间的启动关闭与单核相比又存在哪些异同呢?。。。。。。今天,我们来一起探索并回答这些问题。为了便于大家理解,以下是本文的主题大纲:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JCXrdI0k-1636287756923)(https://gite_autosar 定义了 5 种多核支持类型
VS报错无法打开自己写的头文件_vs2013打不开自己定义的头文件-程序员宅基地
文章浏览阅读2.2k次,点赞6次,收藏14次。原因:自己写的头文件没有被加入到方案的包含目录中去,无法被检索到,也就无法打开。将自己写的头文件都放入header files。然后在VS界面上,右键方案名,点击属性。将自己头文件夹的目录添加进去。_vs2013打不开自己定义的头文件
【Redis】Redis基础命令集详解_redis命令-程序员宅基地
文章浏览阅读3.3w次,点赞80次,收藏342次。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。当数据量很大时,count 的数量的指定可能会不起作用,Redis 会自动调整每次的遍历数目。_redis命令
URP渲染管线简介-程序员宅基地
文章浏览阅读449次,点赞3次,收藏3次。URP的设计目标是在保持高性能的同时,提供更多的渲染功能和自定义选项。与普通项目相比,会多出Presets文件夹,里面包含着一些设置,包括本色,声音,法线,贴图等设置。全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,主光源和附加光源在一次Pass中可以一起着色。URP:全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,一次Pass可以计算多个光源。可编程渲染管线:渲染策略是可以供程序员定制的,可以定制的有:光照计算和光源,深度测试,摄像机光照烘焙,后期处理策略等等。_urp渲染管线