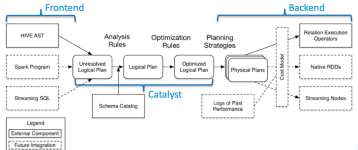
本文主要介绍了spark的执行计划explain的使用方法,以及对逻辑执行计划和物理执行计划进行了说明,让大家更加了解spark的运行原理。
”Spark“ 的搜索结果
文章总结:Spark Streaming是Spark的实时流计算API,将连续的流数据按时间间隔划分为数据块,每个块是一个RDD,具备RDD的优点,如快速处理和数据容错性。然而,实时延迟较高,不支持小批处理时间间隔。Spark ...
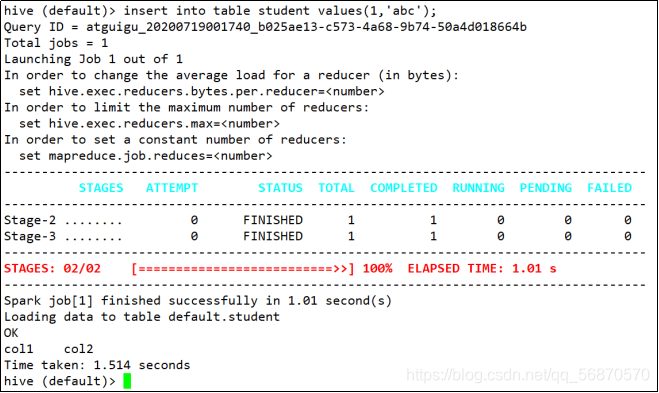
spark on hive : hive只作为存储角色,spark 负责sql解析优化,底层运行的还是sparkRDD 具体可以理解为spark通过sparkSQL使用hive语句操作hive表,底层运行的还是sparkRDD, 步骤如下: 1.通过sparkSQL,加载...

Spark独立集群管理器,一种简单的Spark集群管理器,很容易建立集群,基于Spark自己的Master-Worker集群 Apache Mesos,一种能够运行Haoop MapReduce和服务应用的集群管理器 Hadoop YARN,Spark可以和...

当以分布式集群部署的时候,可以根据自己集群的实际情况选择Standalone模式(Spark自带的模式)、Spark on YARN模式或者Spark on mesos模式。Spark的各种运行模式虽然在启动方式、运行位置、调度策略上各有不同,但...
Spark Installation with Maven & Eclipse IDE 文章目录Spark Installation with Maven & Eclipse IDE安装说明Maven & Eclipse IDE说明参考网站安装过程JDK安装Eclipse IDE安装Maven安装Spark安装新建...
:quit
spark为什么快
Table or view not found: aaa.bbb The column number of the existing table dmall_search.query_embedding_data_1(struct<>) doesn’t match the data schema(struct<user_id:string,dt:string,sku_list:...


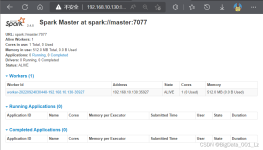
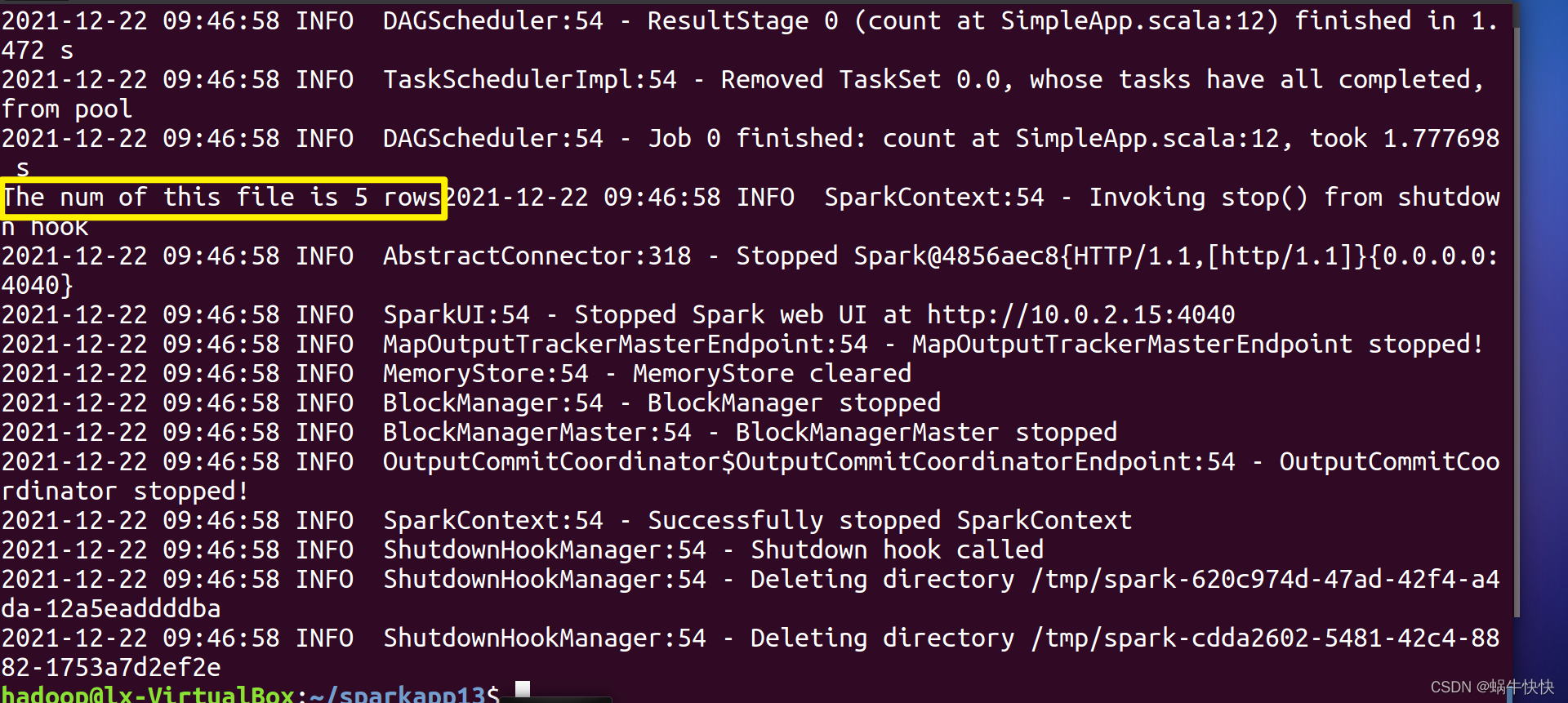
本篇博客,Alice为大家带来关于Spark命令的详解。 ...之前我们使用提交任务都是使用spark-shell提交,spark-shell是Spark自带的交互式Shell程...
这样,你就可以在 Spark 项目中使用 Scala 连接 MySQL 5.6 并进行数据的读取和写入。在 Spark 项目中,你需要在项目的构建工具中添加 MySQL 连接驱动的依赖。将 DataFrame 中的数据保存到 MySQL。在 Spark 项目中...

本人维护的Spark主要运行在三个Hadoop集群上,此外还有其他一些小集群或者隐私集群。这些机器加起来有三万台左右。目前运维的Spark主要有Spark2.3和Spark1.6两个版本。用户在使用的过程中难免会发生各种各样的问题,...
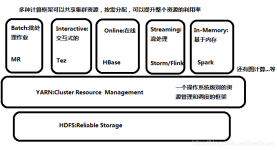
Spark、Python spark、Hadoop简介 Spark简介 1、Spark简介及功能模块 Spark是一个弹性的分布式运算框架,作为一个用途广泛的大数据运算平台,Spark允许用户将数据加载到cluster集群的内存中储存,并多次重复...


一、Spark单机模式部署 Spark版本 : spark-2.4.7-bin-hadoop2.7 1、安装配置JDK环境 2、下载Spark 官网下载http://spark.apache.org/ 然后上传到LInux服务器上 3、解压 tar -zxvf spark-2.4.7-bin-hadoop2.7.tgz ...
推荐文章
- [luogu 4442] [COCI2017-2018#3] Portal {spfa+bfs}_coci portal-程序员宅基地
- 华为杯数学建模比赛经验分享_华为杯数模准备-程序员宅基地
- PyAlgoTrade 学习笔记(一)_pyalgotrade csv-程序员宅基地
- Spark Mllib之线性SVM和逻辑回归_二项逻辑回归sample_libsvm_data.txt-程序员宅基地
- pandas.get_dummies_pd.get_dummies如果某列有缺失值-程序员宅基地
- 【Android】androidx.lifecycle.DefaultLifecycleObserver not found_defaultlifecycleobserver 找不到-程序员宅基地
- skywalking内部测试服务器安装记录_org/apache/skywalking/oap/server/starter/oapserver-程序员宅基地
- 报错提示:java.lang.IllegalArgumentException: Target must not be null-程序员宅基地
- kali安装配置使用手册_slowhttptest安装-程序员宅基地
- .Net程序员学用Oracle系列(16):访问数据库(ODP.NET)-程序员宅基地