
”Spark简介“ 的搜索结果

Spark On YARN模式的搭建比较简单,仅需要在YARN集群上的一个节点上安装Spark即可,该节点可作为提交Spark应用程序到YARN集群的客户端。2)Spark中引入的RDD是分布在多个计算节点上的只读对象集合,这些集合是弹性的...
Spark是由加州大学伯克利分校AMPLab(AMP实验室)开发的开源大数据处理框架。起初,Hadoop MapReduce是大数据处理的主流框架,但其存在一些限制,如不适合迭代算法、高延迟等。为了解决这些问题,Spark在2010年推出...


spark简介及应用.pdf
标签: spark
Spark是一个基于内存计算的开源大数据处理框架,它的出现彻底改变了大数据处理和分析的格局。Spark提供了高效、快速且易于使用的工具,使得数据科学家、数据工程师和开发人员能够轻松处理和分析大规模数据集。下面将...
星火基础 Spark基础知识I-Spark简介
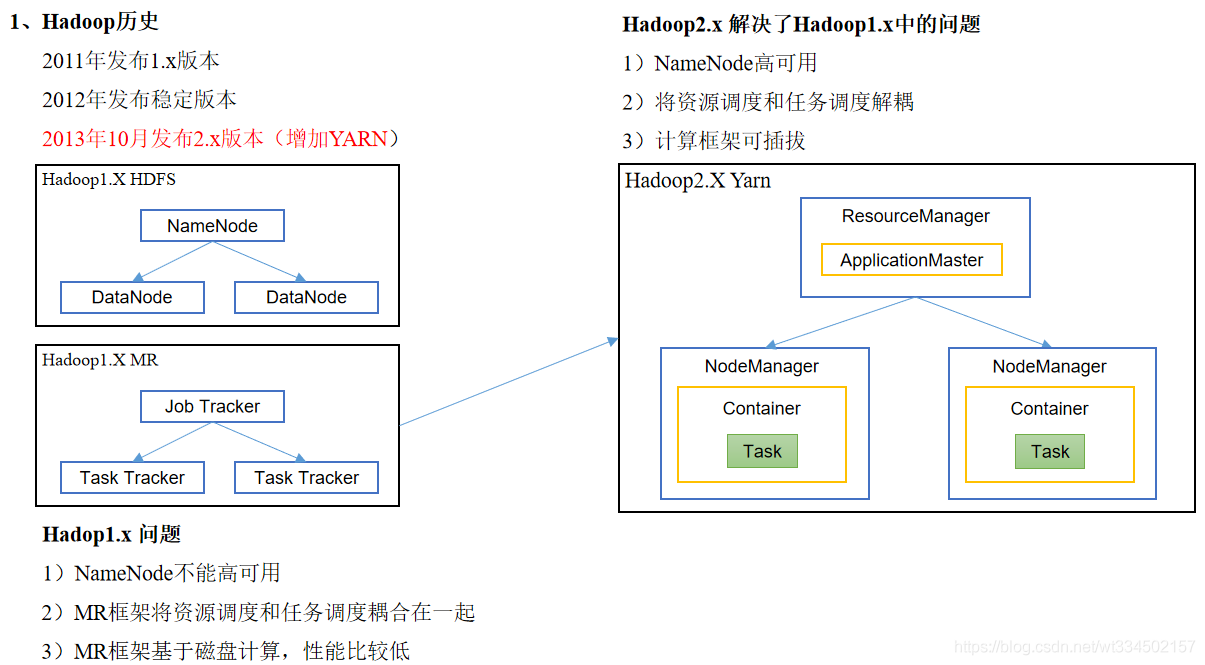
Spark是Apache顶级项目里面最火的大数据处理的计算引擎,它目前是负责大数据计算的工作。包括离线计算或交互式查询、数据挖掘算法、流式计算以及图计算等。 核心组件如下: SparkCore:包含Spark的基本功能;尤其是...
2_Hadoop与Spark简介.pptx
Spark简介以及其生态圈。Spark运行架构原理,让大家快速的理解与掌握Spark
Apache Spark™是用于大规模数据处理的统一分析引擎。 速度 运行工作负载的速度提高了100倍。 Apache Spark使用最先进的DAG调度程序,查询优化器和物理执行引擎,为批处理数据和流数据提供了高性能。 ...

Spark是什么? 简单的说Apache Spark是一个开源的、强大的分布式查询和处理引擎,它提供MapReduce的灵活性和可扩展性,但速度明显要快上很多;拿数据存储在内存中的时候来说,它比Apache Hadoop 快100倍,访问磁盘时...
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache的顶级项目,2014年5月发布spark1.0,2016年7月发布spark...
一、简介Spark 于 2009 年诞生于加州大学伯克利分校 AMPLab,2013 年被捐赠给 Apache 软件基金会,2014 年 2 月成为 Apach
推荐文章
- linux下通过/sys/kernel/debug/gpio查看gpio状态_内核判断管脚电平-程序员宅基地
- CSDN 周赛38期题解_csdn你不知道谁是小明,但是你知道小明的学号是18032。现在来了一些人,你打算挨个-程序员宅基地
- 【Activiti学习之一】Activiti入门-程序员宅基地
- java三大特性——多态_java语言多态特性-程序员宅基地
- Chrome访问https显示ERR_CERT_INVALID无法跳过问题解决-程序员宅基地
- Flask实战:实现简单的计算机资源监控系统,动态数据展示_flask机房监控系统-程序员宅基地
- 二维数组之输出杨辉三角(C++中等难度区)_c++ 输出二维数组的角标-程序员宅基地
- dos下登录fedora下的vsftp失败-程序员宅基地
- Hibernate(五)-程序员宅基地
- Java多线程-一_如果我们让父线程在子线程计算后立即访问计算值,而不是等待子线程终止。-程序员宅基地