交叉验证
”cross_val_score“ 的搜索结果
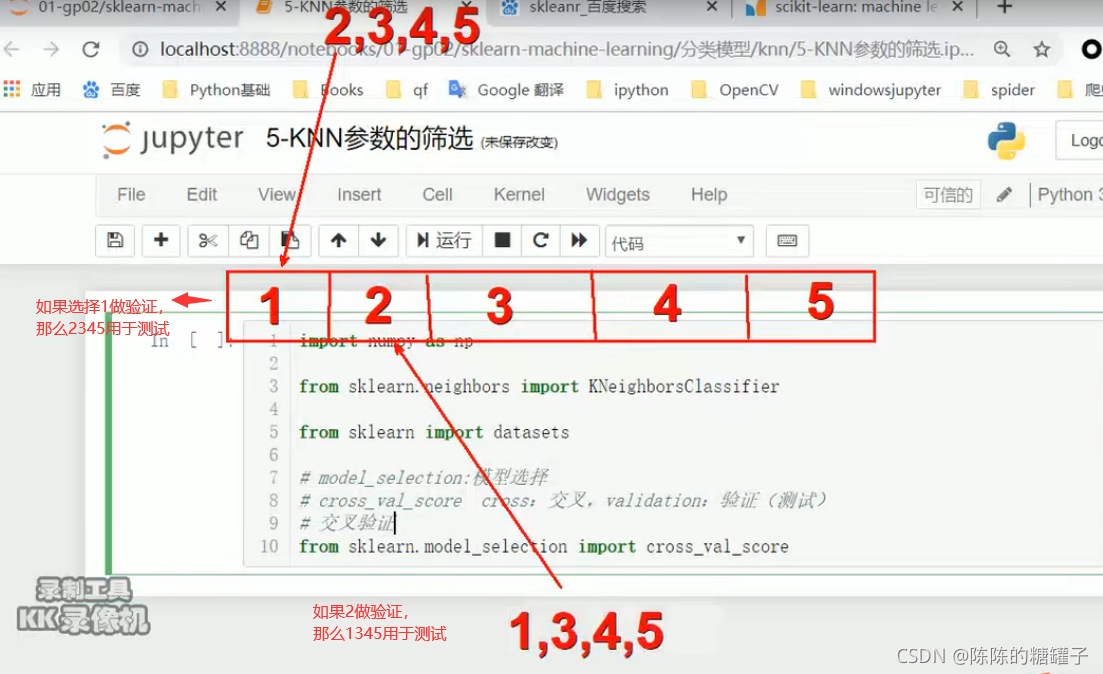
在构建模型时,调参是极为重要的一个...我使用是cross_val_score方法,在sklearn中可以使用这个方法。交叉验证的原理不好表述下面随手画了一个图: (我都没见过这么丑的图)简单说下,比如上面,我们将数据集分为10折
正常情况下,在数据集划分阶段,通常会划分为训练集trainset和测试集testset,在数据集数量足够多的...交叉验证Cross-validation思想很简单,就是对划分好的训练集再进行划分,分为训练集trainset和验证集validset。
交叉验证 一般机器学习对数据的处理就是分割数据集为训练集和测试集,用训练集去训练模型,用测试...sklearn.model_selection.cross_val_score( estimator, X, y=None, groups=None, scoring=None, cv='war
### 1.1 什么是cross_val_score函数? 在机器学习中,`cross_val_score`函数是一个用于评估模型性能的工具。它通过使用交叉验证的方法,将数据集分成多个子集,循环利用这些子集来训练和测试模型,最终返回模型的...
交叉验证(Cross-validation)主要用于建模应用中,例如PCR (主成分回归)、PLS (偏最小二乘)回归建模中。在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预报,并求这小部分样本的...
介绍cross_val_predict的概念 ## 1.1 什么是cross_val_predict 在机器学习中,交叉验证是一种常用的模型评估方法。cross_val_predict是交叉验证的一种变体,它通过在每个交叉验证折叠中进行预测,得到整体预测...
# 1. 介绍 ### 1.1 什么是交叉验证? 在机器学习领域,交叉验证是一种用来评估模型性能和泛化能力的常用技术。它通过将数据划分为训练集和测试集的多个不同子集,来多次训练模型并评估其...cross_val_predict是一个便

在这个例子中, X_train包含60000个手写数字图像的特征向量,而 y_train_5 是一个布尔数组,表示每个图像是否代表数字"5"(True表示是"5",False表示不是"5")。也就是预测结果是 5 实际情况也是 5,和预测结果是 5 ...
当运行机器学习sklearn库中的出现:**ModuleNotFoundError: No module named ‘sklearn.cross_validation’**的错误;
在构建模型时,调参是极为重要的一个步骤,因为只有选择最佳的参数才能构建一个最优的模型。但是应该如何确定参数的值呢?...很显然我是属于后者所以我需要在这里记录一下sklearn 的 cross_val_score:我使...
简单介绍了交叉验证
Unfortunately I am running into an error I cannot fix.If i just copy and paste the code I get the following error when running this snippet:import numpyimport pandasfrom keras.models import Sequentia....

cross_val_score会将数据按照类别分层随机打乱吗
在构建模型时,调参是极为重要的一个步骤,因为只有选择最佳的参数才能构建一个最优的模型。但是应该如何确定参数的值呢?所以这里记录一下选择参数的方法,以便后期复习以及分享。...sklearn 的 cross_val_sc...
我想使用交叉验证来评估使用scikitlearn的回归模型构建并使我感到困惑,我应该使用cross_val_score和cross_val_predict这两个函数中的哪一个.一种选择是:cvs = DecisionTreeRegressor(max_depth = depth)scores = ...
def baseline_logisticRegression_crossValidate():origin_train_data = pd.read_csv(r"data/train.csv")process_data = fe_preprocessData(origin_train_data,'process_train_data') # ???????...
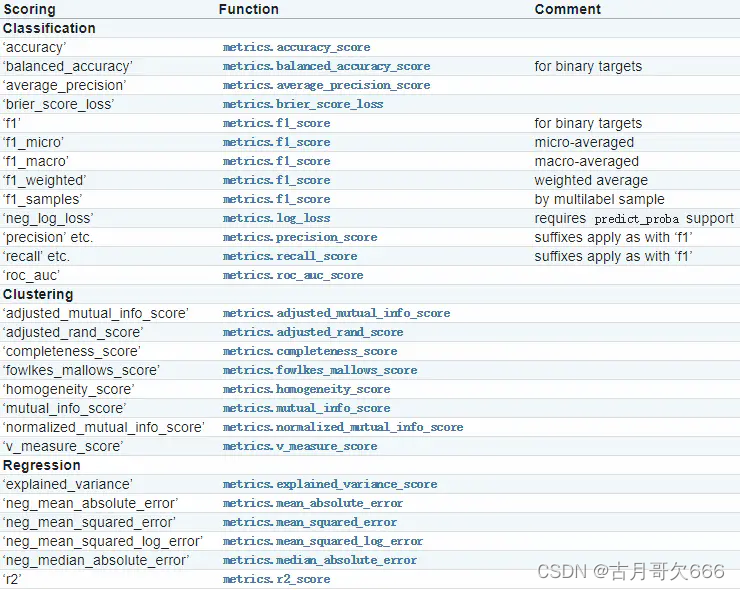
cross_val_score交叉验证 1.0 注意事项 1. 参数cv代表分成几折,其中cv-1折用于训练,1折用于测试 2. cv数值最大 = 数据集总量的1/3 3. 关于参数scoring: 1. ‘accuracy’:准确度; 2. ‘f1’:F1值,只用于二...
我正在尝试使用Python中的Sklearn进行k-...在每次我试着cross_val_score(dt, x, y, cv=5)我得到了一个错误:^{pr2}$这是我的代码:def encode_target(df, target_column):df_mod = df.copy()targets = df_mod[target...
sklearn.model_selection.cross_val_score(estimator,X,y=None,*,groups=None,scoring=None,cv=None,n_jobs=None,verbose=0,fit_params=None,pre_dispatch='2*n_jobs',error_score=nan)前面我们提到了4种分割数据集...

scikit-learn中的cross_val_score函数可以通过交叉验证评估分数,非常方便,但是使用过程中发现一个问题,就是在cross_val_score的文档中对scoring的参数并没有说明清楚。原始文档如下:文档中对scoring参数是这样...
@from sklearn.model_selection import cross_val_score @from sklearn.model_selection import GridSearchCV @sklearn.model_selection知识库
当我尝试使用不等于1的n_job的cross_val_score时遇到错误.我的系统是Intel-i7 cpu,Windows10,python3.6,Spyder.以下是我的代码:from numpy.random import randnimport pandas as pdfrom keras.wrappers.scikit_...
因为sklearn cross_val_score 交叉验证,这个函数没有洗牌功能,添加K 折交叉验证,可以用来选择模型,也可以用来选择特征sklearn.model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=...
我在写我的问题的过程中解决了这个问题,所以在这里:cross_val_score的默认行为是使用KFold或StratifiedKFold来定义折叠。 默认情况下,两者都有参数shuffle=False ,因此不会从数据中随机抽取折叠:import numpy ...
推荐文章
- Android 编译so文件 MP4V2_android下编译mp4v2-程序员宅基地
- 通讯录Contact_02_contact文件内容-程序员宅基地
- Qt笔记(四十二)之QZXing的编译 配置 使用_qzxingfilterrunnable error:-程序员宅基地
- 关于画图软件Dia打开程序始终为英文界面的问题-程序员宅基地
- OpenCV从入门到精通实战(二)——文档OCR识别(tesseract)-程序员宅基地
- 详解avcodec_receive_packet 11_avcodec_receive_packet eagain-程序员宅基地
- OpenGL SuperBible 7th源码编译记录_superbible7-media github-程序员宅基地
- Wireshark简单使用-程序员宅基地
- MXNet 粗糙的使用指南_iou loss mxnet-程序员宅基地
- iOS对ipa包进行代码混淆《二》 ---代码混淆_ipa包混淆-程序员宅基地