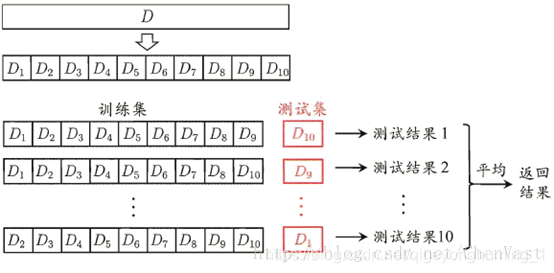
K折交叉验证是针对验证集法的另外一种改进方式,也广泛用于机器学习实践。具体的操作方式就是首先把样本全集采用分层抽样的方式随机划分为大致相等的K个子集,每个子集包含约1/K的样本,K的取值通常为5或者10,其中...
”k折分层交叉验证“ 的搜索结果
但是,对于数据集特别少的情况下,直接划分为训练集和测试集进行训练,模型的效果可能不太好,此时便引入了交叉验证。交叉验证Cross-validation思想很简单,就是对划分好的训练集再进行划分,分为训练集trainset和...
分布最优平衡分层交叉验证 (DOB-SCV) 将数据集划分为 n 折,这样,除了基于标签的分层之外,还可以为每个类维护特征空间中的平衡分布。 使用 DOB-SCV 而不是分层交叉验证的实际效果是稍微提高了测试准确性。 最大的...
交叉验证是在机器学习建立模型和验证模型参数时常用的办法。交叉验证,顾名思义,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。...

在机器学习中,我们拿到一堆数据,在对模型进行训练之前,需要对数据进行划分,在划分时,有几种不同的方法:普通划分、K折交叉验证、分层交叉验证。 这里还有一个概念——超参数,我们有时会见到,他表示在开始学习...
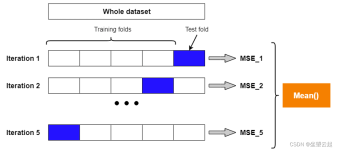
”k折交叉验证K折交叉验证(k-foldcross-validation)首先将所有数据分割成K个子样本,不重复的选取其中一个子样本作为测试集,其他K-1个样本用来训练。共重复K次,平均K次的结果或者使用其它指标,最终得到一个单一...
在临床研究领域,大家特别希望能够未仆先知,于是临床研究者尝试去建立各种预测模型。比如,凭借孕妇的信息预测低出生体重儿的结局。怎么建立预测模型呢?常见的做法是这样的:以低出生体重...其中,K折交叉验证比较...
模型在统计中是极其重要的,可以通过模型来描述数据集的内在关系,了解数据的内在关系有助于对未来进行预测。一个模型可以通过设置不同的参数来描述不同的数据集,有的参数需要根据数据集估计,有的参数需要人为...
本文结构:什么是交叉验证法?为什么用交叉验证法?主要有哪些方法?优缺点?各方法应用举例?什么是交叉验证法?它的基本思想就是将原始数据(dataset)进行分组,一部分做为训练集来训练模型,另一部分做为测试集来...
YOLOv8教程系列:三、K折交叉验证——让你的每一份标注数据都物尽其用(yolov8目标检测+k折交叉验证法)
之前使用train_test_split函数将数据集随机划分为训练集和测试集,然后使用score方法评估...标准k折交叉检验:回归问题默认使用。根据用户指定的k划分数据,经历k次训练测试,每次一折当测试集其它的是训练集。 分层
python中sklearnk折交叉验证发布时间:2018-06-10 11:09,浏览次数:492, 标签:pythonsklearnk1.模型验证回顾进行模型验证的一个重要目的是要选出一个最合适的模型,对于监督学习而言,我们希望模型对于未知数据的...
K折交叉验证不仅仅适用于多参数的网格搜索,也适用于单个参数的调优。其目的是为了提供对模型在未见数据上性能的一个更稳健的估计,从而帮助我们选择更好的参数。
大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用7-K折交叉验证的实践操作。K折交叉验证是一种机器学习中常用的模型验证和选择方式,它可以将数据集分为K个互斥的子集,其中K-1个子集作为训练集,剩下1个子...

实作交叉验证, 参考: https://github.com/apachecn/hands-on-ml-2e-zh/blob/master/docs/3.md StratifiedKFold参考: https://blog.csdn.net/weixin_44110891/article/details/95240937 StratifiedKFold用法类似...
而分层K折交叉验证 (Stratified K-fold cross-validation) 是在K折交叉验证的基础上进行改进的一种方法,它在划分数据集时会考虑数据集的类别分布情况,确保每个子集中的类别分布与整个数据集中的类别分布相同。...

文章目录K折交叉验证sklearn中的K折交叉验证sklearn中的GridSearchCV你的首个(过拟合)POI 标识符的准确度是多少?适当部署的测试范围的准确度 K折交叉验证 通过测试、验证,进而评估你的算法是否能够做你想做的。 ...
基于R语言进行K折交叉验证
标签: 算法


一般情况将K折交叉验证用于模型调优,找到使得模型泛化性能最优的超参值。,找到后,在全部训练集上重新训练模型,并使用独立测试集对模型性能做出最终评价。 K折交叉验证使用了无重复抽样技术的好处:每次迭代过程...
K折交叉验证 先导入需要的库及数据集 In [1]: import numpy as np In [2]: from sklearn.model_selection import train_test_split In [3]: from sklearn.datasets import load_iris In [4]: from sklearn ...
由于之前这篇博客用富文本编辑器写的,公式老是出问题,现在用markdown重新编辑出来。 1. Stacking定义 Stacking并不是简单地对个体学习器的结果做简单逻辑处理,而是先从初始数据集训练出初级学习器,将初级...
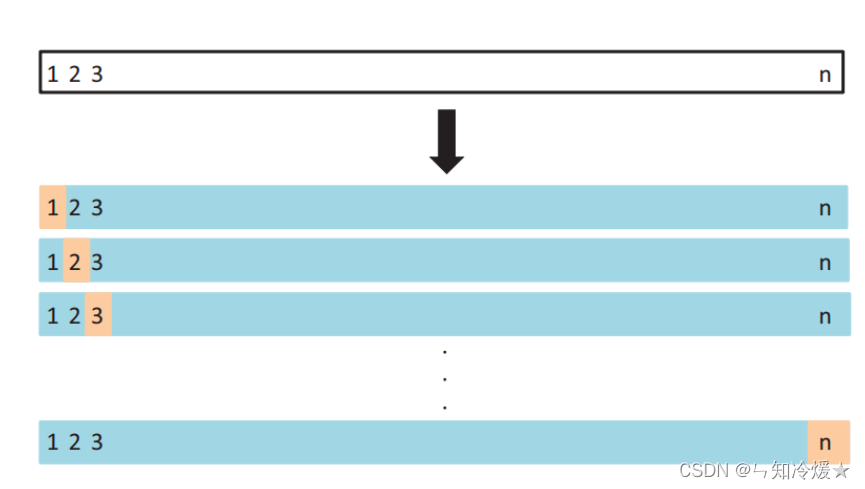
1.标准交叉验证(s折交叉验证) s折交叉验证就是将数据集分为大小相等的s份,每次随机选取s-1份作为训练集,剩下的一份为测试集。当一轮完成后,再随机选取s-1份作为训练集,若干轮(小于S)之后,选择损失函数评估...
推荐文章
- Android 编译so文件 MP4V2_android下编译mp4v2-程序员宅基地
- 通讯录Contact_02_contact文件内容-程序员宅基地
- Qt笔记(四十二)之QZXing的编译 配置 使用_qzxingfilterrunnable error:-程序员宅基地
- 关于画图软件Dia打开程序始终为英文界面的问题-程序员宅基地
- OpenCV从入门到精通实战(二)——文档OCR识别(tesseract)-程序员宅基地
- 详解avcodec_receive_packet 11_avcodec_receive_packet eagain-程序员宅基地
- OpenGL SuperBible 7th源码编译记录_superbible7-media github-程序员宅基地
- Wireshark简单使用-程序员宅基地
- MXNet 粗糙的使用指南_iou loss mxnet-程序员宅基地
- iOS对ipa包进行代码混淆《二》 ---代码混淆_ipa包混淆-程序员宅基地