”spark“ 的搜索结果
Hive 是将 SQL 转为 MapReduce。SparkSQL 可以理解成是将 SQL 解析成:“RDD + 优化” 再执行在学习Spark SQL前,需要了解数据分类。
spark3.0入门到精通
标签: spark
├─Spark-day01 │ 01-[了解]-Spark发展历史和特点介绍.mp4 │ 03-[掌握]-Spark环境搭建-Standalone集群模式.mp4 │ 06-[理解]-Spark环境搭建-On-Yarn-两种模式.mp4 │ 07-[掌握]-Spark环境搭建-On-Yarn-两种...

Spark On YARN模式的搭建比较简单,仅需要在YARN集群上的一个节点上安装Spark即可,该节点可作为提交Spark应用程序到YARN集群的客户端。2)Spark中引入的RDD是分布在多个计算节点上的只读对象集合,这些集合是弹性的...
spark
标签: JupyterNotebook
适用于Python的课程笔记本和适用于大数据的Spark 课程幻灯片:Python和大数据的火花 Spark DataFrames Spark DataFrames部分介绍 Spark DataFrame基础 Spark DataFrame操作 分组和汇总功能 缺失数据 日期和时间戳 ...
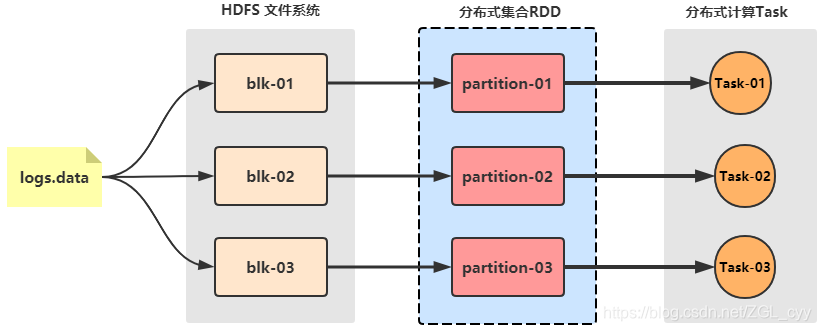
park为了解决以往分布式计算框架存在的一些问题(重复计算、资源共享、系统组合),提出了一个分布式数据集的抽象数据模型:RDD(Resilient Distributed Datasets)弹性分布式数据集。
首先来聊聊什么是Spark?为什么现在那么多人都用Spark? Spark简介: Spark是一种通用的大数据计算框架,是基于**RDD(弹性分布式数据集)**的一种计算模型。那到底是什么呢?可能很多人还不是太理解,通俗讲就是可以...
sparkcore sparksql sparkstreaming structedstreming
目录一、Spark概述(1)概述(2)Spark整体架构(3)Spark特性(4)Spark与MR(5)Spark Streaming与Storm(6)Spark SQL与Hive二、Spark基本原理(1)Spark Core(2)Spark SQL(3)Spark Streaming(4)Spark基本...
部署Spark集群大体上分为两种模式:单机模式与集群模式大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。
Spark系列之Spark启动与基础使用

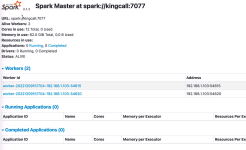
按回车键提交Spark作业后,观察Spark集群管理界面,其中“Running Applications”列表表示当前Spark集群正在计算的作业,执行几秒后,刷新界面,在Completed Applications表单下,可以看到当前应用执行完毕,返回...

在IDEA中运行spark程序


Hive On Spark 概述、安装配置、计算引擎更换、应用、异常解决
Spark大数据分析实战课后答案


YARN(Spark on YARN模式)是一款资源调度管理系统,支持动态资源分配策略,可以为Spark提供资源调度服务,由于在生产环境中,很多时候都要与Hadoop同在一个集群,所以采用YARN来管理资源调度,可以降低运维成本和...

推荐文章
- Zotero参考文献引用(适用国内)_zotero如何引用知网文献-程序员宅基地
- 智慧医院整体解决方案(医院信息化建设)PPT-程序员宅基地
- 利用定时器中断方式控制led灯的闪烁速度_项目四 定时器和中断概念的基本认识...-程序员宅基地
- 基于WVP的轻量化智能监控平台-程序员宅基地
- Scratch3.0 页面初始化的时候加载sb3文件_js 实现scrach sb3 播放器-程序员宅基地
- R语言实现Logistic回归的五折交叉验证_r 5折logistic回归的数据要求-程序员宅基地
- 基于SpringBoot+Vue的电商个性化推荐系统(源码+文档+部署+讲解)_电商推荐系统代码-程序员宅基地
- 在python中、函数可以分为哪4类_python里常用的函数类型-程序员宅基地
- Ubuntu无法检测到外接显示器,无法打开nvidia-settings或者打开nvidia-settings时有报错,ubuntu-drivers devices命令后无显示-程序员宅基地
- 解读吴恩达新书《Machine Learning Yearning》系列(二)-程序员宅基地