Spark、Python spark、Hadoop简介 Spark简介 1、Spark简介及功能模块 Spark是一个弹性的分布式运算框架,作为一个用途广泛的大数据运算平台,Spark允许用户将数据加载到cluster集群的内存中储存,并多次重复...
”spark“ 的搜索结果

从 Hive/Spark SQL 等最原始、最普及的 SQL 查询引擎,到 Kylin/ClickHouse 等 OLAP 引擎,再到流式的 Flink SQL/Kafka SQL,大数据的各条技术栈,都在或多或少地往 SQL 方向靠拢。缺乏对 SQL 的支持会让自身的技术...
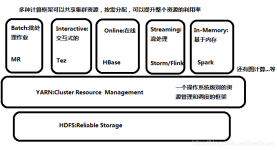
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,基于Scala开发。最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一。与Hadoop和Storm等其他大数据和...
Spark基础知识、RDD操作笔记
cluster的不太好看 succeeded表示成功了,然后点击ID那个点击进去会有一个logs(日志),在日志里面就可以查看对应的结果了它这个是根据你电脑性能来执行的,执行多次结果都是不会重复的。

Hive312的计算引擎由MapReduce(默认)改为Spark
随机森林(Random Forest)是一种基于决策树的集成学习算法,由多棵决策树组成,且每棵树的建立都依赖于一个独立抽取的样本集。在分类问题中,随机森林通过集成学习的思想将多棵树(决策树)的预测结果进行汇总,...
java提交spark任务到yarn平台的配置讲解共9页.pdf.zip

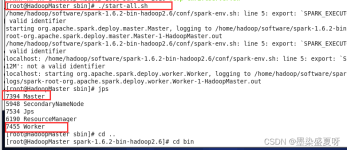
一、Spark单机模式部署 Spark版本 : spark-2.4.7-bin-hadoop2.7 1、安装配置JDK环境 2、下载Spark 官网下载http://spark.apache.org/ 然后上传到LInux服务器上 3、解压 tar -zxvf spark-2.4.7-bin-hadoop2.7.tgz ...
这段脚本首先将 project.jar 复制到 /root 目录下,然后切换到 /opt/spark/dist/bin 目录。在 begin 和 end 之间,使用 spark-submit 命令提交 Spark 程序,其中 --master local 指定了本地模式,--class Student ...
2) history-server配置,查看历史任务。打开http://spark服务器:18080。Spark版本:3.3.5。

Spark自带example
标签: spark

RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。Resilient:RDD中的数据可以存储在内存中或者磁盘中。
知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到...

需求:需要通过spark对redis里面的数据进行实时读写 实现方案:通过建立连接池,在每台机器上单独建立连接,进行操作 1、利用lazy val的方式进行包装 class RedisSink(makeJedisPool: () => JedisPool) ...
目前Spark官方提供的最新版本3.2.0,是2021年10月份发布,但是该版本搭建Windows下环境,在使用spark-shell时,会报以下错误,尚无解决方案。 退而求其次,使用Spark3.1.2,则完全正常。 本次搭建环境,所使用到的...

hive on spark
Springboot+Spark
Spark 参数设置
标签: spark
Spark系统的性能调优是一个很复杂的过程,需要对Spark以及Hadoop有足够的知识储备。从业务应用平台(Spark)、存储 (HDFS)、操作系统、硬件等多个层面都会对性能产生很大的影响。借助于多种性能监控工具,我们可以...

英特尔大数据技术中心研发经理黄洁在OpenCloud 2015大会Spark专场的演讲PPT:Spark优化及实践经验分享,就Spark的内存管理、IO提升和计算优化3个方面进行了详细讲解。对于Spark,黄洁表示,它将成为大数据的一个重要...
查看Spark Dataset的API发现,官网给了四种方法来创建临时视图,它们分别是: def createGlobalTempView(viewName: String): Unit // Creates a global temporary view using the given name. def ...
推荐文章
- 网站快速成型工具-Element UI_基于element 的网页ui-程序员宅基地
- 巨页的配置和修改_hugepages_total-程序员宅基地
- 【python】Python报错:RecursionError: maximum recursion depth exceeded in comparison-程序员宅基地
- 完成SSH项目 -- 实现dao层_ssh框架service层调用dao有的能创建成功-程序员宅基地
- 在.net下将word文档转换为加有水印pdf文档_.net webapi word pdf添加水印 开源-程序员宅基地
- 解决openweather无法注册的问题_openweather api 创建账户被禁止了-程序员宅基地
- winscp通过跳板机访问远程服务器(使用秘钥的方式传输文件)_winscp 隧道 跳板机上的密码-程序员宅基地
- 从C++到Java(一)_enum c++ java-程序员宅基地
- 网络学习第六天(路由器、VLAN)_路由和vlan-程序员宅基地
- 设置div背景颜色透明度,内部元素不透明_div设置透明度,里面的内容不透明-程序员宅基地