
”分布式ID“ 的搜索结果
分布式 ID 是分布式系统下的 ID。分布式 ID 不存在与现实生活中,属于计算机系统中的一个概念。
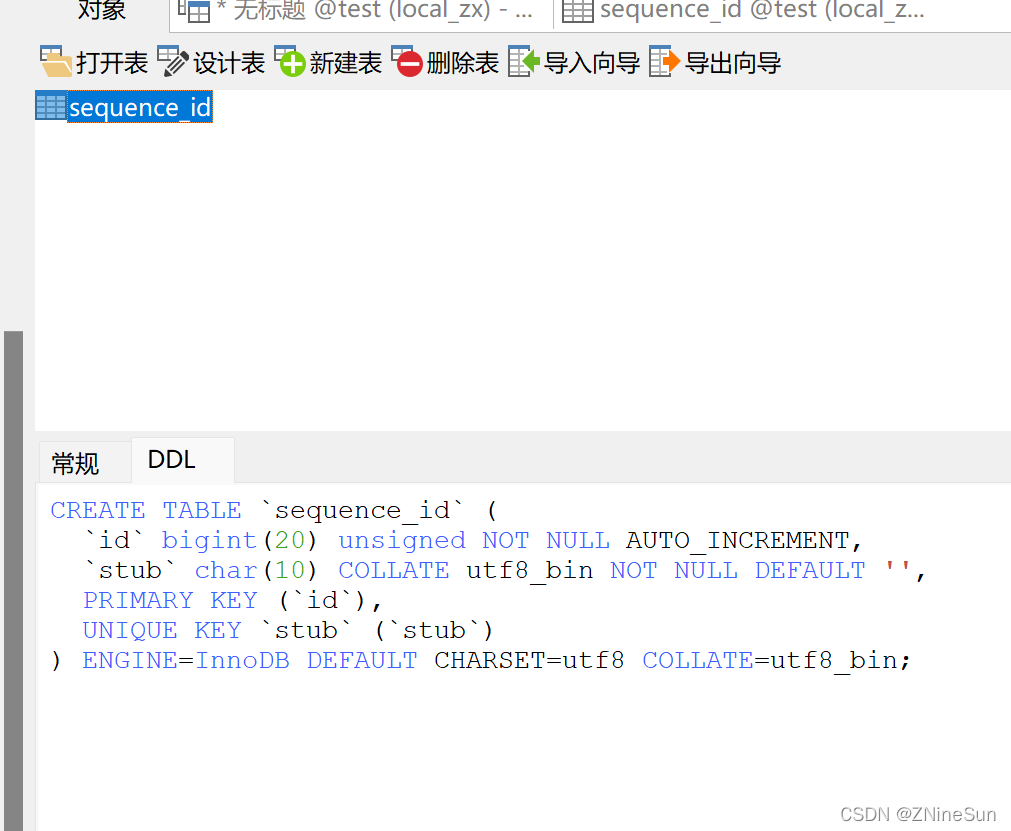
项目中的代码截取自mybatis-plus-3.5项目源码中分布式ID的实现,主要是内容是Mybatis-plus项目中IdentifierGenerator接口的两个实现类DefaultIdentifierGenerator和ImadcnIdentifierGenerator的源码,还有IdWorker工具...
一、分布式ID简介 1、什么是分布式ID? 在我们业务数据量不大的时候,单库单表完全可以支撑现有业务,数据再大一点搞个MySQL主从同步读写分离也能对付。 但随着数据日渐增长,主从同步也扛不住了,就需要对数据库...
通过DefaultUidGenerator的实现可知,它对时钟回拨的处理比较简单粗暴。

一、为什么要用分布式ID?在说分布式ID的具体实现之前,我们来简单分析一下为什么用分布式ID?分布式ID应该满足哪些特征?1、什么是分布式ID?拿MySQL数据库举个栗子:在我们业务数据量不大的时候,单库单表完全可以...

分布式id生成器.zip
标签: 分布式id
Vesta,uidgennator等分布式id生成方案 UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器。UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略, 从而适用于docker等虚拟化环境...
分布式id公开课.pptx
标签: 分布式ID
分布式id公开课.pptx
分布式id在开发分布式系统中经常会用到,有必要了解
分布式 ID 生成方案总结
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的...
【分布式】分布式 ID
标签: 分布式
一、什么是分布式ID? 二、为什么需要分布式ID? 三、如何生成分布式ID?
说的简单一点就是:应用在启动时会往数据库表(uid-generator需要新增一个WORKER_NODE表)中去插入一条数据,数据插入成功后返回的该数据对应的自增唯一id就是该机器的workId,而数据由host,port组成。
gid是使用golang开发的生成分布式Id系统,基于数据库号段算法实现 HTTP,GRPC对外服务 表现 id从内存生成,如果(step)步长设置的足够大,qps可达到千万+ 可用 id分配依赖mysql,当mysql不可用的,如果内存上还有的...
摘要:分布式id;全局唯一性;Leaf-segment 算法;美团——Leaf;BTree;B+Tree分布式id:指在分布式环境下,为保证id全局唯一性而设计的一种分布式id生成方式。全局唯一:不同机器在不同时间生成id必须唯一,确保...
比如单机 MySQL 数据库,前期因为业务量不大,只是使用单个数据库存数据,后期发现业务量一下子就增长,单机 MySQL 已经不能满足于现在的数据量,单机 MySQL 已经没办法支撑了,这时候就需要进行分库分表。
分布式ID九种实现
目录分布式ID什么是分布式ID分布式ID需要满足的需求基本需求:其他需求分布式 ID 常见解决方案1. 数据库维度基于数据库主键自增实现优点 :缺点 :基于数据库的号段模式实现(重要,Leaf和Tinyid框架基于这个模式)...
分布式ID生成,主键生成,Java实现的snowflake算法
百度开源的分布式 ID 生成器,太强大了!(csdn)————程序


分布式场景下的解决方案


分布式ID生成,雪花算法生成唯一ID工具类。该工具类线程安全。 整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右
数据库自增ID和分布式ID
标签: 数据库

推荐文章
- 【Win10】打开控制面板提示:操作系统当前的配置不能运行此应用程序-程序员宅基地
- 神经网络压缩 剪枝 量化 嵌入式计算优化NCNN mobilenet squeezenet shufflenet_基于数据压缩的mec网络中系统能效的优化方法-程序员宅基地
- 高并发场景以及应对技巧-程序员宅基地
- 登录界面转换实现html,一个登录界面的PS设计和HTML/CSS实现-程序员宅基地
- EM算法 - 2 - EM算法在高斯混合模型学习中的应用_em算法在高斯混合模型中的应用-程序员宅基地
- 【玩转华为云】手把手教你用Modelarts基于YOLO V3算法实现物体检测-程序员宅基地
- WiFi介绍_wifi dfs-程序员宅基地
- RK3568-sata接口_rk3568 sata-程序员宅基地
- java实现循环队列,解决普通队列假溢出问题_但是要利用循环队列的时候,处理假溢出,要使q.front=0的时候,为什么q.rear要加-程序员宅基地
- linux CentOS 7下载步骤_centos7下载-程序员宅基地