
”梯度下降参数不收敛“ 的搜索结果
基于DY和DL共轭梯度法,给出一个新的βk公式,在...基于新参数公式建立了采用Wolfe线搜索的共轭梯度算法,证明了算法满足充分下降性和全局收敛性,初步的数值试验结果表明该方法是有效的,适合于求解非线性无约束优化问题.

梯度下降法是一种常见的优化方法,常用于求解损失函数最小化的问题。在线性回归模型中,我们可以使用梯度下降法来求解使得模型损失函数最小的模型参数。
因为是CV出身的,转了推荐...梯度下降也是一种优化算法, 通过迭代的方式寻找使模型目标函数达到最小值时的最优参数, 当目标函数为凸函数的时候,梯度下降的解是全局最优解,但在一般情况下,梯度下降无法保证全局最优
当目标函数是凸函数时,梯度下降算法的解是全局解,一般情况下,其解 不保证是全局最优解,梯度下降的速度也未必是最快的。梯度下降法的最优化思想也是用当前位置负梯度方向最为搜索方向,因为该方向为当前位置的最...
链接:https://www.zhihu.com/question/68109802编辑:深度学习与计算机视觉声明:仅做学术分享,侵删作者:夕小瑶https://www.zhihu.co...
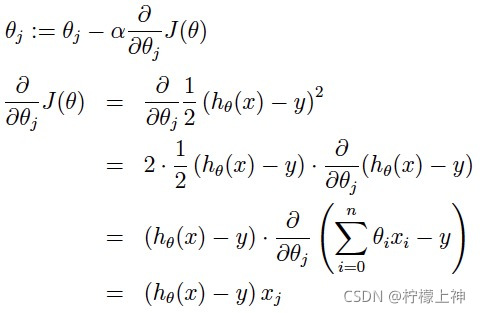
梯度下降法作为机器学习中较常使用的优化算法,其有着三种不同的形式:批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)以及小批量梯度下降(Mini-Batch Gradient Descent)。...
1. 梯度下降 1. 算法描述与学习率 梯度下降是一种非常通用的算法,能够为大范围的问题找到最优解 中心思想为:迭代地调整参数从而使成本函数最小化 首先使用一个随机的θ值(随机初始化),然后逐步改进,每次踏出...

但损失函数一般都比较复杂,难以从函数本身找到最优的参数,因此实际应用过程中使用得较多的就是梯度下降法。通过逐渐改变参数,使损失函数逐渐收敛,最终确定参数值使损失函数的值最小。梯度下降的方式分为三种:...


在上一篇推送中总结了用数学方法直接求解最小二乘项的权重参数,然而有时参数是无法直接求解的,此时我们就得借助梯度下降法,不断迭代直到收敛得到最终的权重参数。首先介绍什么是梯度下降,然后如何用它求解特征的...

这个过程通常会进行多个训练迭代,直到达到预定的停止条件(例如达到指定的训练轮数或损失函数收敛)。通过不断地调整参数并最小化损失函数,神经网络能够逐渐提升其性能和准确性。
在学习线性回归的时候很多课程都会讲到用梯度下降法求解参数,对于梯度下降算法怎么求出这个解讲的较少,自己实现一遍算法比较有助于理解算法,也能注意到比较细节的东西。具体的数学推导可以参照这一篇博客...



深度神经网络“容易收敛到局部最优”,很可能是一种想象,实际情况是,我们可能从来没有找到过“局部最优”,更别说全局最优了。 很多人都有一种看法,就是“局部最优是神经网络优化的主要难点”。这来源于一维优化...
梯度下降法及其python实现
标签: 梯度下降


在梯度下降算法中,都是围绕以下这个式子展开: 其中在上面的式子中hθ(x)代表,输入为x的时候的其当时θ参数下的输出值,与y相减则是一个相对误差,之后再平方乘以1/2,并且其中 注意到x可以一维变量,也可以是...
三种梯度下降方法2.1 批量梯度下降(Batch Gradient Descent)2.2 随机梯度下降(Stochastic Gradient Descent)2.3 小批量梯度下降(MiniBatch Gradient Descent)牛顿法牛顿法和梯度下降法的比较 梯度下降...

在深层神经网络那篇博客中讲了,深层神经网络的局部最优解问题,深层神经网络中存在局部极小点的可能性比较小,大部分是鞍点。...1.mini-batch之前的梯度下降法是将训练集所有的梯度计算之后,再更新参数,这样
神经网络的组成单元——神经元,神经元也叫做感知机。 在机器学习算法中,有时候需要对原始的模型构建损失函数,...而在求解机器学习参数的优化算法中,使用较多的就是基于梯度下降的优化算法(Gradient Descent, GD)。
推荐文章
- 机器学习之超参数优化 - 网格优化方法(随机网格搜索)_网格搜索参数优化-程序员宅基地
- Lumina网络进入SDN市场-程序员宅基地
- python引用传递的区别_php传值引用的区别-程序员宅基地
- 《TCP/IP详解 卷2》 笔记: 简介_tcpip详解卷二有必要看吗-程序员宅基地
- 饺子播放器Jzvd使用过程中遇到的问题汇总-程序员宅基地
- python- flask current_app详解,与 current_app._get_current_object()的区别以及异步发送邮件实例-程序员宅基地
- 堪比ps的mac修图软件 Pixelmator Pro 2.0.6中文版 支持Silicon M1_pixelmator堆栈-程序员宅基地
- 「USACO2015」 最大流 - 树上差分_usaco 差分-程序员宅基地
- Leetcode #315: 计算右侧小于当前元素的个数_找元素右边比他小的数字-程序员宅基地
- HTTP图解读书笔记(第六章 HTTP首部)响应首部字段_web响应的首部内容-程序员宅基地