梯度下降算法每次迭代,都会受到学习速率α的影响。如果α较小,则达到收敛所需要迭代的次数就会非常高;如果α较大,则每次迭代可能不会减小代价函数的结果,甚至会超过局部最小值导致无法收敛。根据经验,可以从...
”梯度下降参数不收敛“ 的搜索结果
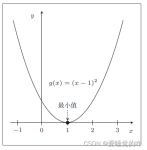

在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法。在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到...
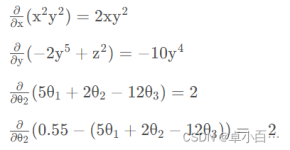
个人公众号:经管人学数据分析基本介绍梯度下降法(gradient descent),又名最速下降法(steepest descent)是求解无约束最优化问题最常用的方法,它是一种迭代方法,每一步主要的操作是求解目标函数的梯度向量,将当前...

最近实验集体学习机器学习,其中涉及到梯度下降及其变体,不是很清楚,看了好多资料和博客。在这里整理总结一下。如果哪里写得不对,请大家指正。 一、梯度下降(GD)   &...
阅读之前看这里????:博主是一名正在学习数据类知识的学生,在每个领域我们都应当是学生的心态,也不应该拥有...目录一、梯度下降(Batch Gradient Descent)二、随机梯度下降(SGD)三、小批量随机梯度下降(Mini Bat
一、梯度下降法 重申,机器学习三要素是:模型,学习准则,优化算法。这里讨论一下梯度下降法。 通常为了充分利用凸优化中的一些高效成熟的优化方法...机器学习中,常用的优化算法就是梯度下降法,首先初始化参数θ0...
随机梯度下降
批梯度下降 批量梯度下降的优势 计算效率高:正如您可能已经猜到的,此技术的计算要求较低,因为每个样本后都不需要更新。 稳定收敛:另一个优点是权重到最佳权重的收敛非常稳定。通过对数据集中每个样本的所有单独...
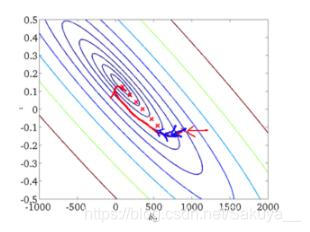
SGD 随机梯度下降 Keras 中包含了各式优化器供我们使用,但通常我会倾向于使用 SGD 验证模型能否快速收敛,然后调整不同的学习速率看看模型最后的性能,然后再尝试使用其他优化器。 Keras 中文文档中对 SGD 的...



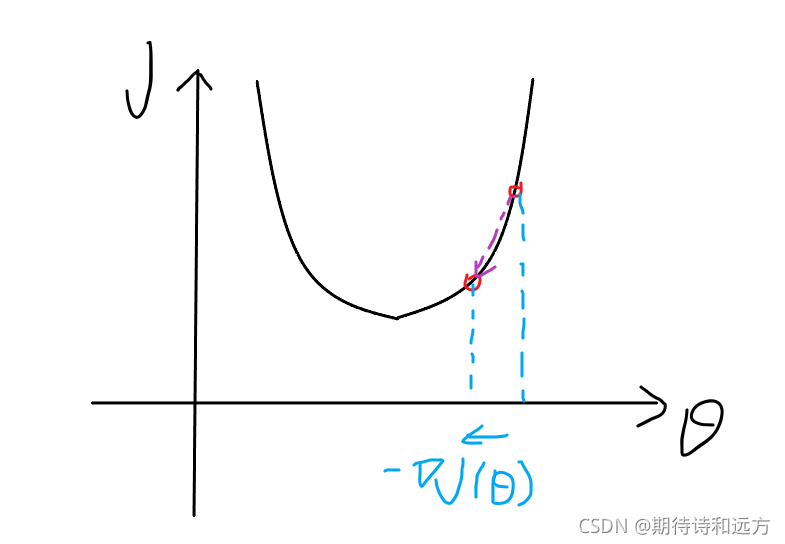
梯度下降算法背后的原理:目标函数 关于参数 的梯度将是损失函数(loss function)上升最快的方向。而我们要最小化loss,只需要将参数沿着梯度相反的方向前进一个步长,就可以实现目标函数(loss function)...

在解决了线性求解问题之后,我们开始挑战更复杂的问题,开始研究非线性划分的问题,类似求解异或问题这样,而解决这类问题,我们先要学习一个概念,就是梯度下降(Gradient Descent),这个方法是解决机器学习领域最...
共轭梯度法(Conjugate Gradient)是介于最速下降法与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了最速下降法收敛慢的缺点,又...其优点是所需存储量小,具有步收敛性,稳定性高,而且不需要任何外来参数。



通过对 Dai_Yuan共轭梯度法的分析,将βDkY推广到更一般的形式 。...含参数 Dai_Yuan共轭梯度法 不仅仅是Dai_Yuan共轭梯度法在形式上的推广,其参数的合理选择有望使 Dai_Yuan共轭梯度法良好的数值表现得到进一步 改善 。

如果我们定义了一个机器学习模型...,当损失函数值下降,我们就认为模型在拟合的路上又前进了一步。最终模型对训练数据集拟合的最好的情况是在损失函数值最小的时候,在指定数据集上时,为损失函数的平均值最小的时候。

优化算法中,梯度下降法是最简单、最常见的一种,在深度学习的训练中被广为使用。在本文中,SIGAI 将为大家系统的讲述梯度下降法的原理和实现细节问题最优化问题最优化问题是求解函数极值的问题,包括极大值和极小值...
推荐文章
- 机器学习之超参数优化 - 网格优化方法(随机网格搜索)_网格搜索参数优化-程序员宅基地
- Lumina网络进入SDN市场-程序员宅基地
- python引用传递的区别_php传值引用的区别-程序员宅基地
- 《TCP/IP详解 卷2》 笔记: 简介_tcpip详解卷二有必要看吗-程序员宅基地
- 饺子播放器Jzvd使用过程中遇到的问题汇总-程序员宅基地
- python- flask current_app详解,与 current_app._get_current_object()的区别以及异步发送邮件实例-程序员宅基地
- 堪比ps的mac修图软件 Pixelmator Pro 2.0.6中文版 支持Silicon M1_pixelmator堆栈-程序员宅基地
- 「USACO2015」 最大流 - 树上差分_usaco 差分-程序员宅基地
- Leetcode #315: 计算右侧小于当前元素的个数_找元素右边比他小的数字-程序员宅基地
- HTTP图解读书笔记(第六章 HTTP首部)响应首部字段_web响应的首部内容-程序员宅基地