python知网爬虫
标签: python爬虫
python知网爬虫,根据作者,爬取所有paper信息
标签: python爬虫
python知网爬虫,根据作者,爬取所有paper信息
使用java代码基于MyEclipse开发环境实现爬虫抓取网页中的表格数据,将抓取到的数据在控制台打印出来,需要后续处理的话可以在打印的地方对数据进行操作。包解压后导入MyEclipse就可以使用,在TestCrawTable中右键...
本篇文章主要介绍Python爬虫的由来以及过程,适合刚入门爬虫的同学,文中描述和代码示例很详细,干货满满,感兴趣的小伙伴快来一起学习吧!

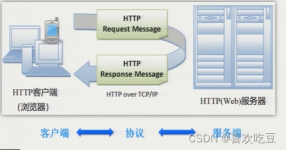
下载地址: Redis 支持 32 位和 64 位。这个需要根据你系统平台的实际情况选择,这里我们下载 Redis-x64-xxx.zip压缩包到 D 盘,解压后,将文件夹重新命名为 redis。 打开一个 cmd 窗口 使用 cd 命令切换目录到 C:...
结论: 在本篇博客中,我们介绍了五个实用的Python爬虫案例,并提供了相应的代码示例和解析。这些案例涵盖了不同的应用场景,包括爬取天气数据、图片下载、电影评论、新闻文章爬取和文本分析,以及股票数据爬取和...
通用搜索引擎利用爬虫程序对网站进行检索,如谷歌、百度等面向所有用户的大型搜索引擎,把种子页面作为搜索起点,力图遍历整个网络,尽可能全面搜索到人们 所需的信息。然而,针对某一特定主题,通用搜索引擎存在...
这是一个python专利爬虫,使用中介者模式防止目标网站长时间无响应
一个简单的python示例,实现抓取 嗅事百科 首页内容 ,大家可以自行运行测试

python代码,可以从百度图片获取给定关键词的所有图片网址,并自动命名下载到一个文件夹中
Python爬虫入门教程导航,目标100篇。
标签: 爬虫
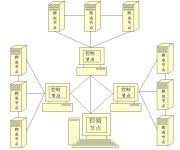
在分布式爬虫系统中,通常包括以下几个主要的组成部分:调度器、爬取节点、存储节点。我们接下来将详细介绍每一个部分的功能和设计方法。
增量式更新指的是再更新的时候只更新改变的地方,而为改变的地方则不更新,所以该爬虫。取出待抓取URL,解析DNS得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中,并且将这些URL放进已抓取URL队列。...
所以,你知道爬虫的作用了吗?
以上就是爬虫的一些基本知识,主要介绍了网络爬虫的使用工具和反爬虫策略,这些东西在后续对我们的爬虫学习会有所帮助,由于这几年断断续续的写过几个爬虫项目,使用 Java 爬虫也是在前期,后期都是用 Python,最近...
python爬虫100例教程 python爬虫实例100例子 涉及主要知识点: web是如何交互的 requests库的get、post函数的应用 response对象的相关函数,属性 python文件的打开,保存 代码中给出了注释,并且可以直接运行哦...


可以直接下载整站的图片 代码中使用多线程进行批量下载 代码中相关的内容已经加了注释 下载的同学应该可以自行修改里面的代码了
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。...
微博爬虫微博爬虫微博爬虫微博爬虫微博爬虫微博爬虫微博爬虫微博爬虫微博爬虫微博爬虫微博爬虫
标签: 大数据

用多线程的方法来加速爬虫。
Scrapy的设计是用于Web爬虫,也可以用于提取数据和自动化测试。 Scrapy提供了一个内置的HTTP请求处理器,可以通过编写自定义的中间件来扩展其功能。Scrapy使用Twisted事件驱动框架,可以同时处理数千个并发请求。 ...