python优点:1.各种爬虫框架,方便高效的下载网页;...3.gae 的支持,当初写爬虫的时候刚刚有 gae,而且只支持 python ,利用 gae 创建的爬虫几乎免费,最多的时候我有近千个应用实例在工作。java 和 c++ :相...
”爬虫“ 的搜索结果

2-2图片爬虫获取照片
标签: 图片爬虫
2-2图片爬虫获取照片
网络爬虫系列共59页.pdf.zip
了解常见基于爬虫行为进行反爬 了解常见基于数据加密进行反爬 一、反爬的三个方向 基于身份识别进行反爬 基于爬虫行为进行反爬 基于数据加密进行反爬 二、常见基于身份识别进行反爬 1. 通过headers字段来反爬 ...
在讲解之前我们先来了解下百度百科对于网络爬虫是如何定义的:网络爬虫(又被称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。...
磁力链接 Nodejs 实现磁力链接获取 DHT BT爬虫 磁力链接解析 种子解析 资源搜索
学习Python数据爬虫的方法共1页.pdf.zip
这篇文章总结了爬虫和反爬虫技术的内卷现状,以及作者DS Hunter的反爬虫经验。强调了技术手段的精髓和思维层面的重要性,提倡培养反爬虫的思路。突出了对技术的深入理解和实战经验的价值,强调了黑暗知识的存在。
了解爬虫,爬虫起源; 爬虫是什么 专业术语:网络爬虫(又被称为网页蜘蛛,网络机器人) 网络爬虫,是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。 爬虫起源(产生背景) 随着网络的迅速发展,...
网络爬虫自学笔记共7页.pdf.zip
学习Python数据爬虫的方法共1页.pdf.zip
爬虫与反爬虫,是一个很不阳光的行业。这里说的不阳光,有两个含义。 第一是,这个行业是隐藏在地下的,一般很少被曝光出来。很多公司对外都不会宣称自己有爬虫团队,甚至隐瞒自己有反爬虫团队的事实。这可能是出于...
学习数据爬虫应掌握的技能共2页.pdf.zip
学习数据爬虫应掌握的技能共2页.pdf.zip
python爬虫,用来爬取图片,已彼岸为例,可以自行输入要爬取的起始页和终止页

好用的Python爬虫与Web开发库汇总共2页.pdf.zip
好用的Python爬虫与Web开发库汇总共2页.pdf.zip

㈠爬虫简述 爬虫,又叫网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外还有一些名字,例如蚂蚁、自动索引、模拟程序或蠕虫。 ㈡爬虫优点 定向数据采集,数据定制化很强,数据针对性强...
Python网络爬虫源代码
标签: Python
Python网络爬虫源代码,Python网络爬虫源代码,Python网络爬虫源代码
抖音web频道爬虫。

【爬虫】爬虫中登录与验证码处理
标签: 爬虫
本系列为自己学习爬虫的相关笔记,如有误,欢迎大家指正 处理登录表单 随着Web 2.0的发展,大量数据都由用户产生,这里需要用到页面交互,如在论坛提交一个帖子或发送一条微博。因此,处理表单和登录成为进行网络...
目前市面上我们常见的爬虫软件大致可以划分为两大类:云爬虫和采集器(特别说明:自己开发的爬虫工具和爬虫框架除外) 云爬虫就是无需下载安装软件,直接在网页上创建爬虫并在网站服务器运行,享用网站提供的带宽和...
java爬虫完整代码,数据挖掘
推荐文章
- 【vue-treeselect+vxe-table】数据量大的时候懒加载,数据回显,输入框绑值,末级节点不要前面的箭头等问题详解_treeselect显示加载中-程序员宅基地
- 【从0入门JVM】-01Java代码怎么运行的_代码如何在jvm中运行-程序员宅基地
- TreeViewer应用实例(ITreeContentProvider与LabelProvider的使用)-程序员宅基地
- 如何将别人Google云端硬盘中的数据进行保存_谷歌网盘怎么保存别人的资源-程序员宅基地
- java中查看数据类型_java查看数据类型-程序员宅基地
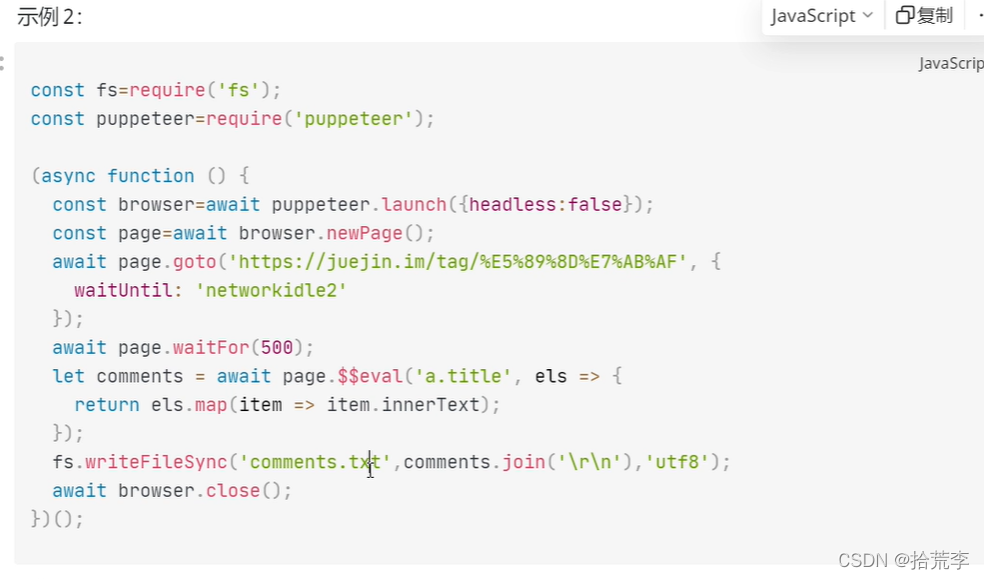
- Scrapy-redis分布式+Scrapy-redis实战-程序员宅基地
- web播放H.264/H.265,海康,大华监控摄像头RTSP流方案_海康api hls怎么取265的流-程序员宅基地
- HTML详解连载(7)-程序员宅基地
- PHP使用多线程-程序员宅基地
- 由excel一键生成json的小工具(基于python,仅支持单层嵌套)_excel转json github-程序员宅基地